深度学习-病毒感染人数预测
引言
今天带大家完成一次kaggle上的一个比赛,通过本次学习可以掌握深度学习回归项目的通用流程。
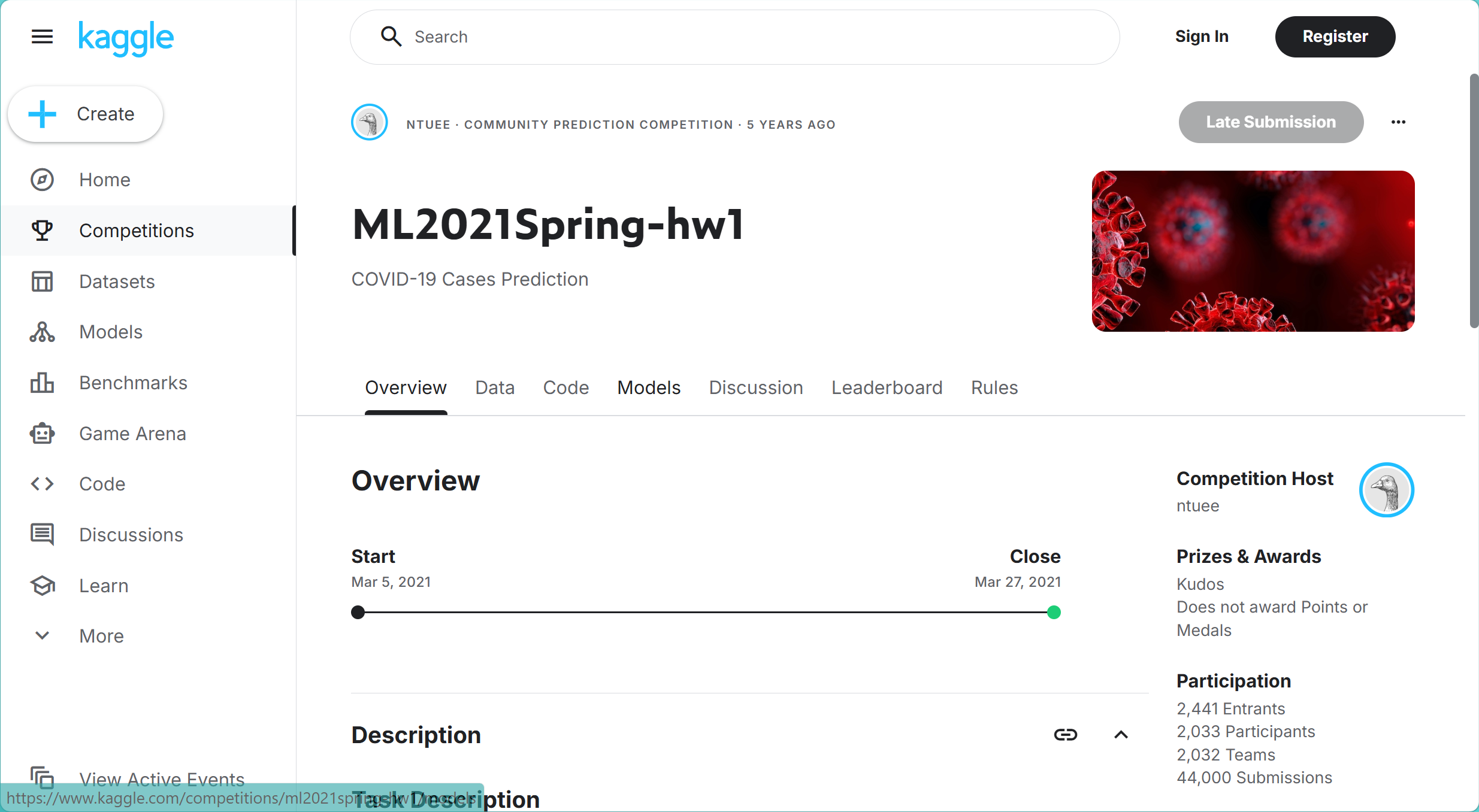
任务描述
- 新冠每日病例预测
- 训练数据:2700个样本
- 检测数据:893个样本
- 评估指标:均方根误差(RMSE)
数据收集与预处理
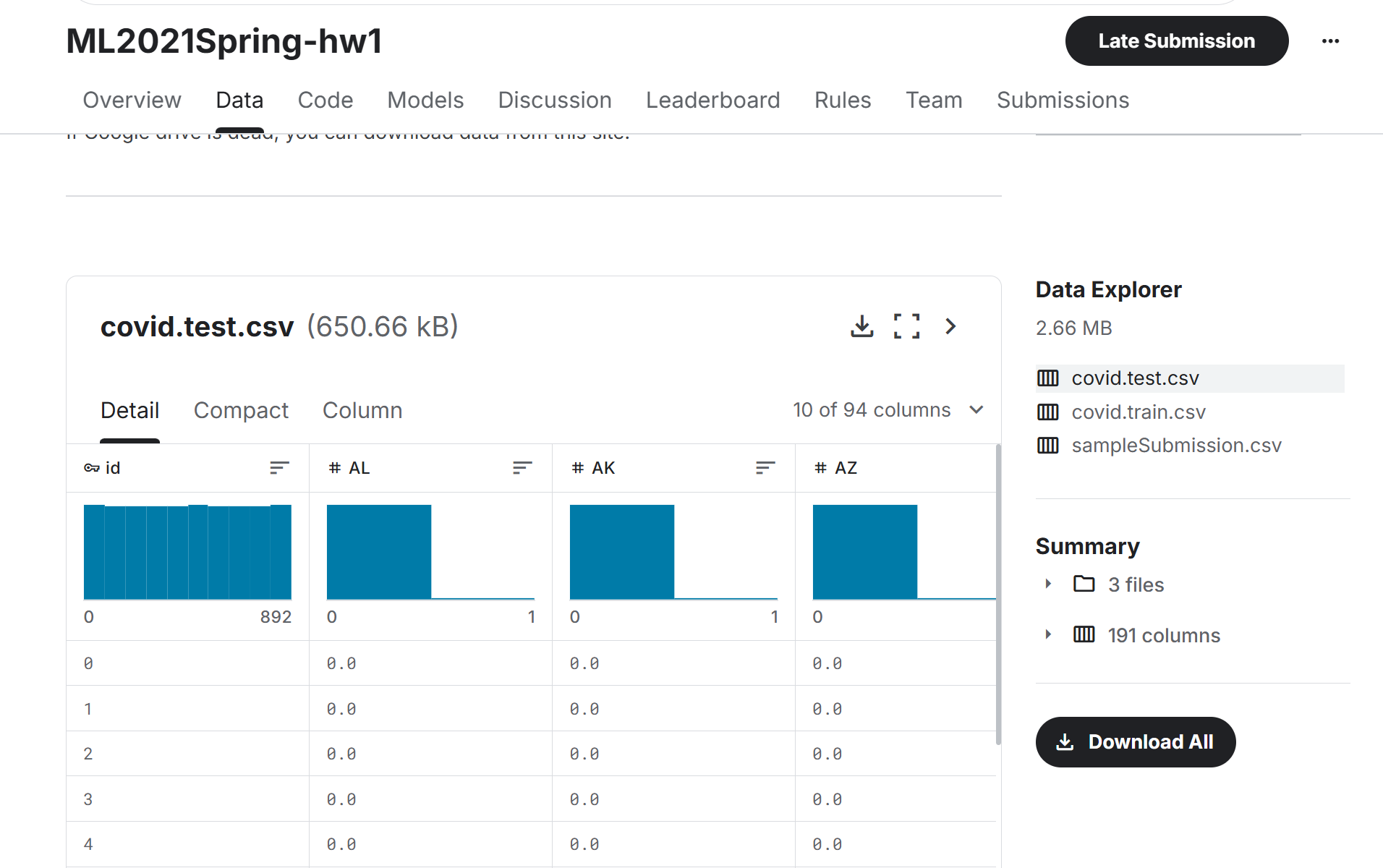
数据我们在这个竞赛里面的Data中看到,一共有三个CSV文件。直接下载下来。
- covid.train.csv: 训练集。我们使用这里面提供的数据来训练模型。
- covid.test.csv: 测试集。将训练好的模型通过这个测试集来检验我们训练的质量。
- sampleSubmission.csv: 我们要将最后得到的结果填入这个csv文件里面然后提交。
covid.train.csv
我们先打开covid.train.csv看看数据。可以看到数据前面这些列是一些编码。编码实际上是美国各州的邮政缩写代码。它采用了(One-Hot)独热编码的方式。
什么是独热编码?举个例子
想象你在填写一份表格,其中有一个问题是:"您所在的地区是?"
-
选项:华北、华东、华南、西部
如果你的回答是"华东",在独热编码中,它会变成:
华北: 0
华东: 1 ← 只有这里是1,表示"是"
华南: 0
西部: 0也就是说只有其中一个地区为1,其余地区都用0来表示。
我们在看后面的数据,代表的是影响感染的各种因素。可以当作我们要输入的x。 我们要输出的y是tested_positive(检测阳性比例)。并且我们可以看到这一组变量出现了三次,说明可能是不同时间段进行测量的。
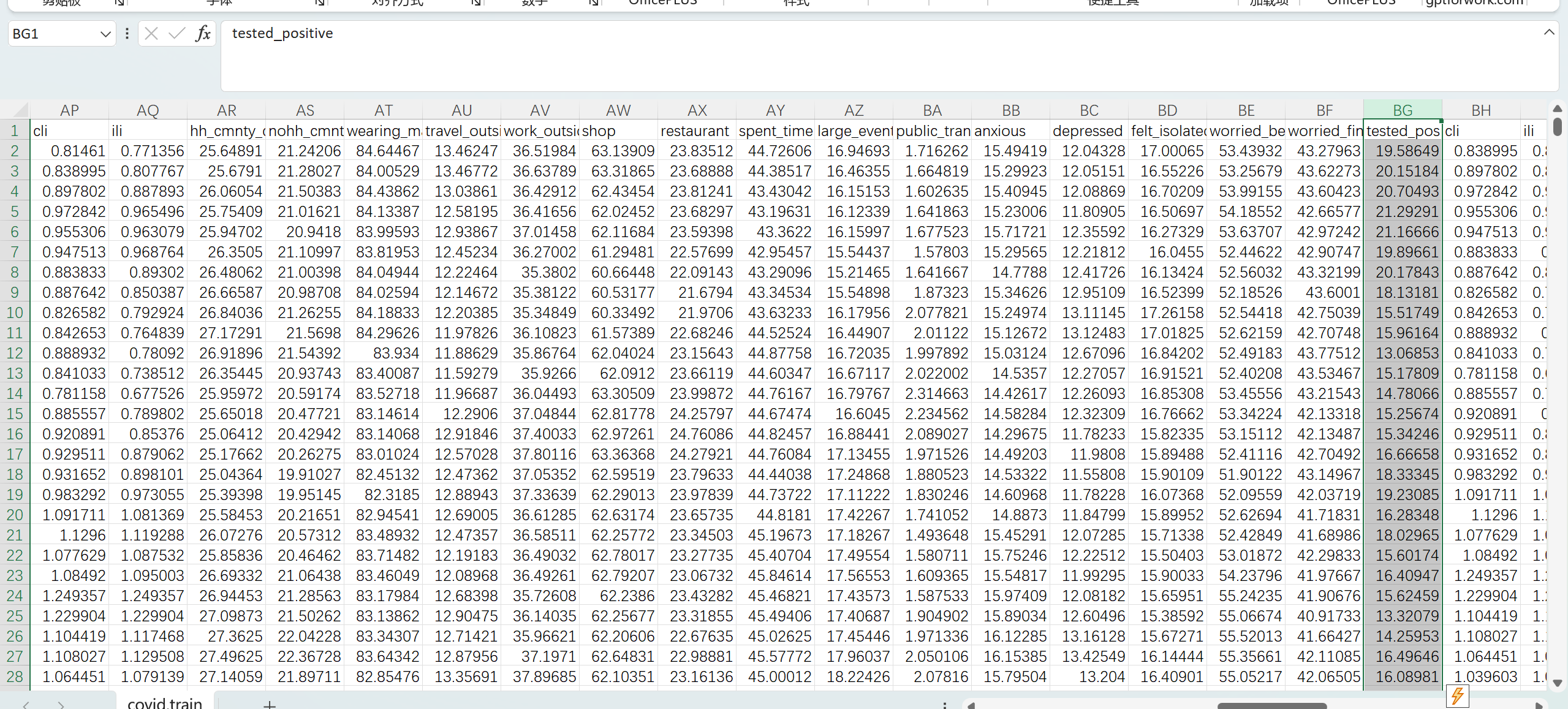
总结,从这个数据中我们可以看到
这是一个面板数据(Panel Data),包含:
-
维度1:时间/批次 - 每组变量重复3次,应该是3个不同的时间点或调查批次
-
维度2:地区 - 40个美国州(从AL到WI)
-
维度3:指标 - 18个调查指标(症状、行为、心理等)
covid.test.csv
我们打开covid.test.csv后,可以看到和covid.train.csv差不多,除了最后一列少了一列tested_positive。说明这个是让我们训练好模型计算出来的。
模型训练基本流程
一共分为四个部分:
- 数据
- 模型
- 超参
- 训练流程
接下来我们一个一个来完成。

首先引入我们所需要的包
import torch
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
import csv
import pandas
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
from torch import optim
import time
数据
第一个数据部分,我们需要按照固定流程来写。
Dataset:
init
getitem
len
我们先定义一个名为CovidDataset的类,继承自PyTorch的Dataset基类。这意味着这个类必须实现__len__和__getitem__方法。
class CovidDataset(Dataset):1.__init__方法
#需要接收两个参数一共我们要读取的文件的路径,一个是数据模式("train"/"val"/"test")
def __init__(self, file_path, mode):
#使用with语句以只读模式打开文件。with可以确保文件使用后自动关闭。
with open(file_path, "r") as f:
#用csv.reader逐行读取文件,然后转成列表形式
ori_data = list(csv.reader(f))
#将列表转换为numpy数组
#不要第一行和第一列,第一行是类别名,第一列是计数的id,我们只要取数据
#因为使用csv.reader()读取CSV文件时,所有数据默认都是字符串类型。所以将所有数据转换为浮点数类型
csv_data = np.array(ori_data)[1:, 1:].astype(float)
# 逢5取1 这里只是简单分 不推荐 将数据分成训练集 验证集 测试集
if mode == "train":
indices = [i for i in range(len(csv_data)) if i % 5 != 0]
elif mode == "val":
indices = [i for i in range(len(csv_data)) if i % 5 == 0]
elif mode == "test":
indices = [i for i in range(len(csv_data))]
X = torch.tensor(csv_data[indices, :93]) # 切片左闭右开
if mode != "test":
self.Y = torch.tensor(csv_data[indices, -1])
# 标准化操作,将数值变为0附近的数值,可以消除量纲可能存在的影响
self.X = (X - X.mean(dim=0, keepdim=True)) / X.std(dim=0, keepdim=True)
self.mode = mode
为什么要做标准化?我们可以看到在数据集中有的数据是0.0几,有的数据是大几十。但是这些数据又同时重要,所以我们要消除这种差异。将数值变为0附近的数值,可以消除量纲可能存在的影响。
2.__getitem__方法
# 固定的写法
def __getitem__(self, item):
if self.mode == "test":
return self.X[item].float() # 64位变成32位
else:
return self.X[item].float(), self.Y[item].float()3.__len__方法
def __len__(self):
return len(self.X)总结
class CovidDataset(Dataset):
def __init__(self, file_path, mode):
with open(file_path, "r") as f:
ori_data = list(csv.reader(f))
csv_data = np.array(ori_data)[1:, 1:].astype(float) # 不要第一行和第一列
# 逢5取1 不推荐
if mode == "train":
indices = [i for i in range(len(csv_data)) if i % 5 != 0]
elif mode == "val":
indices = [i for i in range(len(csv_data)) if i % 5 == 0]
elif mode == "test":
indices = [i for i in range(len(csv_data))]
X = torch.tensor(csv_data[indices, :93]) # 切片左闭右开
if mode != "test":
self.Y = torch.tensor(csv_data[indices, -1])
self.X = (X - X.mean(dim=0, keepdim=True)) / X.std(dim=0, keepdim=True) # 标准化操作,将数值变为0附近的数值,可以消除量纲可能存在的影响
self.mode = mode
# 固定的写法
def __getitem__(self, item):
if self.mode == "test":
return self.X[item].float() # 64位变成32位
else:
return self.X[item].float(), self.Y[item].float()
def __len__(self):
return len(self.X)
模型
模型写起来比较较为固定,我们把全连接写进去就可以了。inDim是输入特征的维度(这里是93)因为数据集是93列。
- 全连接层 fc1 (93,128)
- 激活函数 relu1
- 全连接层 fc2 (128,1)
- 前向传播 forwad
class myModel(nn.Module):
def __init__(self, inDim):
super(myModel, self).__init__()
self.fc1 = nn.Linear(inDim, 128)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(128, 1)
def forward(self, x):
x = self.fc1(x)
x = self.relu1(x)
x = self.fc2(x)
if len(x.size()) > 1:
x = x.squeeze(1) # 如果维度大于1, 就去掉第二个维度
return x超参
def train_val(model, train_loader, val_loader, optimizer, device, epochs, save_path):
# 训练验证函数,接收模型、数据加载器、优化器、设备、训练轮数和保存路径
model = model.to(device) # 将模型移动到指定设备(CPU/GPU)
plt_train_loss = [] # 创建列表存储训练损失值,用于绘图
plt_val_loss = [] # 创建列表存储验证损失值,用于绘图
min_val_loss = 9999999999999999.9 # 初始化最小验证损失为一个很大的数
for epoch in range(epochs): # 开始epoch循环
model.train() # 设置模型为训练模式(启用Dropout、BatchNorm等)
stat_time = time.time() # 记录开始时间
train_loss = 0.0 # 初始化训练损失
for x, y in train_loader: # 遍历训练数据批次
x, y = x.to(device), y.to(device) # 将数据和标签移动到指定设备
y_pred = model(x) # 前向传播:模型预测
bat_loss = loss(y_pred, y) # 计算损失(调用自定义的mseLoss函数)
bat_loss.backward() # 反向传播:计算梯度
optimizer.step() # 更新模型参数
optimizer.zero_grad() # 清空梯度,防止累积
train_loss += bat_loss.cpu().item() # 累加批次损失(移到CPU并转为Python数值)
plt_train_loss.append(train_loss / train_loader.__len__()) # 计算平均训练损失并存储
model.eval() # 设置模型为评估模式
val_loss = 0.0 # 初始化验证损失
with torch.no_grad(): # 禁用梯度计算(节省内存和计算)
for val_x, val_y in val_loader: # 遍历验证数据批次
val_x, val_y = val_x.to(device), val_y.to(device) # 移到指定设备
val_pred_y = model(val_x) # 前向传播
val_bat_loss = loss(val_pred_y, val_y, model) # 计算验证损失(注意第三个参数model用于正则化)
val_loss += val_bat_loss.cpu().item() # 累加验证损失
plt_val_loss.append(val_loss / val_loader.__len__()) # 计算平均验证损失并存储
# 保存最佳模型
if val_loss < min_val_loss: # 如果当前验证损失比之前的最小值还小
min_val_loss = val_loss # 更新最小验证损失
torch.save(model, save_path) # 保存整个模型到指定路径
# 打印训练信息:epoch、总轮数、耗时、训练损失、验证损失
print("[%03d/%03d] %2.2f sec(s) train_loss: %.6f val_loss:%.6f" % \
(epoch, epochs, time.time() - stat_time, plt_train_loss[-1], plt_val_loss[-1]))
# 绘制损失曲线
plt.plot(plt_train_loss) # 绘制训练损失曲线
plt.plot(plt_val_loss) # 绘制验证损失曲线
plt.title("loss") # 设置图表标题
plt.legend(["train", "val"]) # 设置图例
plt.show() # 显示图表
def evaluate(model_path, test_loader, rel_path, device):
# 评估函数,加载训练好的模型并对测试集进行预测
model = torch.load(model_path).to(device) # 加载保存的模型并移到指定设备
rel = [] # 创建列表存储预测结果
model.eval() # 设置评估模式
with torch.no_grad(): # 禁用梯度
for x in test_loader: # 遍历测试数据
x = x.to(device) # 移到指定设备
pred = model(x) # 预测
rel.append(pred.cpu().item()) # 将预测结果加入列表(移到CPU并转为Python数值)
with open(rel_path, "w", newline="") as f: # 以写入模式打开结果文件
csv_writer = csv.writer(f) # 创建CSV写入器
csv_writer.writerow(["id", "tested_positive"]) # 写入表头
for i, pred in enumerate(rel): # 遍历所有预测结果
csv_writer.writerow([str(i), str(pred)]) # 逐行写入预测结果(id和预测值)
print("结果保存到" + rel_path) # 打印保存信息
train_file = r"E:\DL\环境安装\covid\covid.train.csv" # 训练数据文件路径
test_file = r"E:\DL\环境安装\covid\covid.test.csv" # 测试数据文件路径
# for x, y in train_set:
# pred_y = model(x)
# print(pred_y) # 被注释掉的测试代码,用于检查数据加载是否正确
batch_size = 16 # 定义批次大小
# 创建数据集实例
train_set = CovidDataset(train_file, "train") # 创建训练集
val_set = CovidDataset(train_file, "val") # 创建验证集
test_set = CovidDataset(test_file, "test") # 创建测试集
# 创建数据加载器
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True) # 训练数据加载器,批次16,打乱顺序
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=True) # 验证数据加载器,批次16,打乱顺序
test_loader = DataLoader(test_set, batch_size=1, shuffle=False) # 测试数据加载器,批次大小1,不打乱(逐个预测)
def mseLoss(pred, target, model):
# 自定义损失函数:MSE损失 + L2正则化
loss = nn.MSELoss(reduction='mean') # 创建MSE损失函数,返回平均值
''' Calculate loss '''
regularization_loss = 0 # 初始化正则化损失为0
for param in model.parameters(): # 遍历模型所有参数
# TODO: you may implement L1/L2 regularization here
# 使用L2正则项
# regularization_loss += torch.sum(abs(param)) # L1正则化(被注释掉)
regularization_loss += torch.sum(param ** 2) # L2正则化:计算所有参数的平方和
return loss(pred, target) + 0.00075 * regularization_loss # 返回MSE损失 + 正则化项(系数0.00075)
loss = mseLoss # 将自定义损失函数赋值给loss变量
#loss = nn.MSELoss() # 被注释掉的简单MSE损失
epochs = 20 # 设置训练轮数为20
lr = 0.001 # 设置学习率为0.001
device = "cuda" if torch.cuda.is_available() else "cpu" # 检测可用设备:如果有GPU就用cuda,否则用cpu
print(device) # 打印使用的设备
data_dim = 93 # 输入特征维度为93
model = myModel(data_dim).to(device) # 创建模型并移到指定设备
save_path = "model_save/best_model_pth" # 定义模型保存路径
rel_path = "pred.csv" # 定义预测结果输出路径
optimizer = optim.SGD(params=model.parameters(), lr=lr, momentum=0.9) # 创建SGD优化器,添加动量0.9
# train_val(model, train_loader, val_loader, optimizer, device, epochs, save_path) # 被注释掉的训练调用
# 提交
evaluate(save_path, test_loader, rel_path, device) # 执行评估(需要先有训练好的模型)def train_val(model, train_loader, val_loader, optimizer, device, epochs, save_path):
# 训练验证函数,接收模型、数据加载器、优化器、设备、训练轮数和保存路径
model = model.to(device) # 将模型移动到指定设备(CPU/GPU)
plt_train_loss = [] # 创建列表存储训练损失值,用于绘图
plt_val_loss = [] # 创建列表存储验证损失值,用于绘图
min_val_loss = 9999999999999999.9 # 初始化最小验证损失为一个很大的数
for epoch in range(epochs): # 开始epoch循环
model.train() # 设置模型为训练模式(启用Dropout、BatchNorm等)
stat_time = time.time() # 记录开始时间
train_loss = 0.0 # 初始化训练损失
for x, y in train_loader: # 遍历训练数据批次
x, y = x.to(device), y.to(device) # 将数据和标签移动到指定设备
y_pred = model(x) # 前向传播:模型预测
bat_loss = loss(y_pred, y) # 计算损失(调用自定义的mseLoss函数)
bat_loss.backward() # 反向传播:计算梯度
optimizer.step() # 更新模型参数
optimizer.zero_grad() # 清空梯度,防止累积
train_loss += bat_loss.cpu().item() # 累加批次损失(移到CPU并转为Python数值)
plt_train_loss.append(train_loss / train_loader.__len__()) # 计算平均训练损失并存储
model.eval() # 设置模型为评估模式
val_loss = 0.0 # 初始化验证损失
with torch.no_grad(): # 禁用梯度计算(节省内存和计算)
for val_x, val_y in val_loader: # 遍历验证数据批次
val_x, val_y = val_x.to(device), val_y.to(device) # 移到指定设备
val_pred_y = model(val_x) # 前向传播
val_bat_loss = loss(val_pred_y, val_y, model) # 计算验证损失(注意第三个参数model用于正则化)
val_loss += val_bat_loss.cpu().item() # 累加验证损失
plt_val_loss.append(val_loss / val_loader.__len__()) # 计算平均验证损失并存储
# 保存最佳模型
if val_loss < min_val_loss: # 如果当前验证损失比之前的最小值还小
min_val_loss = val_loss # 更新最小验证损失
torch.save(model, save_path) # 保存整个模型到指定路径
# 打印训练信息:epoch、总轮数、耗时、训练损失、验证损失
print("[%03d/%03d] %2.2f sec(s) train_loss: %.6f val_loss:%.6f" % \
(epoch, epochs, time.time() - stat_time, plt_train_loss[-1], plt_val_loss[-1]))
# 绘制损失曲线
plt.plot(plt_train_loss) # 绘制训练损失曲线
plt.plot(plt_val_loss) # 绘制验证损失曲线
plt.title("loss") # 设置图表标题
plt.legend(["train", "val"]) # 设置图例
plt.show() # 显示图表
def evaluate(model_path, test_loader, rel_path, device):
# 评估函数,加载训练好的模型并对测试集进行预测
model = torch.load(model_path).to(device) # 加载保存的模型并移到指定设备
rel = [] # 创建列表存储预测结果
model.eval() # 设置评估模式
with torch.no_grad(): # 禁用梯度
for x in test_loader: # 遍历测试数据
x = x.to(device) # 移到指定设备
pred = model(x) # 预测
rel.append(pred.cpu().item()) # 将预测结果加入列表(移到CPU并转为Python数值)
with open(rel_path, "w", newline="") as f: # 以写入模式打开结果文件
csv_writer = csv.writer(f) # 创建CSV写入器
csv_writer.writerow(["id", "tested_positive"]) # 写入表头
for i, pred in enumerate(rel): # 遍历所有预测结果
csv_writer.writerow([str(i), str(pred)]) # 逐行写入预测结果(id和预测值)
print("结果保存到" + rel_path) # 打印保存信息
train_file = r"E:\DL\环境安装\covid\covid.train.csv" # 训练数据文件路径
test_file = r"E:\DL\环境安装\covid\covid.test.csv" # 测试数据文件路径
# for x, y in train_set:
# pred_y = model(x)
# print(pred_y) # 被注释掉的测试代码,用于检查数据加载是否正确
batch_size = 16 # 定义批次大小
# 创建数据集实例
train_set = CovidDataset(train_file, "train") # 创建训练集
val_set = CovidDataset(train_file, "val") # 创建验证集
test_set = CovidDataset(test_file, "test") # 创建测试集
# 创建数据加载器
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True) # 训练数据加载器,批次16,打乱顺序
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=True) # 验证数据加载器,批次16,打乱顺序
test_loader = DataLoader(test_set, batch_size=1, shuffle=False) # 测试数据加载器,批次大小1,不打乱(逐个预测)
def mseLoss(pred, target, model):
# 自定义损失函数:MSE损失 + L2正则化
loss = nn.MSELoss(reduction='mean') # 创建MSE损失函数,返回平均值
''' Calculate loss '''
regularization_loss = 0 # 初始化正则化损失为0
for param in model.parameters(): # 遍历模型所有参数
# TODO: you may implement L1/L2 regularization here
# 使用L2正则项
# regularization_loss += torch.sum(abs(param)) # L1正则化(被注释掉)
regularization_loss += torch.sum(param ** 2) # L2正则化:计算所有参数的平方和
return loss(pred, target) + 0.00075 * regularization_loss # 返回MSE损失 + 正则化项(系数0.00075)
loss = mseLoss # 将自定义损失函数赋值给loss变量
#loss = nn.MSELoss() # 被注释掉的简单MSE损失
epochs = 20 # 设置训练轮数为20
lr = 0.001 # 设置学习率为0.001
device = "cuda" if torch.cuda.is_available() else "cpu" # 检测可用设备:如果有GPU就用cuda,否则用cpu
print(device) # 打印使用的设备
data_dim = 93 # 输入特征维度为93
model = myModel(data_dim).to(device) # 创建模型并移到指定设备
save_path = "model_save/best_model_pth" # 定义模型保存路径
rel_path = "pred.csv" # 定义预测结果输出路径
optimizer = optim.SGD(params=model.parameters(), lr=lr, momentum=0.9) # 创建SGD优化器,添加动量0.9
# train_val(model, train_loader, val_loader, optimizer, device, epochs, save_path) # 被注释掉的训练调用
# 提交
evaluate(save_path, test_loader, rel_path, device) # 执行评估(需要先有训练好的模型)
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)