0.1B 参数也能听说读写?本周语音 AI 十大前沿论文
Speech AI · FRONTIER
ASR/TTS 论文周报 · 第 002 期
📅 2026-05-01 至 2026-05-07 | 精选 TOP 10(含架构图)
📈 本周趋势小结
- 🔥 超小模型多模态 — 0.1B 参数级别的语音原生全模态模型开源,端侧部署门槛持续降低
- 🎯 LLM 驱动评估范式 — 用大语言模型替代传统 MOS 评分,实现零样本多维度语音质量评估
- 🎵 音频 Token 语言模型扩展 — 声学 Token 序列建模从语音延伸到高保真音乐生成,64 层 RVQ 突破保真度极限
- 🔗 低资源语言 TTS 突破 — 大模型跨语言迁移学习使藏语等极低资源语言首次获得高质量 TTS 能力
- 🛡️ 语音安全与溯源 — 深伪基础编码器 + Mel 域水印双管齐下,从检测和防伪两端强化语音安全
🔝 #1 MiniMind-O Technical Report: An Open Small-Scale Speech-Native Omni Model
⭐⭐⭐⭐⭐
Foundation Model ASR TTS Multimodal 端侧部署
仅 0.1B 参数的开源多模态模型,支持文本/语音/图像输入,同时输出文本和流式语音。采用冻结 SenseVoice + SigLIP2 编码器,通过 MLP 投影器映射到统一隐空间,独立 Talker 模块基于 Mimi codec 实现 8 层流式语音生成。
💡 亮点:开源的超小语音原生全模态模型,0.1B 参数即可实现语音理解 + 生成,端侧部署友好
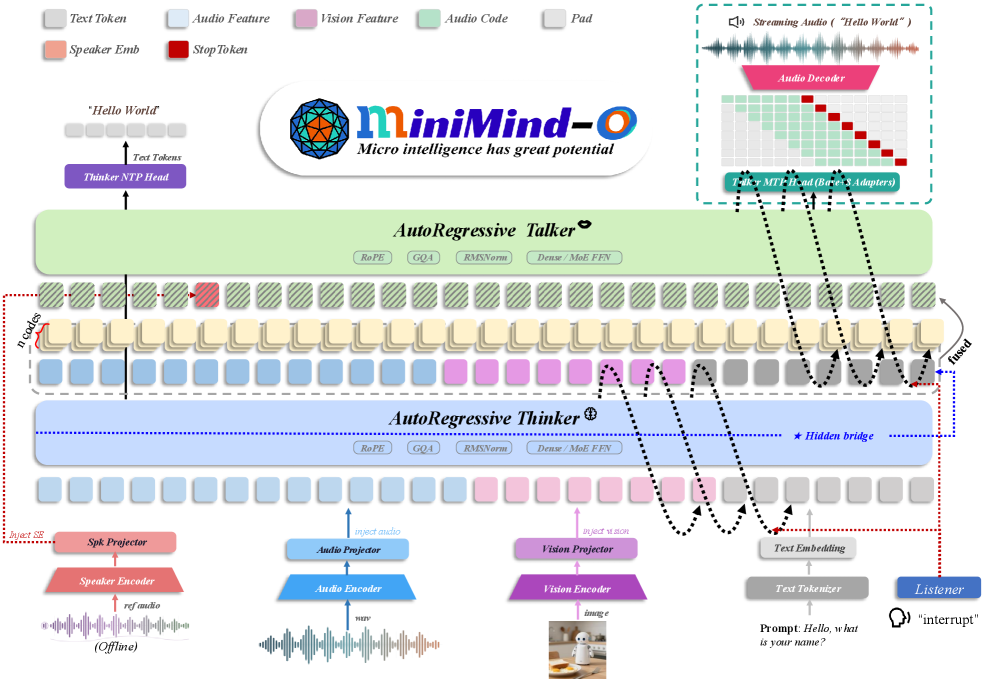
▲ 架构说明:音频/图像经冻结编码器编码后通过 MLP 投影器注入 MiniMind 隐空间,Thinker 输出中间状态与 Mimi codec 历史融合,由独立 Talker 预测 8 层 codec 实现流式语音输出。
📄 论文链接:arxiv.org/abs/2605.03937
💻 开源代码:github.com/jingyaogong/minimind
🔝 #2 JASTIN: Aligning LLMs for Zero-Shot Audio and Speech Evaluation via Natural Language Instructions
⭐⭐⭐⭐
Foundation Model Evaluation Zero-Shot LLM 音频质量
指令驱动的音频评估框架,将冻结音频编码器与微调 LLM 对齐,无需任务特定重训练即可评估语音/音频/音乐质量。提出多源多任务多校准数据构建流水线,在 QualiSpeech 等基准上实现零样本 SOTA。
💡 亮点:用 LLM 替代传统 MOS 评分,一个模型零样本评估所有音频质量维度
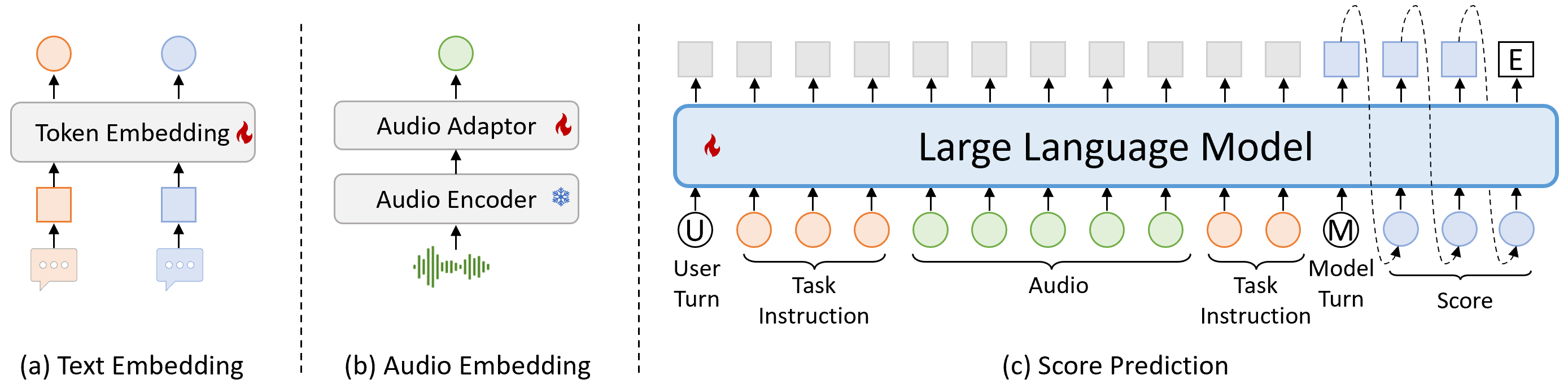
▲ 架构说明:音频通过冻结编码器和适配器映射到 LLM 输入空间,结合自然语言指令描述评估维度,LLM 直接输出分数和文本解释。
📄 论文链接:arxiv.org/abs/2605.04505
🔝 #3 VocalParse: Towards Unified and Scalable Singing Voice Transcription with Large Audio Language Models
⭐⭐⭐⭐
ASR Audio LLM Singing CoT 统一转录
首个用大型音频语言模型统一歌唱语音转录(歌词 + 音符)的框架。提出交错词-音符监督和 CoT 风格提示策略,配合 SingCrawl 大规模伪标注管道,在歌词识别和音符检测上均超越专用模型。
💡 亮点:Audio LLM + CoT 提示统一歌唱转录,打破歌词/音符/节拍分离处理的传统范式
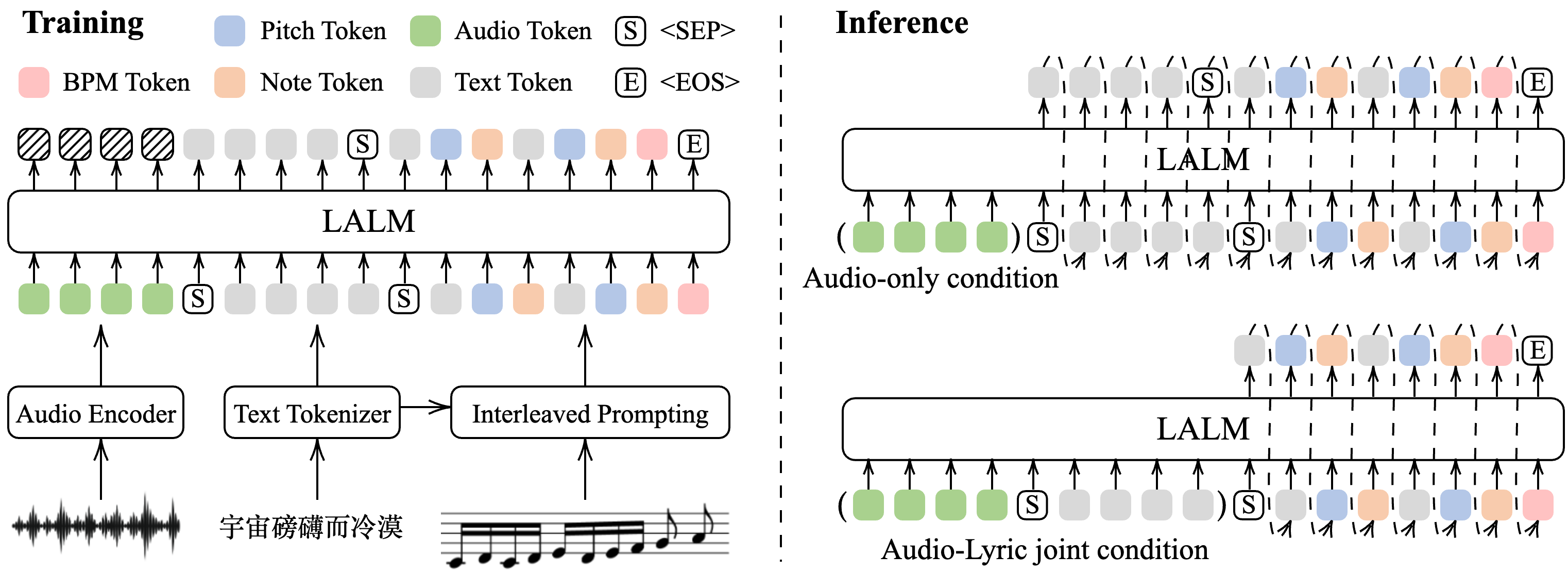
▲ 架构说明:左侧为交错词-音符监督训练范式(CoT 风格),右侧展示音频推理和音频+歌词联合推理两种模式。
📄 论文链接:arxiv.org/abs/2605.04613
🔝 #4 Khala: Scaling Acoustic Token Language Models Toward High-Fidelity Music Generation
⭐⭐⭐⭐
Audio Generation Token LM RVQ Music 超分辨率
将声学 Token 语言模型扩展到高保真音乐生成。采用 64 层 RVQ 编解码器,提出两阶段生成框架:骨干模型生成粗粒度 Token(Layer 0-1),超分辨率模型逐层补全高层细节(Layer 2-63),实现全频段高保真度。
💡 亮点:64 层 RVQ + 两阶段粗细生成,声学 Token LM 首次逼近无损音乐生成质量
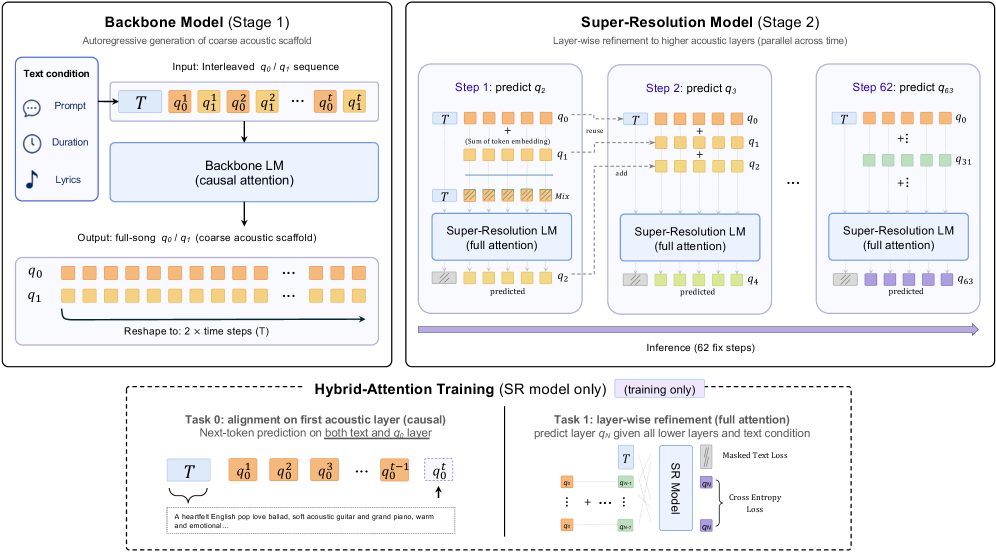
▲ 架构说明:骨干 LM 自回归生成粗粒度 Token(Layer 0-1),超分辨率模型在时间维度并行地逐层补全 Layer 2-63 的高层细节。
📄 论文链接:arxiv.org/abs/2605.01790
🔝 #5 Contrastive Regularization for Accent-Robust ASR
⭐⭐⭐⭐
ASR Robustness Self-Supervised Contrastive Learning 口音
提出在自监督语音编码器的 CTC 微调过程中加入**监督对比损失(SupCon)**作为辅助目标。通过掩码池化获取话语级表征,约束同文本不同口音的表征聚拢,使模型学习口音不变特征,显著提升多口音 ASR 鲁棒性。
💡 亮点:仅加一个对比正则项,即可让 Wav2Vec2/HuBERT 在多口音场景下大幅降低 WER

▲ 架构说明:自监督编码器输出经 CTC 损失训练 ASR,同时通过掩码池化获取话语级表征,施加监督对比损失使相同文本的不同口音表征聚拢。
📄 论文链接:arxiv.org/abs/2605.03297
🔝 #6 Tibetan-TTS: Low-Resource Tibetan Speech Synthesis with Large Model Adaptation
⭐⭐⭐
TTS Low-Resource Cross-Lingual 藏语 大模型迁移
首个基于大模型的藏语 TTS 系统。通过跨语言自适应训练将星辰大语音模型迁移至藏语,提出音节级建模和 BPE 分词器适配两种策略解决藏文脚本表示问题,配合统一数据质量增强管道处理多源低质量数据。
💡 亮点:大模型跨语言迁移首次实现藏语高质量 TTS,为极低资源语言合成提供范式
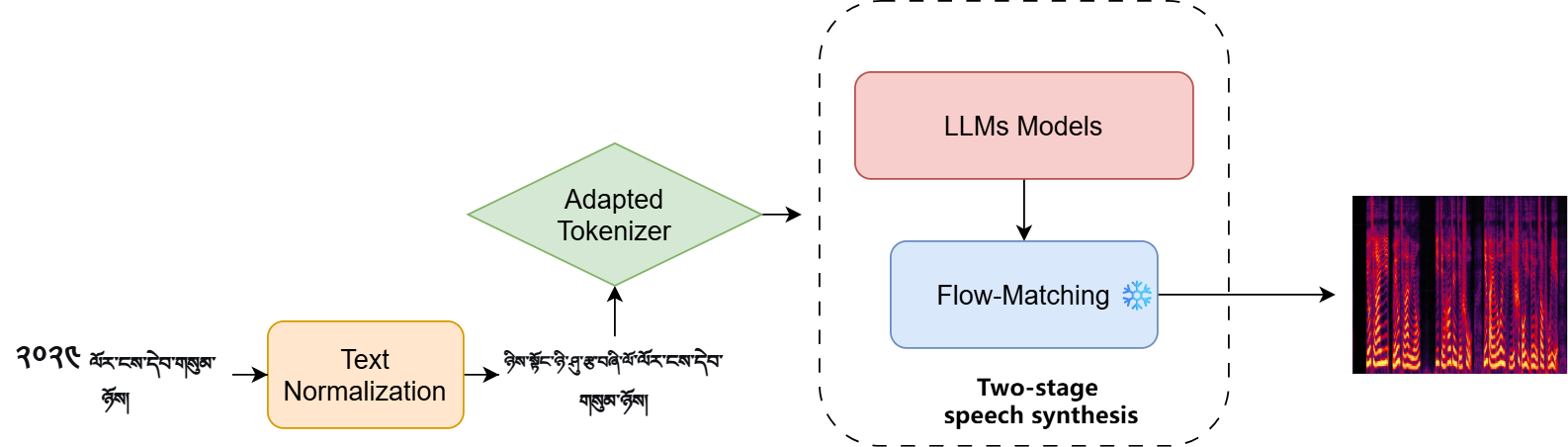
▲ 架构说明:三模块架构——轻量文本预处理、藏语分词器适配(音节级/BPE)、基于星辰大模型的语音生成。
📄 论文链接:arxiv.org/abs/2605.02496
🔝 #7 Fast Text-to-Audio Generation with One-Step Sampling via Energy-Scoring and Auxiliary Contextual Representation Distillation
⭐⭐⭐⭐
Audio Generation Diffusion Distillation 一步生成 能量评分
提出 AudioDEAR——基于能量评分和上下文表征蒸馏的一步采样文本到音频生成模型。通过能量评分头替代多步扩散/流匹配采样,配合掩码自回归框架和辅助蒸馏损失,单步生成即达到多步扩散模型的 FD 分数。
💡 亮点:一步采样即达多步扩散质量,推理速度提升数十倍,实时音频生成新范式
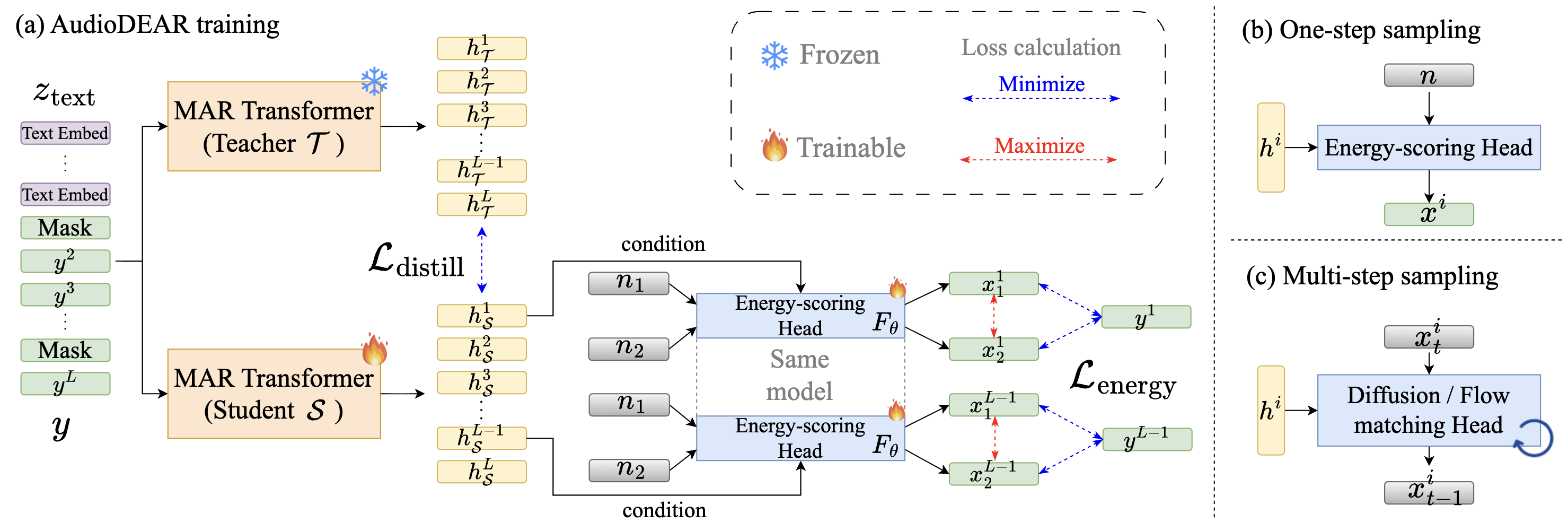
▲ 架构说明:(a) 能量评分 + 表征蒸馏训练管道 (b) 一步推理的能量评分头 © 与多步扩散/流匹配的对比。
📄 论文链接:arxiv.org/abs/2605.00329
🔝 #8 A Comprehensive Analysis of Tokenization and Self-Supervised Learning in End-to-End ASR applied on French Language
⭐⭐⭐
ASR Tokenization SSL French 多指标评估
系统研究子词分词算法(BPE、Unigram、WordPiece)与自监督模型(WavLM、Wav2Vec2、XLS-R)在法语 ASR 中的交互影响。引入 CER/WER/SER/IER 多指标综合评估,揭示分词粒度对不同错误类型的影响模式存在显著差异——BPE 在插入错误上占优,Unigram 在替换错误上更稳定。
💡 亮点:超越 WER 单指标,揭示分词策略与 SSL 模型的最佳搭配规律,指导实际 ASR 系统设计
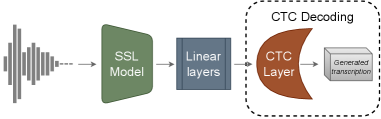
▲ 架构说明:自监督学习编码器提取音频表征,经 3 层 DNN 线性层映射后通过 CTC 框架解码为文本 Token,系统研究了不同 SSL + 分词器组合的效果差异。
📄 论文链接:arxiv.org/abs/2605.03696
🔝 #9 Alethia: A Foundational Encoder for Voice Deepfakes
⭐⭐⭐⭐
Safety Foundation Model Deepfake Self-Supervised 预训练编码器
提出面向语音深伪检测的基础编码器,采用双分支自监督预训练:掩码瓶颈嵌入预测分支 + 频谱图重建分支(基于流匹配的速度场预测)。无需微调即可在 ASVspoof5 等多个基准上实现高质量嵌入分离。
💡 亮点:深伪检测的"基础模型"思路——通用预训练编码器,零样本即可区分真假语音
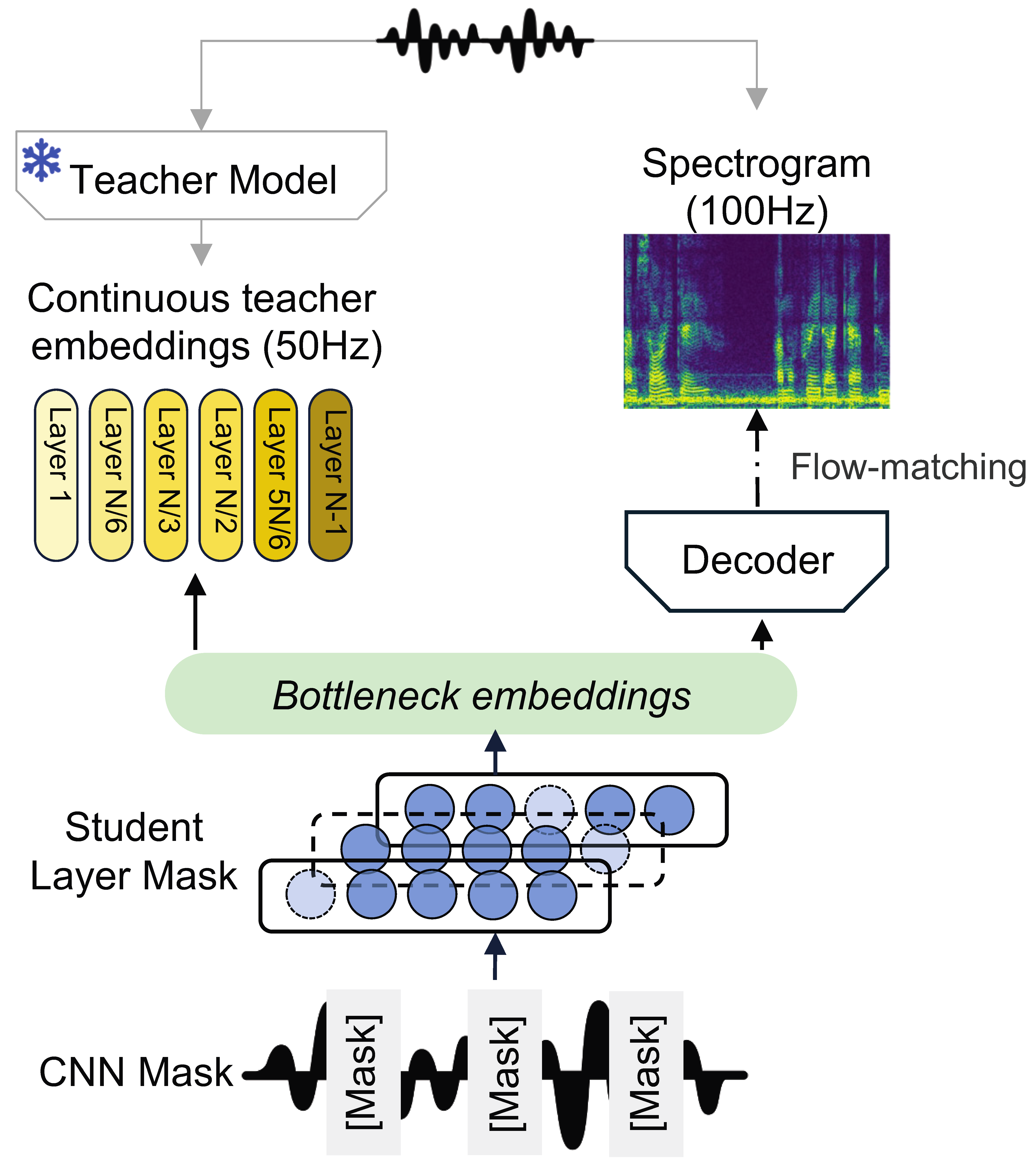
▲ 架构说明:掩码波形输入编码器,投影为层聚合瓶颈嵌入,双分支并行——一支预测教师模型各层嵌入,一支通过流匹配重建完整频谱图。
📄 论文链接:arxiv.org/abs/2605.00251
🔝 #10 Mitigating Multimodal LLMs Hallucinations via Relevance Propagation at Inference Time
⭐⭐⭐⭐
Audio LLM Hallucination Inference-Time 免训练 Qwen2-Audio
提出 LIME——无需训练的推理时幻觉缓解框架。通过层级相关性传播(LRP)量化模型对音频/视觉输入的关注度,优化 KV 缓存中的可学习更新项,迫使模型在解码时更多依赖实际输入而非先验偏见。在 Qwen2-Audio 上验证有效。
💡 亮点:免训练方法解决音频 LLM 幻觉问题,即插即用,对 Qwen2-Audio 等模型立即生效
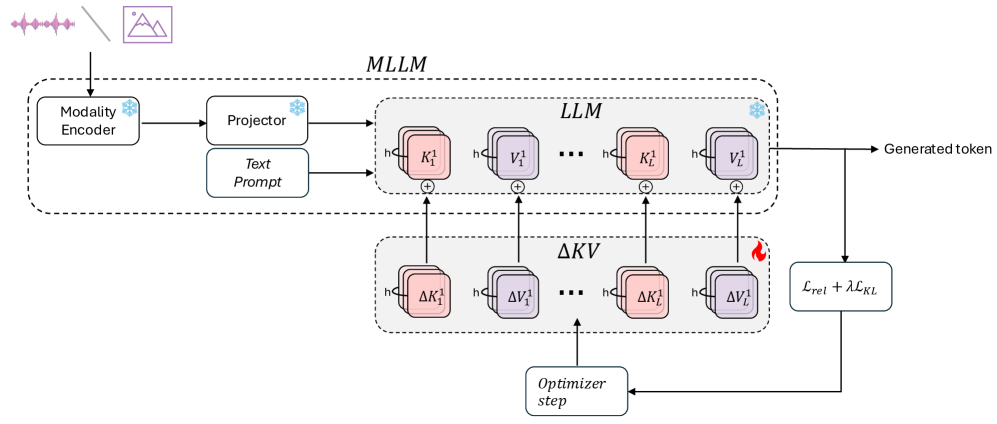
▲ 架构说明:冻结基础模型,仅优化 KV 缓存中的更新项,迭代提升模态相关性(LRP 得分)同时用 KL 散度约束分布稳定。
📄 论文链接:arxiv.org/abs/2605.01766
Speech AI · FRONTIER · 每周语音算法前沿 · 第 3 期
关注公众号获取最新语音 AI 论文解读
本文由 AI 辅助整理,论文筛选与技术点评由作者完成。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)