
产品经理AI知识进阶(十):理解LangChain 与 LangGraph
从 LangChain 的“模块化链条”到 LangGraph 的“自动化状态机”,我们见证了 AI 应用从“玩具”向“工业级系统”演进的历程。大模型本身并不构成产品护城河,真正的护城河在于:你如何利用这些工程框架,将大模型的认知能力与你所在行业的垂直数据、专属工具深度绑定,构建出稳定、可靠且具有商业闭环的复杂工作流。希望这篇文章能帮你简单理解 AI 落地的底层框架,帮助你在与研发沟通时能无缝对话

在大模型落地时,经常听到算法提到的框架就是LangChain和LangGraph,作为产品经理,需要对这两个框架有一定的认知,从而在推进项目时能够与算法无障碍沟通。
这里需要明确的是,在常见的大模型app中的对话,无论提示词写的多么好,得到多好的回答,那也只仅限于个别的对话场景。在应用到实际业务中时,就会发现,大模型存在着各种各样的问题:
模型会胡说八道(幻觉)、它记不住三轮之前的对话(遗忘)、它不知道公司内部的最新数据(知识滞后),更致命的是,它没有手脚,无法真正去“执行”一个动作。
大模型本身只是一个“缸中之脑”。要让它成为一个能落地的 AI 产品,我们需要为它装上记忆、外挂知识库、接上四肢,并设定严谨的工作流。
这正是LangChain与LangGraph诞生的工程背景。
01 核心痛点:为什么我们需要框架?
试想一个场景:你需要做一个“智能排障网络助手”。用户说:“我家的网卡顿了。” 一个及格的 AI 助手不能只回答“请重启路由器”,它需要:
理解意图:分析用户到底遇到的是 Wi-Fi 信号问题,还是宽带欠费。
检索知识:查阅产品最新的排障手册(RAG 检索)。
调用工具:通过 API 查询设备当前的 CPU 负载、丢包率、甚至是节能模式状态。
综合分析:给出结论并执行修复指令(如关闭高延迟的节能模式)。
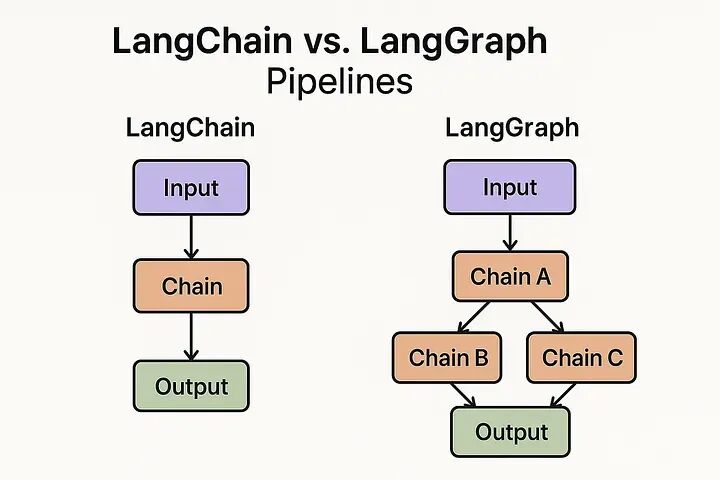
要把这套复杂的逻辑串联起来,如果全靠产品研发手写代码,系统会变得极其脆弱且难以维护。我们需要一套标准化的“脚手架”,这就是 LangChain 存在的意义。
02 LangChain:AI 工作流的“瑞士军刀”
LangChain是一个开源框架,它的核心思想是模块化(Modularity)和链接(Chaining)。它将大模型应用开发中常用的组件进行了高度抽象,你可以像搭积木一样,将不同的模块组合成一个执行流水线。
1. 核心架构与关键模块
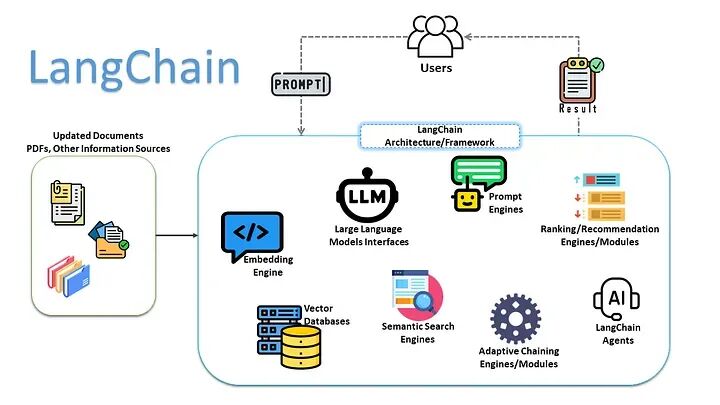
LangChain 的底层主要由以下几个核心模块构成:
-
模型 I/O (Model I/O):屏蔽了底层不同大模型(GPT-4、Claude、文心一言等)的接口差异,提供统一的提示词模板(Prompts)和输出解析器(Output Parsers),强制大模型输出 JSON 等结构化数据。
-
检索 (Retrieval):这是实现 RAG(检索增强生成)的核心。包含文档加载器(读取 PDF/网页)、文本分割器(切块)、以及连接向量数据库的接口,让模型拥有“外挂硬盘”。
-
记忆 (Memory):管理对话历史,解决大模型“金鱼记忆”的问题。
-
链 (Chains):将上述模块按固定顺序串联。比如“检索文档 -> 组装 Prompt -> 大模型生成回答”就是一条经典的 RAG 链。
-
代理与工具 (Agents & Tools):赋予模型“手脚”。工具是具体的 API(如查天气、搜网页、控制硬件设备),代理则是让大模型自己做决策——根据用户的问题,自主决定调用什么工具、以什么顺序调用。
2. 特点与适用场景
特点:高度封装,开箱即用,生态极其丰富(支持数百种外部工具和数据库)。
适用场景:单向的流水线任务。如企业知识库问答(Q&A 机器人)、文档摘要生成、简单的数据结构化提取。
03 LangGraph:复杂 Agent 的“自动化状态机”
随着业务深入,很快会发现 LangChain 的局限性:它是一条单向的直线。在真实的业务中,任务往往不是线性的。比如一个代码生成 Agent,它写完代码后需要测试,如果报错了,需要把错误信息发回给大模型“反思”并重写。这就引入了循环(Loops)和条件分支。
面对这种需求,LangChain 显得力不从心,于是官方推出了进阶版的架构:LangGraph。
1. 技术架构:从“链条”到“图结构”
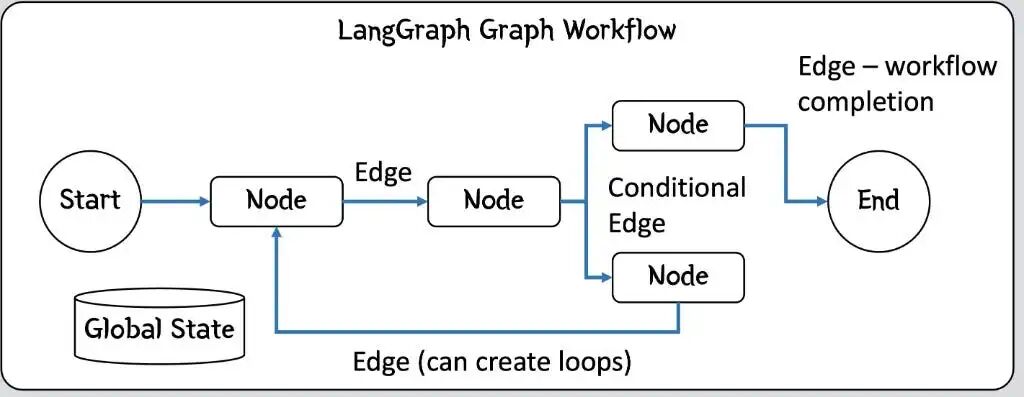
LangGraph 放弃了线性的 Chain,将应用的执行逻辑建模为一个有向图(Graph),本质上是一个状态机(State Machine)。
-
状态 (State):全局共享的数据结构。它像一张在流水线上流转的“工单”,记录着当前任务的所有上下文(如对话历史、检索到的资料、执行报错信息)。
-
节点 (Nodes):图中的执行单元。它可以是一个大模型调用,也可以是一个普通的 Python 函数(比如执行一个硬件诊断脚本)。节点接收当前状态,处理后更新状态。
-
边 (Edges):决定下一步走向的路由规则。最强大的是条件边(Conditional Edges),它可以根据当前状态(例如大模型判断诊断是否成功)动态决定下一个执行节点,从而完美实现循环重试和自我纠错。
2. 特点与适用场景
特点:支持复杂的循环逻辑、原生具备状态持久化(Checkpointing),支持极其关键的“人在回路(Human-in-the-loop)”机制(比如在执行高危操作前,流程暂停,等待人工点击确认)。
适用场景:多 Agent 协同(如一个规划者节点分配任务,多个执行者节点干活,一个审核节点做验收)、需要多步推理与反思的复杂自动化任务、长时间运行的后台进程。
04 产品落地与避坑指南
理解了技术架构,我们如何把它们变成真正的产品?在实际落地时,通常会采用 前端交互 (Web/App) + 后端 API (FastAPI/LangServe) + 监控平台 (LangSmith) 的三层架构。
但在真正的落地过程中,产品经理需要特别注意以下几个工程陷阱:
1. 警惕“框架过载”(Over-engineering)
坑点:为了用而用。很多简单的功能(比如只是让大模型翻译一段话),非要套上几十层 LangChain 的抽象,导致代码调试极其困难,性能严重下降。
对策:架构设计要克制。简单的功能直接裸调 OpenAI SDK;标准 RAG 用 LangChain;涉及循环推理和多步编排的复杂 Agent,才上 LangGraph。
2. RAG 落地:数据清洗大于模型调优
坑点:“Garbage in, garbage out”。很多团队把精力花在换各种大模型上,但检索出来的知识库文档本身排版混乱、格式丢失,导致模型怎么回答都是错的。
对策:在 RAG 场景中,产品经理应该把 70% 的精力放在前置的文档预处理、版面分析(PDF 解析)、以及多路召回策略(语义检索+关键词检索)上,而不是迷信 LangChain 的默认切块工具。
3. Agent 的成本与延迟失控
坑点:LangGraph 的循环图非常强大,但也容易导致大模型陷入“死循环”(不断尝试修复一个它修复不了的 Bug)。由于每循环一次都在消耗 Token,会导致 API 账单爆炸,且用户端迟迟等不到响应。
对策:必须在图中硬性设置最大迭代次数(Recursion Limit)。在产品交互上,必须采用流式输出(Streaming)和中间状态透传。不要让用户面对一个干转的 Loading 菊花图,要把 Agent 每一步在思考什么、正在调用什么工具实时展示给用户,缓解等待焦虑。
4. 必须引入全链路监控
没有监控的 Agent 就像在蒙眼狂奔。强烈建议在落地时接入LangSmith(或其他类似平台)。作为产品经理,你需要通过监控面板,去看大模型在哪个节点做出了错误的路由判断,去评估 Prompt 的修改是否导致了其他场景的退化(回归测试)。
05 结语
从 LangChain 的“模块化链条”到 LangGraph 的“自动化状态机”,我们见证了 AI 应用从“玩具”向“工业级系统”演进的历程。
大模型本身并不构成产品护城河,真正的护城河在于:你如何利用这些工程框架,将大模型的认知能力与你所在行业的垂直数据、专属工具深度绑定,构建出稳定、可靠且具有商业闭环的复杂工作流。
希望这篇文章能帮你简单理解 AI 落地的底层框架,帮助你在与研发沟通时能无缝对话,结合自身业务需求,选择最合适的内容落地。
最后
从0到1!大模型(LLM)最全学习路线图,建议收藏!
想入门大模型(LLM)却不知道从哪开始? 我根据最新的技术栈和我自己的经历&理解,帮大家整理了一份LLM学习路线图,涵盖从理论基础到落地应用的全流程!拒绝焦虑,按图索骥~~
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取