
Agent Skills 和 MCP:两种扩展 AI 能力的路径,你真的选对了吗?
回到文章开头的问题:应该用 Claude Skills 还是 MCP?取决于你的具体场景。选择 Claude Skills,如果• ✅ 你的需求是标准化、通用的• ✅ 已有现成的 Skills 可以满足需求• ✅ 你希望快速上手,不想处理配置和部署• ✅ 你是个人用户或小团队选择 MCP,如果• ✅ 你需要连接特定的内部系统• ✅ 你的需求高度定制化• ✅ 你需要在多个 AI 平台间复用集成• ✅

Agent Skills 和 MCP:两种扩展 AI 能力的路径,你真的选对了吗?
引言:一个常见的困惑
最近在和几位开发者朋友聊天时,我发现一个有趣的现象:当大家想给 Claude 增加新能力时,经常会陷入一种选择困境——"我应该用 Claude Skills 还是 MCP?"更有意思的是,很多人会把这两者混为一谈,认为它们只是"两种实现同一目标的技术方案"。
这种误解其实很正常。毕竟,它们看起来确实都能让 Claude "做更多事情":你想让 Claude 发邮件?Skills 可以,MCP 也可以。你想让 Claude 读取数据库?Skills 可以,MCP 也可以。那它们到底有什么区别?
事实上,这就像在问"汽车和公路有什么区别"——表面上它们都和"出行"有关,但本质上它们处于完全不同的层次。如果你搞混了它们的定位,可能会花费大量时间走弯路,甚至做出错误的架构决策。
今天这篇文章,我想用最通俗的方式,帮你彻底理清 Claude Skills 和 MCP 的异同、各自的定位,以及在实际项目中应该如何选择。相信读完后,你会对 AI 能力扩展有一个更立体的认识。
背景:它们各自解决什么问题?
在深入对比之前,我们需要先理解它们各自诞生的背景和要解决的核心问题。
Claude Skills:预制的能力包
想象一下,你买了一台新手机。手机系统自带了相机、计算器、日历等应用,这些应用开箱即用,无需任何配置。Claude Skills 就像这些预装应用——它是 Claude Code(或其他 Claude 客户端)内置的一组预制能力包。
每个 Skill 本质上是一个封装好的、有特定用途的功能模块。比如:
-
• pdf Skill:让 Claude 能处理 PDF 文件
-
• xlsx Skill:让 Claude 能操作 Excel 表格
-
• generate-image Skill:让 Claude 能生成图片
这些 Skills 的特点是:
-
• ✅ 开箱即用:安装 Claude Code 后就能直接调用
-
• ✅ 高度封装:用户不需要关心底层实现
-
• ✅ 专注场景:每个 Skill 针对一个明确的使用场景
举个例子,当你对 Claude 说"给 jeremysong@126.com 发封邮件",Claude 会自动调用 “邮件发送” Skill,背后的认证、API 调用、错误处理等细节全部被隐藏了。
MCP:连接外部世界的桥梁
现在换个场景。你的公司有自己的内部系统——客户管理系统、订单数据库、知识库等。这些系统的数据和接口各不相同,Claude 怎么访问它们呢?
这时候 MCP(Model Context Protocol)就登场了。如果说 Skills 是预装应用,那 MCP 就像是手机的 USB 接口标准——它定义了一套统一的协议,让 Claude 能够连接到任何遵循该协议的外部系统。
MCP 的核心价值在于:
-
• 🌐 标准化协议:定义了 AI 与外部工具/数据源交互的通用标准
-
• 🔌 可扩展性:任何人都可以开发 MCP 服务器,连接新的系统
-
• 🏗️ 解耦架构:AI 模型不需要知道每个系统的具体实现
举个实际例子:你公司用的是 Jira 管理项目任务。通过开发(或使用现成的)一个 Jira MCP 服务器,Claude 就能读取你的任务列表、创建新任务、更新状态等。而这些能力不是 Claude 自带的,是通过 MCP 协议"外接"进来的。
核心原理:它们如何工作?
理解了背景,我们再深入看看它们的工作机制。
Claude Skills 的工作原理
Claude Skills 的架构相对简单直接:
用户请求 → Claude 理解意图 → 匹配并调用对应 Skill → Skill 执行任务 → 返回结果具体来说,一个 Skill 通常包含:
-
1. 触发器定义:什么样的用户请求会激活这个 Skill
-
2. 参数提取:从用户请求中提取必要参数(如邮件地址、文件路径)
-
3. 执行逻辑:调用底层工具或 API 完成任务
-
4. 结果格式化:将执行结果以用户友好的方式返回
以处理 PDF 为例:
用户:"把这份 Markdown 文档转换为 PDF"
↓
Claude 识别:需要 pdf Skill
↓
提取参数:
- input_file: document.md
- output_format: PDF
↓
调用 Skill:执行文档转换
↓
返回:"PDF 文件已生成"Skills 的执行环境是受控的,所有 Skill 代码都运行在 Claude 客户端(如 Claude Code)的沙箱中,安全性较高。
MCP 的工作原理
MCP 的架构则更像一个客户端-服务器模型:
Claude (MCP Client) ↔ MCP Protocol ↔ MCP Server ↔ 外部系统/数据源MCP 定义了三种核心能力(或称"原语"):
1. Resources(资源)
-
• 暴露数据源,让 Claude 能读取信息
-
• 例如:公司知识库、数据库表、文件系统
2. Tools(工具)
-
• 暴露操作接口,让 Claude 能执行动作
-
• 例如:创建 Jira 任务、发送 Slack 消息、查询 SQL
3. Prompts(提示模板)
-
• 预定义的提示词模板,帮助 Claude 更好地完成特定任务
-
• 例如:代码审查模板、数据分析模板
一个典型的 MCP 交互流程:
1. 启动阶段:
Claude Code 启动 → 读取配置文件 → 启动配置的 MCP 服务器
(例如启动 Jira MCP Server、Database MCP Server)
2. 发现阶段:
Claude 向每个 MCP Server 询问:"你提供哪些能力?"
Jira MCP Server 回应:"我提供 list_tasks、create_task 等工具"
3. 使用阶段:
用户:"帮我看看 Jira 上本周的任务"
Claude → 调用 Jira MCP Server 的 list_tasks 工具
MCP Server → 连接真实的 Jira API → 获取数据 → 返回给 Claude
Claude → 整理并展示给用户
4. 持续连接:
MCP Server 保持运行,Claude 可以随时调用关键点在于:MCP 定义的是协议标准,而不是具体实现。任何人都可以用任何语言(Python、Node.js、Go 等)实现一个 MCP Server,只要遵循协议规范即可。
异同对比:一张表格看清楚
|
维度 |
Claude Skills |
MCP |
|---|---|---|
| 本质定位 |
预制功能模块(应用层) |
连接协议标准(基础设施层) |
| 类比 |
手机预装应用 |
USB 接口标准 |
| 安装方式 |
客户端内置或通过 skill-creator 创建 |
独立进程,通过配置文件注册 |
| 开发难度 |
相对简单,封装程度高 |
需要理解协议,灵活性更高 |
| 适用场景 |
通用、高频的标准化任务 |
连接特定系统、定制化需求 |
| 执行环境 |
Claude 客户端内部 |
独立进程(可以是本地或远程) |
| 可复用性 |
仅在支持 Skills 的 Claude 客户端中使用 |
任何支持 MCP 的 AI 系统都能用 |
| 配置复杂度 |
低(通常无需配置) |
中到高(需要配置服务器连接) |
| 生态系统 |
Claude 官方和社区维护的 Skills 库 |
开放生态,任何人都可以贡献 MCP Server |
更深层的差异:设计哲学
从设计哲学上看,两者的差异更加明显:
Claude Skills 的哲学:易用性优先
-
• 设计目标:让用户"开箱即用",降低使用门槛
-
• 适合对象:终端用户、不想深入技术细节的开发者
-
• 权衡:牺牲一定灵活性,换取简单易用
MCP 的哲学:可扩展性优先
-
• 设计目标:建立生态系统,让 AI 能连接无限可能
-
• 适合对象:企业开发者、需要深度定制的场景
-
• 权衡:需要一定技术门槛,但获得最大自由度
实际应用场景:如何选择?
理论讲完了,我们来看几个实际案例,帮你判断在不同场景下该选哪个。
场景 1:个人博客作者
需求:你是个技术博主,想让 Claude 帮你:
-
• 生成博客文章配图
-
• 将 Markdown 转换为 PDF
-
• 批量处理图片
推荐方案:优先使用 Claude Skills
理由:
-
• 这些都是标准化的通用需求
-
• generate-image Skill、pdf Skill 开箱即用
-
• 无需维护额外服务,降低维护成本
实现方式:
# 直接使用 Skills
"帮我为这篇文章生成一张封面图" → generate-image Skill
"把这个 Markdown 导出为 PDF" → pdf Skill场景 2:企业内部助手
需求:公司想部署一个 Claude 助手,需要:
-
• 查询内部 PostgreSQL 数据库
-
• 创建和查看 Jira 任务
-
• 访问公司内部知识库(存储在 Confluence)
-
• 调用内部的订单系统 API
推荐方案:使用 MCP
理由:
-
• 这些是企业特有的系统,没有通用 Skills 覆盖
-
• 需要连接多个异构系统
-
• 需要灵活的权限控制和安全策略
-
• 一次开发,所有团队成员共享
实现方式:
// MCP 配置文件示例
{
"mcpServers": {
"company-database": {
"command": "npx",
"args": ["-y", "@company/mcp-postgres"],
"env": {
"DB_CONNECTION": "postgresql://..."
}
},
"jira": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-jira"],
"env": {
"JIRA_URL": "https://company.atlassian.net",
"JIRA_TOKEN": "xxx"
}
},
"internal-api": {
"command": "python",
"args": ["path/to/custom_mcp_server.py"]
}
}
}场景 3:混合使用
需求:你在开发一个客户服务助手,需要:
-
• 生成数据分析图表(标准需求)
-
• 查询公司 CRM 系统(定制需求)
-
• 发送邮件通知(标准需求)
-
• 记录对话到内部日志系统(定制需求)
推荐方案:Skills + MCP 混合
实现方式:
-
• 使用 generate-image Skill 生成图表
-
• 使用 xlsx Skill 处理数据导出
-
• 开发 CRM MCP Server 连接客户管理系统
-
• 开发 Email MCP Server 发送邮件通知
-
• 开发 Logging MCP Server 记录对话日志
这种组合发挥了两者的优势:标准功能用 Skills 快速实现,特殊需求用 MCP 灵活扩展。
最佳实践:让它们高效协作
基于实战经验,这里分享一些最佳实践。
实践 1:优先评估是否有现成 Skills
在考虑开发 MCP Server 之前,先检查:
-
1. Claude 官方是否已有对应 Skill
-
2. 社区是否有可复用的 Skill
-
3. 你的需求是否通用到值得封装成 Skill
只有当答案都是"否"时,再考虑 MCP。
实践 2:MCP Server 的设计原则
如果决定开发 MCP Server,遵循以下原则:
原则一:单一职责
-
• 每个 MCP Server 专注一个系统或领域
-
• 不好:一个 Server 同时处理数据库、邮件、文件
-
• 好:database-mcp、email-mcp、filesystem-mcp 分开
原则二:清晰的工具命名
# 不好的命名
def run(params): ...
def execute(params): ...
# 好的命名
def create_customer(name, email): ...
def get_customer_by_id(customer_id): ...
def list_active_customers(): ...原则三:详细的描述信息
# MCP Server 工具定义示例
{
"name": "create_customer",
"description": "创建新客户记录。需要提供客户姓名和邮箱。邮箱必须唯一,如果邮箱已存在会返回错误。",
"inputSchema": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "客户全名,至少2个字符"
},
"email": {
"type": "string",
"description": "客户邮箱地址,必须是有效的邮箱格式"
}
},
"required": ["name", "email"]
}
}描述越详细,Claude 就越能准确地使用你的工具。
实践 3:错误处理与用户反馈
无论是 Skills 还是 MCP,良好的错误处理至关重要:
# MCP Server 错误处理示例
def get_customer(customer_id):
try:
customer = db.query(customer_id)
if not customer:
return {
"error": "customer_not_found",
"message": f"找不到 ID 为 {customer_id} 的客户",
"suggestion": "请检查客户 ID 是否正确,或使用 list_customers 查看所有客户"
}
return {"success": True, "data": customer}
except DatabaseError as e:
return {
"error": "database_error",
"message": "数据库查询失败",
"details": str(e)
}注意返回的错误信息包含:
-
• 错误类型(便于 Claude 理解)
-
• 人类可读的描述
-
• 可行的建议
实践 4:安全性考虑
对于 Skills:
-
• 使用环境变量存储敏感信息(API Key、密码)
-
• 避免在 Skill 代码中硬编码凭证
对于 MCP:
-
• 实现适当的认证机制
-
• 限制 MCP Server 的权限范围(最小权限原则)
-
• 敏感操作需要额外确认
-
• 记录审计日志
# MCP Server 安全示例
def delete_customer(customer_id, confirmation_token):
# 要求危险操作必须提供确认令牌
if not verify_confirmation(confirmation_token):
return {"error": "删除操作需要确认令牌"}
# 记录审计日志
audit_log.write(f"Deleting customer {customer_id}")
# 执行删除
result = db.delete(customer_id)
return result实践 5:性能优化
Skills 性能考虑:
-
• 避免 Skill 内部执行耗时操作
-
• 对于大文件处理,考虑流式处理
MCP 性能考虑:
-
• MCP Server 保持长连接,避免频繁重启
-
• 实现缓存机制,减少重复查询
-
• 批量操作合并为单个 API 调用
# MCP Server 批量处理示例
def batch_get_customers(customer_ids):
# 不好:循环调用
# results = [get_customer(id) for id in customer_ids]
# 好:一次性查询
results = db.query_by_ids(customer_ids)
return results常见误区
在实践中,我见过一些常见的误区,这里列举出来供大家参考。
误区 1:"MCP 就是高级版的 Skills"
错误理解:MCP 功能更强大,所以应该用 MCP 替代所有 Skills
正确理解:它们解决不同层次的问题。Skills 解决"快速使用",MCP 解决"灵活扩展"。就像你不会因为有了自定义装修方案,就放弃购买成品家具。
误区 2:"我的需求简单,不需要 MCP"
错误理解:只有大型企业才需要 MCP,个人项目用 Skills 就够了
正确理解:如果你有任何现有 Skills 无法覆盖的需求(比如连接你的 Notion 笔记、个人 SQLite 数据库、自建的 API),MCP 可能是最优解。MCP 不等于"复杂",很多 MCP Server 只有几十行代码。
误区 3:"开发 Skill 比开发 MCP Server 简单"
错误理解:Skill 开箱即用,所以开发 Skill 肯定更简单
正确理解:对于标准化需求,确实如此。但对于高度定制的需求,MCP 反而可能更简单,因为:
-
• Skill 需要适配 Claude Code 的 Skill 框架
-
• MCP Server 可以用任何语言、任何架构实现
-
• MCP 的协议相对简单清晰
误区 4:"MCP Server 必须部署在本地"
错误理解:MCP Server 只能运行在运行 Claude 的机器上
正确理解:MCP 支持多种传输方式:
-
• stdio:本地进程通信(最常见)
-
• HTTP/SSE:远程 Server 部署
-
• WebSocket:实时双向通信
你可以将 MCP Server 部署在云端,团队成员共享使用。
误区 5:"一个 MCP Server 应该提供尽可能多的功能"
错误理解:为了减少 Server 数量,把所有功能塞进一个 Server
正确理解:遵循单一职责原则,多个小而专注的 Server 比一个大而全的 Server 更好维护、更容易调试、更方便复用。
展望:未来的发展方向
从技术演进的角度看,Skills 和 MCP 的未来发展可能呈现不同的轨迹:
Claude Skills 的可能方向:
-
• 更丰富的官方 Skills 库
-
• 社区驱动的 Skills 市场
-
• 跨平台 Skills(不仅限于 Claude Code)
-
• Skills 组合能力(一个 Skill 调用另一个 Skill)
MCP 的可能方向:
-
• 成为 AI 工具集成的行业标准(类似 OAuth 在身份认证领域的地位)
-
• 更多主流 AI 平台支持 MCP
-
• 企业级 MCP Server 市场的形成
-
• MCP Server 的安全认证和质量标准
两者的融合趋势:
未来可能出现"Skill powered by MCP"的模式——Skill 作为易用的前端接口,底层通过 MCP 连接实际系统。这样既保证了用户的易用性,又保持了架构的灵活性。
总结:因地制宜,各取所需
回到文章开头的问题:应该用 Claude Skills 还是 MCP?
答案是:取决于你的具体场景。
简单总结一下选择逻辑:
选择 Claude Skills,如果:
-
• ✅ 你的需求是标准化、通用的
-
• ✅ 已有现成的 Skills 可以满足需求
-
• ✅ 你希望快速上手,不想处理配置和部署
-
• ✅ 你是个人用户或小团队
选择 MCP,如果:
-
• ✅ 你需要连接特定的内部系统
-
• ✅ 你的需求高度定制化
-
• ✅ 你需要在多个 AI 平台间复用集成
-
• ✅ 你愿意投入一定开发和维护成本,换取更大的灵活性
混合使用,如果:
-
• ✅ 你的项目既有通用需求,又有定制需求
-
• ✅ 你想最大化开发效率和系统灵活性
最重要的是,不要教条地认为"必须只用一种"。技术选型的最高原则是:用最合适的工具,解决实际的问题。
结语:一个开放的生态
Claude Skills 和 MCP 的出现,标志着 AI 应用开发进入了一个新阶段——从"AI 能做什么"转向"我们想让 AI 做什么"。
Skills 让普通用户也能享受 AI 的强大能力,MCP 则为开发者打开了无限可能的大门。它们不是竞争关系,而是互补关系,共同构成了一个开放、可扩展的 AI 能力生态。
作为开发者,我们既要掌握这些工具的使用方法,更要理解它们背后的设计哲学。只有这样,才能在面对具体问题时,做出最合理的技术决策。
从0到1!大模型(LLM)最全学习路线图,建议收藏!
想入门大模型(LLM)却不知道从哪开始? 我根据最新的技术栈和我自己的经历&理解,帮大家整理了一份LLM学习路线图,涵盖从理论基础到落地应用的全流程!拒绝焦虑,按图索骥~~
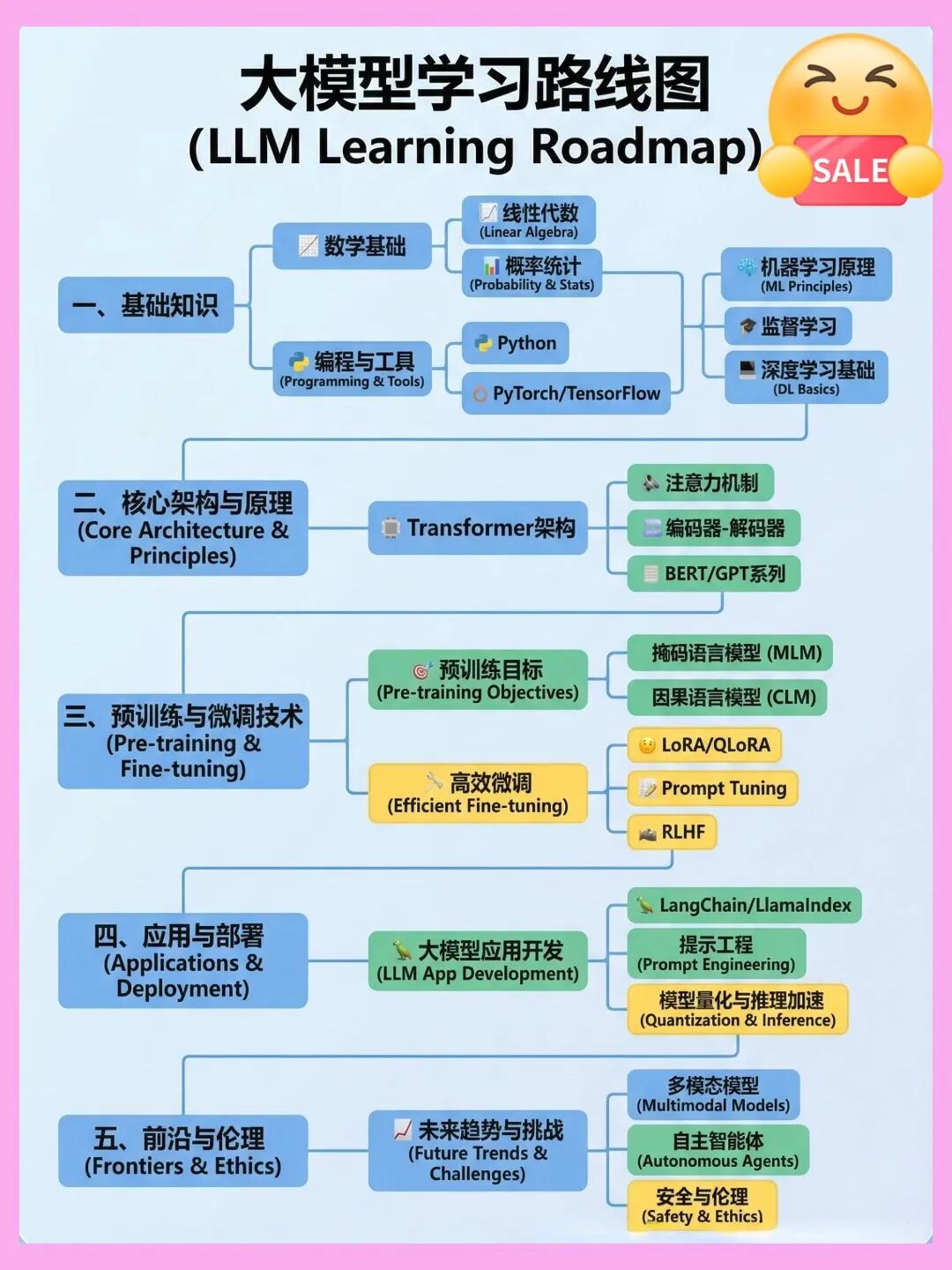
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取