从 PDE 到策略:PINN+RL 如何让仿真、控制与优化同时变快?
近年来,PINN与强化学习的融合研究展现出显著进展。通过将物理规律、守恒约束等先验知识注入智能体学习过程,研究者成功实现了策略学习从"盲试"到"有规可依"的转变。15篇顶会顶刊文献显示,该融合路线通过PINN压缩RL搜索空间,同时利用交互拓展PINN应用边界,形成了可复用的方法论。代表性工作包括:利用PINN构建电网物理模型替代器提升训练效率50%;将PIN
过去几年,一个很清晰的信号在顶会顶刊里不断出现:PINN(Physics-Informed Neural Networks)不再只是“解方程的神经网络”,强化学习也不再只是“靠试错找策略”的黑盒。当两者结合,研究者开始把“物理规律、守恒约束、边界条件、可解释的结构先验”直接注入智能体的学习过程,让策略学习从“盲试”变成“有规可依”的探索。
我们梳理了近期 15 篇来自顶会顶刊的 PINN+RL 代表作,你会发现它们在做的事情高度一致:用物理把 RL 的搜索空间压缩,用交互把 PINN 的适用边界拓宽。从 PDE 约束控制、逆问题与参数辨识,到基于仿真的安全探索、跨场景泛化与样本效率提升,这条融合路线正在形成一套可复用的方法论。接下来我们就用“创新点”视角,带你快速抓住这条赛道的关键脉络。
1.Deep Reinforcement Learning for Optimizing Energy Consumption in Smart Grid Systems
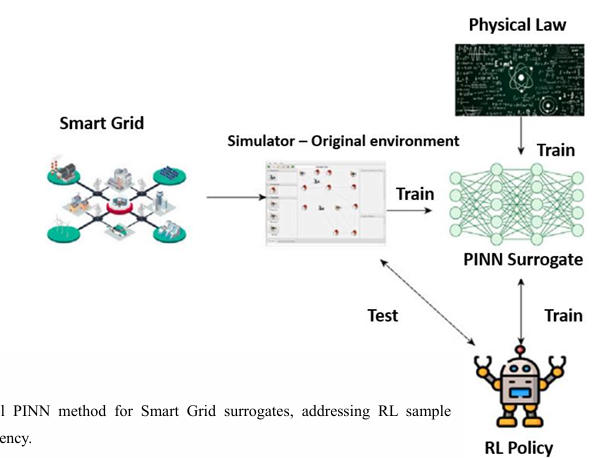
【创新点】
-
PINN 作为 RL 环境替代器:用 PINN 构建电网物理模型的 surrogate simulator,使 RL 训练不依赖昂贵仿真器。
-
样本效率显著提升:RL 与 PINN 结合使策略收敛速度提升约 50%。
-
Physics-consistent policy learning:通过嵌入电力系统物理约束,使 RL 学到的策略满足真实物理规律。
【方法】通过使用物理信息神经网络(PINNs)来替代传统的、成本高昂的智能电网模拟器,从而解决上述挑战。PINNs能够增强RL策略的学习过程,使得收敛速度可以比原始环境快得多。
【实验】PINN代理模型与其它基准数据驱动代理模型进行了比较,结果表明,通过结合对底层物理定律的了解,PINN代理是唯一能够在不访问真实模拟器样本的情况下获得强大RL策略的方法。实验证明,使用PINN代理可以加速训练,训练速度提高50%。
2.RL-PINNs: Reinforcement Learning-Driven Adaptive Sampling for Efficient Training of PINNs
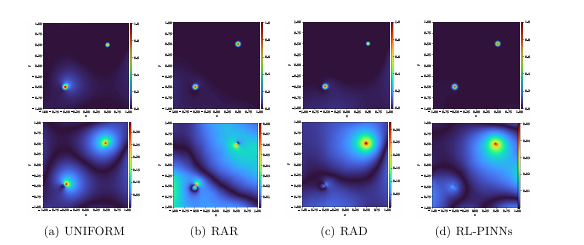
【创新点】
-
RL驱动自适应采样:将 PINN 采样问题建模为 Markov Decision Process。
-
单轮采样训练机制:避免传统 residual-based adaptive refinement 的多轮训练。
-
延迟奖励机制:RL agent 使用函数变化作为 reward,减少高阶导数计算开销。
【方法】 该方法将自适应采样问题建模为马尔可夫决策过程,使用强化学习代理动态选择最优训练点,并通过最大化长期效用指标来优化采样策略。
【实验】作者在多个PDE基准测试中进行了实验,包括低正则性、非线性、高维和高阶问题,结果表明RL-PINNs在准确性上显著优于现有的基于残差的自适应方法,且在采样开销上可忽略不计,适用于高维和高阶问题。
3.MAD-PINN: A Decentralized Physics-Informed Machine Learning Framework for Safe and Optimal Multi-Agent Control
【创新点】
-
PINN + Multi-Agent RL 控制框架:用 PINN 近似 Hamilton-Jacobi PDE 来求解控制策略。
-
安全约束优化控制:将安全约束嵌入价值函数。
-
可扩展多智能体策略:采用 decentralized policy,提高大规模系统稳定性。
【方法】通过采用带有图割的SC-OCP重形式化方法同时捕捉性能和安全,使用物理信息神经网络近似其解,并通过在缩减代理系统上训练SC-OCP值函数实现可扩展性。
【实验】在多智能体导航任务上进行的实验表明,MAD-PINN在安全性与性能的权衡上优于现有技术,并能保持随智能体数量增加的可扩展性,使用了特定的Hamilton-Jacobi可达性基础的邻居选择策略和后退视野策略执行方案。
4.A Survey on Physics-Informed Reinforcement Learning
【创新点】
-
提出 Physics-informed RL 的统一分类框架。
-
分析 PINN-based RL 与 physics-reward RL 两种范式。
-
提出未来研究方向:RL-PINN、control-PDE、SciML integration。
【方法】本文采用了一种新颖的分类法,以强化学习流水线为核心,对现有的物理信息融入的强化学习方法进行分类和比较。
【实验】通过对现有工作的分析,本文识别出了物理信息在强化学习中的应用领域,以及现有方法在物理可行性、精确度、数据效率和实际场景适用性方面的优势和潜力,同时指出了现有方法中存在的问题和挑战。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)