安全使用OpenClaw:从官方威胁模型出发,全面规避AI智能体风险
OpenClaw的强大,建立在「单用户可信环境」的安全假设之上。它不是“开箱即用零风险”的工具,而是需要合规部署、严格配置的专业AI框架。需要坚守网关不暴露、单用户隔离、沙箱必开启、插件可信、权限最小化五大原则,安全使用OpenClaw,让AI助手成为效率工具,而非安全隐患。
OpenClaw作为当下热门的开源AI智能体执行框架,能让大模型直接操控文件、浏览器、系统命令,成为真正能“落地干活”的数字助手。但便捷的背后,它的安全模型与传统应用完全不同——默认面向单用户可信环境、非多租户隔离、沙箱默认关闭,一旦配置不当,极易引发权限失控、数据泄露、系统被接管等风险。
本文结合OpenClaw官方安全策略([SECURITY.md](SECURITY.md))与威胁模型,梳理核心风险点,并给出可直接落地的安全使用规范,让你在享受AI效率的同时,守住安全底线。
一、先搞懂:OpenClaw官方安全信任模型
OpenClaw的所有安全规则,都基于「单用户可信操作员」核心设计,这是安全使用的前提:
1、非多租户设计
网关不做用户间权限隔离,通过网关认证的用户,默认是完全可信操作员,session 仅做路由,不做权限校验。
2、网关与节点同信任域
网关是控制平面,节点是执行平面,配对后节点拥有网关级别的系统权限。
3、插件 = 可信代码
安装 / 启用插件,等同于授予插件网关宿主同级系统权限,插件读写文件、执行命令均为预期行为。
4、沙箱默认关闭
命令执行优先在宿主系统运行,而非沙箱,降低安全门槛但提升风险。
5、网关仅允许本地访问
默认绑定127.0.0.1本地回环,严禁直接暴露公网。
违背这个模型(如多用户共用网关、公网暴露),所有安全防护都会失效。
二、OpenClaw核心安全风险(官方+实战威胁)
结合官方安全文档与公开威胁情报,OpenClaw的风险集中在配置错误、权限失控、生态风险三大类:
1. 网关公网暴露(高危)
-
风险:将网关绑定
0.0.0.0公网IP,会被Shodan、网络扫描工具批量发现,成为攻击目标。 -
危害:未授权访问者可直接操控AI执行命令、窃取数据,甚至接管服务器。
-
官方认定:公网暴露属于违规部署,不在安全保障范围。
2. 权限隔离缺失(高危)
-
风险:多用户共用同一网关/宿主,普通用户可越权查看他人会话、操作敏感数据。
-
危害:垂直/水平越权,打破“仅管理员可操作”的权限规则。
-
官方规则:不支持多租户隔离,共用网关导致的权限问题不属于漏洞。
3. 沙箱默认关闭,命令执行无限制(高危)
-
风险:
agents.defaults.sandbox.mode默认off,AI可直接执行宿主系统命令。 -
危害:AI被诱导或误操作时,可删改核心数据、泄露敏感文件。
4. 插件/技能生态投毒(中高危)
-
风险:ClawHub插件市场存在恶意插件,伪装成工具窃取API密钥、系统权限。
-
危害:插件获得系统权限后,可后台窃取数据、植入后门。
5. 敏感配置信息泄露(中危)
-
风险:大模型API密钥、网关认证信息明文存储在配置文件中。
-
危害:配置文件被读取后,攻击者可控制AI、盗用模型额度。
6. 提示词注入与AI误操作(中危)
-
风险:纯提示注入无权限边界绕过,官方不计入漏洞,AI易被诱导执行违规操作。
-
危害:AI“幻觉”导致误删文件、泄露隐私、执行高危指令。

三、安全使用最佳实践(官方加固+落地规范)
按照OpenClaw官方安全指导,结合行业加固方案,按以下步骤配置,可规避90%以上风险:
1. 部署加固:死守网关访问边界
-
强制网关绑定本地回环:
配置gateway.bind="loopback",或CLI执行openclaw gateway run --bind loopback。
-
远程访问禁用公网暴露:
用SSH隧道或Tailscale内网穿透,保持网关本地监听,杜绝公网扫描。
-
开启网关强认证:
配置密码/Token认证,禁用dangerouslyDisableDeviceAuth危险选项。
2. 权限隔离:严格遵循单用户模型
-
个人用户:一台设备只运行一个网关,专属使用。
-
企业/多用户:
每个用户独立VPS/操作系统用户,部署独立网关,彻底隔离信任域。
3. 沙箱与执行权限加固
-
强制启用沙箱:
agents.defaults.sandbox.mode="all",所有命令优先在沙箱执行。
-
限制文件操作范围:
开启tools.exec.applyPatch.workspaceOnly=true、tools.fs.workspaceOnly=true,仅允许操作工作区目录。
-
禁用子代理越权:
关闭sessions_spawn权限,避免权限委托扩散。
4. 插件全生命周期管控
-
白名单机制:
用plugins.allow指定仅信任的插件ID,拒绝未知插件。
-
来源校验:
仅安装官方认证插件,禁用第三方未审核插件/技能。
-
最小权限:
不授予插件超出需求的系统权限,定期清理无用插件。
5. 运行环境安全
-
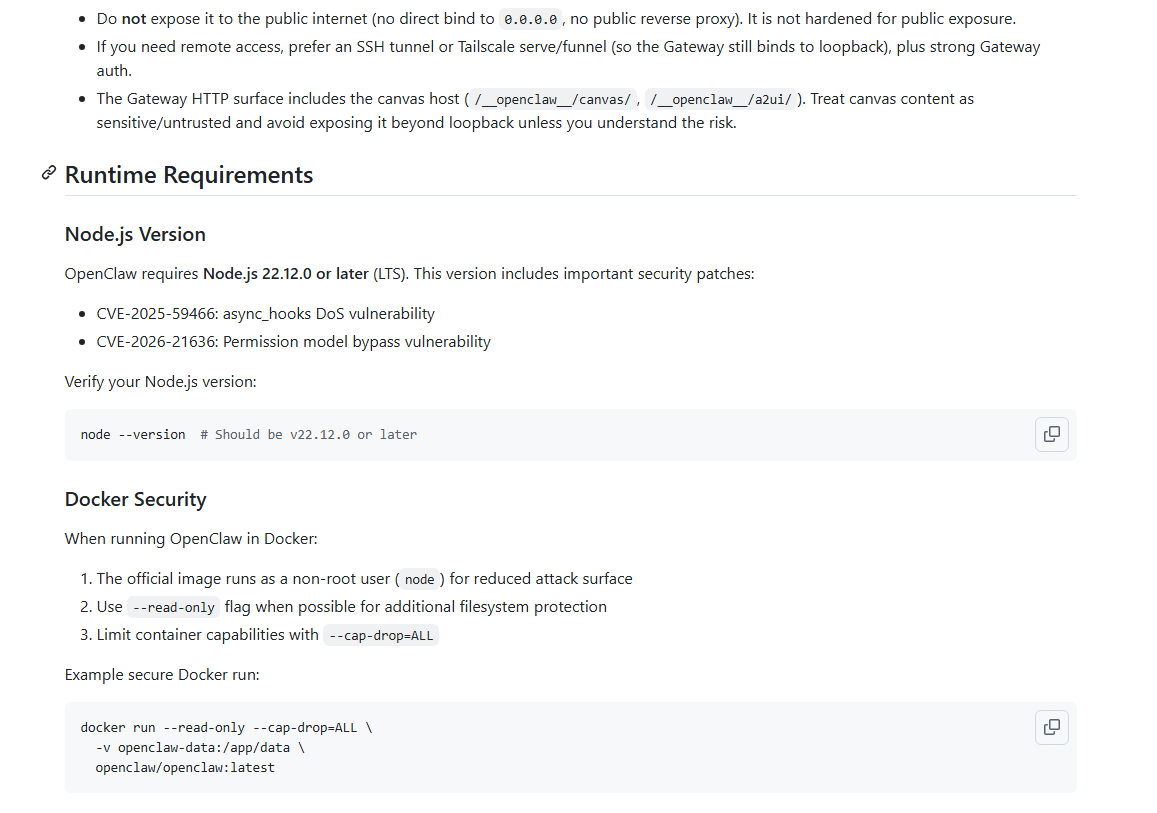
升级Node.js:
必须使用v22.12.0及以上版本,修复已知DoS、权限绕过漏洞。
-
Docker安全部署:
用非root用户运行,添加--read-only、--cap-drop=ALL限制容器权限。
-
临时目录隔离:
仅使用/tmp/openclaw官方临时目录,禁止随意读写系统临时文件。
6. 审计与监控
-
定期安全扫描:
执行openclaw security audit --deep检测风险配置,用--fix自动修复。
-
操作留痕:
开启全量操作日志,记录AI执行的命令、文件操作,便于溯源。
-
敏感信息加密:
配置文件中的API密钥、认证信息加密存储,禁止明文暴露。

四、官方明确:这些场景不属于安全漏洞
在漏洞上报、风险排查时,以下情况OpenClaw官方不认定为漏洞,避免无效排查:
-
仅提示词注入,未突破认证/沙箱/白名单边界;
-
授权用户执行的正常本地操作(如
/export-session写入路径); -
可信插件的正常权限行为;
-
多用户共用网关导致的权限隔离问题;
-
手动开启
dangerous*配置项导致的安全弱化。

五、总结
OpenClaw的强大,建立在「单用户可信环境」的安全假设之上。它不是“开箱即用零风险”的工具,而是需要合规部署、严格配置的专业AI框架。
需要坚守网关不暴露、单用户隔离、沙箱必开启、插件可信、权限最小化五大原则,安全使用OpenClaw,让AI助手成为效率工具,而非安全隐患。
参考:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)