通信与并行系列(二)《大模型并行策略与通信优化》
摘要:随着模型规模扩大,单卡训练面临算力、显存和效率瓶颈,多卡并行成为必要选择。主流并行策略包括数据并行(处理不同数据批次)、模型并行(参数切分)及混合并行,需根据模型规模和硬件资源选择。通信优化是关键,涉及点对点和集合通信(如Allreduce),通过计算通信重叠、拓扑感知和DualPipe等技术减少空闲时间。这些方法显著提升训练效率,未来仍需持续优化以适应更大模型和硬件发展。
目录
1. 点对点通信(Point-to-Point Communication)
2. 集合通信(Collective Communication)
本文将系统介绍大模型训练中常用的并行策略、通信基础原理及优化方法,帮助开发者理解并掌握大规模模型训练的关键技术。
从单卡到多卡:训练需求的演变
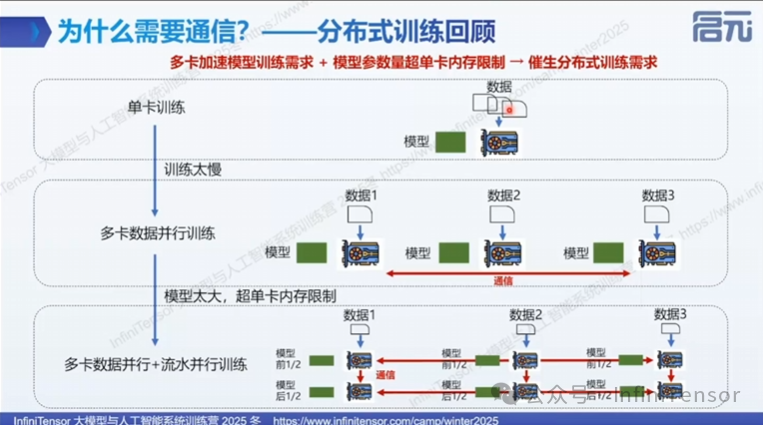
1. 单卡训练的局限
-
• 算力瓶颈:单张消费级显卡算力有限,训练大型模型需数月甚至数年
-
• 显存限制:模型参数量超过显存容量
-
• 训练效率:单卡训练速度慢,无法满足快速迭代需求
2. 多卡训练的必要性
-
• 算力扩展:通过多卡并行,将计算任务分配到多张卡上
-
• 显存扩展:通过模型切分,将模型参数分散到多张卡上
-
• 训练加速:通过并行化,显著缩短训练时间
大模型训练的三大并行策略
1. 数据并行(Data Parallelism)
-
• 核心思想:每张卡上放置相同的模型,但处理不同的数据批次
-
• 工作流程:
-
• 每张卡独立进行前向计算
-
• 计算梯度
-
• 梯度同步(如Allreduce)
-
• 更新模型参数
-
-
• 优势:实现简单,适合大规模集群
-
• 瓶颈:通信开销随卡数增加而增加
2. 模型并行(Model Parallelism)
-
• 核心思想:将模型按层或参数切分,分配到不同卡上
-
• 子类型:
-
• 流水线并行(Pipeline Parallelism):按层切分,形成计算流水线
-
• 张量并行(Tensor Parallelism):按参数维度切分,如将矩阵按列切分
-
-
• 优势:解决单卡显存不足问题
-
• 瓶颈:需要协调不同卡间的计算依赖
3. 混合并行(Hybrid Parallelism)
-
• 核心思想:结合数据并行和模型并行,实现最优的资源利用
-
• 典型实现:数据并行 + 流水线并行 + 张量并行
-
• 优势:充分利用计算资源,适应不同规模的模型
-
• 复杂性:实现难度较高,需要精细的调度策略
选择策略:
-
• 根据模型规模、硬件资源和训练目标选择合适的并行策略。对于超大规模模型(>100B),通常需要采用混合并行策略。
通信基础:点对点与集合通信
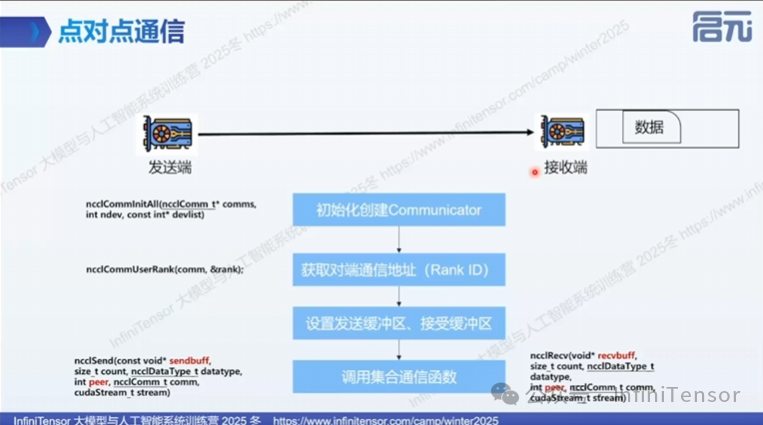
1. 点对点通信(Point-to-Point Communication)
-
• 基本操作:发送端向接收端发送数据
-
• 典型场景:在流水线并行中,将前一层的输出发送给下一层
- • 关键步骤:
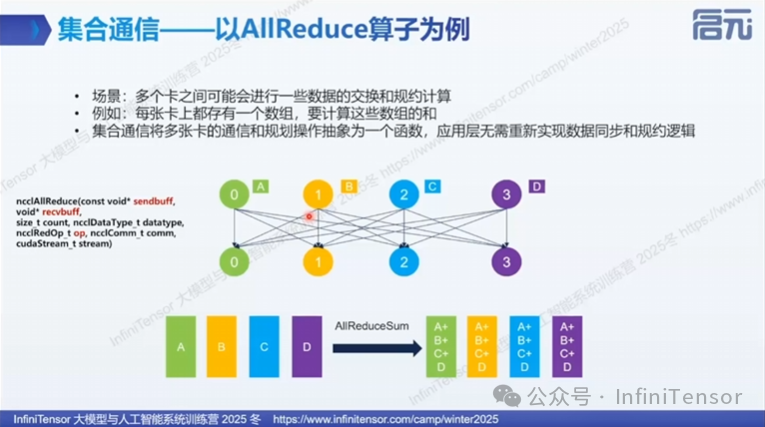
2. 集合通信(Collective Communication)
-
• 核心功能:多卡间进行数据同步操作
-
• 常用算子:
-
• ①Allreduce:求和/平均所有节点数据。Allreduce 做规约(常见 sum),平均是 sum 后再除以 world size(有的框架提供 avg 但本质仍是规约+缩放)。
-
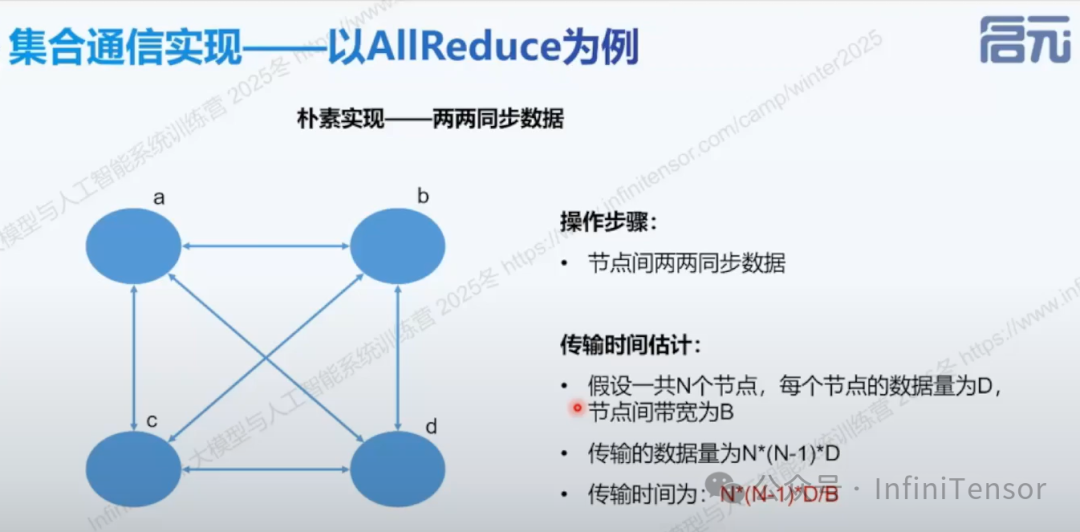
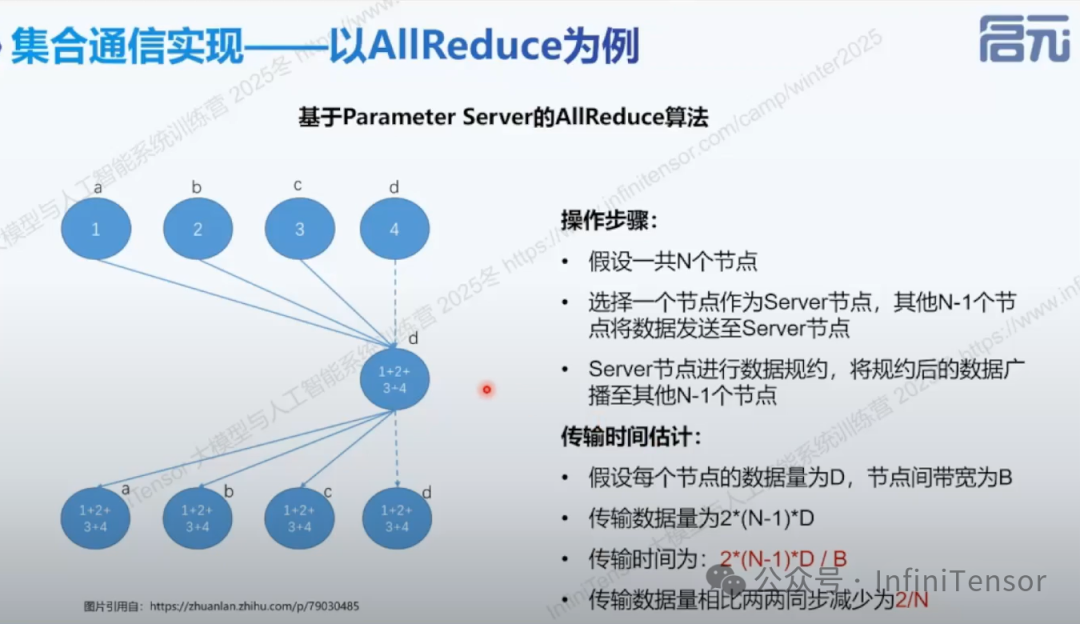
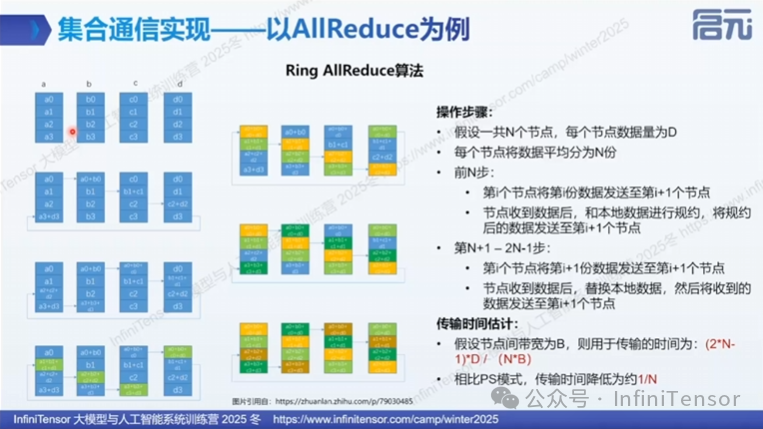
-
• ②AllGather:收集所有节点数据
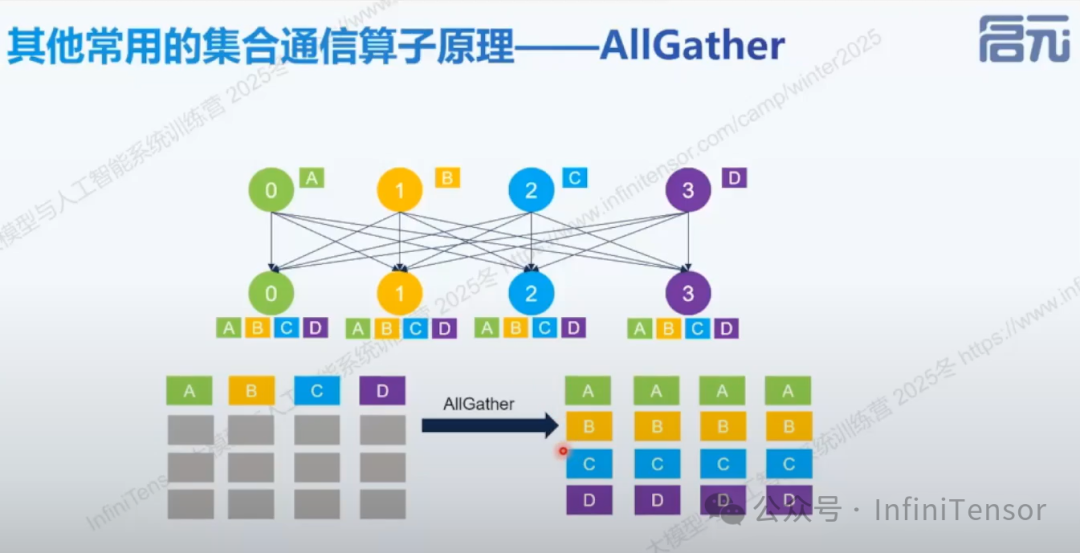
-
• ③AlltoAll:节点间的全交换通信。
-
• 通信抽象:集合通信接口将复杂的通信操作抽象为简单的函数调用,使开发者无需了解底层实现细节。
通信优化
1. 计算通信重叠
-
• 问题:通信操作通常耗时较长,导致GPU空闲
-
• 解决方案:在通信的同时,GPU继续执行计算任务
- • 分布式矩阵乘
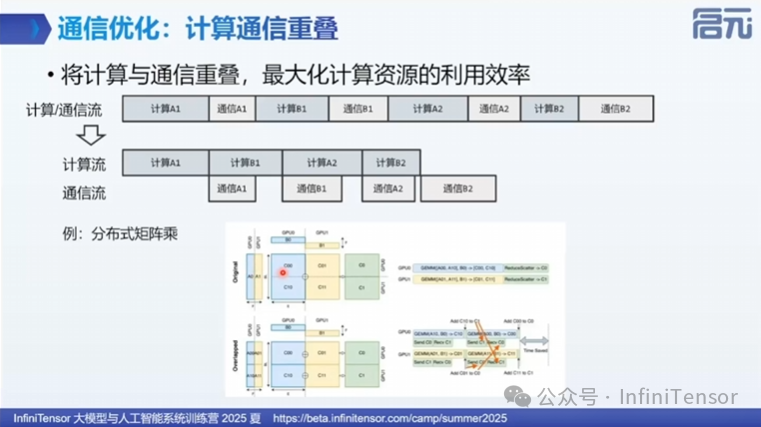
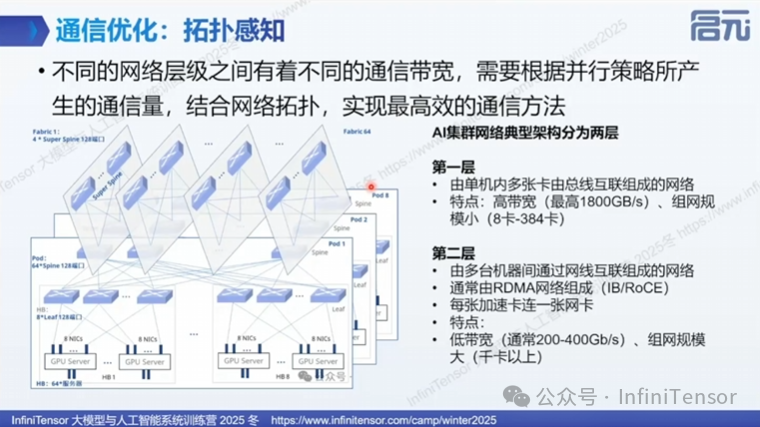
2. 拓扑感知
3. DualPipe
1F1B 策略虽然让设备交替执行前向与后向计算,但受限于设备间的依赖关系,时间轴上留下了大量灰色的空闲“气泡”,造成算力浪费;ZB1P 在流水线调度中优先计算和传输输入梯度,并将权重梯度的计算延后,以填补流水线空闲时间。
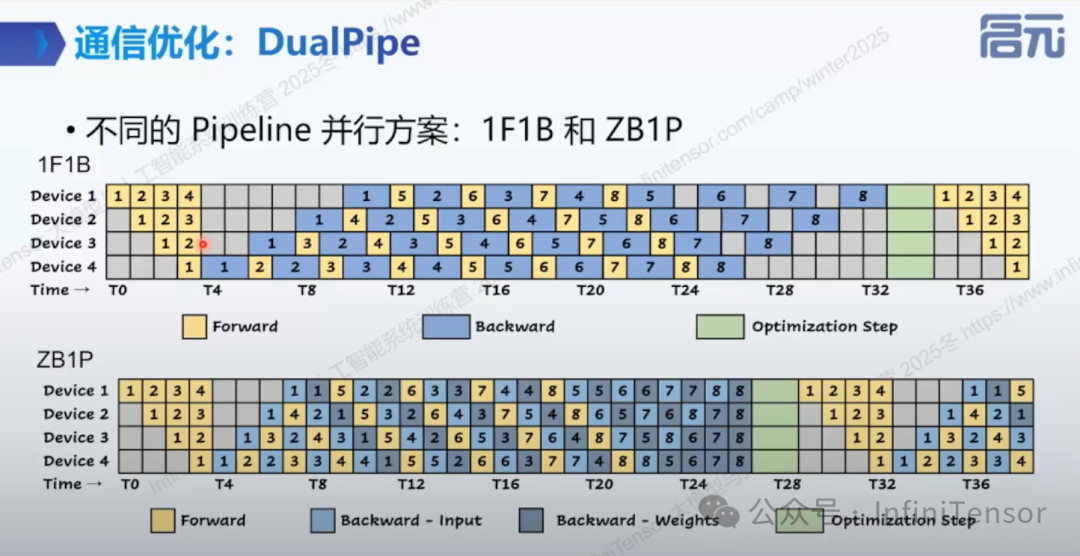
DeepSeek 提出的DualPipe通信优化技术的两种实施形态,旨在解决大规模模型训练中的通信瓶颈。上半部分的 DualPipe 描绘了一个双向并行的流水线系统(8个设备),它利用两组微批次数据从相反方向(Up to Down 和 Down to Up)穿过流水线,并结合 ZB1P 的细粒度切分策略(区分输入梯度和权重梯度),实现了前向传播与后向传播的并行重叠(图中橙绿混合色块),从而最大化地填补计算空隙并平衡网络带宽。下半部分的 DualPipeV 则是一种交错式(Interleaved)或虚拟化的变体,展示了如何在较少的物理设备(如4个)上,通过在同一设备上交替处理模型的“前半部分层”和“后半部分层”,在保持高吞吐量的同时灵活适配硬件资源,进一步减少流水线中的“气泡”。

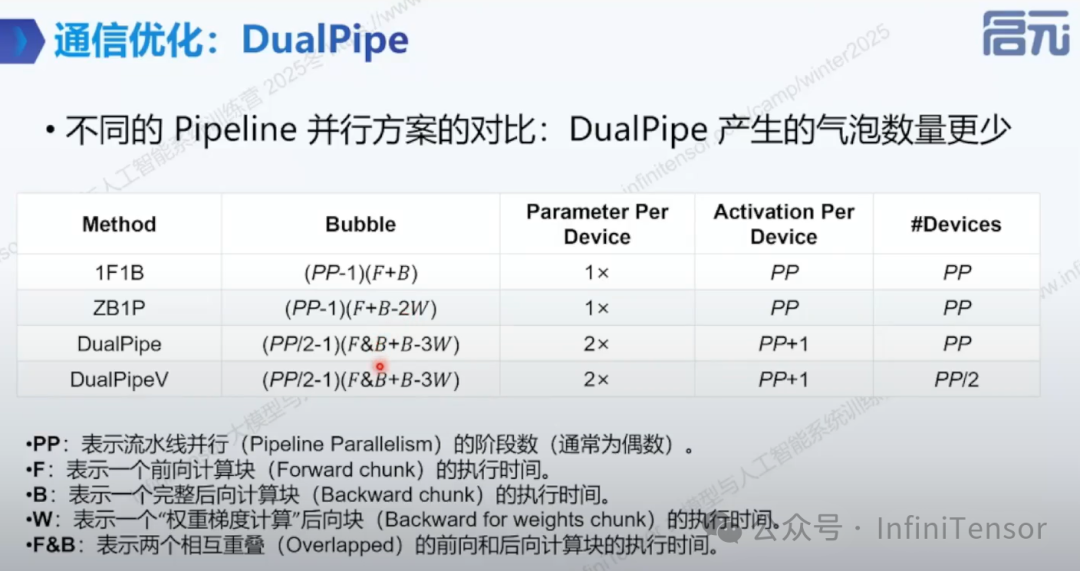
通过具体的数学公式(Bubble 栏)证明:相比传统的 1F1B 和 ZB1P,DualPipe 系列方案能显著大幅减少流水线中的“气泡”(空闲等待时间);但这同时也揭示了其代价——单设备的 参数存储(Parameter Per Device) 翻倍以及 激活值(Activation) 开销增加,体现了该算法“以显存空间换取计算时间”的核心优化哲学。
总结与展望
大模型训练的并行策略与通信优化是大规模AI训练的核心技术。通过合理选择并行策略、优化通信算法、实现通信与计算重叠,可以显著提升训练效率,降低训练成本。
随着模型规模的持续扩大和硬件技术的不断进步,这些优化技术将变得越来越重要。对于AI从业者而言,深入理解并掌握这些技术,是高效训练大规模模型的关键。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)