我用 Seedance 月标套餐只做了 80 秒视频?从产品体验到视频生成模型原理
体验完即梦友好的产品外壳后,真正的挑战才刚刚开始。虽然优秀的 GUI 设计和工作流引导帮我们规避了不少入门的麻烦,但在长达几天、消耗了几百积分的“抽卡”博弈中,我不可避免地撞上了大模型底层的那些“法则”。为什么有的要求无论怎么调提示词都会崩坏?为什么画面里一个小小的水印会像病毒一样遗传?接下来,我将暂时抛开产品的表象,从这段“痛苦”的实操经验中,总结几个在视频生成中极其反直觉、却又必须遵循的底层规
上手玩耍
上个月,即梦AI的 seedance2.0 模型比较火热,我也充了一个月度会员(以及最开始的一元首充)来尝试完成两个视频给高中老师拿去当上课素材。
价格惊人
首先来说说价格。
3 月 4 日消息,字节火山引擎官网日前公布了
Doubao-Seedance-2.0模型的定价标准,包含视频输入(视频编辑)是 28 元 / 百万 tokens,不含视频输入(纯视频生成)的价格是 46 元 / 百万 tokens。Seedance 2.0 是字节豆包大模型团队推出的新一代多模态创作视频模型,支持图像、视频、音频等多种模态作为参考输入生成视频。在 Seedance 2.0 生成 15 秒视频,大概需要消耗 30.888 万 tokens。以此计算,纯视频生成(不含视频输入)的价格大约为 1 元 1 秒。
当然这个是API调用的费用,按量计费的挺清楚的,但是对于普通GUI的用户,我们购买的更多是提供的套餐选项。
而购买会员套餐的单月价格如下,当然连续按月买和连续按年买是有优惠的。计价也是国内常用的“积分”模式。相比 token 模式可能一定程度上更直观,争议更小,但是同时也更加黑盒,定价更加不透明。
大模型调用API和直接使用它客户端的网页GUI产品,在输出质量、使用体验有什么区别吗?如果有,你分别推荐怎样的需求使用对应的产品?
| 维度 | GUI | API |
|---|---|---|
| 使用难度 | 低 | 高 |
| 灵活性 | 低 | 极高 |
| prompt控制 | 弱 | 强 |
| 工具能力 | 产品集成 | 自己实现 |
| 成本 | 订阅 | 按token |
| 适合人群 | 普通用户 | 开发者 |
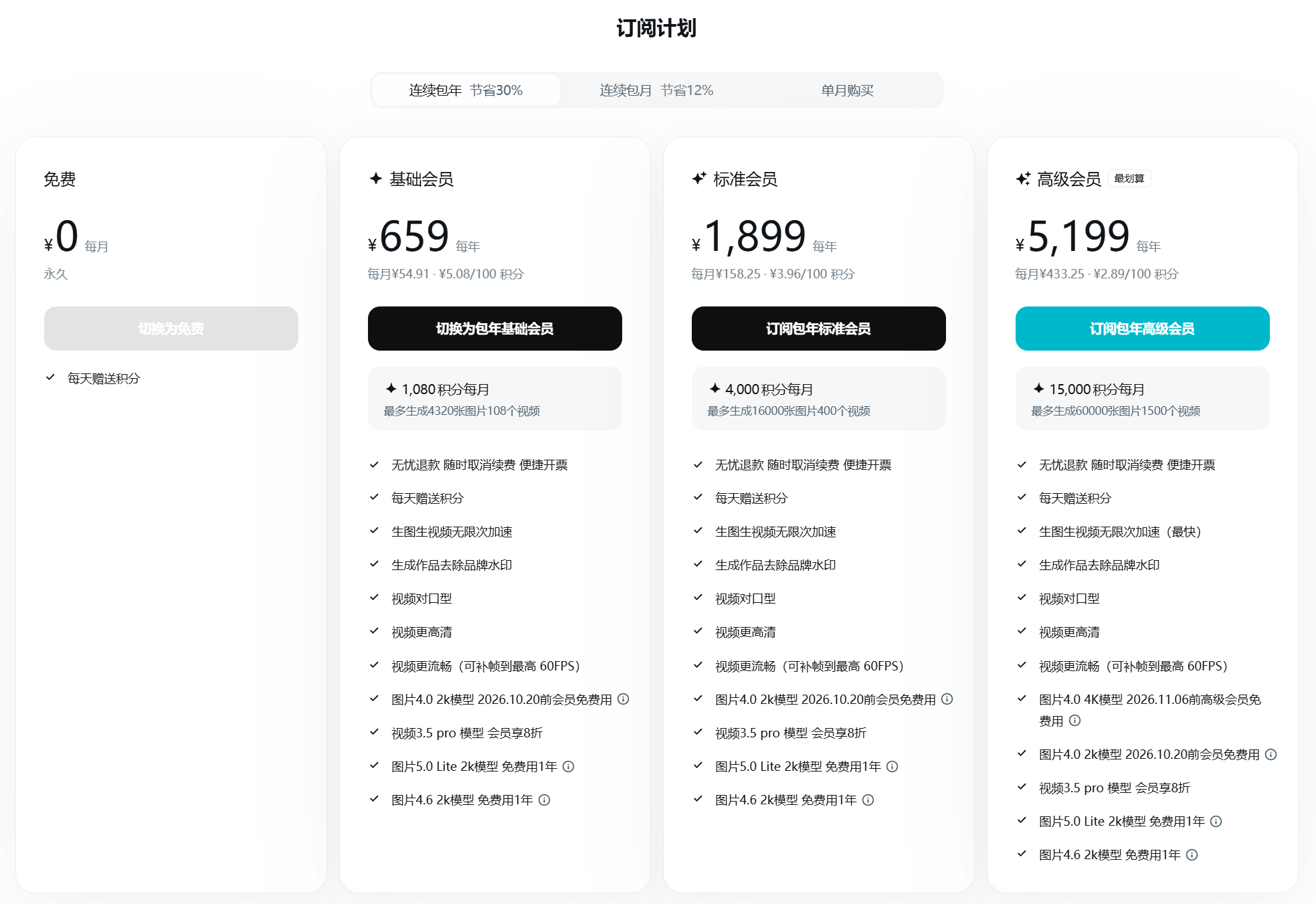
生成图片一般都是免费的,生成视频需要“积分”。这一点还是挺正常的,不存在扰乱市场的行为,毕竟在 Google AI studio ,我们也可以使用到Nano Banana来免费生图,同时也没有免费模型来生视频。
大家可以猜一下我做了了两个 1080p 分别是 42s 和 38s 的视频一共消耗了多少积分,稍后揭晓。
值得一提的是想要下载到本地自己制作的图片和视频没有水印的话是必须要充会员才可以的,以及部分模型是只有充会员后才可以多次使用的。
而生成一个视频所需的最少积分数从 10 到 80 不等,这取决于生成视频的清晰度(部分模型不支持 1080p )、时长,甚至是模式,部分模式下多数模型无法使用。
比如本次重点使用了“智能多帧”的模式,是无法使用最先进的seedance系列模型而仅仅可以使用视频 3.0 和视频 3.0 FAST 的。
生成图片和Nano Banana速度相近,质量不错。生成视频的速度取决于模型和提示词等要求细粒度,写这篇博客当天请求使用 seedance 模型来生成一个 5s 的视频,一直停留在“排队加速中”的界面中,属于是赶上好时候了……
任务本身
尽管是拿来玩耍的一个工具,但是玩耍同时附带的任务也难度较大,到最后也是外加了很多人工的剪辑等操作才完全呈现出合理的效果,即最后共80s的视频是对即梦 AI 生成的多个视频的剪辑。
最后是用到的工具如下:
提示词完善: Gemini 3.1 pro preview
生图:图片 5.0 Lite by Seedream 5.0 Lite ; 图片 4.6 by Seedream 4.6
生视频:视频 3.0 Pro ; 视频 3.5 Pro
生声音: Gemini 2.5 Pro Preview TTS
添加字幕: Arctime
剪辑:剪映专业版
个人工作流:仍然人在回路
script
↓
prompt engineering
↓
image generation
↓
keyframe selection
↓
video diffusion
↓
editing
↓
subtitle alignment
工作流大概是,接收到高中老师发来的搭配视频的文章原文、视频台词信息以及期待的大致运镜效果后,结合Gemini 3.1 pro preview细化生图提示词、运镜提示词、生声提示词等一切提示词,使用提示词生图后,使用“智能多帧”的模式和“首尾帧”的模式来生成视频。在无数次调试后以及需求反馈更新后得到相对满意的视频,在剪辑软件中剪切和拼接,再叠加字幕,使之和画面内容相对应,最后输出交付。
使用Arctime手动加字幕,是因为剪映专业版的加字幕功能比较稚嫩(其实是当时没有找到加一个正常字幕的地方呜呜呜),以及 ChatGPT是这么推荐的。(简单说一下使用体验,很好的是,他会把你自己编辑的字幕文件,即文字和时间的对应关系保存到一个文件里面,所以即使后面需求发生迭代,我也可以在确保声音文件不变的基础上,不调整字幕文件,直接丢进去生成就好了)
而至于为甚没有直接全部让视频模型全程自己输出字幕、声音和视频,一方面是在抖音平台上看到了很多 AI 生成创作的恶搞视频,而其中的字幕往往出现乱码,这在娱乐场景中尚且观感不好,在课堂中使用只会偏移学生的注意力,实在是得不偿失;而另一方面是为了控制成本,之前过年的时候使用多个AI生图工具(Nano banana和千问生图)为父母和为辅导员修改照片中或是字或是人脸的细节,往往要 10 轮以上的详细“调教”才可以勉强达到需求,那么本身对运镜的要求和对内容的契合对视频本身已经很难那达成了,如果同时要求字幕、声音和视频三者同时不出现幻觉,我估量其中涉及到的反复生成所消耗的算力或者叫“积分”会呈几何倍数的上升。
同时在声音层面,人物大段的英文串词使用Gemini 2.5 Pro Preview TTS模型,为了精准和可控,也便于后面重新修改字幕和台词,同时也大大增大解空间,降低难度。但是,即梦 AI 提供了 AI 音效的选项。每个视频,只要时长不过于长,就可以 0 积分免费生成三段带音效的视频,在本次任务中大量的运镜涉及到风、水、等复杂自然元素和全息投影和画卷展开的复杂声音,而音效都出乎意料地很令人满意,并且和画面相得益彰,这个和后面会说到的模型架构“双分支同步生成机制的‘大脑’逻辑”有关。
而即使是在这样的设计下,由于任务本身的高要求,也只剩下 200 左右的积分,在几天内每天登陆会送 60 积分的情况下。生成视频的通过门槛一旦提高,损耗率便会变得惊人,本次任务的损耗率在 20% 左右。平均一个可以使用的视频,背后是五个失败的视频,当然这个只是能用,如果是到整个视频没有任何可以挑刺的片段,那会需要更多得多的次数来祈祷。
产品感知:用户友好的产品设计
Agent 模式
我工作流里的使用 Gemini 辅助修改提示词的部分完全可以去掉,因为自带的 agent 模式就可以一定程度上完成这个工作,帮助用户完成提示词的生成、图片和视频的样例生成。
但是这个似乎不会告诉你这个请求会消耗多少积分,所以在描述提示词的时候还是要足够谨慎。
先生图再生视频的引导设计
我们往往没有直接去生成视频,尽管这样也可以,但是我们被UI设计提示需要一个输入的图片作为一个参考。这样给用户一种更强的可控性和秩序性。在用户体验和模型生成上都更加不“黑箱”。一方面,用户体验会更好,用户可以几乎无限制地生成图片,然后选择一个满意的作为关键帧,让模型来自行生成,或者叫补全剩下的帧;另一方面模型本身生成也可以有更多的来自 image encoder 的输入,这样也让模型的幻觉更少,前面所说的有关文字幻觉的问题即是可以被这样解决,我也觉得短期内只有这样的方法可以在不大幅提高模型或者等待一个专门解决这个问题的模型架构或者模块出现,换言之更低成本的纯软件层面,解决这个问题。
相关问题的经验总结
体验完即梦友好的产品外壳后,真正的挑战才刚刚开始。虽然优秀的 GUI 设计和工作流引导帮我们规避了不少入门的麻烦,但在长达几天、消耗了几百积分的“抽卡”博弈中,我不可避免地撞上了大模型底层的那些“法则”。为什么有的要求无论怎么调提示词都会崩坏?为什么画面里一个小小的水印会像病毒一样遗传?接下来,我将暂时抛开产品的表象,从这段“痛苦”的实操经验中,总结几个在视频生成中极其反直觉、却又必须遵循的底层规律。
基本认知
基于现在的视频生成模型架构的特点,我们可以知道任务的难度主要和对视频要求的精细程度有关。视频的最终解空间越小,对视频的要求越高,生成难度越高。
一定程度上可以说是,越是包容越是简单,越是苛刻越是复杂,但是这两句话的主语不仅是用户本身,更是任务的输入。
当输入的提示词越短,大模型可以发挥的空间就越大,如果用户的要求也如提示词一样“包容”,那么便可以迅速验收,不用反复修正。但是如果提示词过长,过于细节或者用户要求过高,那么便不是一件轻易的事情。
反而,越是简单但是越是和内容高度契合的视频,越是难以被制作,因为这往往意味着解空间的狭窄或者用户的要求不可能低。
例如,在本次任务中,我就觉得这不会是一个简单的任务,注定要多轮尝试,尽管真实的生成过程中还是几经令人崩溃。
文字幻觉
前面说到了我是用手动添加字幕来规避其中可能出现的任何幻觉,但是在视频生成中要是有任何带有艺术字成分的字呢?
其实解决方法很直觉很简单,但是仅靠模型自身很难完成,但是在工程级别仅仅加上一个小组件就可以完成,这个可以由用户自己来设定,这样更个性化,但是字节完全可以让即梦这个“软件”产出更好,而不是仅仅依赖大模型。
自己在最开始也一直局限在“大模型就是生成文字不可避免会有幻觉”“乱码不可规避”的思维定式中,尽管这样的认知在近期是一定程度正确的,但是我们并非只有大模型本身可以解决这个问题。
新华网报道中的图片
参考的生图结果
不参考(包含海昏侯字样的图片)的生图结果
解决大模型不知道这个字怎么写,在 token 映射这一步,象形的文字就变成了抽象的数字,而大模型去模拟这个字本身则难度巨大了,更不必说各种字体大小关系的考量。但是直接告诉他,这个字在图片中是怎样的,直接让图像经过 image encoder 即可,有一种“种花得花、种豆得豆”的感觉。
而不得不说,即梦AI在添加参考图片这一点的软件设计上是极为舒适的,动画是卡牌排列的图片束,靠近打开,远离就聚拢,相比很多大模型的入口,即梦AI真的很好的完成了从大模型到软件的这一步,不是强极客风格的入口,而是真正的AI落地的解决方案和应用范式。
不只是这一点,在很多地方,即梦都做得很好。
画布式的布局也很类似 figma 这样的灵感类软件,像我也是用这个画布大致排布了这样几个区域,来“工作留痕”:视频报废区、视频取用区、关键帧图片区、候选图片区、图片报废区。
水印?
在生成图像的过程中,遇到了一个很奇怪的问题,可能是seedance 2.0在训练的过程中有蒸馏自己家或者别人家的模型,当然也有可能是训练的是互联网上已经被 AI 污染的数据,总之就是原图片没有删掉水印,导致生成图片的过程中产生了水印。但是必须得说的,就我自己的体验来说这个水印并非在最开始就存在,而是在多轮对话中才出现的,但是一旦把这个放入参考图片的行列中,那么便会让与之相关的全部遗传水印。
具体来说,水印产生原因如下。
首先,当然是数据污染,不管这个数据是蒸馏来的还是互联网上来的,几乎必须得提高数据清洗的细粒度,同时也意味着提高成本,也不依赖任何先验的别家的模型才有可能避免这个问题。但是,我们为这个是利在千秋的事情,任何一个互联网厂做了自己的干净的大模型,后面不断结合新的图片来源或者新的训练数据以及蒸馏这个干净的模型都是可以的。
其次, seedance 是基于扩散模型架构的。扩散模型对局部的任何风吹草动都极为敏感。
当时我为了提高这个页面的效果,决定去掉水印,然而在我调高清晰度使用相同的提示词之后,效果怎么都不满意,于是我决定手搓!自己手动使用最基础的“画图”软件来覆盖掉这一块水印,是的,甚至没有使用 photoshop ,感觉初中信息课白学了……
但是也正式这样左上角一块看似不足为奇的部分,让后续使用这张图片作为关键帧的视频仍然出现了一丝不对劲,但是也可以忽略不计,至少不是文字的水印这样吓人。嗯。毕竟花钱买的会员就是为了没有水印啊啊啊啊啊。
再次,前面我所说我是“多部反复生成”才有的,这和前面这一点是类似的,都是基于扩散模型的“遗传效应”。
如果某一轮出现了 微弱的水印残影:模型会把它当作真实视觉特征,下一轮 diffusion 会继续强化这个特征
于是会出现类似遗传效应:
```第一轮:几乎看不见
第二轮:隐约结构
第三轮:明显水印
第四轮:完整水印
本质原因是扩散模型会“保留已有结构并继续细化”。
也因此一旦产生了一张带有水印的图片,如果后续把这张图片加入了参考的图片的列表中或者模型自动把这个加入了上下文,那么后续的生成过程都无法绕开对这块水印的牛皮藓般的刻画,即使告诉 TA “我不要水印了!”。
当然或许裁剪 reference image 是一个好主意,如果非要加入参考图片列表的话。

清晰度
还有一个让人费解的问题是,在从 720p 到 1080p 的清晰度更换后,提示词和参考图片和运镜提示词等等包括模型在内全部不变,得到的运镜大相径庭,或许是模型本身自己在不断微调,或许清晰度本身对应的卷积核大小不一样,或许是模型本身的温度就挺高的,无论如何,这是一个很关键的问题。
因而,不能用清晰度去作为交换,来试水,以此节省积分。如果最后的需求是 1080p ,那么尽管成本更高,但是过程中不能用 720p 生成任何一个有可能直接用在结果里的视频,即使是尝试。当然这个建立在任务要求高的基础上。
那么究竟是为什么会出现这种问题呢?
- 其实可以类比 CNN 中的卷积核大小,不同的分辨率也会更改这样一个潜在的核心组件的尺寸,即“潜空间”的结构。
大多数视频扩散模型并不是直接在像素空间生成,而是在 latent space(潜空间)生成,然后再解码。
视频 → VAE encoder → latent space
latent diffusion
latent → VAE decoder → 视频
分辨率越高,latent尺寸越高。这意味着:噪声张量大小不同,采样路径不同。所以即使 seed 一样,结果也会完全不同。
2. 好巧不巧的是,前面所说的扩散模型对细节更改或者说噪声极为敏感,其实对“初始噪声形状”也十分敏感。
扩散生成本质是noise → step1 → step2 → step3 → ... → video。
但如果分辨率改变意味着noise tensor shape 改变。,导致生成的轨迹完全不同,因而其实某种意义上 resolution 和 seed 同等重要。
3. 同时,当分辨率变大时:
- spatial token 数量增加
- attention pattern 改变
于是,运动路径、摄像机轨迹、主体位置都会发生变化。
4. 而前面我所说的“温度较高”,其实就是因为尤其是“运镜”是概率取样的,解空间是比较大的,尤其是对于一个看似解空间小实则很宽泛的 prompt 描述。而更改分辨率就会给本就温度高本就不稳定的这个取样系统呈现一个蝴蝶效应。
5. 更进一步,语义理解回合分辨率有关。形象上可以理解为,近视的人不带眼镜可能都无法分辨远处一个人的性别。而随着分辨率的提高,当然即使仅仅是小量的提高就会导致我们前后得到的画面尤其是运镜完全同。甚至会有 720p 更加符合我们的预期的情况出现。这也很好理解, 扩散模型的敏感性!原本的图片是 2k 的分辨率生成的,被 720p 的分辨率去理解会忽略很多细节上的噪音,反而效果好,而 1020p 也反而捕捉到了这些噪声,进一步形成噪声。
模型架构原理
经历了水印遗传的“牛皮癣”和分辨率更改导致的“蝴蝶效应”后,我不禁开始思考:即梦 AI 背后的 Seedance 2.0 到底在经历怎样的计算,才会出现这种看似降智、实则对初始条件极度敏感的反直觉现象?要彻底搞懂这些 bug,我们就不能仅仅停留在“经验之谈”的黑盒层面。我们必须看看 Seedance 2.0 底层架构,究竟在进行着怎样复杂的数据流转。
Seedance 2.0 最核心的技术创新在于“双分支扩散 Transformer”(Dual-Branch Diffusion Transformer, DiT)的底层架构 。这一架构彻底改变了 AI 视频生成的底层逻辑,使模型从“无声像素堆砌”进化为“声画一体”的智能体。
架构层面对 U-Net 的替代与 DiT 的进化
早期的视频生成模型多采用基于卷积神经网络 CNN 的 U-Net 骨干网络,但也正因为这样的基于 CNN 的 U-Net 架构,CNN的特点是局部,而后者的下采样 downsampling 这一核心算法也使之更加容易丢失细节,也就是说原本的 U-Net 处理信息是线性且局部的,在处理长程空间和时间关系时存在天然的局限性。
Seedance 2.0 转向基于 Transformer 的架构,这使其能够更有效地捕捉视频帧之间的复杂关联 ,自注意力机制解决了上述存在的问题。在 DiT 架构中,模型采用了解耦的空间层(Spatial Layers)和时间层(Temporal Layers),前者专注于纹理、光效等空间细节,后者则负责处理运动逻辑、物理规律等时间动态 。这种分层处理方式极大地提升了视频的画面美感与运动稳定性。
双分支同步生成机制的交叉注意力机制(Cross-Attention)
与以往“先生成无声视频,再后期利用配音工具合成”的流水线模式不同,Seedance 2.0 实现了视觉与音频的原生同步生成 。其架构内部可以被形象地比喻为左右脑协同工作:
- 视觉分支(左脑): 专注于生成视频像素帧,精确控制物体的形状、质感、光影交互以及物理互动逻辑 。
- 音频分支(右脑): 专注于生成与之匹配的音频波形,包括环境音效、背景音乐、拟音以及基于文本的自然对话 。
- 注意桥(Attention Bridge): 充当类似“胼胝体”的角色,在毫秒级维度上进行时空协同,确保音频的频率、节奏与视觉中的物体运动(如钢琴指法、玻璃破碎)或人物口型精准对齐 。
共享位置编码与帧准确对齐
通过共享位置编码(Shared Positional Encoding),Seedance 2.0 在生成过程中不需要繁琐的后期对齐步骤。视觉每一帧的像素变化都与音频中的对应时间点形成潜空间层面的绑定 。这种原生同步能力不仅解决了以往 AI 视频中常见的音画脱节问题,更将视频生产链路的后期成本降低了 70% 以上 。
模块组件功能优化
即跨越单镜头限制、进行复杂叙事与多镜头转场的能力
叙事规划器与多镜头逻辑
模型引入了一个名为“叙事规划器”的逻辑模块。在生成具体像素之前,该模块会首先根据用户的文本指令,像一名经验丰富的分镜师一样,将复杂的提示词拆解为一组逻辑连贯的镜头序列 。
这意味着用户只需输入一个简单的故事大纲,模型就能自动规划出全景镜头( establish environment)、中景镜头(dialogue/action)以及特写镜头(emotion capture),并自动处理镜头间的衔接与转场,如推拉(Dolly Zoom)、摇移(Pan/Tilt)等 。
深度物理感知与运动稳定性
在 Seedance 2.0 中,物理规律的还原得到了显著增强。模型在训练过程中引入了大规模的物理常识数据集,并采用了“物理感知训练目标”,对生成中出现的物理谬误(如违反重力、物体穿模)进行惩罚 。
- 流体与交互: 水流的表现不再像胶状物,而是具有真实的飞溅与折射;玻璃碎裂时的动力学轨迹与碎片碰撞声实现了完美的视听一致 。
- 运动连贯性: 无论是高难度的双人花样滑冰动作,还是复杂的打斗场景,Seedance 2.0 都能保持主体的重心稳定与运动线条的流畅,有效改善了以往 AI 视频中常见的结构崩溃问题 。
底层角度解释奇怪情况
既然 Seedance 2.0 的“双分支 DiT”和“叙事规划器”在理论上如此强大,甚至宣称能理解复杂的物理规律,那为什么在我的实际操作中,依然会遇到“提示词越长越容易崩坏”、“哪怕加了反向词也除不掉水印”、“分辨率一改全盘崩溃”的窘境呢?事实上,架构的升级虽然拔高了视频生成的上限,但并未彻底摆脱扩散模型(Diffusion Model)底层的数学诅咒。接下来,我将结合前沿的扩散理论(如流形假设、无分类器引导等),用计算机科学的底层视角,对我在前文中踩过的这些“坑”进行一次深度的再解释。
解空间越小,任务越难
基于传统的 U-Net 架构解释,参考文章什么是扩散模型,我们可以从文章中四个底层的核心机制来解释为什么“提示词越长、要求越苛刻,解空间越小,生成越困难,往往需要多轮尝试”。而即使是变为了 DiT 架构,也仍未完全脱离底层的扩散模型的规律。
1. 无分类器引导(Classifier-Free Guidance)与对齐/失真的权衡
对应文章部分: Classifier-Free Guidance 与 Scale up Generation Resolution (Imagen部分)
- 底层解释: 为了让模型听懂用户的“条件(提示词)”,在 conditioning 模块下现在的模型广泛使用
Classifier-Free Guidance技术。其公式是基于条件分数和无条件分数的线性外推:\tilde{\epsilon}_\theta(x_t, c) = (1+w)\epsilon_\theta(x_t, c) - w\epsilon_\theta(x_t)。其中的权重 w (Guidance Scale)控制了生成的图像/视频与提示词的契合度。 - 解释: 当用户的要求“越苛刻、越复杂、细节越多”时,为了让模型不遗漏这些细节,往往需要更高的引导权重 w 来强迫模型贴合文本。
然而,文章在 Imagen 一节中明确提到:“increasing w may lead to better image-text alignment but worse image fidelity. They found that it is due to train-test mismatch...”(增加引导权重会导致文本对齐更好,但图像保真度变差,原因是训练和测试的像素值范围不匹配)。
- 结论: 极度受限的解空间(苛刻的提示词)需要强力的 Guidance,但在底层数学上,过强的 Guidance 会破坏原有图像生成的稳定性和保真度(产生伪影或崩坏),这就是为什么“要求越高,生成难度呈指数级上升”。
2. 流形假设(Manifold Hypothesis)与低密度区域的梯度估计失效
对应文章部分: Connection with noise-conditioned score networks
- 底层解释: 扩散模型的本质是学习数据分布的梯度,从而引导纯噪声一步步走到真实数据。
*文章提到:“According to the manifold hypothesis, most of the data is expected to concentrate in a low dimensional manifold... In regions where data density is low, the score estimation is less reliable.”(根据流形假设,大部分数据集中在低维流形上。在数据密度低的区域,分数估计是不可靠的)。
即使,通过添加不同强度的噪声扰动数据,使扰动后的数据分布覆盖整个空间,从而让得分估计网络在不同噪声水平下都能稳定训练,解决了原始得分匹配在低密度区域估计不准的问题,通过噪声将数据分布“扩散”到了整个空间,使得每个区域都有数据点,但是这只是完全覆盖,仍然存在数据的密度分布不均匀的问题。
- 解释: 所谓的“包容、简单的提示词”,对应的是训练集里海量的、常见的广阔流形区域,这里的 Score(梯度)被模型学习得非常好,随便怎么生成都很完美。而“过长的提示词、极度苛刻的细节组合”,在多维空间中相当于划定了一个极其狭窄、甚至在训练集中极其罕见(数据密度极低)的子空间。
- 结论: 在这种极窄的解空间(低密度区域)里,模型对梯度的估计非常不可靠。这从底层解释了为什么“简单但高度契合的内容难以制作”,因为模型在这个极其特定的流形区域“迷路”了,导致必须多轮尝试。
3. 潜空间(Latent Space)与交叉注意力机制的计算瓶颈
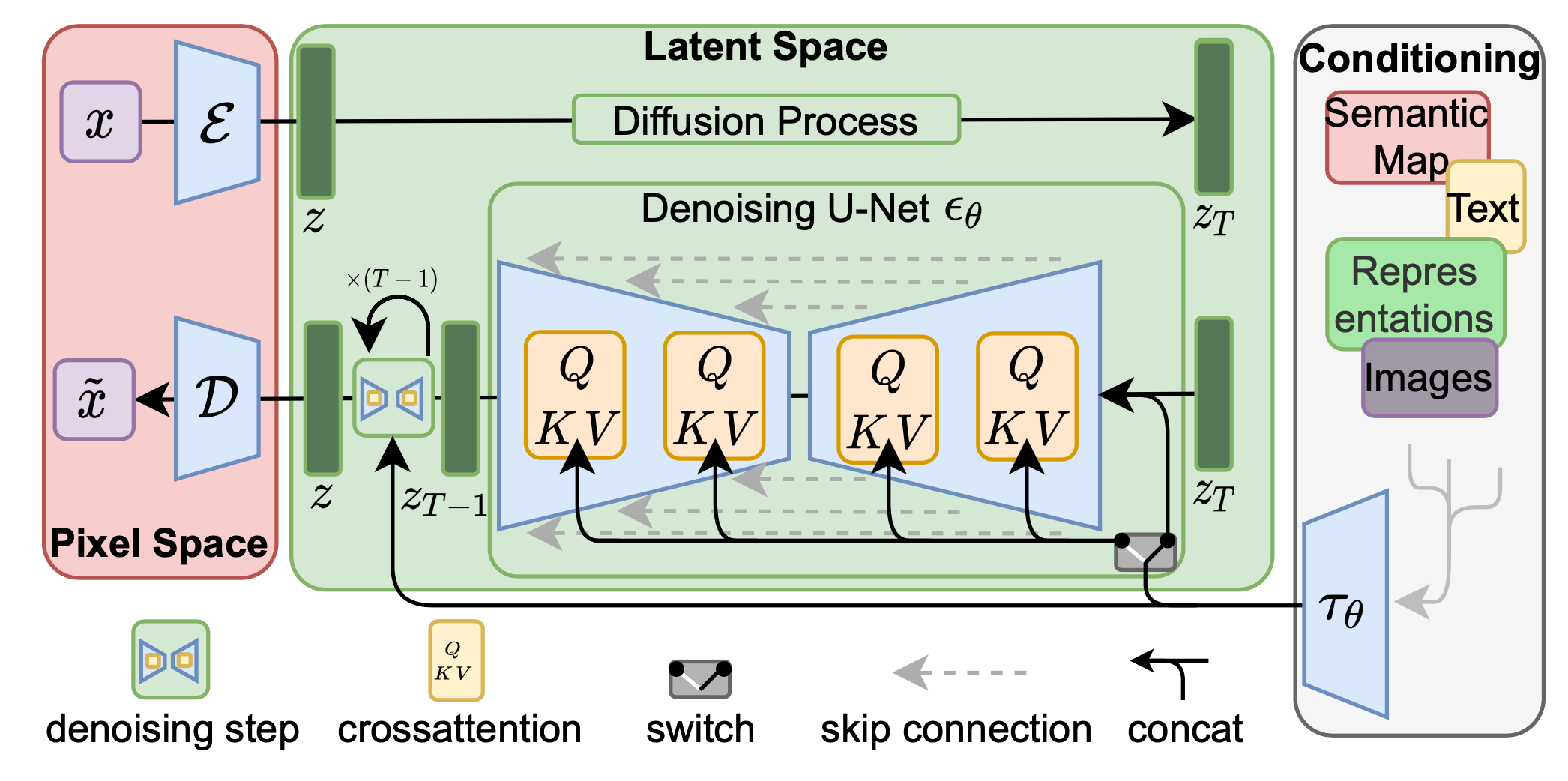
对应文章部分: Latent Variable Space (LDM / Stable Diffusion 架构)
- 底层解释: 文章在 LDM 部分给出了交叉注意力(Cross-Attention)的公式:Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d}}) \cdot V。这里,图像的中间特征映射为 Query (Q),而文本提示词(经过编码器处理后)映射为 Key (K) 和 Value (V)。
- 解释: 当提示词“越短、越包容”时,K 和 V 的语义特征相对宏观,注意力机制有极大的自由度将不同的视觉特征(Q)与文本融合,此时的“解空间”非常大。当“提示词过长、过于细节”时,K 包含了大量的约束条件(比如背景是什么颜色、左边有什么、右边有什么动作),而这往往是困难的,容易出现很多问题。注意力机制必须同时在矩阵乘法中满足所有这些互相独立的特征寻址。
- 结论: 在单一模型容量下,强行在注意力矩阵中满足过多且具体的约束,会导致各个局部特征之间的冲突。解空间被物理地压缩到了注意力分布极其苛刻的几个特定点上,模型很难在一次生成中完美协调所有 Attention Heads。
4. 逆向扩散的马尔可夫链与随机游走
对应文章部分: Reverse diffusion process 与 Conditioned Generation
- 底层解释: 生成过程是一个从纯高斯噪声 x_T \sim \mathcal{N}(0, I) 开始的逆向马尔可夫链。我们要根据条件概率 p_\theta(x_0 | y) 采样出最终结果。
- 解释: 如果提示词 y 很宽泛(包容),满足条件的 x_0 集合非常大。这意味着,不管初始的随机噪声 x_T 抽到什么(即无论用什么随机种子),逆向去噪链都有很大概率能顺利“滑落”到一个合理的图像/视频上。
反之,如果要求极其苛刻(解空间极窄),满足 y 的 x_0 仅仅是数据海洋中的孤岛。那么在 T 步去噪过程中,初始随机噪声 x_T 加上每一步的随机注入,极大概率会偏离这个微小的目标。 - 结论: 这就解释了为什么“注定要多轮尝试,几经令人崩溃”。因为当目标解空间极小时,找到一个能准确收敛到该空间的初始噪声本身就变成了一个低概率的抽奖事件。
水印问题
“一旦把这个放入参考图片的行列中,那么便会让与之相关的全部遗传水印”,即使用画图软件抹掉了,甚至加上了反向提示词“不要水印”。
在基于分数的模型中,当我们引入参考图像作为上下文(Context)时,我们使用的是条件分数(Conditional Score):\nabla_x \log p(x | c)。
- 局部极度敏感:由于 DiT 架构采用的是 Transformer 的全局注意力机制(Attention),它把图像切成一个个 Patch。用“画图”软件粗糙地涂抹了左上角,实际上创造了一个极度不自然、低概率的突变边缘,对于 DiT 来说,这个涂抹痕迹(不自然的色块边缘)本身就是一个强烈的条件特征 c。
- 掉入引力井:模型在计算 \nabla_x \log p(x | c) 时,为了匹配这个局部条件,加上模型本身的先验(“很多图片的边角都会有水印或标识”),条件分数的梯度会产生一个巨大的“引力井”。
- 后续轮次: 当把这张带有“微弱残影”的图片作为参考图或者被动作为上下文传入时,实际上我们把下一次生成的起始点(Initial State)直接放在了概率分布的半山腰上。离这座山峰越近,指向山顶的梯度就越明确。于是在 DiT 全局注意力的计算下,模型会顺着梯度,把模糊的结构不断“细化”。
- 为什么提示词“不要水印”无效? 此时存在两个维度的引导:文本条件的 Score 和图像条件的 Score。在实际采样中,视觉结构(参考图)提供的梯度信号往往具有压倒性的局部优势(Local Mode)。当告诉它“不要水印”时,文本维度的力量不足以把图像状态 x 从参考图构筑的“水印引力井”中拉出来。它已经被死死困在了局部最优解里。
- 最后得出的结论——“裁剪 reference image 是一个好主意”,从 Lilian Weng 的视角来看,是最符合数学逻辑的终极解决方案。
因为只要带有水印(或拙劣涂抹痕迹)的区域存在,它就会改变当前高维空间的起点,让 Langevin Dynamics 的采样轨迹无可避免地滑向带有水印的概率高峰(Score 梯度所指的方向)。
裁剪掉那个区域,在数学上等同于彻底改变了条件分布 p(x|c),直接移除了通向“水印山峰”的那条坡道。 这比任何提示词干预(调整梯度)都要直接和有效得多。
分辨率问题
在 DiT 架构下,分辨率的改变不仅是“像素变多”或“噪声变大”,而是整个模型计算图和序列结构的彻底重组,看似微不足道的改变,实则本身即是巨大变化。
1. Token 数量的剧变与“全局注意力”的蝴蝶效应
在 CNN 或 U-Net 中,分辨率变大通常意味着卷积核在更大的特征图上滑动(局部感受野)。但 DiT 模型(如基于 DiT 的 EchoMotion)完全抛弃了卷积核,而是将输入的 Latent 空间切分成一个个 Token(块)。
- 从局部到全局:当分辨率从 720p 提升到 1080p,画面被切分出的 Spatial Token(空间 Token)数量会呈平方级增加。
- Attention Pattern 的彻底改变:DiT 的核心是“多头自注意力机制(multi-head self-attention)”。在 Transformer 中,每一个 Token 都要和其他所有 Token 进行注意力计算。720p 和 1080p 对应着完全不同维度的注意力矩阵。一旦 Token 数量改变,整个画面特征的全局上下文(Context)就被打乱重构了。这就会导致原本 720p 下计算出的主体运动路径和摄像机轨迹,在 1080p 的注意力权重下被重新分配,从而产生“运镜大相径庭”的结果。
2. 双分支交互与模态平衡的打破
像 seedance 这类高级视频模型,往往采用了双分支架构(如 EchoMotion 处理视频与运动/运镜,VoiceDiT 处理内容与环境)。
- 序列拼接(Sequence Concat)的失衡:EchoMotion 和 D-DiT 会通过“序列拼接”将不同分支的 Token(例如“运镜控制/文本描述 Token”和“视频画面 Token”)合并在一起送入 Shared Transformer。
- 改变分辨率 = 改变权重占比:当分辨率升至 1080p,视频分支的 Token 数量暴增,而“提示词、参考图、运镜提示词”所在的分支 Token 数量是不变的。在经过注意力层(Shared attn/FFN)交互时,海量的 1080p 视频 Token 可能会“稀释”或改变原有的运镜 Token 的引导力,导致模型对运镜提示词的理解和执行方式发生偏移。
3. 空间-时间对齐机制(位置编码)的错位
运镜本质上是“空间随时间的变化”。 Positional Encoding(位置编码) 在时空对齐中有着决定性作用,比如 EchoMotion 使用的 MVS-RoPE(运动-视频同步旋转位置编码)。
- 坐标系的重构:DiT 严格依赖位置编码来识别“这是画面的哪个位置”。从 720p 到 1080p,空间分辨率网格改变,模型分配给 Token 的空间位置索引(Spatial Indices)也就完全不同了。
- 时空同步失效:当空间位置编码被重构后,原本在 720p 下能够完美对齐时间轴的“运镜轨迹(Motion)”,在 1080p 的新空间网格下就会发生错位。模型在生成时,其内部的 Inductive Bias(归纳偏置)会根据新的空间网格重新规划物理运动,导致最终的运镜轨迹完全偏离 720p 时的效果。
4. 联合概率分布与双重无分类器引导的敏感性
前文所提到的“模型温度较高(随机性大)”,在双分支 DiT 中可以归结为多目标损失与采样机制。
- 高维扩散轨迹的极度敏感:扩散模型是在高维 Latent 空间中进行概率采样(Noise Prediction)。分辨率增加导致 Latent 维度成倍扩大。在这个更庞大的高维空间里,即使是相同的 Seed(初始随机数种子生成的噪声),其噪声张量的 Shape 也不同。
- CFG(无分类器引导)的放大器效应:模型通过 Dual Classifier-Free Guidance 来调整样本的保真度。在高维空间中,条件引导(运镜提示词)和无条件预测之间的线性组合会因为 Token 结构的改变而走向完全不同的去噪轨迹(Trajectory)。这就好比在岔路口,720p 和 1080p 在第一步去噪时就踏上了不同的时间线,后面几十步的演化自然南辕北辙。
为什么不能用 720p 试水来代替 1080p?
Dual-Branch DiT 模型的核心在于全局 Token 的注意力交互和多模态分支的对齐。
分辨率不同,意味着 Token 数量不同 → 注意力矩阵完全不同 → 双分支融合比例不同 → 空间位置编码打乱重排 → 去噪轨迹走向平行宇宙。
所以,在这类模型中,720p 并不是 1080p 的“模糊版”,它们在 Transformer 的计算视角下,输入的是两套完全不同长度和结构的序列。分辨率(Resolution)在这个架构中不仅是清晰度参数,更是决定全局网络结构的“拓扑参数”。 这就是为什么如果最终需要 1080p,就必须直接在 1080p 下尝试,而不能用 720p 试水的原因。
暂且不谈
1. 视频生成的最大难点:为什么长视频容易崩坏或者变异?
简单来说,因为随着时间 T 的增加,自回归生成或长序列扩散时的误差累积。在潜空间中,由于时间维度的马尔可夫链极长,微小的扰动会导致后面的帧完全脱离原有的“流形(Manifold)”。
2. 交叉注意力机制的底层:为什么不需要后期对齐?
因为在扩散去噪的每一步(Step 1 到 Step T),声音特征都在强制约束画面像素的梯度方向。声音和画面共享了同一套去噪时间步(Timesteps)。
3. I2V(图生视频)为什么比 T2V(文生视频)好控制?
- 纯文生视频(T2V)是条件生成 P(x|text),初始状态是纯随机的高斯噪声,解空间极大。
- 图生视频(I2V)则将第一帧(或首尾帧)硬编码为了一个确定性的锚点(Anchor),即 P(x|text, x_0)。这在数学上相当于给复杂的马尔可夫链加了一个极强的边界条件(Boundary Condition),大大缩小了你所说的“解空间”,因此不仅能规避文字幻觉,还能减少失败率。
4. 为什么CFG 过高会导致视频失去动态,变成“带噪声的静态PPT”?
因为文本提示词通常描述的是“静止的语义”(比如“一只狗在跑”)。当 CFG 权重过大时,模型为了死死贴合文本语义,会倾向于生成一幅完美的静态画,而惩罚那些会带来模糊感的“运动轨迹”。这种“对齐/失真的权衡”在视频领域的表现,比图像领域更致命。
行业意义: AI 离工业化还有多远
从直观的 UI 点击,一路深潜到高维潜空间的矩阵乘法与马尔可夫链,这 80 秒的视频制作不仅耗费了大量的积分,更像是一场对当前 AI 视频能力边界的极限压力测试。当我们试图理解它底层那些残酷且精妙的数学规律后,再重新审视即梦这个产品,一切反直觉的现象都有了合乎逻辑的答案。那么,站在技术底层与产品应用的交汇点上,我们该如何评价当下这个视频生成的“奇点时刻”?跳出我个人的这 80 秒,AI 视频到底离真正的影视工业化还有多远?
在亲手用 80 秒视频烧掉高昂的积分、并经历了无数次“抽卡失败”这样的体验后,我们仍然不得不面对一个冷酷的现实:如今的 AI 视频大模型,确实惊艳,但距离真正的“工业化”还有一段泥泞的路要走。
工业化的核心标准是“可预期的质量”、“可控的成本”与“标准化的工作流”。
就目前而言,1元/秒的生成成本和极高的废片率(如我这次约 20% 的可用率),注定了它现阶段还无法成为一键出大片的“全自动工厂”,而更像是一个人在回路中的高级工具。
尽管如前文所述的难如登天,但从 Seedance 2.0 的产品形态上,我们已经清晰地听到了工业化齿轮咬合的声音。拐点的出现,并非因为模型一夜之间变得不再有幻觉,而是工程落地的思路变了:
- 从“盲盒抽卡”到“精准控制”:
即梦极其克制的“先给参考图,再生成视频”的 UI 引导,以及引入 Agent 辅助写提示词,本质上都是在强行收窄解空间。通过提供首尾关键帧和双分支架构(音画强制对齐),平台把一个发散的生成问题,变成了两点之间的“插值补全”问题。这种工程上的取巧,大大提升了可控性。 - 架构收敛带来的红利:
就像当年 ResNet 统一了图像识别,如今 DiT + 3D VAE 的架构已经成为了全球顶尖视频模型(从 Sora 到 Seedance)的共识。当底层架构不再频繁推翻重来,工程界的精力就会集中在优化显存、加速算子、降低推理成本上。算力的摩尔定律,迟早会把那“1元1秒”的价格打下来。 - 融入既有工作流(Human-in-the-loop):
这也是我这 80 秒视频最大的感悟——AI 不必包揽一切。 现在的 AI 视频不需要去取代长片电影的完整摄制,它只需要作为一块极高规格的“素材垫片”。当它被无缝接入到诸如剪映、Arctime、AE 等成熟的后期工作流中,由人类来完成剪辑、字幕补齐与逻辑编排时,它就已经在切切实实地重塑广告、短剧和教育素材的生产线了。
结语
AI 视频的工业化,不是用一行提示词生成《流浪地球3》,而是让像我这样的普通人,能在一个周末的下午,看见自己想象的画面片段,描绘自己无法传达的梦和画面。
未来将至,奇幻将现。
参考材料:
【闪客】AI视频的底层诅咒!Seedance2.0真的很牛吗?
https://openai.com/index/video-generation-models-as-world-simulators/
https://arxiv.org/abs/2506.09113
https://arxiv.org/abs/2512.13507
https://openai.com/index/video-generation-models-as-world-simulators/
https://arxiv.org/abs/2310.10647
https://arxiv.org/html/2504.09656v1
https://arxiv.org/abs/2506.07177
https://arxiv.org/abs/2511.12099
https://arxiv.org/pdf/2306.02018
https://mp.weixin.qq.com/s/g5CheBk1yj50Fn85bUtHaw
https://mp.weixin.qq.com/s/4fwLmBrCIMcrRrWlNBjYgw
https://news.qq.com/rain/a/20260304A07QZ400
https://jimeng.jianying.com/ai-tool/home
https://arxiv.org/abs/2208.11970
https://jalammar.github.io/illustrated-stable-diffusion/
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
https://arxiv.org/abs/2006.11239
https://www.emergentmind.com/topics/dual-branch-diffusion-transformer#continue-learning
Seedance 2.0 Complete Guide: ByteDance's Revolutionary AI Video Generator (2026)
Seedance2.0引AI视频风暴 - 新浪新闻
字节跳动,新年王炸诞生了:Seedance 2.0爆火_投资界
Seedance 2.0 Review: ByteDance's AI Video Generator That Has Hollywood Terrified (2026)
What Is Seedance 2.0? A Guide With Examples - DataCamp
vertu.comSeedance 2.0 Review: ByteDance's 90% Success Rate AI Video Tool - VERTU® Official Site
Seedance 2.0 vs. Traditional Video Production: Reducing E-commerce Video Costs by 70%
Seedance 2.0: Multimodal AI Video Generation by ByteDance - Vizard.ai
Seedance 2.0: ByteDance's New AI Video Model – Developer Guide & Comparison - SitePoint
Seedance 2.0 - Wikipedia
榜单更新,字节Seed2.0表现亮眼,我们还测了爆火的龙虾|xbench ...
Seedance 2.0 AI Video: Technical Preview and User Discussion - Higgsfield
字节跳动豆包视频生成模型Seedance 2.0 上线 - 新浪财经
字节Seedance 2.0火爆出圈影视板块掀起涨停潮内测暂停真人人脸上传 - 财联社
Seedance 2.0 Vs Previous: Who Delivers Better AI Video? | KreadoAI
Seedance 2.0 is Here: ByteDance Redefines AI Video Generation with Director-Level Control - Siraya Technologies
字节,再出爆款!引爆A股涨停潮 - 证券时报
Seedance 2.0 正式发布 - ByteDance Seed
How to Use Seedance 2.0 in the US : Free Trial, Tutorial & Alternative - CyberLink
生成式AI 模型Seedance 2.0:全方位參考指南- Atlas Cloud Blog
Seedance:字节跳动的AI视频生成技术突破与行业变革 - 新浪财经
Seedance 2.0 vs. Sora 2 vs. Kling 3.0: Ultimate AI Video API ...
Seedance 2.0 即将上线:特性、预期发布时间、以及如何在Atlas Cloud上使用
字节跳动Seedance 2.0定价公布 - 东方财富
Seedance 2.0 Prices: Is the Subscription Worth It? (2026) - GamsGo
那个下午,我变成了一个“缝合怪”导演 - 富途资讯
将Seedance 2.0 AI 视频打造为最强大的转化率优化工具之一 - Atlas Cloud[
“地表最强”视频模型Seedance 2.0刷屏技术升级革新影视创作 - 证券时报
ByteDance suspends Seedance 2.0 feature that turns facial photos into personal voices over potential risks - TechNode
SeeDance2.0降智,字节却成为硅谷门外的“野蛮人”?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)