从LLM到Agent:大语言模型核心概念指南
领域知识(Prompt 模板、Few-shot 示例)工具集(Tools/Resources)执行流程(Workflow/State Machine)记忆模式(该领域的上下文管理)AI系统传统软件类比作用LLM推理引擎/解释决定下一步做什么Token字符/单词大模型处理的最基本单元Context运行时内存当前可见信息RAG数据库查询提供外部数据PromptCLI输入/参数用户输入Tool函数执行具
文章目录
一、LLM
大语言模型(Large Language Model, LLM)是能够理解、生成和推理人类语言的人工智能,其能力源于对海量文本数据的学习。
当前主流的大模型,普遍以 Transformer 神经网络架构 为技术核心
那么他是怎么工作的呢?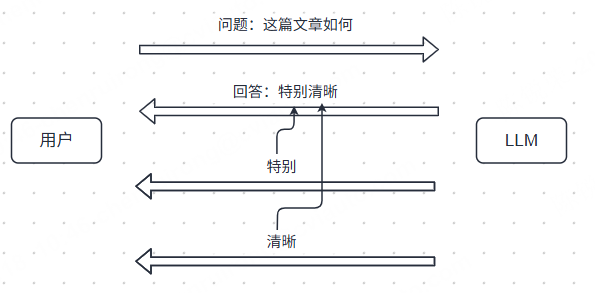
接收输入:您输入“这篇文章如何?”模型将其转换为一系列数字标记(Token)。
首次预测:模型基于您的整个问题,计算出一个概率分布,并从中采样(或选择概率最高的)生成第一个词,比如“特别”。
循环生成:模型会将您的问题 + 它自己刚生成的“特别”,组合成新的输入序列,再次计算下一个词的概率分布,然后生成“清晰”。
持续扩展:这个过程循环进行:输入 + 已生成的全部文本 -> 预测下一个词 -> 追加到末尾。
终止条件:生成不会无限继续。当模型预测出的下一个词是特定的结束符时,或者达到预设的最大生成长度时,它就会停止。模型并不是“觉得输入完了”,而是“预测到该结束了”。
在每一步,模型计算的是整个序列(您的原始问题 + 它已生成的所有词)的概率分布,但只输出最后一个位置预测的下一个词。这确保了上下文的连贯性。
二、Token
大语言模型(LLM)的核心本质是一个庞大的数学函数(参数矩阵),其内部运行的是纯数字的矩阵运算。它并不直接“理解”或“看见”人类文字。
因此,在与人类交互时,需要一个不可或缺的“翻译官”——即 Tokenizer(分词器/令牌化器)。它主要承担两个关键功能
编码:在输入时,将用户输入的文字(如“这篇文章如何?”)切分成模型认识的片段(Token),并转换成模型能处理的数字序列。
解码:在输出时,将模型计算出的下一个数字,转换回人类可读的文字(如“特别”)。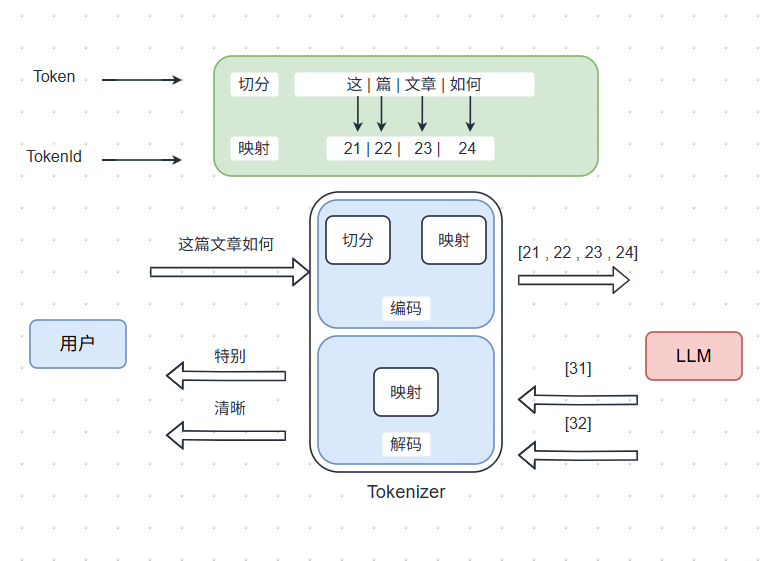
人类输入文字 → Tokenizer编码(文字→数字) → 模型计算(数字→数字) → Tokenizer解码(数字→文字) → 人类看到文字回复。
Token 大模型处理的最基本单元
三、Context
Context(上下文) 是大语言模型在生成每一个词时,所依据的全部已知信息的总和。您可以将其理解为模型当前的“短期记忆”或“思维背景”。
Context 就是指模型在预测下一个词时,所参考的“全部已知信息”。它本质上是一个不断增长的、由Token ID组成的数字序列。
具体来说,它包含两个部分:
初始输入:您的问题(经过Tokenizer编码后的数字序列)。
历史输出:模型自己已经生成的所有词(同样被编码成数字并追加在后面)。
核心作用与特点:
决定生成内容:模型每一步的预测,都基于当前整个Context序列进行计算。就像我们说话要考虑之前说过的所有话一样,模型依靠完整的Context来保证回复的连贯性、相关性和逻辑性。
有长度限制:所有模型都有一个固定的 “上下文窗口” 大小(例如 4K、8K、128K Tokens)。这意味着Context序列的长度不能超过这个限制。当对话或文本超过这个长度时,最早的信息会被“挤出”窗口,模型就会“忘记”它们。
技术实现:模型通过 “注意力机制” 来有效处理Context。这个机制允许模型在预测时,动态地“关注”Context序列中不同位置、不同重要性的信息,而不是平等地看待每一个词。
一个简单的比喻:
把大模型生成回答想象成您正在写一篇文章。 Context 就是您面前已经写好的所有文字(包括最初的提纲和您刚写完的句子)。
您写下一个句子时,必须反复阅读前面已经写好的所有内容(Context),才能保证文章前后一致、逻辑通顺。
您的短期记忆容量是有限的(上下文窗口),如果文章太长,您可能就记不清开头的具体细节了。
因此,Context是大模型实现连贯对话和多轮推理能力的根本基础。它的长度和质量直接决定了模型处理复杂任务(如长文档分析、长篇对话、代码编写)的上限。
Context Window
Context Window 是大语言模型单次处理时,其 Context(上下文) 所能容纳的最大 Token(词元)数量。它是模型核心能力的一个关键硬性指标,直接决定了模型“短期记忆”的容量。
您可以将其形象地理解为模型的 “工作记忆白板” 或 “实时信息缓冲区” 的大小。
为什么上下文窗口如此重要?
它从根本上限制了模型能处理的任务复杂度:
长文档处理:能否一次性读完一整本书、一份长篇报告或一篇学术论文进行分析。
多轮对话:能否在长达数小时或数天的对话中,始终保持对早期讨论内容的记忆,保证对话连贯。
复杂任务执行:能否基于一整个代码库进行编程,或综合多份材料进行创作、推理和总结。
信息完整性:窗口越大,模型在生成回复时能参考的背景信息就越全面,理论上回复会更准确、相关。
以下是目前主流大语言模型的上下文窗口(Context Window)大小对比
| 模型 | Tokens |
|---|---|
| GPT-4.1 系列 | 1M (100万) |
| Gemini 2.5 Pro / 3 Pro | 1M (100万) |
| DeepSeek | 1M (100万) |
| Qwen 1.5 | 32k |
四、RAG
RAG(检索增强生成)
相当于给大模型配一个“海马体”
你可以把纯大模型想象成一个知识渊博但爱吹牛的小说家。他读过的书(训练数据)都记在脑子里,能滔滔不绝地讲。但有两个毛病:
他只会讲“记忆里”的故事,不知道昨天刚发生的大事。
他分不清哪些是真事,哪些是自己编的情节,经常把两者混在一起讲,还说得特别真。
RAG 就是给这位小说家配了一个高效的“海马体”(大脑中负责记忆检索的部分)—— 一个“图书馆管理员”。

为什么需要RAG
是为了从根本上解决纯大模型的两个关键缺陷,从而让AI系统变得更可靠、更实用。
简单来说,RAG通过“先检索,后生成”的机制,为模型回答注入了准确的事实依据和最新的信息。
-
解决“知识陈旧”问题
纯大模型:它的知识截止于训练数据的时间点(例如2024年7月),无法知晓之后的事件。
RAG:在回答前,会先从你提供的实时数据库(如最新文档、网页、知识库)中检索相关信息。因此,它能回答“昨天股市如何”或“公司最新政策是什么”这类问题。 -
解决“幻觉胡编”问题
纯大模型:基于概率生成文本,容易混淆记忆,编造看似合理但错误的事实、引用或数据。
RAG:将生成过程锚定在检索到的真实文档上。它生成答案时,会严格依据这些文档内容,并可以提供出处。这大幅提升了答案的可信度和可验证性。
RAG如何工作
RAG 的三步工作法
当你想问这个“组合”一个问题时,流程是这样的:
第一步:提问
你问:“上次财报会议上,CEO提到明年最重要的战略方向是什么?”
第二步:检索(图书馆管理员的工作)
小说家(大模型)自己不知道答案,因为他没“参加”会议。
但他的“管理员”(检索系统)立刻行动,跑进一个实时更新的、可信任的专属档案库(知识库,里面有你公司的所有会议纪要、财报文件)。
管理员用最快的速度,找到和你的问题最相关的几段原文,比如财报会议记录的第3-5页。
第三步:生成(小说家在新规则下的工作)
管理员把找到的这几页原文,和你的问题钉在一起,递给小说家,并命令他:“严格根据我给你的这几页纸上的内容,回答用户的问题。不准自己瞎编!”
小说家看了这几页原文,心里有底了。他发挥自己组织语言、总结归纳的强项,把原文信息转换成流畅的答案:
“根据您公司2026年Q1财报会议记录第4页,CEO明确指出的明年核心战略是‘All in AI Agent’。具体包括:1. … 2. … (此处信息均来自提供的原文)”
最后,他还可以告诉你:“以上信息来源于《2026-Q1-Earnings-Call.pdf》第4页。”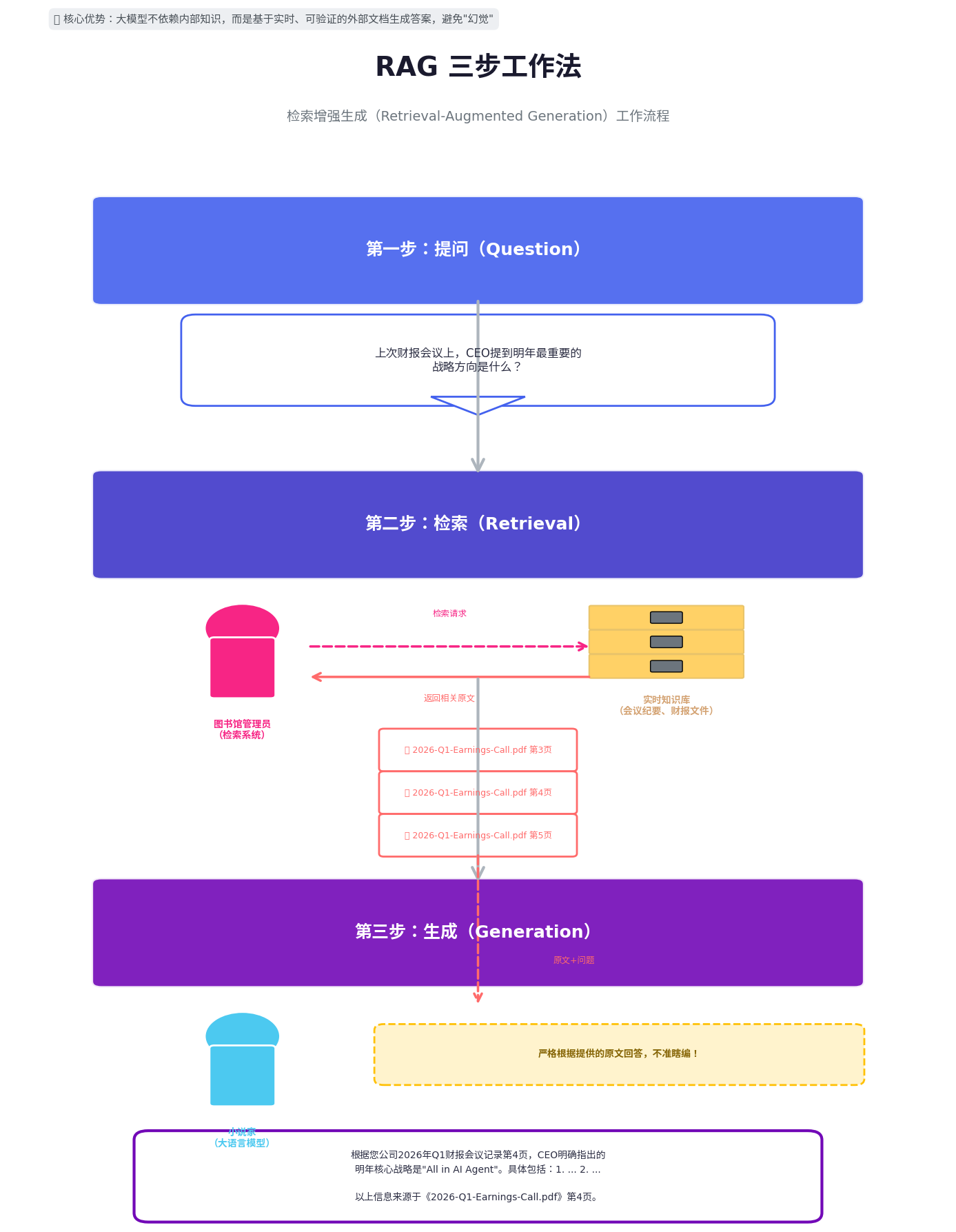
五、Prompt
Prompt 是你与大语言模型(LLM)沟通时输入的指令或问题。它是告诉模型"你想要什么"的桥梁。
Prompt 的质量直接决定了输出的质量——好的 Prompt 能让模型给出精准、有用的回答;模糊的 Prompt 则可能导致答非所问。
与大语言模型对话时,许多人习惯于直接抛出需求:
“帮我写一封信”
这种单一层级的指令往往导致输出平庸——缺乏个性风格、忽视边界约束、格式随机不可控。
问题的根源在于:我们将"是谁在回答"、“怎么回答”、"回答什么"这三个维度混为一谈。
优秀的 Prompt 设计应当像导演指导演员:先确立角色内核,再规定表演方法,最后给出具体台词。这就引申出了 System Prompt 与 User Prompt 分层协作的概念。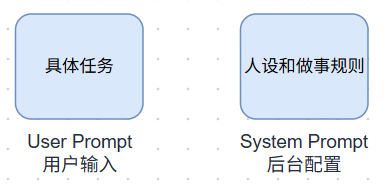
一个完整的 Prompt 结构 = 人设 + 规则 + 任务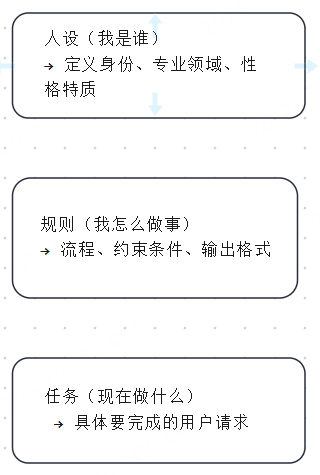
例如:
场景 1:代码审查助手
❌ 只有 User Prompt(效果差)
帮我看看这段 RecyclerView 代码有没有问题
问题:模型不知道你的代码规范、项目架构(MVVM?MVP?)、Kotlin/Java 偏好,回答可能泛泛而谈。
✅ System + User Prompt(专业级输出)
System Prompt:
【人设】
你是一位有8年经验的Android技术负责人,专注于性能优化和代码规范性审查。
【代码审查规则】
1. 审查维度(必须覆盖):
- 性能:是否存在内存泄漏、过度绘制、主线程阻塞
- 架构:是否符合MVVM分层,Repository模式使用是否规范
- Kotlin特性:是否善用空安全、扩展函数、协程(避免回调地狱)
- Android最佳实践:是否使用ViewBinding、DiffUtil、Paging3等现代组件
2. 输出格式:
- 🔴 严重问题:可能导致Crash或明显卡顿
- 🟡 建议优化:影响可维护性或性能隐患
- 🟢 良好实践:值得保持的写法
- 每个问题必须给出:问题描述 → 具体代码位置 → 修改建议(含代码片段)
3. 语言风格:
- 技术术语准确,但避免过度学术化
- 对初级开发者友好,关键概念简要解释
- 不假设第三方库版本,询问时默认使用最新稳定版
【禁止事项】
- 不审查UI美观度(只关注代码层面)
- 不推荐未经过生产环境验证的实验性API
- 不做"必须重构"的绝对判断,优先给出渐进式优化方案
User Prompt:
项目:电商App商品列表页
架构:MVVM + Repository + Hilt依赖注入
语言:Kotlin 100%
代码片段:
[粘贴你的Adapter代码]
请重点检查:列表滑动卡顿问题和内存泄漏风险
输出效果:模型会自动带上"技术负责人"的视角,按你规定的维度逐条审查,甚至主动询问是否使用了 ListAdapter 或 Paging。
六、Tool
想象一位学识渊博的教授,但他被关在一个没有窗户的房间里,房间里只有截止到某个时间点的书籍和资料。
| 能力 | 局限 |
|---|---|
| ✅ 懂编程、会写作、能推理 | ❌ 不知道今天的天气 |
| ✅ 记得2024年前的公开知识 | ❌ 查不到实时股价 |
| ✅ 能分析你输入的文本 | ❌ 无法读取你的本地文件 |
| ✅ 会解数学题 | ❌ 不能真的执行代码验证结果 |
这就是大模型的本质:它是一个纯文本预测机器,只能基于训练时的静态数据生成回答。它没有眼睛、没有手、不能联网、不能执行代码——除非你给它"装上工具"。
Tool(工具) 是连接大模型与外部世界的桥梁。它让模型能够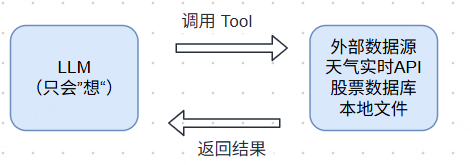
核心逻辑:
用户问了一个需要外部数据的问题
模型判断:“我需要调用某个 Tool”
系统执行 Tool,获取真实数据
模型基于真实数据生成最终回答
Tool的本质 就是给大模型提供一个外部感知的工具
七、MCP
MCP(Model Context Protocol,模型上下文协议)
MCP是什么?
MCP(Model Context Protocol) 是一个开放标准协议,定义了 AI 模型如何安全地连接外部数据源和工具。
为什么需要MCP
当前 Agent 开发的痛点
假设你开发了三个 AI Agent,分别需要连接不同的数据源:
| Agent | 需要连接 | 开发成本 |
|---|---|---|
| 代码助手 | GitHub、本地文件、Jira | 写 3 套适配代码 |
| 数据分析助手 | 数据库、Excel、BI 系统 | 再写 3 套适配代码 |
| 运维助手 | K8s、AWS、Prometheus | 又写 3 套适配代码 |
问题:每个工具都要为每个 Agent 单独开发适配层,N 个工具 × M 个 Agent = N×M 的复杂度。
MCP 就是为了统一AI工具接口定义MCP 的核心思想:就像 USB-C 统一了充电接口,MCP 统一了 AI 与外部工具的连接协议。
八、Agent
之前我们讲了 Tool 是"给模型装上工具"。但仅仅有工具还不够——模型需要知道什么时候该用哪个工具。
| 阶段 | 状态 | 类比 |
|---|---|---|
| 纯大模型 | 只有脑子,没有手 | 只会说的顾问 |
| 大模型 + Tool | 有手,但需要人递工具 | 技工,你说"用扳手"他才用 |
| Agent | 自己判断用什么工具、按什么顺序用 | 独立解决问题的工程师 |
Agent 的核心作用:从"回答问题"到"完成任务"
举一个天气查询例子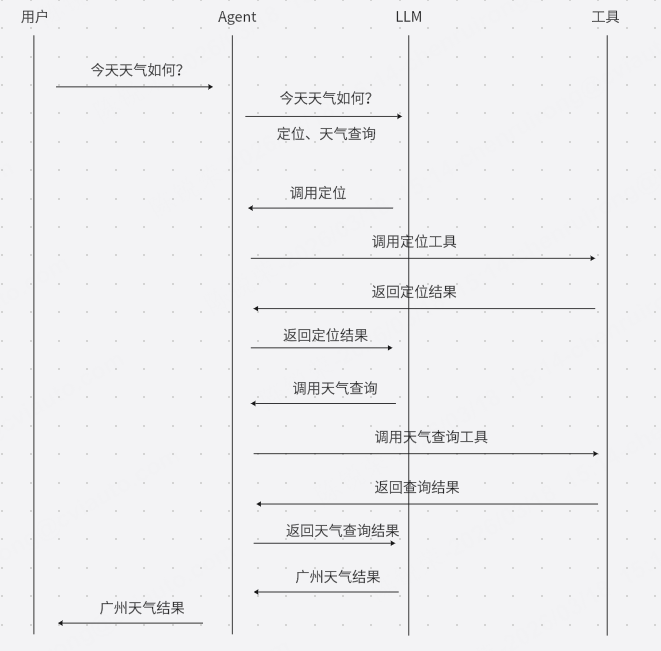
Agent = 大模型(大脑)+ 工具集(手脚)+ 自主规划能力(灵魂)
它不是被编程的固定流程,而是被赋予目标后,能自主思考、自主行动、自主纠偏的智能体。
就像你给一位资深助理说"帮我安排明天出差",他会自己查航班、订酒店、看天气、提醒你带伞——而不需要你一步步指挥。
九、Agent Skill
Agent Skill(智能体技能) 指的是一个AI智能体(Agent)所具备的、用于完成特定目标任务的独立能力模块。它不仅仅是调用一个工具,而是一套包含目标理解、规划、工具调用、信息处理和结果输出的完整解决方案。
你可以将其理解为智能体的“职业技能包”。一个强大的智能体通常由多个技能组合而成,以应对复杂任务。
1、什么是Agent Skill
Agent Skill(智能体技能) 是 Agent 的模块化能力单元,封装了特定领域完成特定任务所需的全部要素:
- 领域知识(Prompt 模板、Few-shot 示例)
- 工具集(Tools/Resources)
- 执行流程(Workflow/State Machine)
- 记忆模式(该领域的上下文管理)
2、为什么需要 Agent Skill?
2.1 当前 Agent 开发的痛点
假设你正在开发一个全能型 AI 助手,它需要帮助用户完成各种任务:
| 场景 | 需要的工具 | 需要的知识 | 需要的流程 |
|---|---|---|---|
| 写 Android 代码 | IDE、Git、Gradle | Kotlin、架构模式 | 分析→编码→测试→提交 |
| 订外卖 | 美团 API、支付接口 | 用户地址、口味偏好 | 选餐厅→选菜→下单→追踪 |
| 分析股票 | 金融数据 API、图表工具 | 财务指标、技术分析 | 获取数据→计算→可视化→建议 |
| 写 PPT | 幻灯片软件、图片搜索 | 排版原则、演讲结构 | 大纲→素材→制作→美化 |
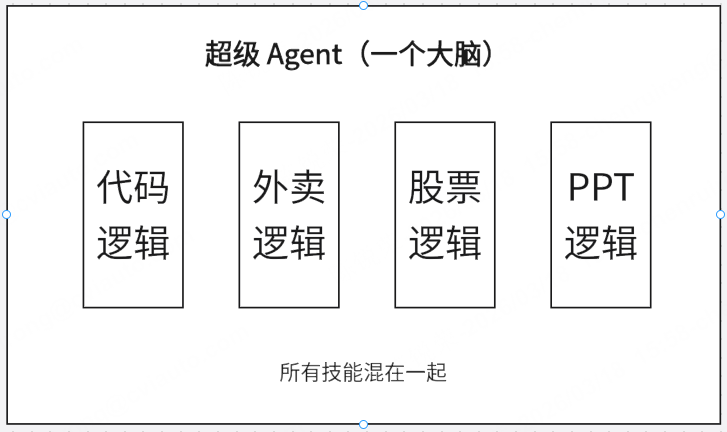
❌ 提示词爆炸:System Prompt 要涵盖所有领域,长度超限
❌ 上下文污染:聊股票时带着外卖的 Tool 定义,干扰决策
❌ 维护困难:改外卖逻辑可能影响代码生成
❌ 无法复用:每个项目重写一遍"订外卖"能力
❌ 协作困难:多个开发者改同一个 Agent,冲突频发
2.2 Agent Skill 的解决方案
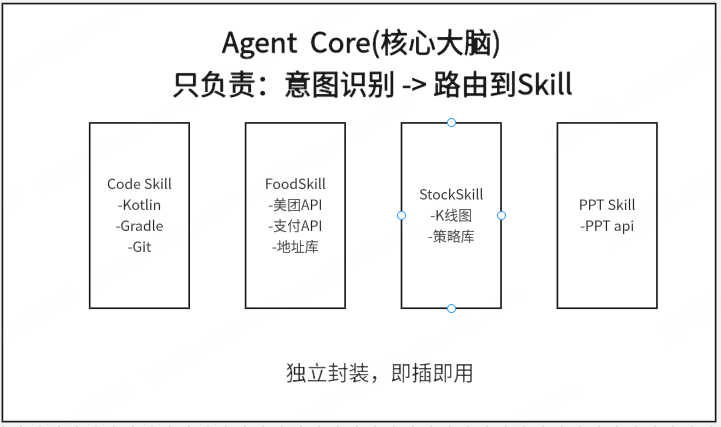
✅ 按需加载:聊代码只加载 CodeSkill,上下文精简
✅ 独立维护:每个 Skill 独立开发、测试、部署
✅ 复用共享:FoodSkill 可以给任何 Agent 用
✅ 团队协作:A 组写代码,B 组写外卖,互不干扰
✅ 安全隔离:Skill 崩溃不影响核心 Agent
十、总结
| AI系统 | 传统软件类比 | 作用 |
|---|---|---|
| LLM | 推理引擎/解释 | 决定下一步做什么 |
| Token | 字符/单词 | 大模型处理的最基本单元 |
| Context | 运行时内存 | 当前可见信息 |
| RAG | 数据库查询 | 提供外部数据 |
| Prompt | CLI输入/参数 | 用户输入 |
| Tool | 函数 | 执行具体操作 |
| MCP | API规范 | 统一调用协议 |
| Agent | 控制器/workflow | 调度工具与技能 |
| Agent Skill | 软件库/包 | 实现一个复杂目标的任务模块(如天气查询) |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)