InforMARL解读:Dec-POMDP图信息聚合
论文提出了一种基于图神经网络(GNN)的可扩展多智能体强化学习方法InforMARL,通过智能信息聚合解决局部观测下的协作问题。该方法使用GNN聚合Actor和Critic的局部信息,采用注意力机制选择重要邻居信息,并通过多层网络实现高阶信息传播。在集中训练分布式执行(CTDE)框架下,Critic使用图信息聚合模块处理可变数量智能体。实验在四种导航任务中验证了该方法的有效性,结果表明仅使用局部信
原文献:Scalable Multi-Agent Reinforcement Learning through Intelligent Information Aggregation,2023ICML
官方GitHub地址:https://github.com/nsidn98/InforMARL
局部观测下,使用GNN聚合Actor和Critic智能体的局部信息,并用分布式方式去计算所有智能体的路径。
结构构成:四个模块
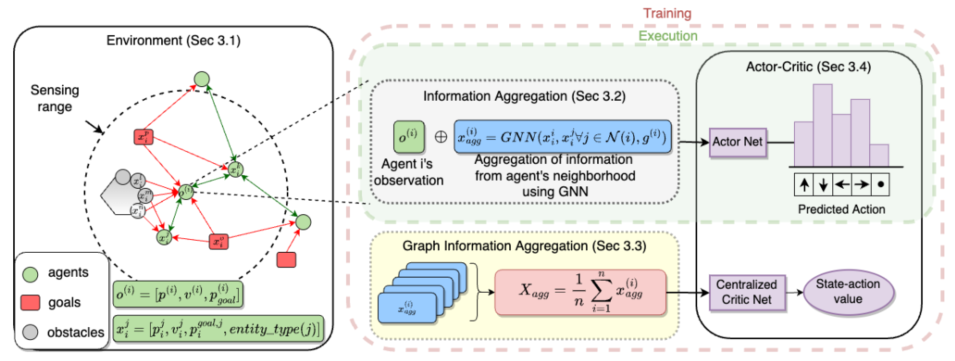
环境
局部观测信息包括:位置、速度、目标相对位置
图gi中的每个节点j有节点特征
![]()
(实体类型:智能体,障碍物,目标)
图中智能体和智能体之间是双向边,表示通信通道,智能体和实例间是单向边,表示不能进行通信只是单方面的观测。
信息聚合
使用带有信息传递框架的GNN推断每个智能体周围的局部邻域信息,即UniMP,一种graph transformer的变体,每一层更新为
![]()
,注意力系数计算
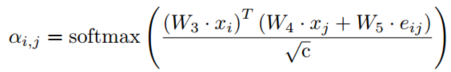
。
利用注意力机制,智能体根据重要性选择邻居信息优先权,利用多层网络构建信息传递使信息可以在智能体的“高阶邻居”间传播。
对每个智能体,该模块将来自图中相邻节点的信息聚合到一个固定大小的向量
中。观测向量和聚合向量构成的连接向量作为actor网络的输入。
图信息聚合
在CTDE(集中式训练分布式执行)设置中训练模型时,Critic会将环境中所有智能体的状态-动作对作为一个级联向量,为使训练可转移到可变数量的智能体并帮助课程学习,将级联替换为图信息聚合模块。该模块类似于用GNN聚合智能体邻居信息的信息聚合模块。
应用全局均值池化算子
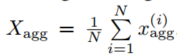
来聚合图中更新的节点特征。与级联向量不同,是固定大小向量,与智能体数量无关。将
向量作为critic网络输入。
AC网络
AC网络可以是MLP或RNN,使用LSTM或GRU。文中提出的信息聚合方法可以与任何标准MARL算法(MADDPG、MATD3、MAPPO、QMIX、VDN等)结合使用。
实验
通过修改MAPE,在4种不同的导航任务上评估模型。所有环境中,N个智能体遵循双积分动力学在2D空间移动,离散动作空间,可以控制x、y方向上的单位加速度。
-
- Target(N智能体,N静态目标点)
- Coverage(覆盖,智能体可以去任何目标点)
- Formation
- Line
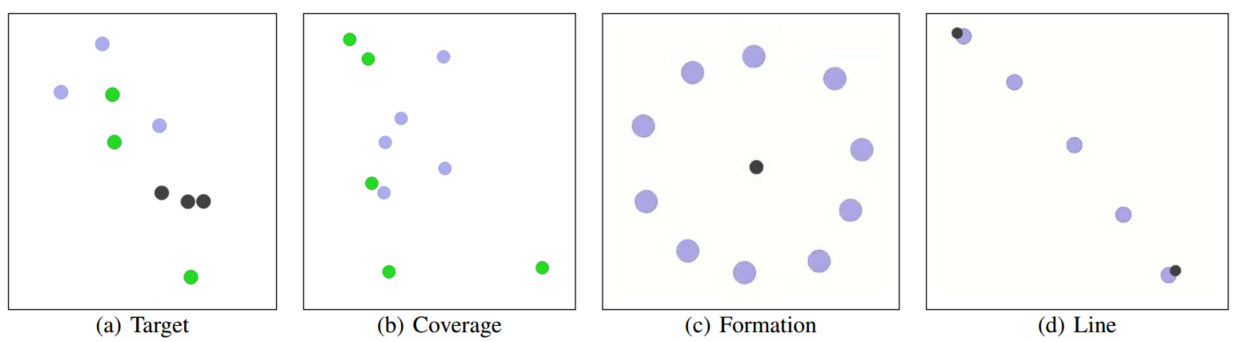
实验中选择MAPPO作为InforMARL的MARL算法。
定义三种信息模式来表示智能体可获得的信息量:
- Local(自身位置、速度以及目标相对位置,InforMARL使用)
- Global(在local基础上增加其它所有实体的相对位置,其它使用MAPE场景的算法使用)
![]()
- Neighborhood(在local基础上增加在智能体邻域范围内的其它实体的相对位置,固定最大邻域实体数,因此观测向量维度固定,不足最大实体的补零)
激励实验
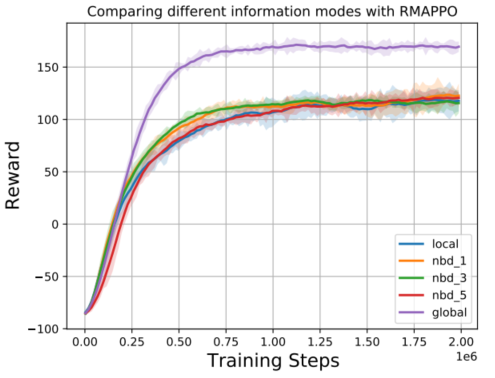
在3A-3O环境下,RMAPPO(使用RNN的MAPPO)三种信息模式可见global模式的优势,同时在nbd-5情况下,尽管同样能接受其它5个实体信息,但是仍与global有差距(存在感知范围限制)。
Target
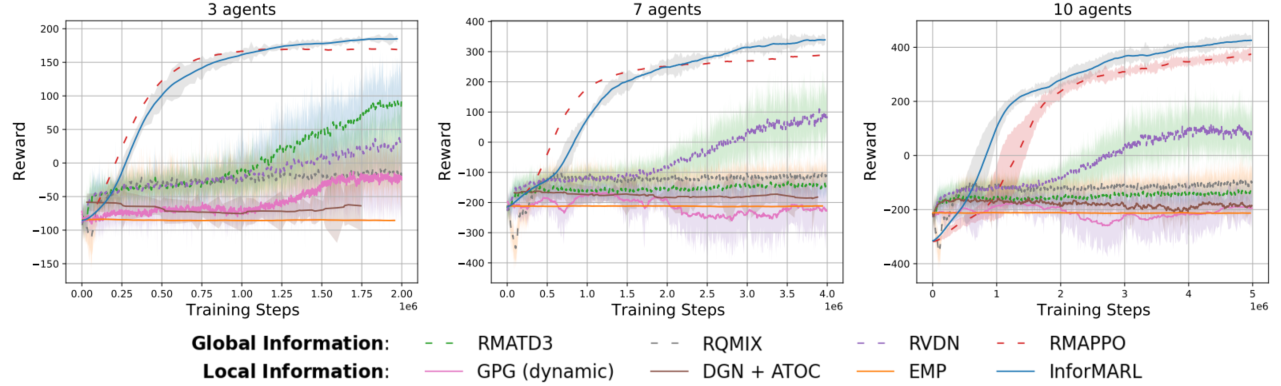
尽管只有local信息,但InforMARL做到了与RMAPPO同样甚至更好的效果,并且尽管InforMARL获得的信息少很多但是需要的训练步和RMAPPO差不多。
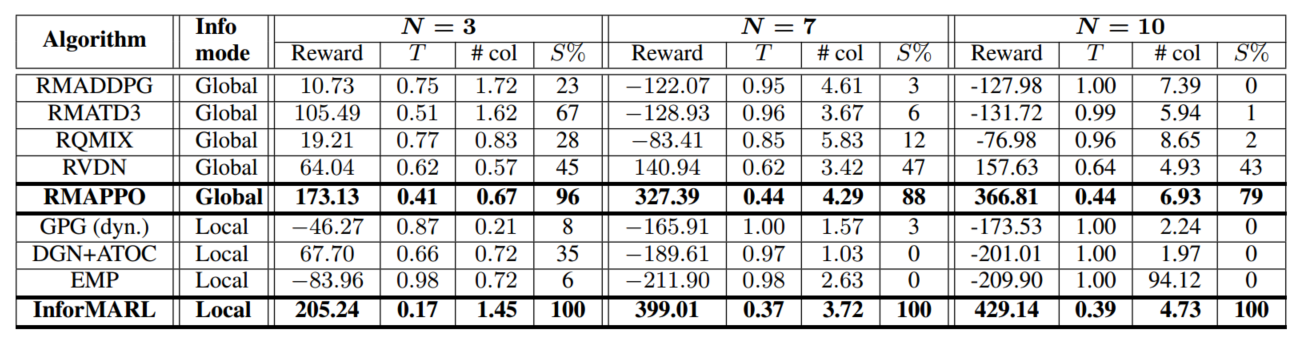
(T:智能体平均到达目标所需的episode,col:发生的碰撞总数,A-A & A-O,S%:所有智能体均到达目标的episodes占比)
Other Tasks
在3-A场景下训练,在3-A和7A场景中测试。
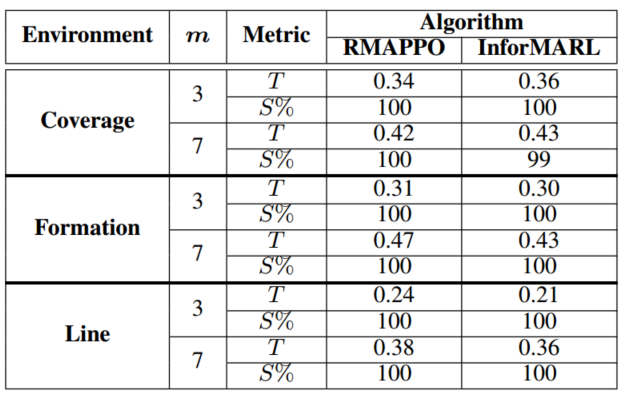
RMAPPO需要全局信息来学习成功的策略,但InforMARL只需要本地邻域信息。这说明了当智能体只能访问本地信息时,InforMARL中的信息聚合模块的有效性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)