AI编译器系列(二)《AI 编译器中的前端优化》
本文系统介绍了前端模型优化技术,重点分析了图层优化方法及其应用。主要内容包括:1)图层优化技术,通过常量折叠、冗余节点消除、算子融合和数据布局转换解决结构冗余和读写冗余问题;2)模型优化案例分析,针对Gather操作性能问题提出优化策略;3)CUDAGraph解决方案,通过预定义计算图减少CPU-GPU交互开销;4)实践环节展示ONNX模型优化代码示例。文章强调前端优化技术对提升模型性能的重要性,
目录
本节课主要讲述常用前端优化技术、模型优化案例分析、CUDA Graph 简介等内容。
常用前端优化技术
1. 图层优化概述
-
• 定义:将一种计算图结构,在算术结果不变的情况下,基于一系列预先写好的模板,对计算图进行相应的图替换操作。
-
• 计算图三要素:拓扑、张量、算子。
-
• 优化目标:解决结构冗余和读写冗余。
2. 结构冗余与解决方法
-
• 结构冗余:模型构建和执行中的无效计算节点或重复计算子图。
-
• 解决方法:常量折叠、节点消除、分支合并。
3. 读写冗余与解决方法
-
• 读写冗余:数据处理和传输中的重复读写。
-
• 解决方法:算子融合、布局转换。
4. 具体优化技术
-
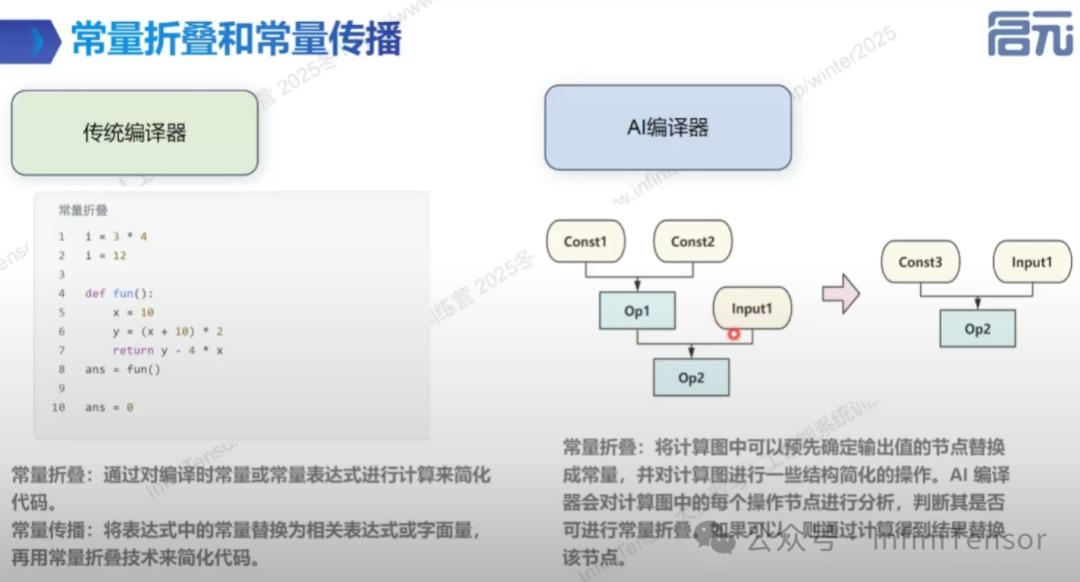
• 常量折叠和常量传播
-
• 定义:提前识别并折叠输入为常量的算子。
-
• 示例:传统编译器与 AI 编译器中的常量折叠对比。
-
-
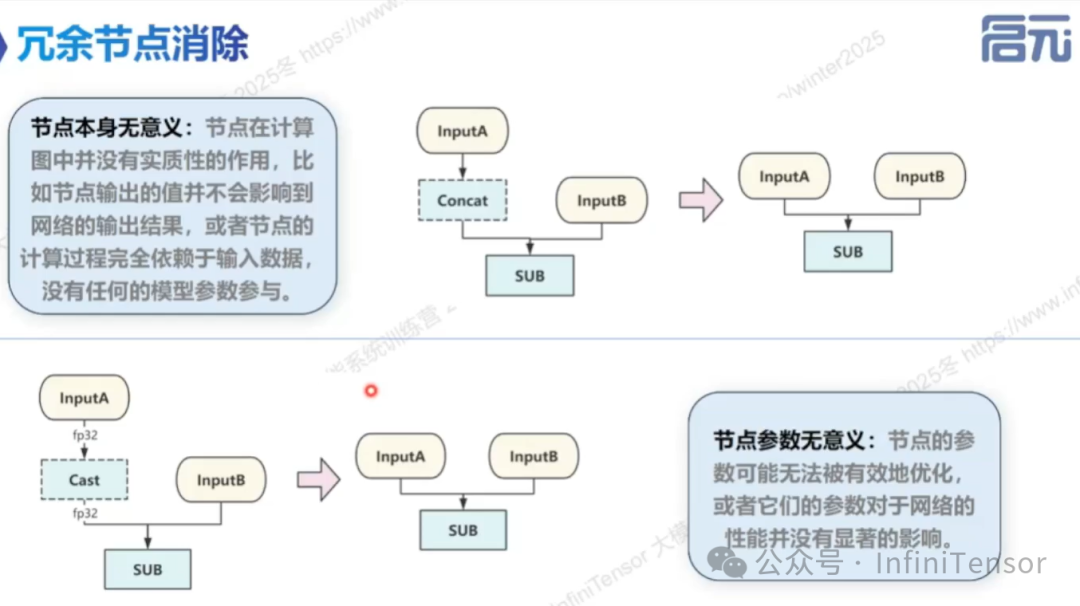
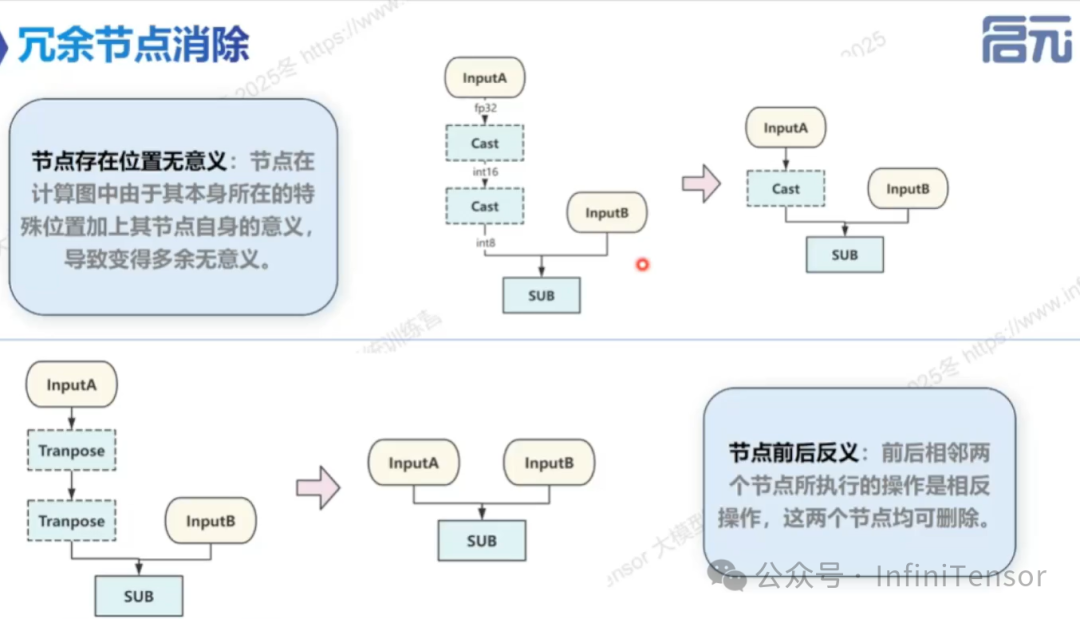
• 冗余节点消除
-
• 定义:删除计算图中无实质作用的节点。
-
• 类型:节点本身无意义、节点参数无意义、节点存在位置无意义、节点前后反义。
-
• 示例:死代码消除在传统编译器与 AI 编译器中的对比。
-
-
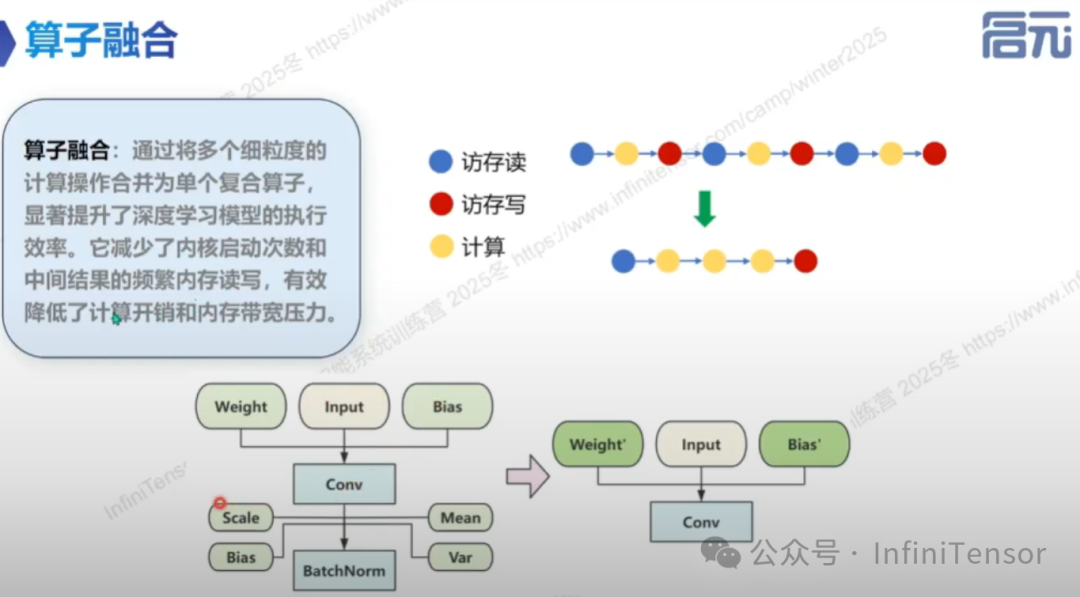
• 算子融合
-
• 定义:将多个算子融合为一个算子以优化计算过程。
-
• 示例:Conv 与 BatchNorm 的融合。
-
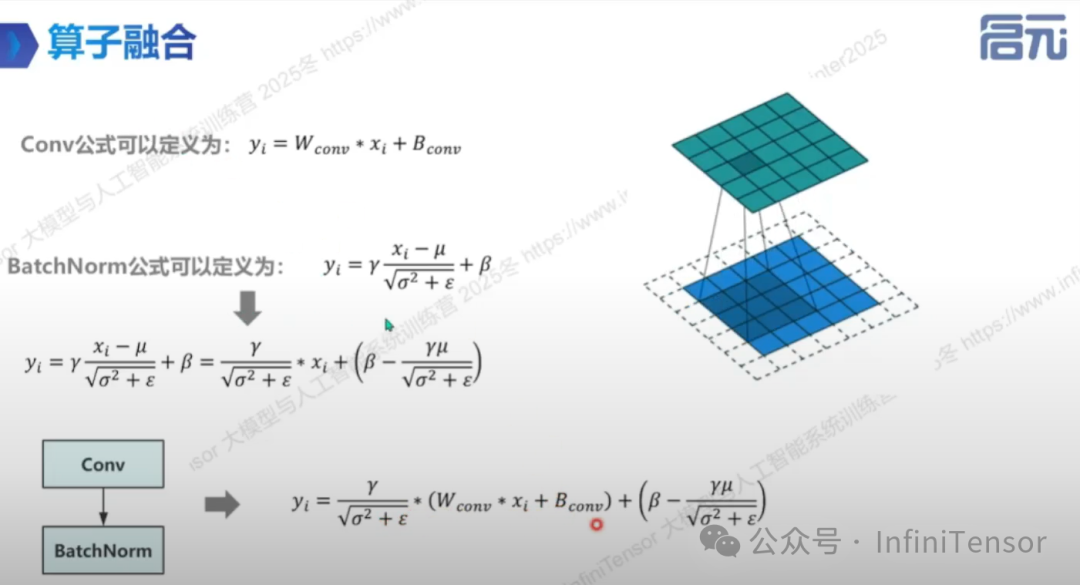
-
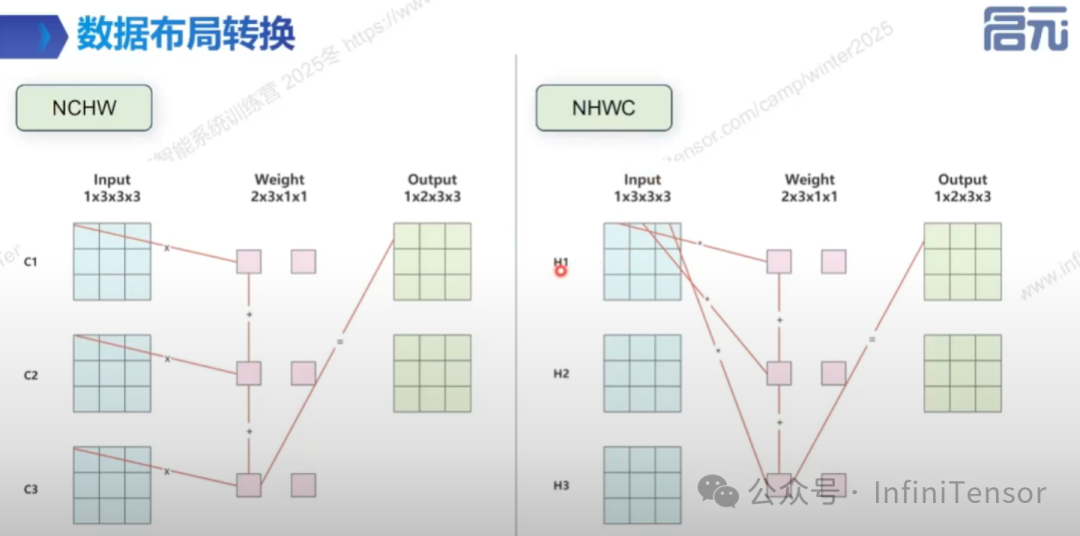
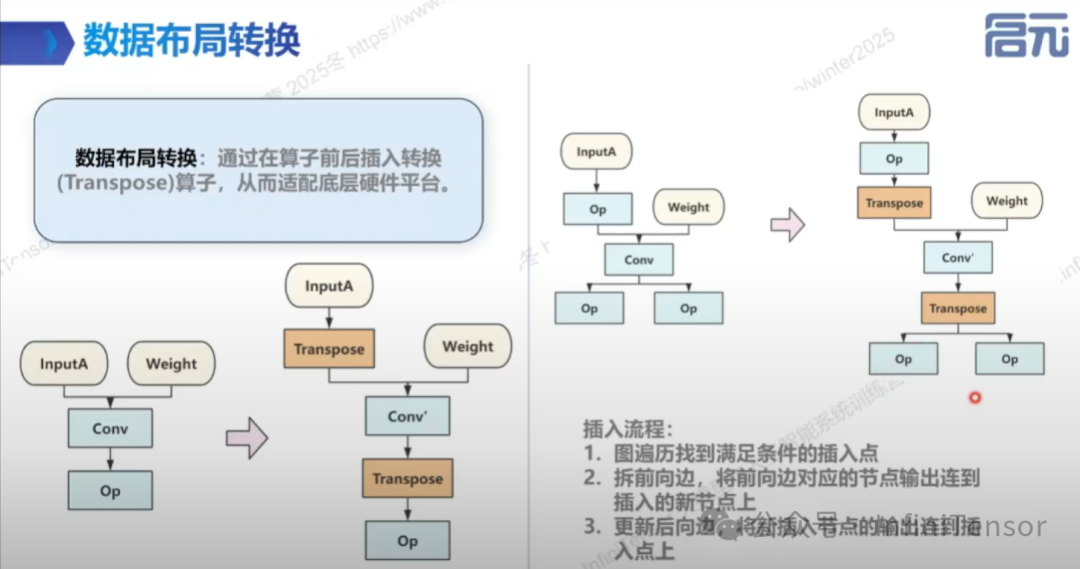
• 数据布局转换
-
• 定义:修改数据布局以减少访存耗时。
-
• 常见布局:NCHW 与 NHWC。
-
• 示例:Conv 算子在不同数据布局下的性能差异。
-
模型优化案例分析
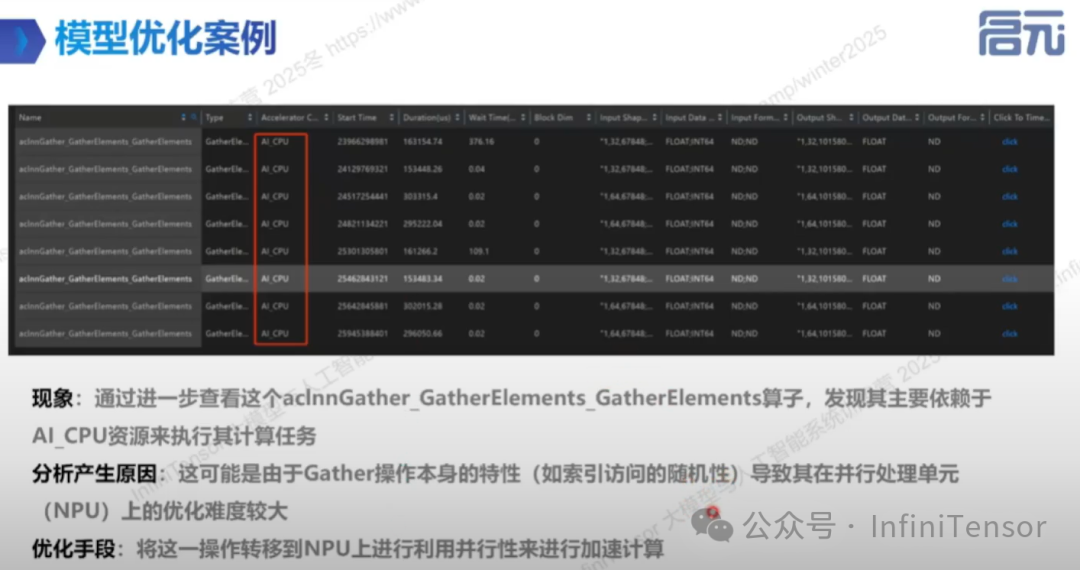
1. 案例背景
-
• 模型性能分析:发现 Gather 操作耗时占比高。
-
• Gather 操作特性:根据 indices 值从 data 中取值,indices 无规律时性能损失大。
2. 优化策略
-
• 分析 Gather 操作逻辑:发现 indices 取值有一定规律性。
-
• 实现 NPU 上的对应算子:利用 NPU 并行性加速计算。
-
• 图替换操作:使用 Graph Surgeon 进行图替换。
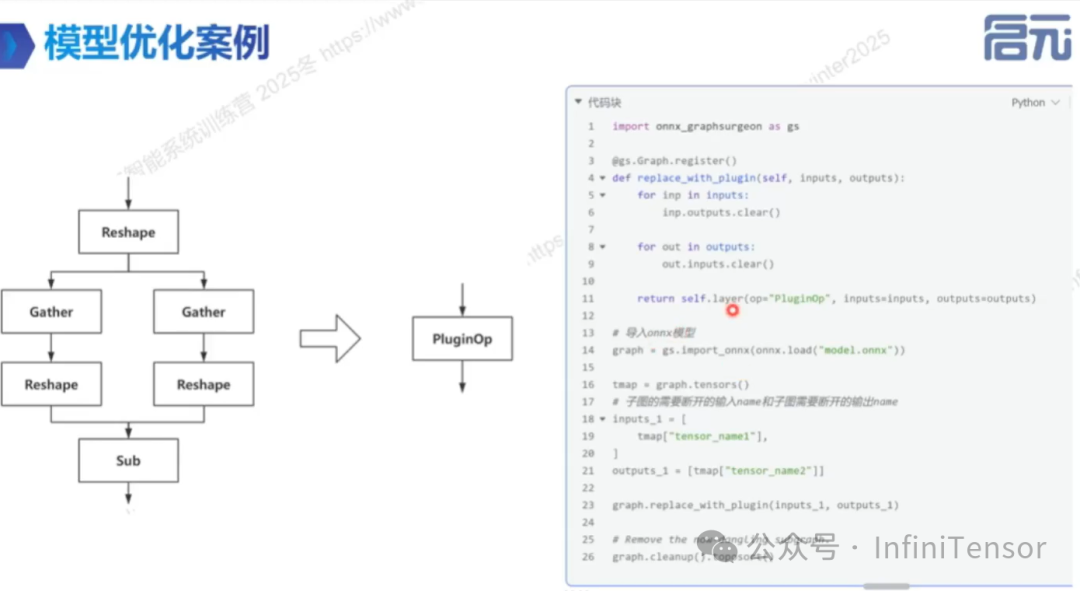
CUDA Graph
1. 传统串行任务提交模式的挑战
-
• 内核启动延迟
-
• CPU-GPU 交互瓶颈
2. CUDA Graph 革新性解决方案
-
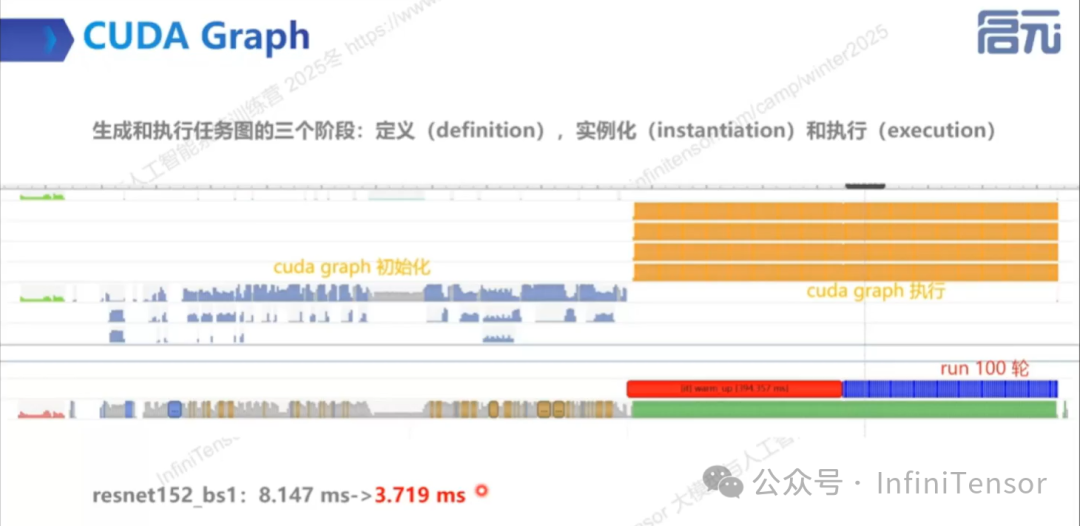
• 拓扑预定义:将计算流程编码为 DAG 流图,一次性提交整个计算图。
-
• 极低开销:通过 CUDA graph launch 触发 GPU 直接执行预编译指令序列。
-
• 局限性:对静态计算图的强依赖性。
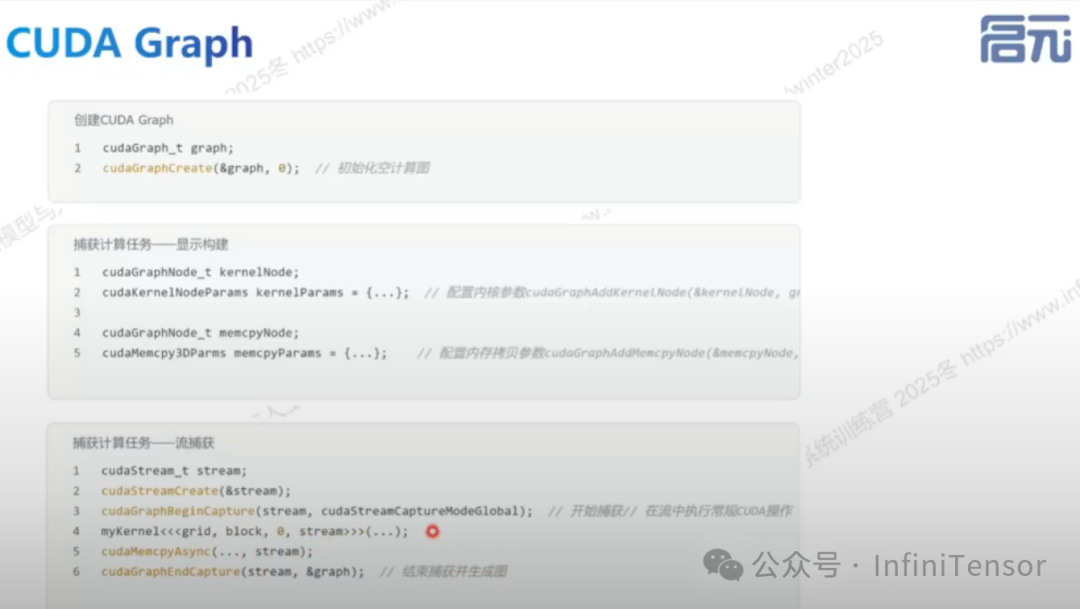
3. CUDA Graph 使用示例
-
• 创建 CUDA Graph:定义数据结构,初始化空计算图。
-
• 捕获计算任务:显式构建或流式捕获计算节点。
-
• 实例化可执行图:创建实例化可执行图并提交执行。
实践环节与代码展示
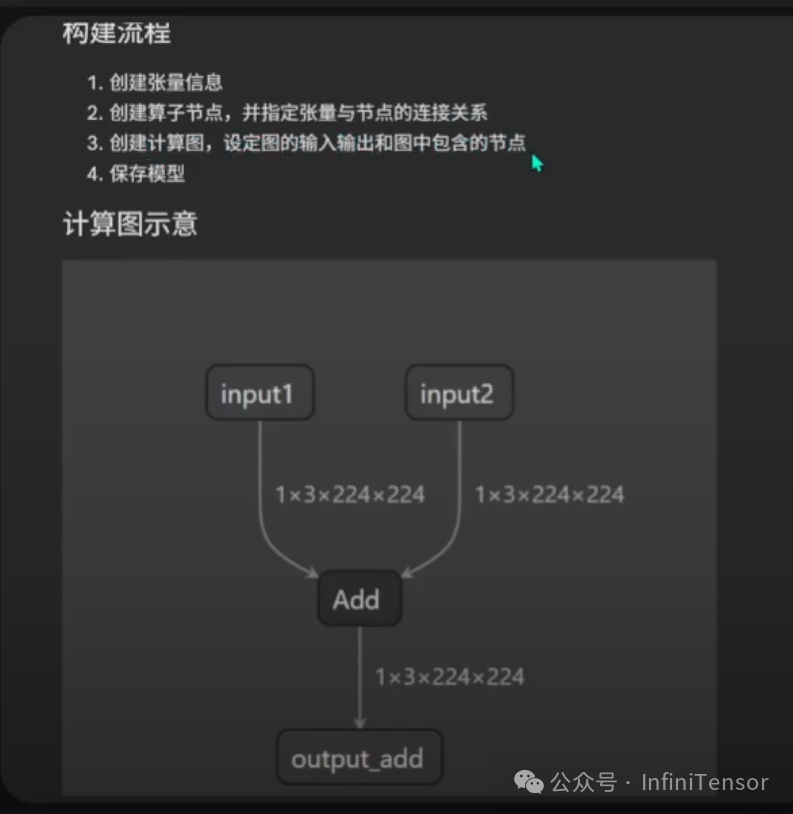
1. 构建 ONNX 模型流程
2. 优化技术代码示例
-
• 常量折叠示例。
-
• 冗余节点消除示例(相反意义的 Transpose)。
-
• 算子融合示例(Conv 与 BatchNorm 融合)。
3. 实践建议
-
• 使用 ONNX Simplifier 进行模型优化。
-
• 利用 Netron 工具可视化 ONNX 模型。
总结
本节课梳理了常用前端优化技术,强调模型优化案例与 CUDA Graph 的重要性。下节课将介绍 AI 编译器后端优化技术,探讨更多实际模型优化案例。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)