OSS 向量 Bucket 最佳实践:快速构建多模态图片语义检索
OSS 向量 Bucket 是阿里云对象存储 OSS 提供的一种专门用于存储、查询和管理向量数据的 Bucket 类型,具有低成本、大规模和简单易用的特点,面向多模态检索、知识库、RAG、AI Agent 等 AI 场景提供向量存储和查询的能力。目前,已经有众多客户基于向量 Bucket 来构建自身的语义检索系统。
OSS 向量 Bucket 是阿里云对象存储 OSS 提供的一种专门用于存储、查询和管理向量数据的 Bucket 类型,具有低成本、大规模和简单易用的特点,面向多模态检索、知识库、RAG、AI Agent 等 AI 场景提供向量存储和查询的能力。目前,已经有众多客户基于向量 Bucket 来构建自身的语义检索系统。本文将介绍基于 OSS 向量 Bucket 和阿里云大模型服务平台百炼的多模态 Embedding 模型,搭建海量图片的智能语义检索系统,实现基于自然语言描述的文搜图能力的最佳实践,适用于电商商品搜索、智能相册、媒体资产管理、AI 语义检索、图片知识库等场景。
最佳实践操作概览
搭建多模态图片语义检索系统,包含以下步骤:
- 环境准备:获取访问凭证,并安装 OSS Python SDK 和阿里云百炼 SDK。
- 上传图片数据到 OSS:准备待检索的图片数据集,上传至 OSS Bucket。
- 创建 OSS 向量 Bucket 和向量索引:创建存储向量数据的 OSS 向量 Bucket 和向量索引。
- 生成并写入向量:使用阿里云百炼多模态 Embedding 模型将图片转换为高维向量,并将百炼生成的向量数据写入 OSS 向量索引中。
- 执行语义检索:将查询文本转换为向量语义,在向量索引中执行相似度搜索,同时通过元数据进行检索结果过滤。
- 可视化 Demo:通过 OSS 提供的 Demo 平台展示语义检索效果。
1.环境准备
获取访问凭证
安装SDK
-
已安装 Python 3.12 及以上版本。
-
执行以下命令安装阿里云 OSS Python SDK V2和阿里云百炼 SDK。
pip install alibabacloud-oss-v2
pip install dashscope配置环境变量
为确保代码安全与可移植性,建议将访问凭证配置为环境变量。
# 百炼 API Key
export DASHSCOPE_API_KEY=<您的百炼API-KEY>
# OSS 访问凭证
export oss_test_access_key_id=<您的AccessKey ID>
export oss_test_access_key_secret=<您的AccessKey Secret>
export oss_test_region=<您的Region,如cn-hangzhou>
export oss_test_account_id=<您的阿里云账号ID>2.上传图片数据到 OSS
将图片数据从本地上传到 OSS Bucket。百炼的 Embedding 模型需要通过 OSS 文件 URL 来访问这些图片并进行向量化处理。以下代码演示了如何批量上传本地文件夹中的图片到指定的 Bucket。
使用 OSS SDK 上传原始图片数据
"""
示例:使用文件上传管理器上传图片
本示例展示如何使用 OSS SDK 的文件上传管理器进行更高效的文件上传。
适用于大文件或需要断点续传的场景。
"""
import os
import alibabacloud_oss_v2 as oss
from alibabacloud_oss_v2.models import PutObjectRequest
def create_oss_client():
"""创建 OSS Client"""
access_key_id = os.environ.get('oss_test_access_key_id')
access_key_secret = os.environ.get('oss_test_access_key_secret')
region = os.environ.get('oss_test_region')
cfg = oss.config.load_default()
cfg.credentials_provider = oss.credentials.StaticCredentialsProvider(
access_key_id, access_key_secret
)
cfg.region = region
return oss.Client(cfg)
def upload_with_uploader(client, bucket_name: str, local_path: str, oss_key: str):
"""
使用上传管理器上传文件
Args:
client: OSS Client
bucket_name: OSS Bucket 名称
local_path: 本地文件路径
oss_key: OSS 对象键
"""
# 创建上传管理器
uploader = client.uploader()
# 执行上传
result = uploader.upload_file(
filepath=local_path,
request=PutObjectRequest(
bucket=bucket_name,
key=oss_key
)
)
return result
def main():
client = create_oss_client()
bucket_name = "your-bucket-name"
# 注意:文末的 Github仓库里 data/photograph/ 目录已包含测试图片,可直接使用
# 也可以修改 local_image_path 变量,指向自己的图片目录
local_image_path = "data/photograph/"
oss_prefix = "photograph/"
image_files = os.listdir(local_image_path)
print(f"待上传图片数量: {len(image_files)}")
for i, image_name in enumerate(image_files, 1):
local_path = os.path.join(local_image_path, image_name)
oss_key = f"{oss_prefix}{image_name}"
try:
result = upload_with_uploader(client, bucket_name, local_path, oss_key)
print(f"[{i}/{len(image_files)}] 上传成功: {image_name}, status: {result.status_code}")
except Exception as e:
print(f"[{i}/{len(image_files)}] 上传失败 {image_name}: {e}")
print(f"\n上传完成!")
if __name__ == "__main__":
main()3.创建 OSS 向量 Bucket 和向量索引
创建向量 Bucket
使用 OSS SDK 创建一个向量 Bucket,将其作为存储所有向量数据和向量索引的云资源。OSS 向量 Bucket 目前在 华南1(深圳)、华北2(北京)、华东1(杭州)、华东2(上海)、华北6(乌兰察布)、新加坡、中国香港、印度尼西亚(雅加达)、德国(法兰克福)、美国(硅谷)、美国(弗吉尼亚)地域。您可以在同一地域中创建最多 10 个向量 Bucket。
创建向量 Bucket
# -*- coding: utf-8 -*-
"""
示例:创建 VectorBucket
本示例展示如何创建一个 OSS VectorBucket。
前提条件:
1. 已安装 alibabacloud-oss-v2: pip install alibabacloud-oss-v2
2. 已设置环境变量(参考初始化 Client 示例)
"""
import os
import alibabacloud_oss_v2 as oss
import alibabacloud_oss_v2.vectors as oss_vectors
def main():
# 从环境变量获取凭证
access_key_id = os.environ.get('oss_test_access_key_id')
access_key_secret = os.environ.get('oss_test_access_key_secret')
region = os.environ.get('oss_test_region')
account_id = os.environ.get('oss_test_account_id')
# 初始化 Client
cfg = oss.config.load_default()
cfg.credentials_provider = oss.credentials.StaticCredentialsProvider(
access_key_id, access_key_secret
)
cfg.region = region
cfg.account_id = account_id
client = oss_vectors.Client(cfg)
# VectorBucket 名称
vector_bucket_name = "my-test-2"
print(f"正在创建 VectorBucket: {vector_bucket_name}")
try:
# 创建 VectorBucket
result = client.put_vector_bucket(oss_vectors.models.PutVectorBucketRequest(
bucket=vector_bucket_name,
))
print(f"创建成功!")
print(f" status code: {result.status_code}")
print(f" request id: {result.request_id}")
except Exception as e:
print(f"创建失败: {e}")
print("提示: 如果 Bucket 已存在,会返回错误")
if __name__ == "__main__":
main()创建向量索引
OSS 向量 Bucket 创建成功后,您还需要在该向量 Bucket 中创建向量索引,作为存储向量数据的索引表。向量索引创建后,您可以逐行写入向量数据,以及向量数据所携带的标量元数据。向量索引定义了向量的结构(如维度)和检索方式(如距离度量),是存储和查询向量数据的基础。其中,向量索引的维度需要和您在百炼中使用的向量模型的维度保持一致,以下以创建一张向量维度为 1024 维,距离度量函数为余弦距离方式的向量索引表为例。
创建向量索引
"""
示例:创建向量索引(Index)
本示例展示如何在 VectorBucket 中创建向量索引。
前提条件:
1. 已安装 alibabacloud-oss-v2: pip install alibabacloud-oss-v2
2. 已设置环境变量
3. 已创建 VectorBucket
"""
import os
import alibabacloud_oss_v2 as oss
import alibabacloud_oss_v2.vectors as oss_vectors
def main():
# 从环境变量获取凭证
access_key_id = os.environ.get('oss_test_access_key_id')
access_key_secret = os.environ.get('oss_test_access_key_secret')
region = os.environ.get('oss_test_region')
account_id = os.environ.get('oss_test_account_id')
# 初始化 Client
cfg = oss.config.load_default()
cfg.credentials_provider = oss.credentials.StaticCredentialsProvider(
access_key_id, access_key_secret
)
cfg.region = region
cfg.account_id = account_id
client = oss_vectors.Client(cfg)
# 配置参数
vector_bucket_name = "my-test-2"
vector_index_name = "test1"
dimension = 1024 # 百炼多模态模型输出向量维度
print(f"正在创建向量索引:")
print(f" Bucket: {vector_bucket_name}")
print(f" Index: {vector_index_name}")
print(f" 维度: {dimension}")
# 创建向量索引
result = client.put_vector_index(oss_vectors.models.PutVectorIndexRequest(
bucket=vector_bucket_name,
index_name=vector_index_name,
dimension=dimension,
data_type='float32', # 向量数据类型
distance_metric='cosine', # 距离度量方式:余弦相似度
metadata={
"nonFilterableMetadataKeys": ["key1", "key2"] # 不参与过滤的元数据字段
}
))
print(f"\n创建成功!")
print(f" status code: {result.status_code}")
print(f" request id: {result.request_id}")
if __name__ == "__main__":
main()4.生成并写入向量
OSS 向量 Bucket 支持写入任意方式产生的向量数据,如通过阿里云百炼、自建向量化服务等方式。本文使用阿里云百炼的多模态 Embedding 模型“multimodal-embedding-v1 ”来生成图片的向量化数据,将原始图片转换为 1024 维向量,并写入到 OSS 向量 Bucket 的向量索引中。您可以分别调用阿里云百炼和 OSS 的 SDK 来生成和写入向量,也可以使用 OSS-Vectors-Embed-CLI 命令行工具封装好的命令来通过一条命令完成向量数据和写入。
-
使用阿里云百炼 SDK 和 OSS SDK 来生成和写入向量
使用阿里云百炼 SDK 生成向量数据
import dashscope
from dashscope import MultiModalEmbeddingItemImage
def embedding_image(image_url: str) -> list[float]:
"""
将图片转换为向量
Args:
image_url: 图片的 URL 地址(支持 OSS 地址或公网 URL)
Returns:
1024 维的向量列表
"""
resp = dashscope.MultiModalEmbedding.call(
model="multimodal-embedding-v1",
input=[MultiModalEmbeddingItemImage(image=image_url, factor=1.0)]
)
return resp.output["embeddings"][0]["embedding"]
def main():
# 示例图片 URL(需替换为实际可访问的图片地址,如为图片为私有权限,需要填入带签名的临时 URL)
image_url = "http://your-bucket-name.oss-cn-hangzhou.aliyuncs.com/photograph/Zsd0YhBa8LM.jpg"
print(f"正在对图片进行向量化: {image_url}")
# 调用 Embedding API
resp = dashscope.MultiModalEmbedding.call(
model="multimodal-embedding-v1",
input=[MultiModalEmbeddingItemImage(image=image_url, factor=1.0)]
)
# 打印完整响应
print("\n完整响应:")
print(resp)
# 获取向量
embedding = resp.output["embeddings"][0]["embedding"]
print(f"\n向量维度: {len(embedding)}")
print(f"向量前10个元素: {embedding[:10]}")
if __name__ == "__main__":
main()使用 OSS SDK 将百炼生成的向量数据写入到 OSS 向量索引
# -*- coding: utf-8 -*-
"""
示例:批量写入图片向量数据
本示例展示如何批量写入已经向量化的图片数据到向量索引中。
前提条件:
1. 已安装 alibabacloud-oss-v2: pip install alibabacloud-oss-v2
2. 已设置环境变量
3. 已创建向量索引
4. 已准备好图片向量数据文件(data/data.json)
"""
import os
import json
import alibabacloud_oss_v2 as oss
import alibabacloud_oss_v2.vectors as oss_vectors
def main():
# 从环境变量获取凭证
access_key_id = os.environ.get('oss_test_access_key_id')
access_key_secret = os.environ.get('oss_test_access_key_secret')
region = os.environ.get('oss_test_region')
account_id = os.environ.get('oss_test_account_id')
# 初始化 Client
cfg = oss.config.load_default()
cfg.credentials_provider = oss.credentials.StaticCredentialsProvider(
access_key_id, access_key_secret
)
cfg.region = region
cfg.account_id = account_id
client = oss_vectors.Client(cfg)
# 配置参数
vector_bucket_name = "my-test-2"
vector_index_name = "test1"
# 加载预处理好的图片向量数据
# 注意:文末的 Github仓库里 data/目录已包含测试文件,可直接使用
# 也可以修改 data_file 变量,指向自己的图片目录
data_file = "./data/data.json"
print(f"正在加载图片向量数据: {data_file}")
image_data_array = []
with open(data_file, "r") as f:
image_data_array = json.load(f)
print(f"共加载 {len(image_data_array)} 条图片向量数据")
# 打印数据样例
if len(image_data_array) > 0:
sample = image_data_array[0]
print(f"\n数据样例:")
print(f" key: {sample.get('key', 'N/A')}")
if 'metadata' in sample:
print(f" metadata: {sample['metadata']}")
if 'data' in sample and 'float32' in sample['data']:
print(f" 向量维度: {len(sample['data']['float32'])}")
# 批量写入,每批 500 条
batch_size = 500
vectors = []
total_written = 0
print(f"\n开始批量写入 (batch_size={batch_size})...")
for idx in range(len(image_data_array)):
vectors.append(image_data_array[idx])
if len(vectors) == batch_size:
result = client.put_vectors(oss_vectors.models.PutVectorsRequest(
bucket=vector_bucket_name,
index_name=vector_index_name,
vectors=vectors,
))
total_written += len(vectors)
print(f" 已写入 {total_written}/{len(image_data_array)} 条, "
f"status code: {result.status_code}")
vectors = []
# 写入剩余数据
if len(vectors) > 0:
result = client.put_vectors(oss_vectors.models.PutVectorsRequest(
bucket=vector_bucket_name,
index_name=vector_index_name,
vectors=vectors,
))
total_written += len(vectors)
print(f" 已写入 {total_written}/{len(image_data_array)} 条, "
f"status code: {result.status_code}")
print(f"\n写入完成! 共写入 {total_written} 条向量数据")
if __name__ == "__main__":
main()-
使用 OSS-Vectors-Embed-CLI 工具的命令来完成向量生成和写入
OSS-Vectors-Embed-CLI 命令行工具是 OSS 推出的全新命令行工具,用户可以使用该工具的封装命令便捷地调用阿里云百炼向量模型,将 OSS 中原始文件或存储在本地的海量文件进行向量化,并将向量化结果写入到 OSS 向量 Bucket。同时,该命令行工具也支持发起多模态语义检索,简化如 RAG 知识库、AI 助手、多模态语义检索等各类 AI 应用的开发流程,并具有批量处理、灵活自定义、添加标量元数据等丰富的功能,您可以参考,<使用OSS-Vectors-Embed-CLI工具三步搭建多模态语义检索系统>
请求示例
oss-vectors-embed \
--account-id <your-account-id> \ //阿里云 ID
--vectors-region cn-hangzhou \ //OSS 向量 Bucket 所在地域
put \
--region cn-hangzhou \ //OSS 原始文件所在 Bucket 的地域
--vector-bucket-name my-vector-bucket \ //OSS 向量 Bucket 名称
--index-name my-index \ //OSS 向量 Index 名称
--model-id multimodal-embedding-v1 \ //使用的向量模型
--image "oss://bucket/path/*" //对 OSS 该 Prefix 下的文件批量发起向量化和向量结果的写入
--filename-as-key //将原始文件 Key 值自定义设置为向量 Ke返回示例
{
"type": "streaming_batch",
"bucket": "my-vector-bucket",
"index": "my-index",
"model": "multimodal-embedding-v1",
"contentType": "image",
"totalFiles": 2,
"processedFiles": 2,
"failedFiles": 0,
"totalVectors": 2,
"vectorKeys": [
"myimage01.jpg",
"myimage02.jpg"
]
}5.执行语义检索
您可以使用自然语言文本作为 Query 查询条件,调用 OSS 向量 Bucket 提供的 QueryVectors 接口、SDK 或者 OSS-Vectors-Embed-CLI 命令行工具来完成向量语义检索,或者向量和标量的混合检索,以返回最相似的向量 TopK。
5.1 向量检索
-
使用阿里云百炼 SDK 和 OSS SDK 来进行向量检索
将查询文本(例如“狗狗”)向量化后,在索引中查找最接近的 Top-K 个图片向量
使用阿里云百炼 SDK 和 OSS SDK 来进行向量检索
# -*- coding: utf-8 -*-
"""
示例:向量检索查询(Query Vector)
本示例展示如何使用向量进行相似度检索,支持元数据过滤。
前提条件:
1. 已安装 alibabacloud-oss-v2 和 dashscope
2. 已设置环境变量
3. 已设置百炼 API Key: export DASHSCOPE_API_KEY=<您的 API Key>
4. 已写入向量数据
"""
import os
import alibabacloud_oss_v2 as oss
import alibabacloud_oss_v2.vectors as oss_vectors
import dashscope
from dashscope import MultiModalEmbeddingItemText
def embedding(text: str) -> list[float]:
"""
文本向量化用于将查询文本转换为向量,实现文搜图能力
Args:
text: 待转换的文本
Returns:
1024 维的向量列表
"""
return dashscope.MultiModalEmbedding.call(
model="multimodal-embedding-v1",
input=[MultiModalEmbeddingItemText(text=text, factor=1.0)]
).output["embeddings"][0]["embedding"]
def main():
# 从环境变量获取凭证
access_key_id = os.environ.get('oss_test_access_key_id')
access_key_secret = os.environ.get('oss_test_access_key_secret')
region = os.environ.get('oss_test_region')
account_id = os.environ.get('oss_test_account_id')
# 初始化 Client
cfg = oss.config.load_default()
cfg.credentials_provider = oss.credentials.StaticCredentialsProvider(
access_key_id, access_key_secret
)
cfg.region = region
cfg.account_id = account_id
client = oss_vectors.Client(cfg)
# 配置参数
vector_bucket_name = "my-test-2"
vector_index_name = "test1"
# 查询文本
query_text = "狗狗"
print(f"正在进行向量检索:")
print(f" Bucket: {vector_bucket_name}")
print(f" Index: {vector_index_name}")
print(f" 查询文本: {query_text}")
# 将查询文本转换为向量
print(f"\n正在将查询文本转换为向量...")
query_vector = embedding(query_text)
print(f" 向量维度: {len(query_vector)}")
# 执行向量检索
print(f"\n执行向量检索 ...")
result = client.query_vectors(oss_vectors.models.QueryVectorsRequest(
bucket=vector_bucket_name,
index_name=vector_index_name,
query_vector={
"float32":query_vector
},
top_k=5, # 返回最相似的 5 个结果
return_distance=True, # 返回相似度距离
return_metadata=True, # 返回元数据
))
print(f"\n检索结果 (共 {len(result.vectors)} 条):")
for i, vector in enumerate(result.vectors, 1):
print(f"\n [{i}] key: {vector.get('key', 'N/A')}")
if 'distance' in vector:
print(f" 距离: {vector['distance']:.6f}")
if 'metadata' in vector:
print(f" 元数据: {vector['metadata']}")
# 不带过滤条件的检索
print(f"\n" + "=" * 50)
print(f"执行向量检索 (无过滤条件)...")
result = client.query_vectors(oss_vectors.models.QueryVectorsRequest(
bucket=vector_bucket_name,
index_name=vector_index_name,
query_vector={
"float32": query_vector
},
top_k=5,
return_distance=True,
return_metadata=True,
))
print(f"\n检索结果 (共 {len(result.vectors)} 条):")
for i, vector in enumerate(result.vectors, 1):
print(f" [{i}] key: {vector.get('key', 'N/A')}, "
f"距离: {vector.get('distance', 'N/A')}")
if __name__ == "__main__":
main()-
使用 OSS-Vectors-Embed-CLI 工具的命令来完成向量检索
OSS-Vectors-Embed-CLI 提供封装好的命令语句,快速完成 Query 内容的向量化和相似度检索。除了支持本文中的“以文搜图”,还可以满足如“以图搜图”等多模态语义检索需求。您可以参考<使用OSS-Vectors-Embed-CLI工具三步搭建多模态语义检索系统>
请求示例
oss-vectors-embed \
--account-id <your-account-id> \
--vectors-region cn-hangzhou \
query \
--vector-bucket-name my-vector-bucket \
--index-name my-index \
--model-id multimodal-embedding-v1 \
--text-value "狗狗" \ // Query 检索文本
--top-k 100 // 检索返回 100 个最相似的向量结果返回示例
{
"results": [
{
"Key": "myimage03.jpg", //检索返回的向量结果,返回向量 Key-Value 和标量元数据
"metadata": {
"OSS-VECTORS-EMBED-SRC-CONTENT-TYPE": "TEXT",
"OSS-VECTORS-EMBED-SRC-LOCATION": "./images/photo.jpg", //CLI 会自动在向量 Bucket 该向量所在行添加源信息字段(OSS-VECTORS-EMBED-SRC-*),用于追溯向量来源。
}
},
...
],
"summary": {
"queryType": "text",
"model": "multimodal-embedding-v1",
"index": "my-index",
"resultsFound": 100,
"queryDimensions": 1024
}
}5.2 结合标量元数据过滤条件进行检索
在进行向量相似度检索的同时,OSS 向量 Bucket 可以根据图片的元数据(如city、height)进行精确过滤,以缩小检索范围。向量检索支持使用$in、$and、$or等操作符对元数据进行过滤。
-
使用阿里云百炼 SDK 和 OSS SDK 来进行向量检索
将查询文本(例如“狗狗”)向量化后,在索引中查找最接近的 Top-K 个图片向量,并添加不同的标量元数据过滤条件。
使用阿里云百炼 SDK 和 OSS SDK 来进行向量检索
"""
示例:高级向量检索查询(Advanced Query)
本示例展示向量检索的高级用法,包括复杂过滤条件和多个查询示例。
前提条件:
1. 已安装 alibabacloud-oss-v2 和 dashscope
2. 已设置环境变量
3. 已设置百炼 API Key: export DASHSCOPE_API_KEY=<您的 API Key>
4. 已写入向量数据
"""
import os
import alibabacloud_oss_v2 as oss
import alibabacloud_oss_v2.vectors as oss_vectors
import dashscope
from dashscope import MultiModalEmbeddingItemText
def embedding(text: str) -> list[float]:
"""文本向量化用于将查询文本转换为向量,实现文搜图能力"""
return dashscope.MultiModalEmbedding.call(
model="multimodal-embedding-v1",
input=[MultiModalEmbeddingItemText(text=text, factor=1.0)]
).output["embeddings"][0]["embedding"]
def create_client():
"""创建 OSS Vector Client"""
access_key_id = os.environ.get('oss_test_access_key_id')
access_key_secret = os.environ.get('oss_test_access_key_secret')
region = os.environ.get('oss_test_region')
account_id = os.environ.get('oss_test_account_id')
cfg = oss.config.load_default()
cfg.credentials_provider = oss.credentials.StaticCredentialsProvider(
access_key_id, access_key_secret
)
cfg.region = region
cfg.account_id = account_id
return oss_vectors.Client(cfg)
def query_with_filter(client, bucket, index, query_text, filter_body, top_k=5):
"""执行带过滤条件的向量检索"""
result = client.query_vectors(oss_vectors.models.QueryVectorsRequest(
bucket=bucket,
index_name=index,
query_vector={"float32": embedding(query_text)},
filter=filter_body,
top_k=top_k,
return_distance=True,
return_metadata=True,
))
return result.vectors
def main():
client = create_client()
vector_bucket_name = "my-test-2"
vector_index_name = "test1"
print("=" * 60)
print("高级向量检索示例")
print("=" * 60)
# 示例 1: $in 操作符 - 匹配多个城市
print("\n【示例 1】使用 $in 操作符 - 查询杭州或上海的图片")
print("-" * 40)
filter_in = {
"city": {"$in": ["hangzhou", "shanghai"]}
}
results = query_with_filter(client, vector_bucket_name, vector_index_name,
"城市风景", filter_in)
print(f"查询: '城市风景', 过滤: city in ['hangzhou', 'shanghai']")
print(f"结果数量: {len(results)}")
for v in results[:3]:
print(f" - {v.get('key')}: {v.get('metadata', {}).get('city', 'N/A')}")
# 示例 2: $and 操作符 - 组合多个条件
print("\n【示例 2】使用 $and 操作符 - 组合多个过滤条件")
print("-" * 40)
filter_and = {
"$and": [
{"city": {"$in": ["hangzhou", "shanghai"]}},
{"height": {"$in": ["1024"]}}
]
}
results = query_with_filter(client, vector_bucket_name, vector_index_name,
"高楼大厦", filter_and)
print(f"查询: '高楼大厦', 过滤: city in [hangzhou, shanghai] AND height=1024")
print(f"结果数量: {len(results)}")
for v in results[:3]:
meta = v.get('metadata', {})
print(f" - {v.get('key')}: city={meta.get('city')}, height={meta.get('height')}")
# 示例 3: 不同查询文本的比较
print("\n【示例 3】不同查询文本的语义检索效果")
print("-" * 40)
query_texts = ["狗狗", "海边日落", "城市夜景", "美食"]
for qt in query_texts:
results = query_with_filter(client, vector_bucket_name, vector_index_name,
qt, None, top_k=3)
print(f"\n查询: '{qt}'")
for i, v in enumerate(results, 1):
print(f" [{i}] {v.get('key')}, 距离: {v.get('distance', 0):.4f}")
if __name__ == "__main__":
main()-
使用 OSS-Vectors-Embed-CLI 工具的命令来完成向量检索
OSS-Vectors-Embed-CLI 提供封装好的命令语句,也可以添加相应的标量元数据过滤语法进行标量元数据过滤,如 AND、OR、IN 等,以加强检索结果的准确性,快速完成 Query 内容的向量化和相似度检索。除了支持本文中的“以文搜图”,还可以满足如“以图搜图”等多模态语义检索需求。您可以参考<使用OSS-Vectors-Embed-CLI工具三步搭建多模态语义检索系统>。
请求示例返回示例
# AND: 两个条件都必须匹配
oss-vectors-embed \
--account-id <your-account-id> \
--vectors-region cn-hangzhou \
query \
--vector-bucket-name my-vector-bucket \
--index-name my-index \
--model-id multimodal-embedding-v1 \
--text-value "狗狗" \
--filter { //组合过滤条件
"$and": [
{"city": {"$in": ["hangzhou", "shanghai"]}},
{"height": {"$in": ["1024"]}}
]
} \
--top-k 5返回示例
{
"results": [
{
"Key": "fd91808c-8d7c-480e-a72b-2bfa7d313a80",
"metadata": {
"OSS-VECTORS-EMBED-SRC-CONTENT-TYPE": "IMAGE",
"author": "admin",
"city": "hangzhou",
"OSS-VECTORS-EMBED-SRC-CONTENT": "狗狗",
"height": "1024",
"OSS-VECTORS-EMBED-SRC-LOCATION": "./images/photo.jpg"
}
},
{
...
],
"summary": {
"queryType": "text",
"model": "multimodal-embedding-v1",
"index": "my-index",
"resultsFound": 5,
"queryDimensions": 1024
}
}6.构建可视化检索界面
为了更直观地展示检索效果,可使用 Gradio 构建一个简单的 Web 界面,提供一个包含文本输入、条件过滤和图片结果展示的交互式检索界面。
安装 Web UI 框架
pip install gradio==5.44.1将以下代码保存为 gradio_app.py
# -*- coding: utf-8 -*-
import json
import logging
import os
import alibabacloud_oss_v2 as oss
import alibabacloud_oss_v2.vectors as oss_vectors
import dashscope
import gradio as gr
from PIL import Image
from dashscope import MultiModalEmbeddingItemText
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class Util:
access_key_id = os.environ.get('oss_test_access_key_id')
access_key_secret = os.environ.get('oss_test_access_key_secret')
region = os.environ.get('oss_test_region')
account_id = os.environ.get('oss_test_account_id')
cfg = oss.config.load_default()
cfg.credentials_provider = oss.credentials.StaticCredentialsProvider(access_key_id, access_key_secret)
cfg.region = region
cfg.account_id = account_id
client = oss_vectors.Client(cfg)
vector_bucket_name = "my-test-2"
vector_index_name = "test1"
dimension = 1024
@staticmethod
def embedding(text) -> list[float]:
return dashscope.MultiModalEmbedding.call(
model="multimodal-embedding-v1",
input=[MultiModalEmbeddingItemText(text=text, factor=1.0)]
).output["embeddings"][0]["embedding"]
@staticmethod
def query_text(text: str, top_k: int = 5, city: list[str] = None, height: list[str] = None, return_meta: bool = True, return_distance: bool = True) -> list[tuple[Image.Image, str]]:
logger.info(f"search text:{text}, top_k:{top_k}, city:{city}, height:{height}")
sub_filter = []
if city is not None and len(city) > 0:
sub_filter.append({"city": {"$in": city}})
if height is not None and len(height) > 0:
sub_filter.append({"height": {"$in": height}})
if len(sub_filter) > 0:
filter_body = {"$and": sub_filter}
else:
filter_body = None
result = Util.client.query_vectors(oss_vectors.models.QueryVectorsRequest(
bucket=Util.vector_bucket_name,
index_name=Util.vector_index_name,
query_vector={
"float32": Util.embedding(text)
},
filter=filter_body,
top_k=top_k,
return_distance=return_distance,
return_metadata=return_meta,
))
gallery_data = []
current_dir = os.path.dirname(os.path.abspath(__file__))
# 前端展示依赖本地图片文件,请确保已按仓库结构准备图片资源:
# - 默认使用文末仓库内 data/photograph/ 目录下的图片,前端会读取并展示其中的文件;
# - 如需使用自己的图片,可将图片放入其他目录,并修改下方 path 指向该目录。
for vector in result.vectors:
file_path = os.path.join(current_dir, "data/photograph/", vector["key"])
img = Image.open(file_path)
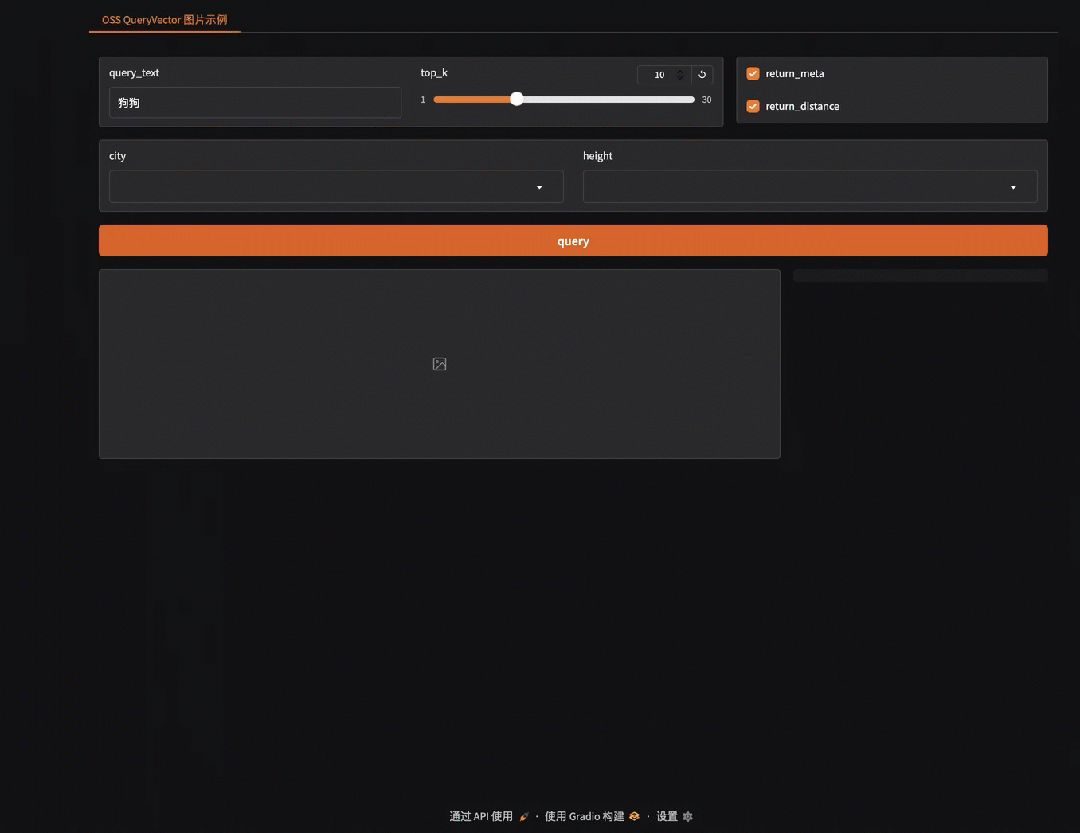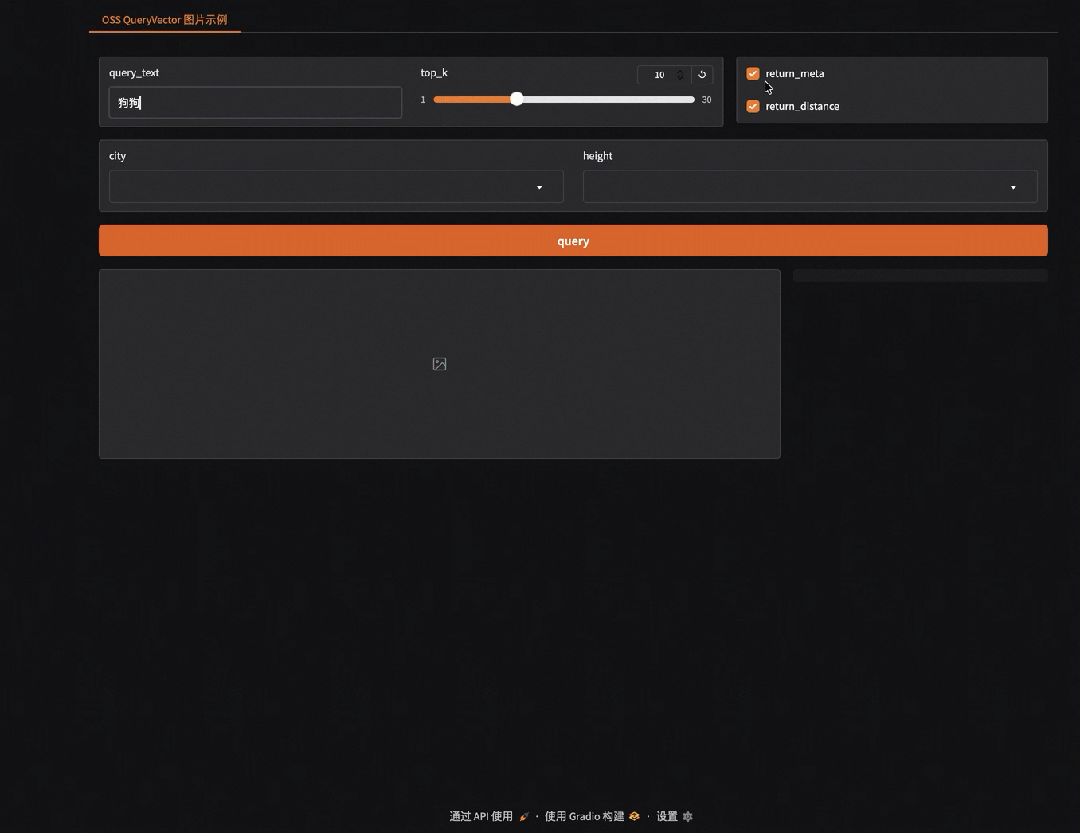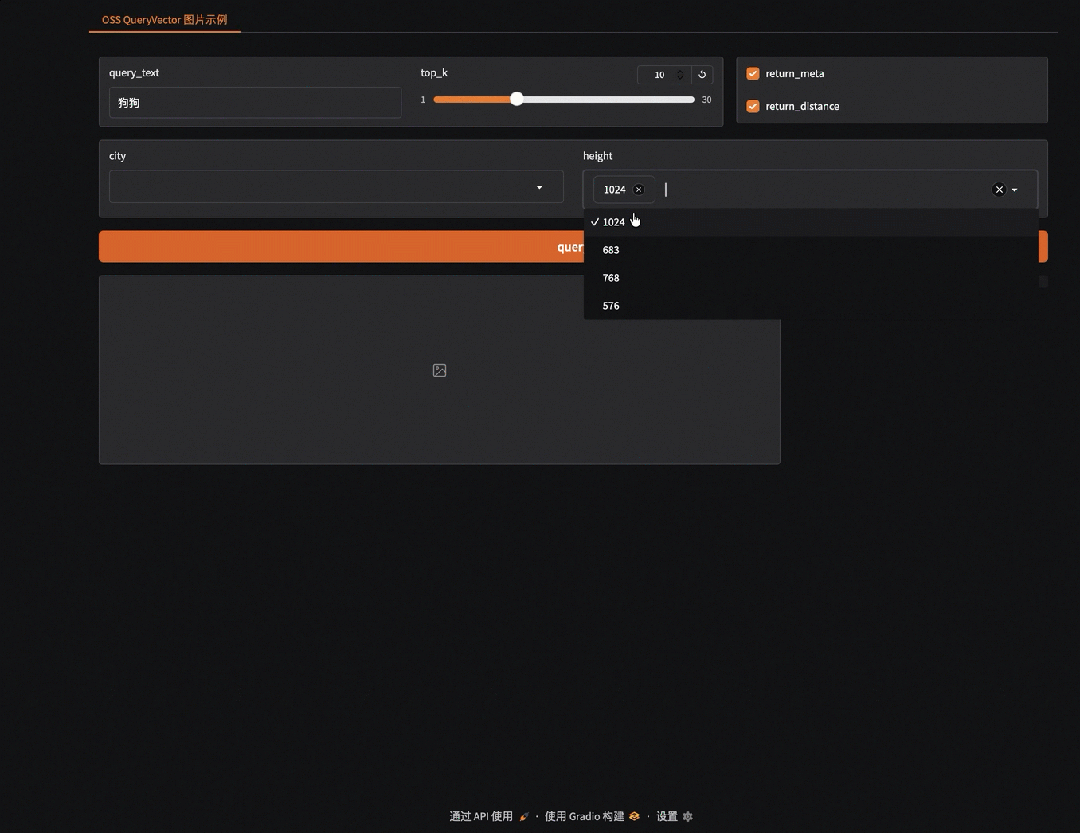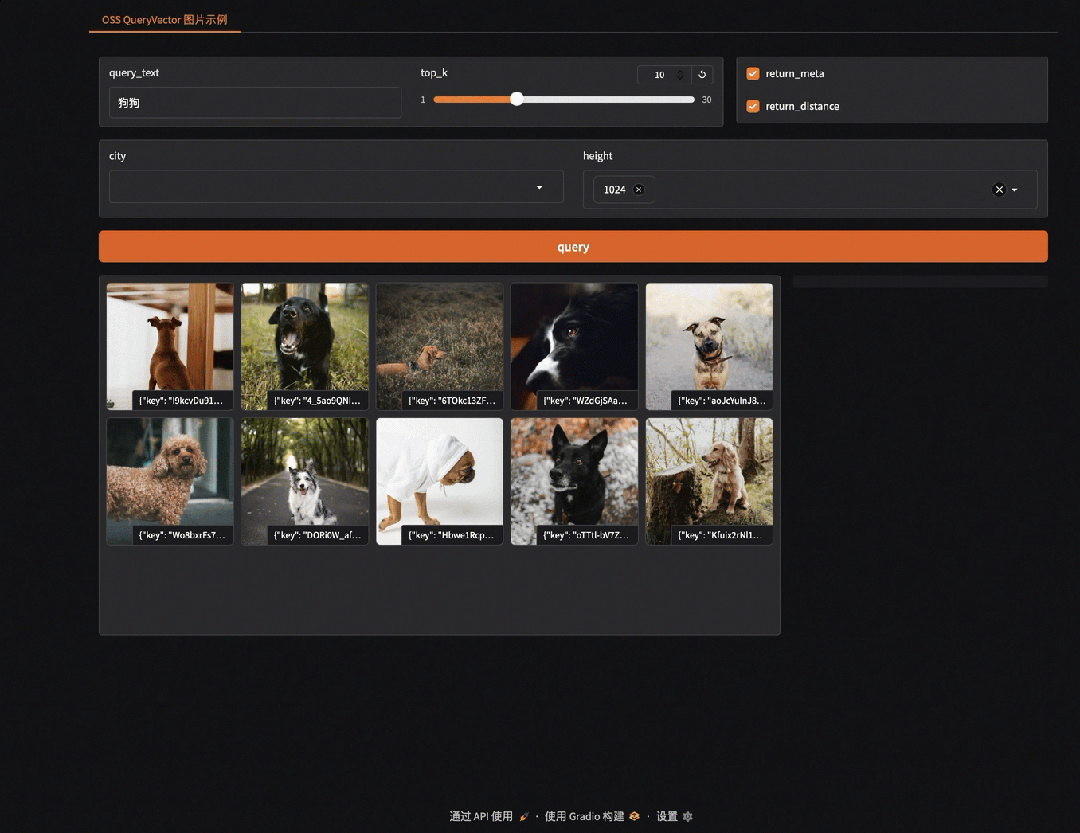
gallery_data.append((img, json.dumps(vector)))
ret = gallery_data
logger.info(f"search text:{text}, top_k:{top_k}, request_id:{result.request_id}, ret:{ret}")
return ret
@staticmethod
def on_gallery_box_select(evt: gr.SelectData):
result = ""
img_data = evt.value["caption"]
img_data = json.loads(img_data)
for key in img_data:
img_data_item = img_data[key]
if type(img_data_item) is str:
img_data_item = img_data_item.replace("\n", "\\n").replace("\t", "\\t").replace("\r", "\\r")
if type(img_data_item) is dict:
for sub_key in img_data_item:
img_data_item[sub_key] = img_data_item[sub_key].replace("\n", "\\n").replace("\t", "\\t").replace("\r", "\\r")
result += f' - **{sub_key}**: {img_data_item[sub_key]}\r\n'
continue
result += f' - **{key}**: {img_data_item}\r\n'
return result
with gr.Blocks(title="OSS Demo") as demo:
with gr.Tab("OSS QueryVector 图片示例") as search_tab:
with gr.Row():
query_text_box = gr.Textbox(label='query_text', interactive=True, value="狗狗")
top_k_box = gr.Slider(minimum=1, maximum=30, value=10, step=1, label='top_k', interactive=True)
with gr.Column():
return_meta_box = gr.Checkbox(label='return_meta', interactive=True, value=True)
return_distance_box = gr.Checkbox(label='return_distance', interactive=True, value=True)
with gr.Row():
city_box = gr.Dropdown(label='city', multiselect=True, choices=["hangzhou", "shanghai", "beijing", "shenzhen", "guangzhou"])
height_box = gr.Dropdown(label='height', multiselect=True, choices=["1024", "683", "768", "576"])
with gr.Row():
query_button = gr.Button(value="query", variant='primary')
with gr.Row():
with gr.Column(scale=8):
gallery_box = gr.Gallery(columns=5, show_label=False, preview=False, allow_preview=False, visible=True, show_download_button=False)
with gr.Column(scale=2):
with gr.Row(variant="panel"):
md_box = gr.Markdown(visible=True, elem_classes="image_detail")
gallery_box.select(Util.on_gallery_box_select, [], [md_box])
query_button.click(
Util.query_text,
inputs=[
query_text_box,
top_k_box,
city_box,
height_box,
return_meta_box,
return_distance_box
],
outputs=[
gallery_box,
],
concurrency_limit=1,
)
if __name__ == "__main__":
demo.launch(server_name="0.0.0.0", server_port=7860)启动界面
python gradio_app.py启动成功后,访问 http://localhost:7860 即可使用检索界面。如检索示例:输入"狗狗",即可返回包含狗的图片。
更多参考
- OSS 向量 Bucket 功能介绍:https://help.aliyun.com/zh/oss/user-guide/overview-vector-bucket
-
OSS-Vectors-Embed-CLI 命令行工具介绍:https://help.aliyun.com/zh/oss/user-guide/oss-vectors-embed-cli

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)