架构设计:安全 AI 产品的全生命周期(MLSecOps)
Google 在 2015 年发表过一篇著名论文《Hidden Technical Debt in Machine Learning Systems》(机器学习系统中的隐蔽技术债),其中有一张经典的图:在一个真实的 ML 系统中,核心的 ML 代码只占中间极小的一个方框,周围被数据收集、特征提取、数据验证、资源管理、监控、服务化基础设施等巨大的方块包围。安全环境是动态变化的。而 MLSecOps
架构设计:安全 AI 产品的全生命周期(MLSecOps)
你好,我是陈涉川,欢迎你来到我的专栏。这里是《硅基之盾:AI 与网络安全攻防全鉴》第五模块“工程落地”的开篇重头戏——第 38 篇《架构设计:安全 AI 产品的全生命周期(MLSecOps)》。这一篇不仅是从理论到实践的跨越,更是从“作坊式实验”到“工业化流水线”的质变。我们将深入探讨如何构建一套既能应对高速网络流量,又能抵御对抗性攻击的 AI 安全系统。”
引言:从霍格沃茨的实验室,到血肉横飞的真实战场
在前三十七篇文章中,我们更像是在霍格沃茨的实验室里钻研精妙的魔法。我们推导了对抗样本的数学原理,拆解了 LLM 的注入技巧,甚至在沙箱里用强化学习孵化了自动渗透的 Agent。在那个理想环境里,数据静静躺在 CSV 里,显存充裕,代码在 Jupyter Notebook 中优雅地一镜到底。
但当你试图将这套“完美算法”推向商业化——部署到拥有十万终端的企业,或者接入每秒吞吐量 10Gbps 的核心网关时,幻象瞬间破灭:
- 实验室里 99% 准确率的模型,上线第一天就因为一个未知的畸形包导致 OOM(内存溢出),干崩了客户的核心交换机。
- 模型推理延迟高达 500ms,生生把 C 端用户的网页加载时间拖慢了一倍,直接被运维老哥强行“拔线”。
- 高薪聘请的安全专家,每天的时间都耗在找数据、对字段、修 Bug 上,成了高级“数据搬运工”。
欢迎来到安全 AI 真实的工程世界。在这里,算法本身只占核心代码的极小部分,海面之下是庞大的数据管道、特征仓库、监控体系和高频对抗流水线。而解决这一切痛点的工业化方法论,正是 MLSecOps(Machine Learning Security Operations)——它不仅是 MLOps 的简单延伸,更是将机器学习(ML)、网络安全(Security)与开发运维(DevOps)深度融合的特种工程体系。本篇作为第五模块“工程落地”的总纲,将带你彻底抛弃作坊式思维,为你精细拆解从需求定义到模型退役的七阶全生命周期架构蓝图。
1. 交付危机:为什么安全 AI 容易死在“最后一公里”?
Google 在 2015 年发表过一篇著名论文《Hidden Technical Debt in Machine Learning Systems》(机器学习系统中的隐蔽技术债),其中有一张经典的图:在一个真实的 ML 系统中,核心的 ML 代码只占中间极小的一个方框,周围被数据收集、特征提取、数据验证、资源管理、监控、服务化基础设施等巨大的方块包围。
在网络安全领域,这种“头重脚轻”的现象更为严重,且伴随着独特的挑战:
- 数据的非平稳性(Non-Stationarity): 猫的照片过了一百年还是猫,但恶意的流量特征可能下周就变了。攻击者的 TTPs(战术、技术和程序)在不断演进,导致 Concept Drift(概念漂移)极其剧烈。
- 极端的误报容忍度: 在推荐系统中,推荐错了一部电影用户可能只是不点击;但在防火墙中,阻断了一个正常的支付请求(False Positive)可能导致巨大的商业损失;而漏过一个病毒(False Negative)则意味着数据泄露。
- 对抗性环境: 推荐系统的用户不会故意画花自己的脸来欺骗人脸识别模型,但黑客会。安全 AI 运行在一个时刻有人试图攻击它、欺骗它的敌对环境中。
- 隐私与合规: 安全数据往往包含敏感信息(IP、Payload、PII),数据管道必须严格符合 GDPR、甚至各国的数据出境法规。
因此,MLSecOps 并不是 MLOps 的简单复制,它是在 MLOps 的基础上,叠加了高频对抗更新、低延迟推理和强隐私合规的特种工程体系。
2. MLSecOps 核心架构概览
一个成熟的安全 AI 产品架构,通常由三个闭环组成:
- 开发环(Development Loop): 数据科学家和安全研究员进行特征工程、模型训练和验证。
- 部署环(Deployment Loop): 自动化打包、测试、金丝雀发布、模型服务化。
- 反馈环(Feedback Loop): 在线监控、漂移检测、对抗样本捕获、自动触发重训练。
我们将这个生命周期拆解为七个阶段,并在接下来的篇幅中逐一构建。
- Phase 1: 需求与威胁建模(Design & Threat Modeling)
- Phase 2: 数据工程与特征存储(Data Engineering & Feature Store)
- Phase 3: 模型开发与对抗训练(Model Development & Adversarial Training)
- Phase 4: 持续集成与持续训练(CI/CD/CT)
- Phase 5: 服务化部署策略(Serving Strategy)
- Phase 6: 全链路监控与观测(Observability)
- Phase 7: 治理与合规(Governance)
3. Phase 1: 战略设计与指标陷阱
一切工程的起点不是 import torch,而是明确“我们要解决什么安全问题”以及“如何衡量成功”。
3.1 重新定义评估指标:走出 Accuracy 的误区
在安全领域,Accuracy(准确率) 往往是最无用的指标。因为安全数据不仅是极度不平衡的(Imbalanced),而且代价也是不对等的。
假设你要检测网络流量中的 C2(命令与控制)通信。正常流量是 99.99%,恶意流量是 0.01%。哪怕你的模型直接“躺平”,把所有流量都预测为“正常”,你的 Accuracy 也能达到 99.99%。但这毫无意义。
在架构设计阶段,必须确立以下“业务向”指标:
- 精确率(Precision)与召回率(Recall)的权衡:
- 阻断型产品(如 WAF、IPS): 追求极高的 Precision。误报意味着业务中断,用户会因为无法下单而卸载你的产品。你宁可漏掉一次攻击,也不能误杀一个正常用户。
- 检测型产品(如 EDR、NTA): 追求较高的 Recall。SOC 分析师可以容忍每天处理几个误报工单,但不能容忍勒索软件在眼皮底下加密了服务器。
- F-Beta Score: 很多时候我们需要调整 \beta 值。例如在反欺诈场景,可能 F_{0.5} 更重要(侧重 Precision);在 APT 检测场景,可能 F_2 更重要(侧重 Recall)。
- 时间相关指标:
- TTL (Time To Label): 从发现新攻击到样本进入数据集的时间。
- TTD (Time To Deploy): 从模型开始重训练到推送到全网边缘节点的时间。在 MLSecOps 中,这个指标通常要求在小时级甚至分钟级。
3.2 威胁建模:为 AI 及其环境建模
在设计阶段,安全架构师必须对 AI 系统本身进行威胁建模。这不同于传统的 STRIDE 模型,我们需要考虑针对 ML 的攻击面(参考 MITRE ATLAS 框架):
- 数据投毒风险: 我们的训练数据来源是否包含不受控的公网数据?攻击者能否通过构造特定流量污染我们的数据集?
- 模型窃取风险: 如果模型部署在客户端(如手机端的反诈 APP),攻击者能否通过逆向工程提取模型参数?是否需要使用知识蒸馏(Knowledge Distillation)将大模型压缩为小模型再部署,以保护源模型?
- 推断攻击风险: API 是否暴露了过多的置信度信息,导致攻击者可以进行成员推理攻击?
架构决策点:
在设计初期,如果确定模型将面临高频对抗(如验证码识别、WAF),则必须在架构中预留“热更新”通道,并采用集成学习(Ensemble Learning)架构,避免单点模型被绕过。
4. Phase 2: 数据工程与特征仓库(The Fuel)
在安全 AI 中,特征工程的重要性远超模型算法的选择。代码是车,模型是引擎,但数据是油。如果是劣质油,法拉利也跑不过拖拉机。
4.1 原始数据摄取:处理海量异构数据
安全数据的特点是“脏、乱、快”。我们需要构建一个强大的 ETL(Extract, Transform, Load)管道。
- 异构性: 我们需要处理的数据包括非结构化的 HTTP Payload、半结构化的 JSON 日志、二进制的 PE 文件、时序的 NetFlow 统计数据,甚至图结构的资产关系。
- 流式处理(Streaming First): 攻击通常稍纵即逝。传统的 T+1 离线批处理(Batch Processing)只能用于事后取证,无法进行实时防御。现代 MLSecOps 架构强烈依赖 Kafka 或 Pulsar 作为数据总线,结合 Flink 或 Spark Streaming 进行实时特征提取。
案例:基于 Flink 的 DGA(域名生成算法)实时检测管道
- Source: 从 DNS Resolver 接收实时 DNS 查询日志流。
- Transformation (Stateful): Flink 维护一个时间窗口(Window),计算该域名在过去 5 分钟内的访问频率、源 IP 分布熵。
- Feature Extraction: 提取域名的语言学特征(元音占比、最长连续辅音、熵值)。
- Sink: 将特征向量推送到 Feature Store,同时推送到推理服务。
4.2 特征存储(Feature Store):解决训练与推理的一致性
这是大多数初创安全团队遇到的第一个巨坑:训练-服务偏差(Training-Serving Skew)。
- 训练时: 数据科学家用 Python 的 Pandas 库计算“过去 24 小时该 IP 的访问次数”,使用的是离线全量数据。
- 推理时: 线上工程代码用 C++ 或 Go 实现同样的逻辑,计算实时数据流。
由于离线训练使用批处理引擎(如 Spark),而线上推理使用流处理引擎(如 Flink)。两者对时间语义(如 Event Time 与 Processing Time)的底层计算机制不同,哪怕逻辑完全一致,也会导致同样的 IP 在训练时特征值为 100,推理时却算出 95。这种偏差会导致模型在线上性能崩塌。
解决方案:引入 Feature Store(如 Feast, Tecton)
Feature Store 是 MLSecOps 的心脏,它提供统一的特征定义和存储:
- 离线存储(Offline Store): 存储在 S3/HDFS/Snowflake 中,保存历史数月甚至数年的特征数据,用于模型训练。
- 在线存储(Online Store): 存储在 Redis/Cassandra/DynamoDB 等低延迟 KV 数据库中,用于线上实时推理。
- 统一 API: 无论是训练脚本还是线上服务,都通过同一个 ID(如 ip_address 或 user_id)和特征名(如 login_fail_count_1h)请求数据。Feast 会自动处理离线和在线的数据同步。
代码片段示例(Feature Store 定义):
# features.yaml
entities:
- name: user_id
type: STRING
feature_views:
- name: user_login_stats
entities: [user_id]
ttl: 24h
features:
- name: failed_logins_last_hour
type: INT64
- name: distinct_ips_last_day
type: INT64
batch_source:
type: BQ
query: "SELECT user_id, count(*) ... FROM logs"通过这种方式,数据科学家定义的逻辑,会自动同步到线上 Redis,保证工程侧直接调用,消除了代码重写的偏差。
4.3 数据版本控制与血缘(Data Versioning & Lineage)
当安全模型出现误报时,我们需要回溯:“这个模型是基于哪份数据训练的?”
如果你的回答是“大概是上周三那个 csv 文件,但我好像后来又手动删了几行”,那么这就是工程灾难。
我们需要 DVC (Data Version Control) 或类似工具,像管理代码(Git)一样管理数据。
- 数据快照: 每次训练前,对数据集进行哈希快照。
- 代码-数据绑定: 模型的 Metadata 中必须包含:Git Commit ID(代码版本) + DVC Hash(数据版本)。
- 脏数据回溯: 如果发现训练集中混入了红队测试的攻击流量导致模型过拟合,可以通过 Lineage 快速找到所有受影响的模型版本并下线。
4.4 标签工程:最稀缺的资源
在安全领域,打标签(Labeling)极其昂贵。你不能像 ImageNet 那样雇佣众包人员去标注“这是一只猫”。判断一段汇编代码是否是恶意软件,或者一个 HTTP 请求是否是 SQL 注入,需要资深的安全专家。
主动学习(Active Learning)架构:
为了节省专家时间,我们必须在架构中设计主动学习循环:
- 模型对未标记数据进行预测,并给出置信度(Confidence Score)。
- 不确定性采样(Uncertainty Sampling): 系统筛选出那些置信度在 0.4~0.6 之间(模棱两可)的样本。
- 将这些最难判断的样本推送给安全专家进行人工标注。
- 将标注后的样本加入训练集(Feature Store),触发重训练。
通过这种方式,专家只需要标注 5% 最具价值的数据,就能达到全量标注 90% 的效果。
5. Phase 3: 模型开发与实验管理(The Engine)
当数据准备就绪,我们进入模型构建阶段。在 MLSecOps 中,这个阶段的核心不是“调参”,而是“实验的可复现性”和“对抗鲁棒性”。
5.1 算法选择的工程视角
在学术论文中,Transformer 可能是最时髦的。但在工程落地时,我们需要考虑 ROI(投入产出比):
- 树模型(XGBoost/LightGBM): 结构化数据的王者(如 PE Header 特征、流量统计特征)。优势是训练快、推理极快、可解释性强。这是安全工业界的主力军。
- 深度学习(CNN/RNN/Transformer): 适用于非结构化数据(如原始 Payload 字节流、函数调用序列)。优势是无需人工特征工程,但推理延迟高,且不仅需要 GPU,更难以解释。
- 逻辑回归/SVM: 不要小看它们。在超高并发(如网关层每秒百万 QPS)场景下,简单的线性模型可能是唯一能跑得起来的选择。
架构建议: 采用级联架构(Cascading Architecture)。
- L1 层: 使用轻量级模型(如逻辑回归或白名单规则)快速过滤掉 90% 的明显正常流量。
- L2 层: 使用树模型处理剩下的 10% 流量,识别已知攻击。
- L3 层: 对于 L2 认为可疑但无法确定的 0.1% 流量,送入复杂的深度学习模型进行精细研判。
5.2 实验跟踪(Experiment Tracking)
一个安全团队往往同时在跑几十个实验:尝试不同的特征组合、不同的超参数、不同的时间窗口。如果没有工具管理,很快就会乱套。
必须引入 MLflow 或 Weights & Biases。
在每一次实验运行(Run)中,必须自动记录:
- 代码版本: Git commit hash。
- 数据版本: DVC hash。
- 超参数: Learning rate, tree depth, etc.
- 环境依赖: Docker image ID 或 requirements.txt。
- 评估指标: Precision, Recall, AUC, Confusion Matrix。
- Artifacts: 训练好的模型文件、特征重要性图表。
这样,当半年后你需要复现某个特定版本的模型时,只需一行命令。
5.3 核心差异:对抗训练(Adversarial Training)作为标配
这是安全 AI 与其他 AI 最大的区别。在训练管道中,必须包含一个攻击生成器。
自动化对抗训练流程:
- 正常训练: 使用原始数据集训练模型 M。
- 攻击生成: 使用对抗攻击库(如 ART - Adversarial Robustness Toolbox),针对模型 M 生成对抗样本(Adversarial Examples)。例如,对恶意流量包添加微小的扰动(Perturbation)。
- 混合增强: 将生成的对抗样本标记为“恶意”,混合入原始训练集。
- 鲁棒重训练: 使用混合数据集重新训练模型 M'。
- 鲁棒性评估: 此时不仅要看测试集的准确率,还要看“攻击成功率”(Attack Success Rate)是否下降。
如果你的 MLSecOps 流水线中没有这一步,你的模型上线后就是黑客的靶子。我们在第 34 篇中详细讨论过防御机制,而在架构层面,这必须自动化集成在 Pipeline 中,而不是偶尔手动跑一次。
5.4 模型注册与版本管理
训练完成并通过评估的模型,不能直接发给运维。它需要进入模型注册中心(Model Registry)。
模型注册中心定义了模型的生命周期状态:
- Staging(预发布): 等待进行 A/B 测试或金丝雀部署。
- Production(生产): 当前正在线上服务的版本。
- Archived(归档): 历史版本,用于快速回滚。
每个注册的模型必须附带一张“体检报告”(Model Card),明确说明:
- 适用范围(例如:仅适用于 HTTP/1.1 流量,不支持 HTTP/2)。
- 已知的偏差(例如:对加密流量检测能力较弱)。
- 训练数据的时间范围(例如:2023.01 - 2023.06)。
6. Phase 4: 持续集成与持续训练(CI/CD/CT)—— 自动化的免疫系统
在传统的 DevOps 中,CI/CD 意味着代码的自动构建和部署。但在 MLSecOps 中,我们引入了第三个维度:CT (Continuous Training)。
安全环境是动态变化的。黑客发明了新的混淆技术,或者企业上线了新的业务导致流量基线改变,旧模型就会失效。我们需要建立一套机制,让系统像生物免疫系统一样,在检测到新病毒(新数据)时自动生成抗体(更新模型)。
6.1 触发 CT 的三种机制
何时触发模型的重新训练?不能仅凭感觉,必须基于明确的规则:
- 基于计划(Schedule-based):
- 适用于周期性变化明显的场景(如办公网流量)。
- 策略: 每周五晚 2:00 自动拉取本周新标记的数据,进行全量重训练。
- 基于事件(Event-based):
- 适用于突发安全事件。
- 策略: 当威胁情报中心(TIP)推送了新的高危 C2 域名列表,或者 SOC 确认了一批新的误报样本(False Positives)数量超过阈值(如 100 个)时,立即触发微调(Fine-tuning)流水线。
- 基于指标(Metric-based):
- 这是最智能的方式。
- 策略: 监控系统的**数据漂移(Data Drift)**指标。当输入数据的统计分布与训练数据产生显著差异(例如 KL 散度 > 0.5)时,自动触发重训练。
6.2 流水线编排:Airflow 与 Kubeflow
一个标准的 MLSecOps 流水线包含以下自动化步骤(DAG):
- 数据验证(Data Validation):
- 使用工具如 Great Expectations。
- 检查点: 新进来的流量日志字段是否完整?IP 格式是否正确?是否存在 NULL 值暴增?如果数据质量不达标,立即阻断流水线并报警,防止“垃圾进,垃圾出”。
- 数据拆分与预处理:
- 自动将数据按时间切分,确保验证集(Validation Set)的时间晚于训练集(Training Set),防止“未来数据泄露”。
- 模型训练与评估:
- 并行训练多个模型架构(如 XGBoost 和 LightGBM)。
- 自动计算 AUC, Precision, Recall。
- 关键步骤:对抗性测试(Adversarial Testing)。 在发布前,自动使用攻击生成器(如 Foolbox)对模型进行轰炸。如果新模型对旧攻击的防御力下降(Catastrophic Forgetting),则禁止发布。
- 模型注册与打包:
- 如果新模型在所有关键指标上都优于旧模型(Champion/Challenger 模式),则将其标记为 Staging,并打包成 Docker 镜像或序列化为 ONNX 格式。
6.3 基础设施即代码(IaC)
在安全领域,环境的一致性至关重要。训练环境的依赖库版本(如 tensorflow==2.10.0)必须与生产环境完全一致。
- 使用 Terraform 或 Ansible 管理 GPU 训练集群。
- 使用 Docker 固化运行环境。
- 严禁在生产环境服务器上运行 pip install。所有的变更必须通过镜像更新完成。
7. Phase 5: 服务化部署策略(Serving Strategy)—— 速度与精度的博弈
模型训练好了,如何部署?这是安全工程中最具挑战性的环节。与推荐系统不同,安全产品(特别是防火墙、WAF、IPS)往往串行在网络主路(Inline)上。
延迟预算(Latency Budget):
- 推荐系统: 200ms 的延迟用户几乎无感。
- WAF(Web 应用防火墙): 每个请求增加 20ms 延迟,业务部门就会投诉;增加 50ms,你的安全设备就会被拔线。
我们必须在极短的时间内完成特征提取、模型推理和决策执行。
7.1 部署模式选择
根据业务场景的实时性要求,架构设计通常分为三种模式:
|
模式 |
典型场景 |
延迟要求 |
架构特点 |
|
实时阻断 (Inline Blocking) |
WAF, IPS, 网关 |
< 5ms |
模型需极度轻量,通常嵌入在 Nginx/Envoy 进程中,或使用侧车(Sidecar)模式。 |
|
近实时检测 (Near Real-time) |
EDR, 邮件网关 |
< 1min |
异步处理。流量镜像或日志投递到 Kafka,由消费者微服务批量推理。 |
|
离线分析 (Batch Analytics) |
僵尸网络挖掘, 威胁狩猎 |
T+1 天 |
大数据处理(Spark/Hive),处理海量历史日志,构建用户行为画像(UBA)。 |
7.2 高性能推理优化技巧
为了达到 < 5ms 的极致性能,Python 通常是不被允许的。我们需要进行模型编译与加速:
- 模型转换(ONNX):
- 将 PyTorch/TensorFlow 模型导出为 ONNX (Open Neural Network Exchange) 标准格式。这使得模型可以脱离原框架运行。
- 推理引擎加速:
- TensorRT (NVIDIA): 如果使用 GPU,TensorRT 可以对计算图进行层融合(Layer Fusion)和精度校准(FP16/INT8),提升 5-10 倍吞吐量。
- OpenVINO (Intel): 如果运行在 CPU 服务器上,OpenVINO 是最佳选择。
- ONNX Runtime: 通用的高性能运行时,支持多种后端。
- 量化(Quantization):
- 将 32 位浮点数(FP32)权重转换为 8 位整数(INT8)。模型体积缩小 4 倍,速度提升,而精度损失通常在 1% 以内(对于安全分类任务通常可接受)。
7.3 安全发布的“三板斧”
直接将新模型推送到全网 WAF 节点是自杀行为。一旦出现高误报,整个公司的业务可能瘫痪。必须严格遵守灰度发布流程:
- 影子模式(Shadow Mode / Dark Launch):
- 这是最稳妥的第一步。新模型上线,接收真实流量并进行预测,但不执行拦截动作。
- 系统记录新模型的预测结果(例如:模型认为这是 SQL 注入),并将其与当前运行的旧模型或规则引擎的结果进行比对。
- 观察期: 持续运行 48 小时,分析“新模型报警但旧系统放行”的案例,确认是新模型发现了未知攻击,还是产生了误报。
- 金丝雀发布(Canary Deployment):
- 将 1% 的流量路由到搭载新模型的节点。
- 密切监控业务指标(如 HTTP 500 错误率、用户投诉率)。如果无异常,逐步提升比例至 5%、10%、50%、100%。
- A/B 测试(A/B Testing):
- 在两个同质的流量组中分别运行模型 A 和模型 B,比较核心指标(如检出率、误报率)。
- 注意: 安全领域的 A/B 测试比较困难,因为攻击流量是不均匀分布的。需要确保两组流量的威胁分布具有统计学上的相似性。
8. Phase 6: 全链路监控与观测(Observability)—— 也就是“看门狗”
软件工程监控的是 CPU、内存和 HTTP 状态码。MLSecOps 监控的是数据分布、模型表现和业务影响。
模型的腐化是悄无声息的。它不会抛出 NullPointerException,它只会自信地把恶意软件识别为正常文件。
8.1 核心监控指标体系
我们需要构建一个专门的监控仪表盘(Dashboard),重点关注以下三类指标:
A. 稳定性指标 (System Metrics)
- P99 Latency: 99% 的请求推理耗时是否在预算内?
- Throughput (QPS): 当前每秒处理多少请求?
- Error Rate: 推理服务是否返回错误?
B. 漂移指标 (Drift Metrics) —— 预警雷达
这是检测模型是否过期的关键。我们需要计算训练数据(Reference)和推理数据(Current)之间的统计距离。
- 数据漂移 (Data Drift / Covariate Shift): P(X) 发生变化。
- 常用算法: KL 散度 (Kullback-Leibler Divergence) 或 PSI (Population Stability Index)。
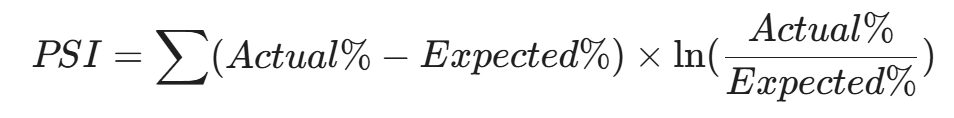
- 阈值: PSI < 0.1 (稳定); 0.1 < PSI < 0.25 (轻微漂移); PSI > 0.25 (显著漂移,报警)。
- 场景: 突然出现大量来自新国家/地区的 IP,或者 HTTP User-Agent 分布剧变。
- 概念漂移 (Concept Drift): P(Y|X) 发生变化。
- 这是最危险的。意味着同样的特征映射到了不同的结果。例如,某个 IP 的高频扫描行为昨天还是黑客攻击,今天该 IP 被重新分配给了内网的合法漏扫平台——数据特征没变,但真实的判定标签(Y)已经反转。
- 检测难点: 我们无法实时获得真实标签(Y)。
- 解决方案: 使用代理指标(Proxy Metrics),如“预测置信度分布”。如果模型对所有样本的预测置信度都从 0.9 降到了 0.6,说明模型对当前数据感到困惑。
C. 业务指标 (Business Metrics) —— 最终防线
- 告警率 (Alert Rate): 如果告警率突然从 0.1% 飙升到 5%,通常意味着发生了误报风暴(False Positive Storm)。
- 用户反馈率: 客服收到的“无法访问”投诉数量。
- SOC 处理时长: 分析师研判一个告警所需的平均时间。如果时间变长,说明模型输出的解释性变差。
8.2 闭环反馈系统(Feedback Loop)
监控不仅仅是看,更要动。一个成熟的 MLSecOps 架构必须具备自动回滚和自动采样能力。
- 断路器(Circuit Breaker): 当告警率超过安全阈值(如 10%)时,自动触发断路器,将流量切换回传统的规则引擎或白名单模式,优先保障业务可用性。
- 难例挖掘(Hard Example Mining): 自动将那些处于决策边界(Decision Boundary)附近的样本保存到对象存储,推送给专家进行标注,加入下一轮的训练集。
9. Phase 7: 治理与合规(Governance)—— AI 的“驾照”
在将 AI 引入安全产品时,我们面临着比传统软件更严格的法律和伦理审查。
9.1 可解释性(Explainability/XAI)
安全分析师不会相信一个黑盒。如果 AI 说“阻断这个 IP”,分析师会问“为什么?”。如果无法回答,AI 就只是一个玩具。
架构要求:
- 局部解释(Local Explanation): 对于每一个被阻断的请求,必须提供解释。
- 工具: SHAP (SHapley Additive exPlanations) 或 LIME。
- 输出示例: “阻断该请求,因为 payload 包含 <script> (贡献度 +0.4),且 User-Agent 为空 (贡献度 +0.2)。”
- 归因分析: 能够追溯决策是由训练集中的哪些样本影响的(Influence Functions)。
9.2 模型鲁棒性与红队测试
在上线前,必须对模型本身进行安全审计。
- 模型窃取防御: 限制推理 API 的调用频率,只返回 Top-1 类别,不返回具体的置信度数值,增加攻击者通过查询窃取模型的难度。
- 输入清洗: 虽然是 AI 模型,但输入端依然要防范传统的 SQL 注入或缓冲区溢出。确保传递给 TensorFlow/PyTorch 的 Tensor 数据已经过严格的类型检查。
9.3 合规性文档
对于欧盟 GDPR 或中国《数据安全法》等法规,架构师需要维护一份算法影响评估报告(AIA):
- 数据来源合法性: 证明训练数据不包含未经授权的个人隐私信息。
- 无歧视性证明: 证明模型不会因为用户的地域、设备类型而产生不公平的阻断策略。
9.4 隐私增强技术(PETs)的工程应用
当安全厂商需要利用跨国企业的全球数据联合训练模型,又受限于 GDPR 等数据出境与本地化法规时,传统的“数据集中打宽表”模式将面临极大的法律风险。在架构设计上,必须引入隐私增强技术(Privacy-Enhancing Technologies):
- 联邦学习(Federated Learning, FL): 跨域联合建模的必选项。模型参数可以在边缘节点(或各分公司本地服务器)更新后,仅将加密后的梯度数据汇总到中心服务器,实现了“数据可用不可见”,从根本上解决了合规痛点。
- 差分隐私(Differential Privacy, DP): 在模型训练或数据特征提取过程中注入特定的统计学噪声。这能有效防止攻击者通过不断向 AI 引擎发起高频探测(如成员推理攻击),来逆向猜出训练集中的某一具体敏感 IP 或真实 Payload。
- 机密计算与可信执行环境(TEE): 在云端部署安全 AI 服务时,将核心的推理引擎置于 Intel SGX 或 ARM TrustZone 等硬件级安全飞地中。这确保了即使是云厂商的底层运维人员,也无法窥探到运行在内存中的模型权重和用户请求的明文流量。
结语:将七阶法则熔铸为硅基防御网
至此,我们完成了《架构设计:安全 AI 产品的全生命周期(MLSecOps)》的完整构建。安全 AI 的工程化落地,绝不是简单地把一个 Python 脚本塞进 Docker 容器,而是一场从“算法竞赛”到“系统工程”的深刻范式转移。
让我们回顾这七个阶段是如何精准咬合,共同孕育出一个数字有机体的:
- 需求与威胁建模(Phase 1) 避开了纯看准确率的陷阱,设定了业务价值的罗盘;
- 数据工程与特征仓库(Phase 2) 抹平了训练与推理的时间差,保障了流动的纯净血液;
- 对抗训练(Phase 3) 充当了疫苗,让模型在被绕过前提前产生抗体;
- 持续集成与训练(Phase 4) 构筑了自动发现并应对变异威胁的白细胞防线;
- 服务化部署(Phase 5) 在毫秒级延迟与精准阻断间取得平衡,并用灰度发布系好了安全带;
- 全链路监控(Phase 6) 化身中枢神经,时刻洞察模型腐化与数据漂移的阵痛;
- 治理与隐私合规(Phase 7) 则运用 PETs 技术,为这台高速运转的引擎加上了法律的护栏。
传统的网络安全是在建城墙,堆砌死板的规则和无尽的特征码;而 MLSecOps 则是打破孤岛,让安全专家懂算法,算法工程师懂运维,运维人员懂合规,最终打造出一支拥有“生物免疫力”的数字军团。
掌握了宏观架构,接下来的战场将更加硬核与逼仄。在企业最核心的物理隔离内网中,数据出不去,算力捉襟见肘,我们该如何安全地部署并掌控那些几百亿参数的庞然大物?
下一篇,第 39 篇,《本地大模型: 如何在内网部署 Llama/Qwen 等安全增强模型》,我们将拔剑出鞘,直指生成式 AI 落地的深水区。敬请期待。
陈涉川
2026年03月09日

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)