2026年“AI主流大模型“格局洞察以及未来技术发展趋势分析
2026年初AI大模型市场呈现多元化竞争格局,各模型在性能、价格和应用场景上形成鲜明特色。Google Gemini 3 Pro以73分智能指数领跑,Claude在编程领域领先,DeepSeek以超高性价比成为中文用户首选。技术趋势显示:MoE架构普及、推理能力专项突破、国产模型性价比优势明显。未来十年AI发展将转向价值落地,重点关注多模态融合、智能体工业化、世界模型等十大方向。选择建议强调&qu
一、主流大模型对比:2026年初格局洞察
前言
从OpenAI的GPT系列到谷歌的Gemini,从Anthropic的Claude到中国的DeepSeek,全球AI大模型市场已形成多元竞争格局。2026年初,各模型在智能、价格、应用场景上展现出鲜明特色,选择不再只是“哪个最强”,而是“哪个最适合你”。

🏆 性能与价格:第一梯队全景
根据2025年12月的权威评测数据,全球主流大模型在智能指数与价格上呈现出清晰的梯队分布。
模型 智能指数 价格 ($/百万token) 核心定位 Google Gemini 3 Pro Preview 73 4.50 全能王者,多模态领先 Claude Opus 4.5 70 10.00 编程与写作专家 GPT-5.1 (high) 70 3.44 综合实力强劲 DeepSeek V3.2 66 0.32 性价比之王 Kimi K2 Thinking 67 1.07 思维推理新星 数据来源:Artificial Analysis 2025年12月排行榜
核心能力矩阵
不同模型在特定领域展现出差异化优势。根据2025年的对比分析,各模型的核心能力评分(满分10分)如下:
从能力分布看,GPT-4.5/4o在多模态处理(9.6分)和易用性(9.8分)上表现突出,适合日常综合应用。Claude 3.7 Sonnet则在推理能力(9.7分)和长文本处理(9.7分)上领先,成为研究和编程的首选。

应用场景指南
🤖 日常助手与创意
GPT-4.5/4o和Google Gemini 2.0是最佳选择。GPT在创意写作方面得分高达9.5分,能够生成高质量的文学作品和营销文案。Gemini与Google生态深度集成,适合Gmail、Docs等服务的重度用户。
💻 编程与技术开发
Claude 3.7 Opus被广泛认为是编程能力全球第一的模型,其Artifacts功能提供了最佳的交互式开发环境。DeepSeek R1在代码生成和理解方面同样表现出色,且完全开源免费,成为预算有限开发者的首选。
🔬 学习与研究
对于学术研究和深度思考任务,Claude 3.7 Sonnet的混合推理能力和MCP集成使其能够提供深入准确的研究内容。Kimi则专注于长文本分析,能精准总结数百页的财报、合同或法律文书,被誉为“长文本处理的开创者”。
🧮 数学与科学问题
Grok 3在AIME数学测试中得分高达95.8%,是解决复杂数学和科学难题的明确首选。其依托X平台数据,实时性全球第一,对时事热点的反应速度无人能及。
🇨🇳 中文与多语言需求
QWQ-2.5 MAX和DeepSeek在中文处理方面表现尤为出色,其中DeepSeek的中文理解能力被认为是“全球断层第一”。对于主要使用中文的用户,这些国产模型不仅免费,还针对中文进行了特别优化。
技术趋势与市场格局
2025-2026年,AI大模型市场呈现出几个明显趋势:
- 混合专家架构(MoE)成为主流:如Qwen3采用MoE架构,部署成本大幅下降,显存占用仅为性能相近模型的三分之一。
- 推理能力专项突破:DeepSeek R1采用强化学习进行后训练,专门提升数学、代码和自然语言推理等复杂任务能力。
- 国产模型性价比优势明显:DeepSeek V3.2以GPT-5约1/10的价格达到相近性能,性价比评分达206.25(智能指数/价格)。
- 多模态融合加速:文本、图像、音频处理能力全面整合,GPT-4.5/4o和Gemini在多模态能力上领先。
市场格局上,Google Gemini 3 Pro Preview以73分智能指数登顶2025年12月排行榜,显示谷歌在AI领域的强势崛起。同时,国产模型在前15名中占据3席,在特定场景表现突出。
选择建议:找到你的“最佳拍档”
基于不同用户需求,2026年的模型选择建议如下:
🎯 按需求匹配模型
1. 追求易用性与综合性能
选择 GPT-4.5/4o($20/月)或 Gemini 2.0($19.99/月),两者提供最友好的用户体验和多模态能力。
2. 注重性价比与中文支持
DeepSeek 完全免费且性能接近付费模型,是目前的“版本答案”。处理极长中文文档可选 Kimi。
3. 需要深度思考与研究
Claude 3.7 的混合推理能力和深度思考模式提供了独特价值,被誉为“最强打工模型”。
4. 重视隐私与开源
开源模型 DeepSeek R1 和 QWQ-2.5 MAX 可完全离线运行,确保数据不被发送给第三方。
AI发展已进入精细化时代,没有“绝对最好”的模型,只有“最适合”的模型。选择时应综合考虑预算、使用场景、技术能力和隐私需求,找到能最大化AI技术价值的助手。
二、未来技术趋势:2026-2036 十年展望
核心洞察
2026年标志着AI从“参数竞赛”转向“价值落地”的关键转折。技术竞争焦点已从“模型规模”转向“推理效能、场景适配与成本控制”,推动AI从实验室走向千行百业的生产一线。
🚀 参数竞赛 → 🎯 价值落地
十大核心发展方向
1. 多模态原生融合
告别“文本+图像”的简单拼接,原生多模态模型通过统一特征空间实现深度对齐。谷歌Gemini 3.0 Ultra支持2000万Token上下文,可直接处理2小时长视频。
2. 智能体工业化落地
Agentic AI元年,智能体从“对话助手”升级为“数字员工”。某银行部署智能投研Agent,研报生成周期从3天缩短至4小时。
3. 世界模型兴起
从“预测下一个词”到“预测世界状态”。DeepMind的AlphaFold 4.0将世界模型与蛋白质预测结合,精度提升30%。
4. 架构创新取代参数堆砌
MoE架构、神经符号融合等技术实现效率革命。阿里通义千问采用动态路由MoE,推理成本降低60%。
5. 端侧模型规模化部署
“云-边-端”协同成为主流。苹果MLX框架使7B参数模型在iPhone上实时运行,延迟<100ms。
6. RAG技术成熟
检索增强生成技术根治幻觉。GPT-5.3原生支持RAG,幻觉率降至0.5%以下。
7. 垂直领域模型爆发
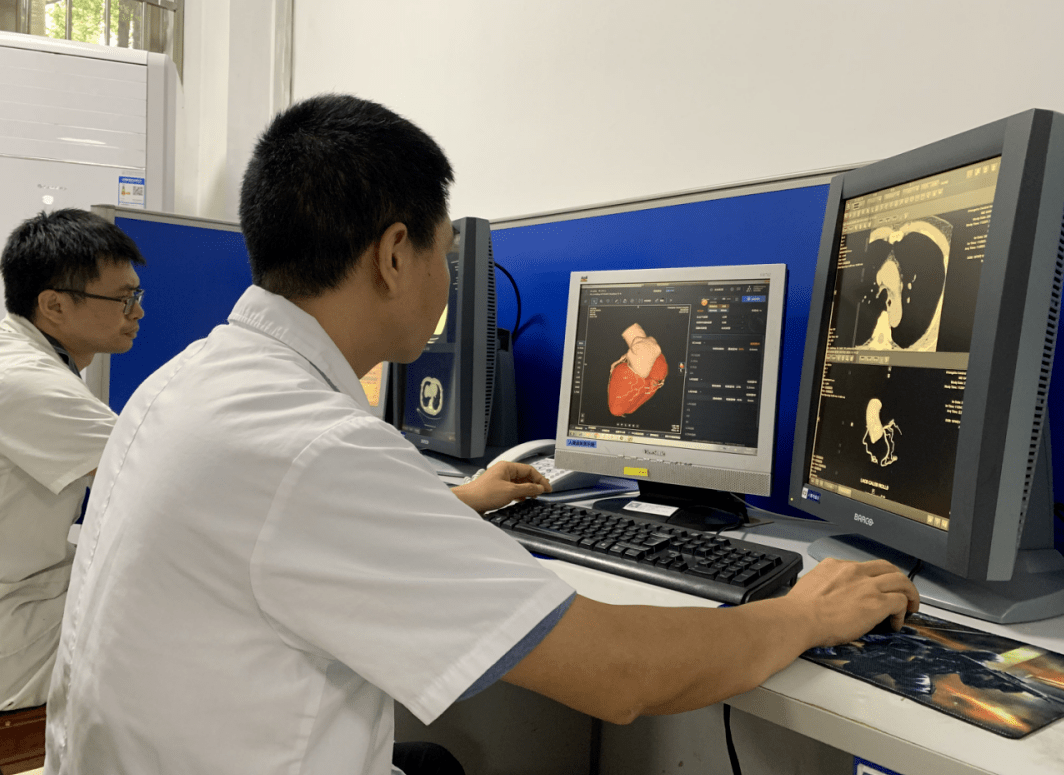
“医源AI”、“法智模型”等专家模型崛起。联影医疗元智大模型诊断准确率超95%。
8. 模型安全与可控
差分隐私、联邦学习等技术升级。OpenAI的DP-GPT实现训练数据零泄露。
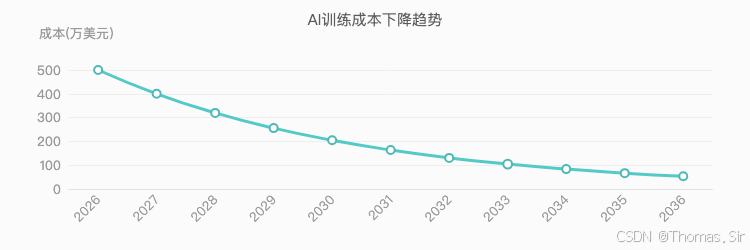
9. 成本革命性降低
训练成本降低90%以上。GPT-5级模型训练成本从1亿美元降至500万美元。
10. 开源生态崛起
中国模型全球领先。2026年2月,中国大模型周调用量首次超越美国。
关键技术突破
⚛️ 量子计算突破: IBM预测2026年量子计算机将首次超越传统计算机
🤖 具身智能进化: “大小脑协同”架构推动人形机器人商业化
🌐 智能体通信协议: MCP/A2A成为Agent时代的“TCP/IP”
写在最后的话
我们正见证从AI工具到AI队友的历史性转变。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)