Token级BatchSize理论简介与计算
本文探讨了大模型训练中BatchSize的计算方法,重点分析了样本级BatchSize的局限性,并提出了更精准的Token级BatchSize指标。文章详细阐述了GlobalBatchSize的计算公式,说明在多机多卡、梯度累积和并行策略等复杂场景下如何确定全局批次大小。通过两个具体示例(大模型预训练和指令微调),展示了不同场景下Token级BatchSize的计算过程,验证了该指标能更准确地反映
目录
1.从样本级Batch Size与Token级Batch Size
在大模型训练的工程实践中,Batch Size(批次大小)是影响训练效率、收敛速度和模型性能的关键超参数。传统的Batch Size定义仅关注样本数量,而在大模型预训练和SFT阶段,由于序列长度的显著增长,样本级的Batch Size已无法准确反映训练过程中的计算负载和梯度更新质量。因此,Token级Batch Size成为更具指导意义的核心指标。
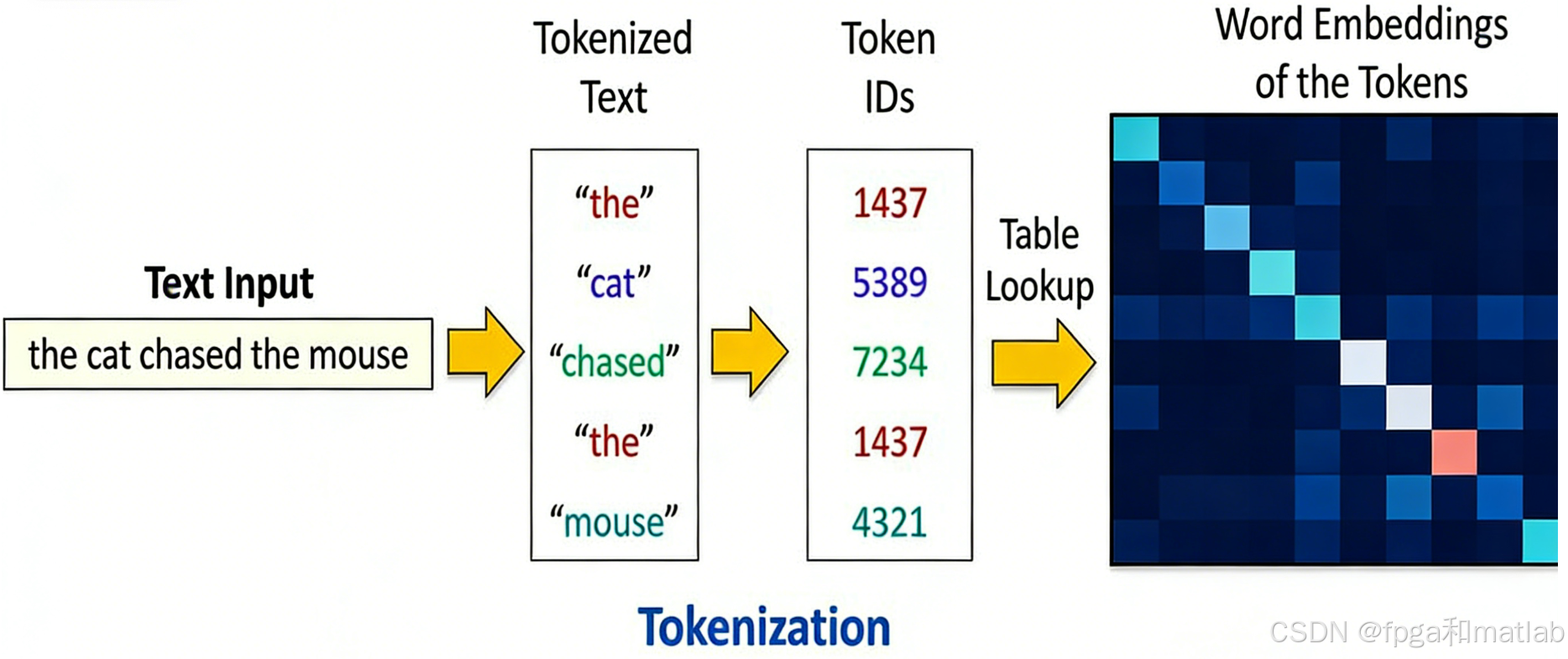
1.从样本级Batch Size与Token级Batch Size
1.1 样本级Batch Size
在传统深度学习任务中,Batch Size通常指单次前向 / 反向传播所使用的样本数量。例如,在图像分类任务中,Batch Size=32意味着每次更新梯度时,模型会处理32张图片。这种定义在样本维度固定、序列长度较短的场景下是有效的,但在大模型训练中存在明显缺陷:
忽略序列长度差异:大模型(如Transformer)的输入是变长序列,不同任务或同一任务的不同阶段,序列长度可能从几百扩展到几千甚至上万。样本级Batch Size无法区分“32个长度为512的样本” 和“32个长度为2048的样本”在计算量和Token数量上的差异。
无法反映梯度更新的有效信息:梯度更新的质量本质上取决于模型在多少Token上学习到的统计信息。样本级Batch Size相同但Token总数不同时,梯度的稳定性和泛化能力会有显著差异。
但在多机多卡、梯度累积、数据并行等复杂训练策略下,样本级Batch Size的计算变得复杂,而 Token级Batch Size可以提供更直观的基准,便于跨场景对比和调优。
1.2 Token级Batch Size
Token级Batch Size是指模型在一次梯度更新中,总共处理的Token数量。它将样本级Batch Size与序列长度结合,更精准地反映训练过程中的计算规模和梯度更新的有效信息。例如,当 max_seq_len=2048,样本级Global Batch Size=2048时,Token级Batch Size= 2048×2048 =4,194,304(约4M),这正是大模型预训练中常用的基准规模。
2.Token级Batch Size计算方法
2.1 Global Batch Size计算
要计算Token级Batch Size,首先需要明确全局批次大小(Global Batch Size),即模型在一次梯度更新中处理的样本总数。在多机多卡、梯度累积和并行策略的复杂场景下,Global Batch Size的计算公式为:

其中:
per_gpu_bs:每个GPU上的样本Batch Size,受单卡显存限制。
gradient_accumulate_step:梯度累积步数,用于模拟更大的Batch Size而不增加显存占用。
dp:数据并行度(Data Parallelism),即参与数据并行的GPU数量。
world_size:GPU总量,等于机器总数(node_cnt)乘以每台机器的GPU数量(gpu_per_node)。
pp、tp、cp:分别为流水线并行(Pipeline Parallelism)、张量并行(Tensor Parallelism)和上下文并行(Context Parallelism)的切分数量,默认值为1。
2.2 Token级Batch Size
在得到Global Batch Size后,Token级Batch Size的计算只需将其与序列长度相乘,公式为:
token_global_batch_size

其中:
序列长度(max_seq_len):决定了每个样本包含的Token数量,是Token级规模的核心乘数。
单卡 Batch Size(per_gpu_bs):受限于单卡显存,是工程实现的基础约束。
梯度累积步数(gradient_accumulate_step):通过多次前向/反向传播累积梯度,等效扩大 Batch Size。
并行策略(pp、tp、cp):通过模型并行切分,释放显存,间接支持更大的Token级Batch Size。
3.计算示例
场景1:大模型预训练
假设配置如下:
机器总数(node_cnt):32台
每台机器GPU数量(gpu_per_node):8张A100(80GB)
单卡Batch Size(per_gpu_bs):16
梯度累积步数(gradient_accumulate_step):8
序列长度(max_seq_len):2048
并行策略:tp=4,pp=2,cp=1
则:
GPU总量(world_size)=32×8=256
数据并行度(dp)=256 / (2×4×1) =32
Global Batch Size=16×8×32=4096
Token级Batch Size=2048×4096=8,388,608(约8MToken)
这一规模符合大模型预训练的常见基准(4M~8M Token),能够保证梯度更新的稳定性和模型收敛质量。
场景2:指令微调(SFT)
假设配置如下:
机器总数(node_cnt):8台
每台机器GPU数量(gpu_per_node):8张A100(80GB)
单卡Batch Size(per_gpu_bs):8
梯度累积步数(gradient_accumulate_step):4
序列长度(max_seq_len):1024
并行策略:tp=2,pp=2,cp=1
则:
GPU总量(world_size)=8×8=64
数据并行度(dp)=64/(2×2×1)=16
Global Batch Size=8×4×16=512
Token级Batch Size=1024×512=524,288(约0.5MToken)
这一规模远小于预训练阶段,符合SFT阶段 “指令数据较少、可适当缩小等效Batch Size”的实践经验。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献191条内容
已为社区贡献191条内容

所有评论(0)