多模态特征融合完全是发文密码!易创新,轻松冲击双1区TOP刊!
多模态特征融合研究前沿:本文综述了多模态AI领域的最新进展,重点介绍了三种创新方法。MUFASA模型通过标题引导的多模态融合和稀疏注意力机制,解决了长序列推荐难题;CVPR2025研究系统分析了视觉特征融合的最佳实践,提出了层级选择黄金法则;ICCV2025的ProtoMM框架利用最优传输实现测试时自适应,动态更新多模态原型。这些工作共同推动了跨模态深层关联挖掘、计算效率优化和动态适应能力的发展,
多模态特征融合已是AI领域的绝对主流,顶会论文层出不穷。
研究早已从简单的特征拼接,演进到基于Transformer的跨模态交互。CLIP等工作的成功,更是将焦点锁定在模态间深层关联的挖掘上,其核心就是实现“1+1>2”的协同增益。
可以说,当前顶会成果大多围绕融合机制的革新展开。除此之外,动态鲁棒性(处理模态缺失)、轻量化以及可解释性,都是极具潜力的研究切入点。建议先剖析几篇经典的交互范式,对快速找到自己的创新点大有裨益。
如果毫无思路,那可以先看看我备好的13篇 多模态特征融合论文合集,有助于快速找到idea。
Multimodal Fusion And Sparse Attention-based Alignment Model for Long Sequential Recommendation
-
关键词: 多模态推荐, 序列推荐, 稀疏注意力, 多模态融合
- 方法:
-
在长序列推荐场景中,如何有效融合跨类型、多模态的物品信息(如帖子、新闻、短视频),并高效地从用户冗长的行为序列中挖掘多粒度的兴趣偏好,一直是个巨大挑战。为此,论文提出了名为 MUFASA 的解决方案。其核心架构包含两大组件:一是多模态融合层(MFL) ,它天才般地以物品标题作为语义锚点,通过四重联合损失函数(标题引导的对比学习、协同过滤引导等)将不同模态和类型的内容强制对齐到统一的语义空间;二是稀疏注意力引导的对齐层(SAL) ,它将用户行为序列划分为“兴趣块”,结合窗口、块级和选择性注意力,分层、多粒度地捕捉用户短期、长期及核心兴趣,完美解决了全注意力机制的计算瓶颈和噪声问题。
-
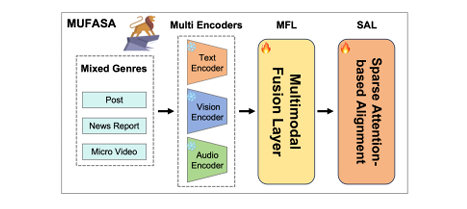
- 创新点:
-
提出了一个以标题为锚点的多模态融合层(MFL)和四重联合优化目标,实现了跨模态、跨类型的深度语义对齐和表示增强。
-
创新地将用户行为序列抽象为“兴趣块”,并设计了包含窗口、块级、选择性注意力的稀疏注意力对齐层(SAL),解决了长序列兴趣建模中的计算复杂度和噪声干扰问题。
-
通过块级注意力机制,将长序列偏好建模的计算复杂度从O(L²)显著降低到O(B²),其中B为兴趣块数量,远小于序列长度L。
-
首次将多粒度稀疏注意力与多目标优化的多模态融合级联,在真实工业场景中验证了其在提升推荐准确性和冷启动性能方面的有效性。
-

Multi-Layer Visual Feature Fusion in Multimodal LLMs: Methods, Analysis, and Best Practices
-
来源:CVPR 2025
-
关键词: 多模态大语言模型, 视觉特征融合, 层级选择, 融合策略
- 方法:
-
现有的多模态大模型(MLLMs)在融合视觉特征时,对于“选择哪些层级的视觉特征”以及“如何将它们与语言模型融合”这两个关键问题缺乏系统性研究,设计选择往往是随意的,如同“盲人摸象”。这篇论文没有提出一个新模型,而是做了一件更伟大的事:它构建了一套系统的研究框架。该研究将视觉特征融合问题分解为两大维度:在层级选择上,提出了基于“表征相似度”(分为初、中、末三个阶段)的划分标准;在融合策略上,提出了基于“融合位置”(外部输入vs.内部注入)和“融合模式”(模块化vs.直接融合)的分类法。通过对这些组合策略进行地毯式实验,最终总结出了该领域的“黄金法则”。
-
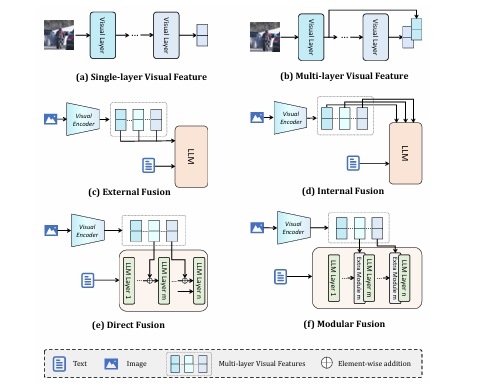
-
创新点:
-
首次构建了一个系统性的MLLM视觉特征融合研究框架,通过对层级选择和融合策略进行解耦和组合实验,为该领域提供了清晰的最佳实践指导。
-
创新地引入“表征相似度”作为视觉层级划分依据,发现从不同表征阶段(初、中、末)各取一个代表性特征的组合效果最佳,解决了盲目选择多层特征导致性能下降的问题。
-
通过系统性对比,验证了“外部直接融合”(如在输入端直接相加)策略在大多数情况下性能最优且稳定,避免了引入复杂融合模块带来的额外参数和训练不稳定性。
-
首次系统性地对比了内部/外部、模块化/直接融合四大范式,实验验证了“外部直接融合”策略具有最强的泛化性和稳定性,是融合多层视觉特征的首选方案。
-
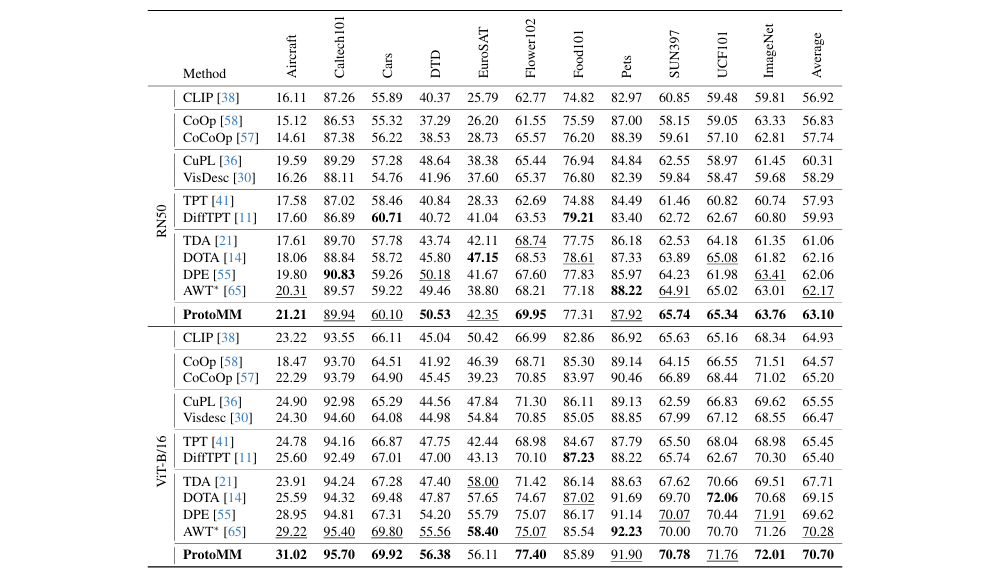
Dynamic Multimodal Prototype Learning in Vision-Language Models
-
来源:ICCV 2025
-
关键词: 视觉语言模型, 测试时自适应, 多模态原型, 最优传输
- 方法:
-
CLIP这类视觉语言模型在处理语义模糊的类别(如“剑兰”vs“黑莓百合”)时常常“犯迷糊”,因为它们的类别原型完全依赖于文本。为了解决这一问题,论文提出了一个免训练的测试时自适应框架 ProtoMM。其核心思想是,将每个类别原型视为一个由“文本描述”和“视觉粒子”构成的多模态离散分布。最妙的是,随着测试数据的不断输入,ProtoMM会动态地从高置信度的测试样本中“捕获”视觉特征,并用其更新“视觉粒子”。这个过程通过最优传输(OT)来智能地度量图文语义距离并加权更新,让类别原型在测试中“边看边学”,变得越来越精准。
-
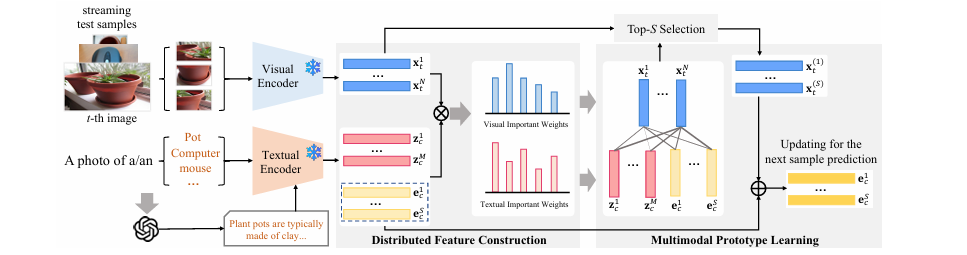
- 创新点:
-
提出了一个动态多模态原型学习框架(ProtoMM),通过在测试时融合实时视觉信息,实现了对视觉语言模型的免训练自适应增强。
-
创新地将类别原型建模为文本与视觉粒子的混合分布,并通过动态更新视觉粒子,解决了仅依赖文本原型时因类名语义模糊而导致的分类性能瓶颈。
-
通过将图文匹配问题建模为最优传输(OT)问题,并使用高效的Sinkhorn算法求解,实现了对测试样本和多模态原型之间复杂语义关系的量化度量和高效匹配。
-
首次将在测试时动态更新的视觉缓存(视觉粒子)与基于最优传输的语义对齐相结合,在15个基准测试上验证了其持续学习和提升模型泛化能力的有效性。
-
如果毫无思路,那可以先看看我备好的13篇 多模态特征融合论文合集,有助于快速找到idea。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)