Context Engineering已经不够用了:Mind Lab提出Context Learning,让模型真正「越用越聪明」
MindLab提出从ContextEngineering到ContextLearning的范式转变,认为当前AI开发瓶颈在于模型无法从使用中持续学习。其核心方案是ContextDistillation(上下文蒸馏),通过将临时上下文增益转化为参数化能力,实现模型持续进化。该方法利用强化学习机制,让模型通过自我评估和参数更新逐步内化知识。这一转变将重塑Agent开发分工,实现系统级与模型级进化的打通
当所有人都在卷Context Engineering的时候,Mind Lab说:该往前走一步了。
2025年,AI Agent开发圈最火的概念是什么?
毫无疑问是Context Engineering。从Manus的经验分享到Anthropic的官方指南,整个行业都在研究如何给模型塞入更好的上下文——更精准的RAG检索、更丰富的工具调用、更完善的MCP协议。
但一个尴尬的事实正在浮现:Benchmark分数一路飙升,真实任务的体验却在原地踏步。
比如,经过高度打磨的GPT-4o在情感智能和上下文感知上,往往比某些纯粹为刷分而训练的新模型表现更好。这说明,预训练的边际收益正在递减,进步不再只是「更多数据+更多算力」的事了。
刚刚,Mind Lab发布了一篇重磅研究博客,提出了一个核心论断:
AI Agent开发正处于拐点——从Context Engineering走向Context Learning。
简单说就是:别只是给模型「用」好的上下文了,要让模型「学会」上下文,把临时的增益变成永久的能力。
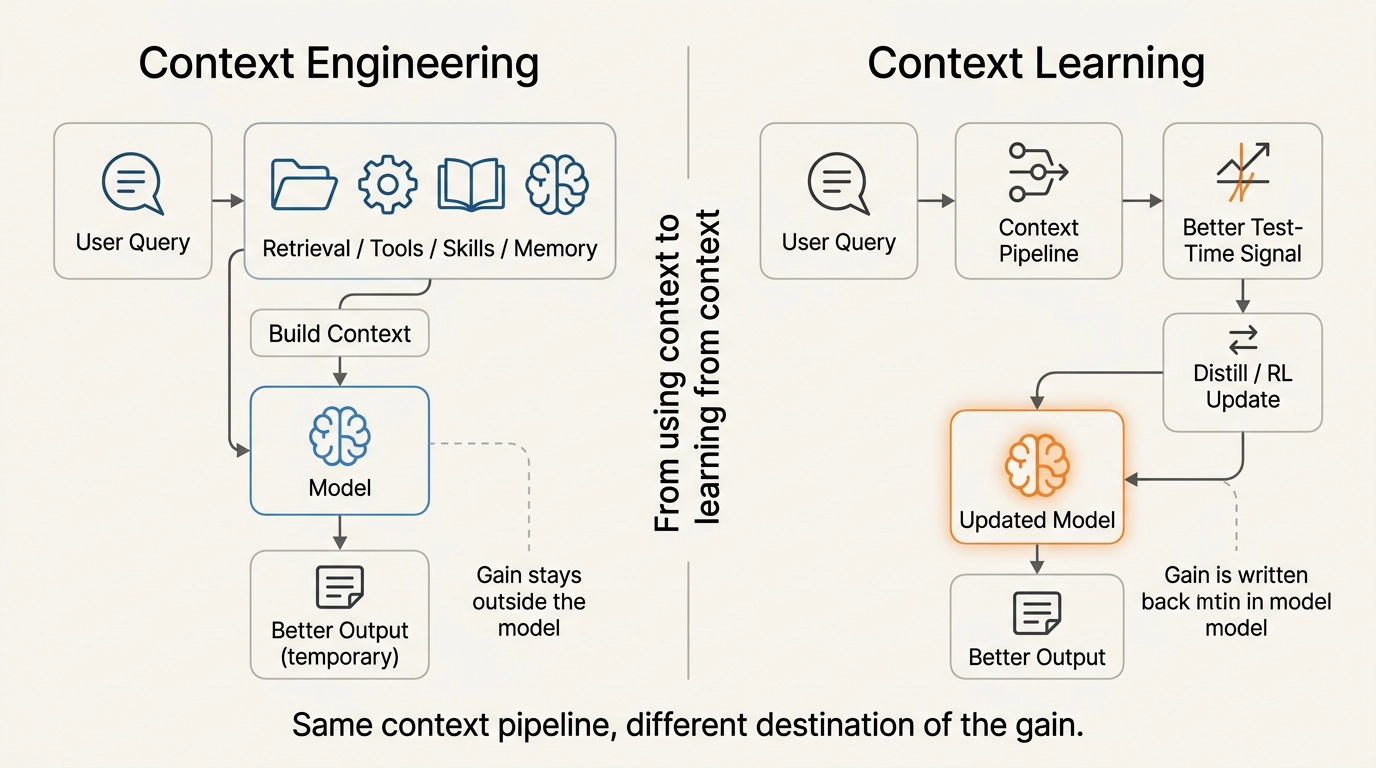
真正的瓶颈:模型不是不够强,是不会「长大」
Mind Lab在博客中指出了当前Agent开发的核心矛盾:
瓶颈不再是模型开箱即用有多强,而是模型能否从真实使用中持续变强。
这话乍一听像「正确的废话」,但细想很有深意。
当前主流的Agent架构已经相当成熟——Skills、MCP、多智能体协作、RAG、文件存储,应有尽有。这些架构能让我们快速利用前沿模型执行复杂任务。
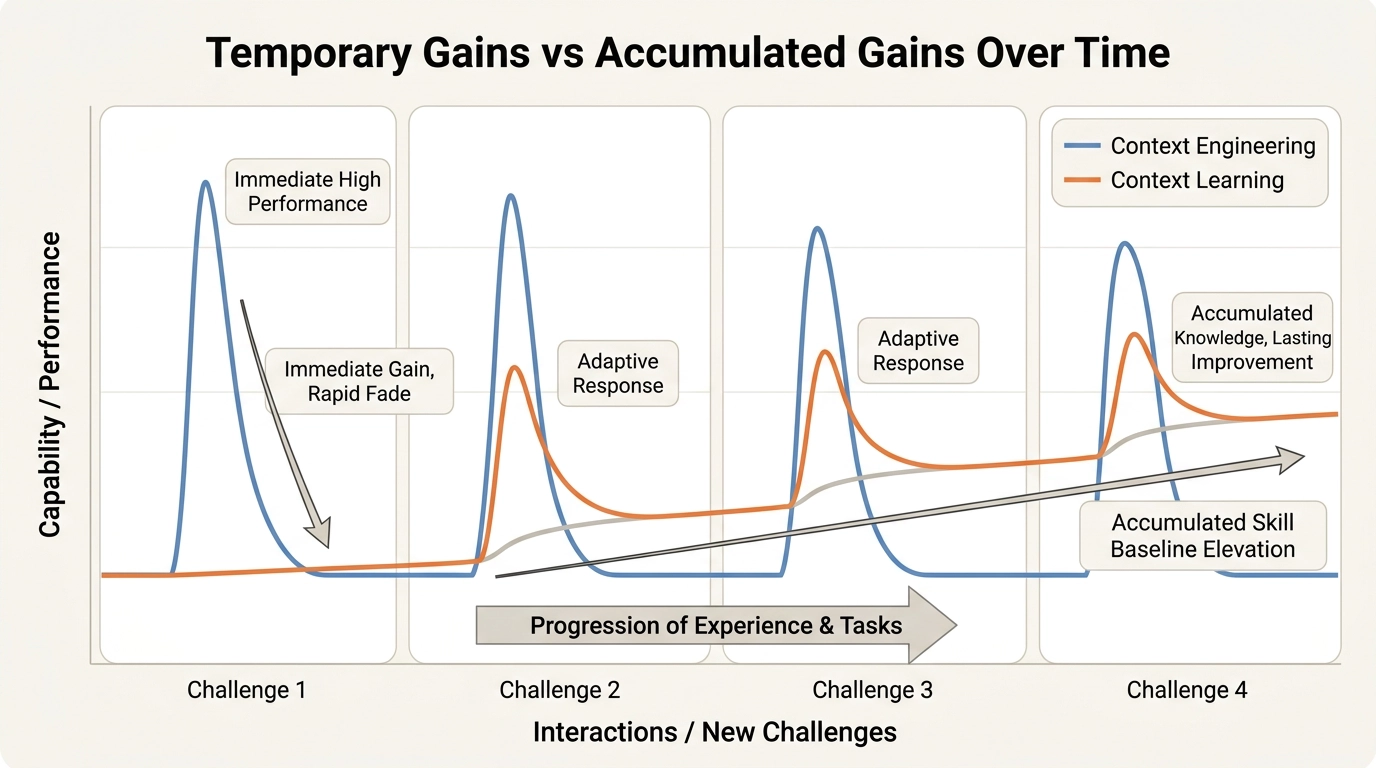
但问题是:这些全是「临时增益」。
每次新查询来了,Agent都要重新检索、重新组装上下文。检索失败?Agent就像失忆了一样,从头开始。你跟它聊了一个月的项目细节,它下次还是不认识你。
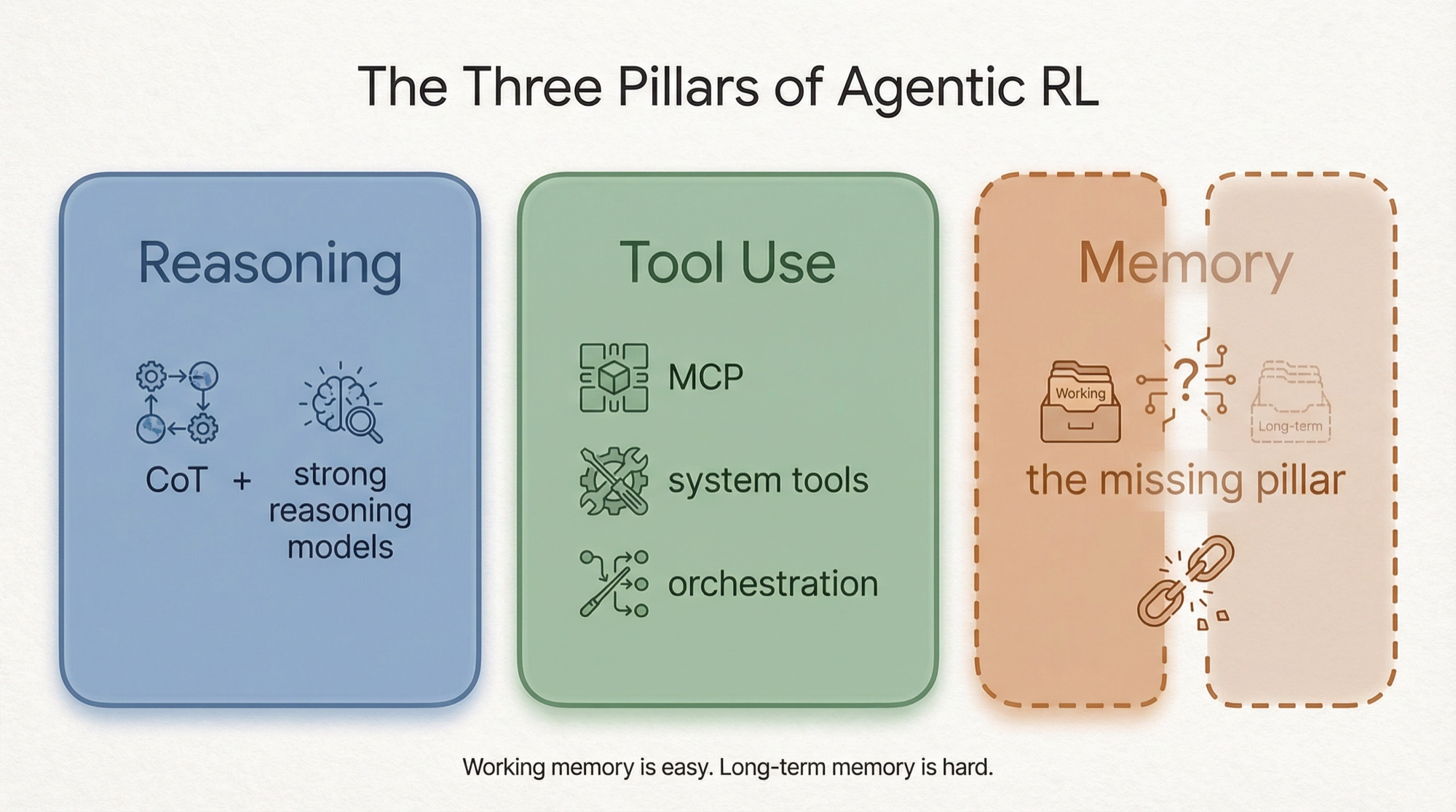
Agent RL的三大支柱,最难的一根还没立起来
Mind Lab将智能体强化学习(Agentic RL)的能力分为三大支柱:
|
支柱 |
现状 |
代表 |
|
推理 |
已有成熟方案 |
DeepSeek-R1、Chain-of-Thought |
|
工具使用 |
已有成熟方案 |
Claude MCP、Computer Use |
|
记忆 |
还没解决 |
—— |
推理和工具使用都有了清晰的技术路径和成功的商业产品。但记忆——这个最终决定用户体验的能力——仍然是硬骨头。
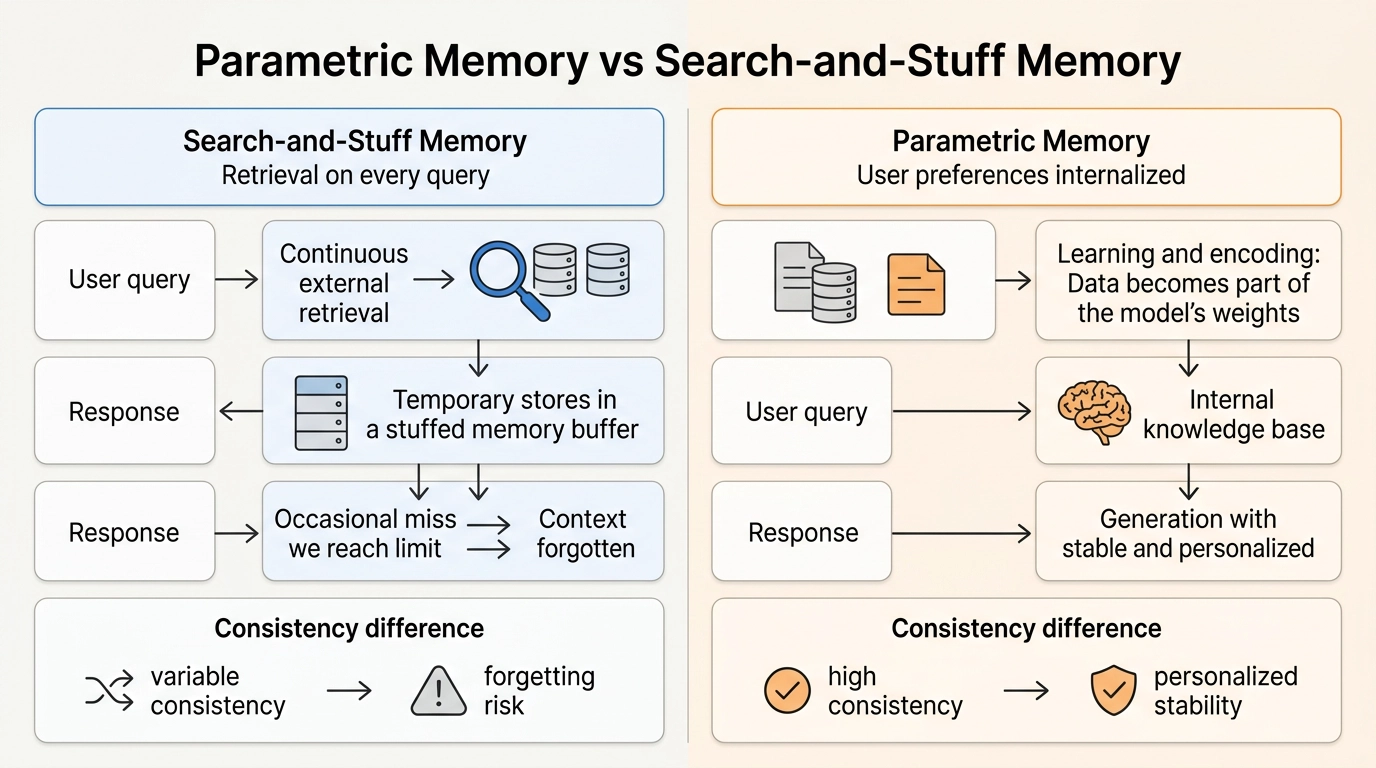
工作记忆(上下文窗口内的内容)不难处理。真正的摩擦在于长期记忆:用户习惯、偏好、约束、历史上下文的积累。
Mind Lab认为,真正的长期记忆必须是参数化的。LLM本身就是终极的参数化记忆引擎——它完美记住了世界的通用知识,但偏偏记不住「我」,也维护不好「我的产品」的稳定特征。
为什么长期记忆这么难训练?Mind Lab指出两个核心障碍:
1. 信用分配难题:今天的正确输出,很难追溯到几个月前学到的某个具体事实。
2. 缺乏可验证奖励:不像数学和代码——对错一目了然——记忆质量是主观的、长周期的、难以量化的。
结果就是,大多数团队只能退回到Context Engineering,靠检索来凑合。
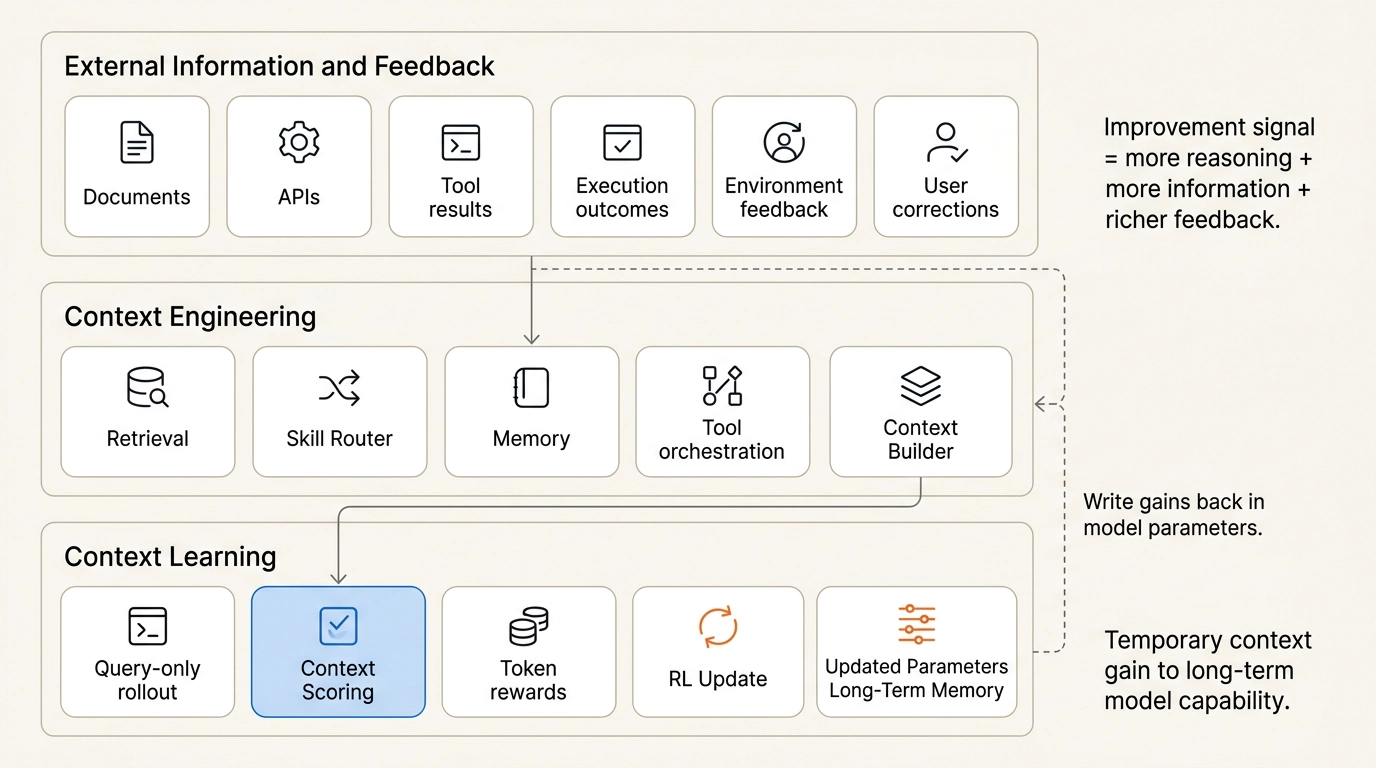
Context Distillation:把「上下文增益」写进参数
Mind Lab提出的解法叫做Context Distillation(上下文蒸馏)。
核心思想用一句话概括:如果Context Engineering能让模型在测试时变好,能不能把这种增益系统性地编码进模型参数,让它即使没有外部上下文也能保持这种能力?
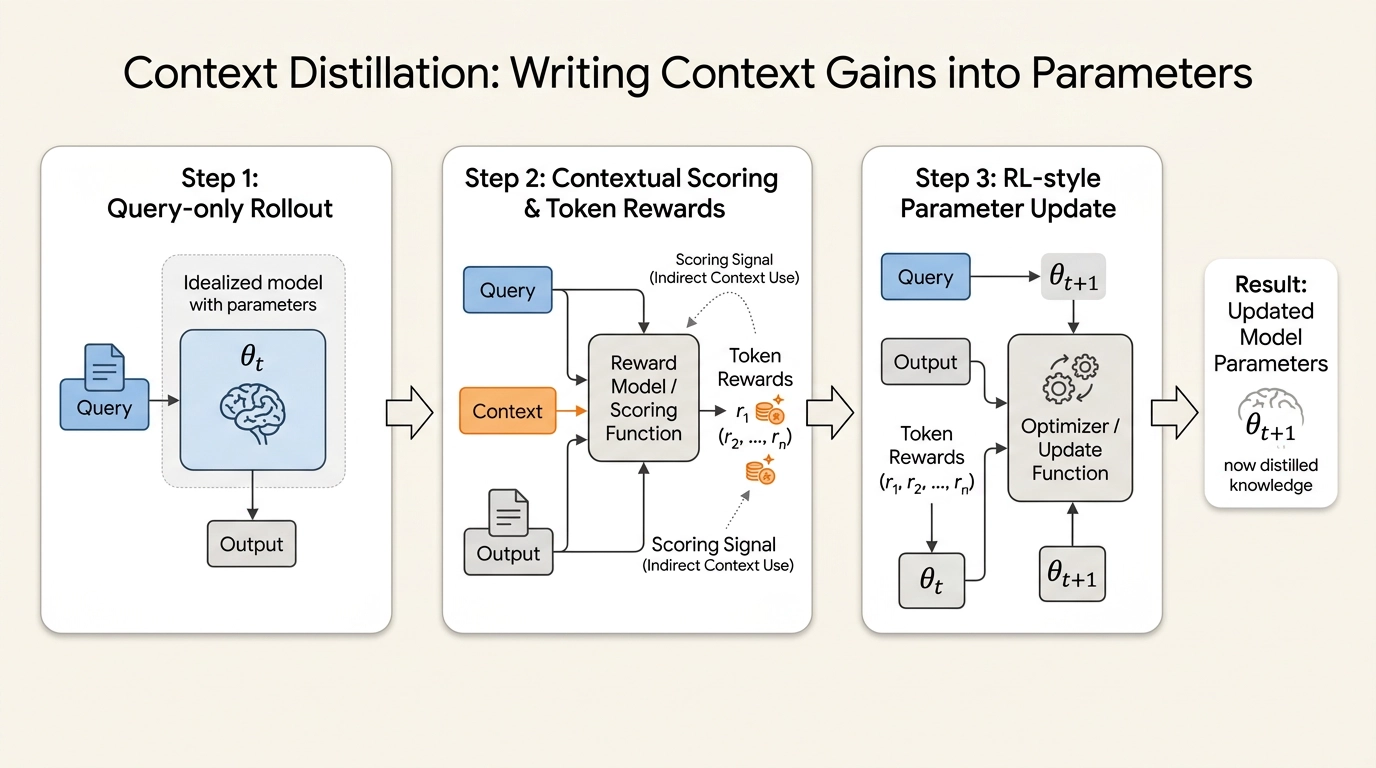
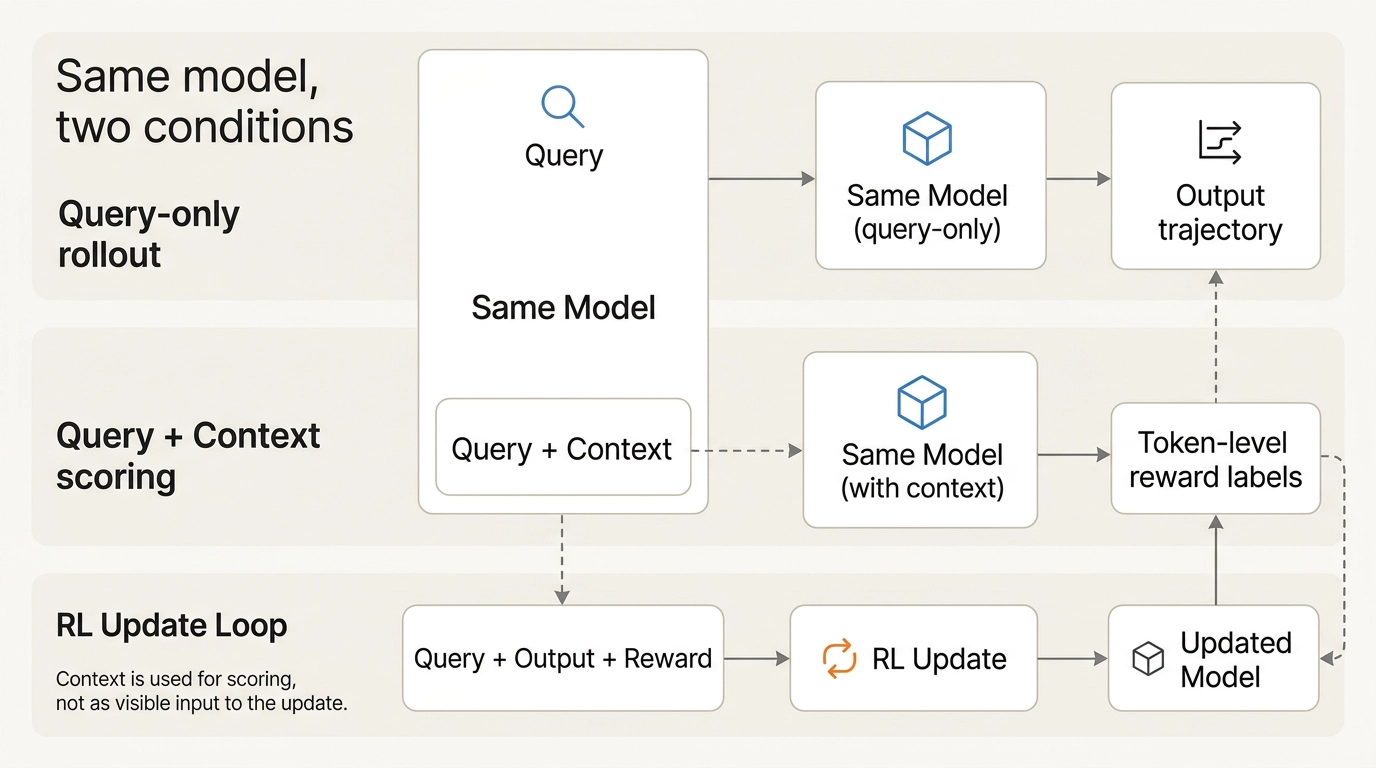
具体怎么做?
-
纯查询生成:模型仅根据查询生成一个on-policy输出(不给上下文)
-
上下文评分:用查询+上下文(RAG结果、工具反馈、示例等)对这个输出进行token级别的打分
-
RL式更新:用这个打分信号作为奖励,对模型参数做强化学习更新
def context_distill(model, query, build_context, rl_update): # Step 1: 纯查询生成on-policy rollout out = model.sample(query) # Step 2: 查询+上下文生成token级奖励 ctx = build_context(query) r_tok = model.token_reward(query, ctx, out) # Step 3: RL式参数更新 return rl_update(model, query, out, r_tok)
关键区别:上下文只用来打分,不作为训练输入。 这是一种on-policy的蒸馏方式,与传统的off-policy上下文蒸馏(先用上下文生成目标,再用SFT学习)有本质不同。
Context Learning:持续学习的闭环
把Context Distillation串成连续循环,就得到了Context Learning。
对每一个真实查询:模型生成输出→自我评估→更新参数。一轮接一轮,这就是经典的**策略迭代(Policy Iteration)**过程。
def context_learning(model, queries, build_context, rl_update, steps): for _ in range(steps): model = context_distill(model, next(queries), build_context, rl_update) return model
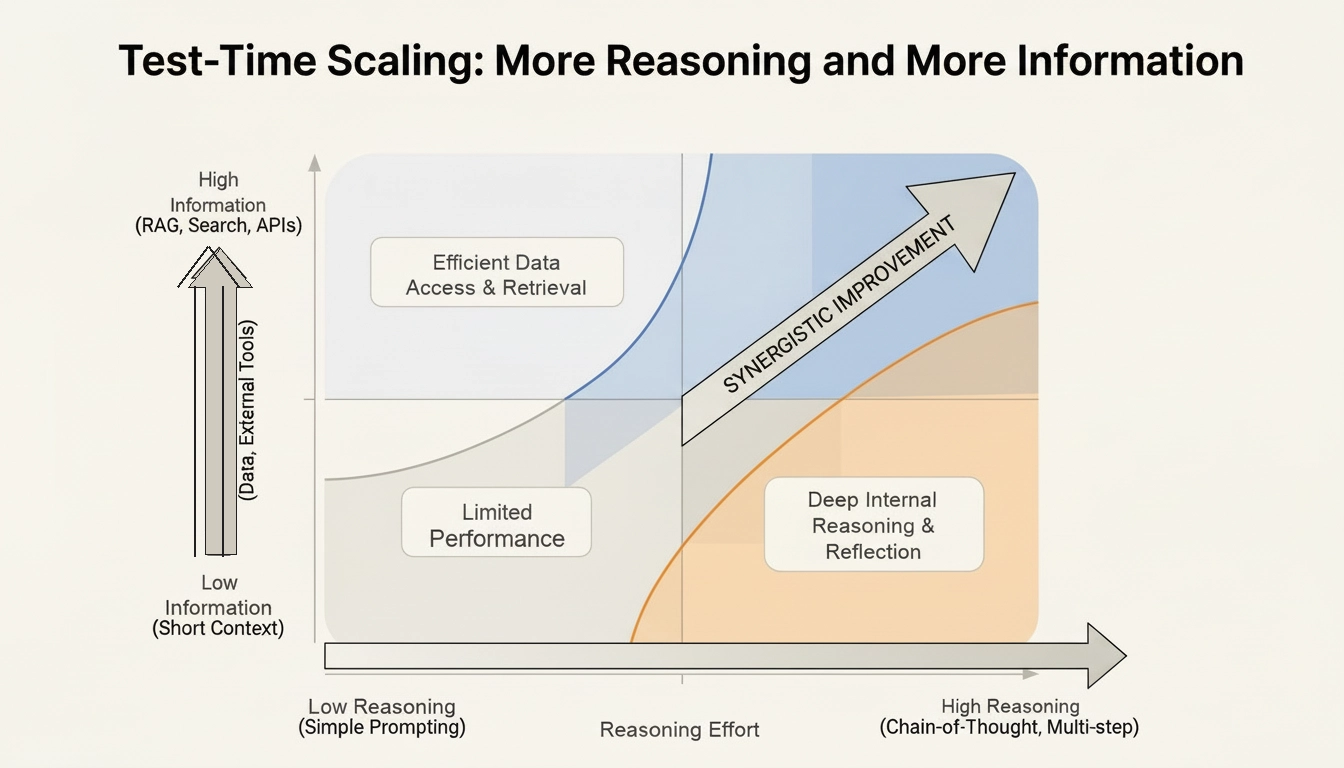
这个循环之所以有效,依赖于**测试时缩放定律(Test-Time Scaling Law)**的两个维度:
-
更多推理计算:额外的测试时推理产生更好的决策和检查
-
更多信息:更丰富的上下文(RAG、工具反馈)弥补信息缺口
举个例子:一个基于RAG的记忆系统。查询A来了,系统检索到相关记忆M1-M5。模型先不看记忆生成回复,再用查询+M1...M5对自己的回复打分,更新一次参数。查询B、C接踵而至,循环重复。每一步都把临时上下文转化为参数化技能。
三个被重塑的Agent体验
Mind Lab认为,Context Learning将改变我们构建和使用AI的方式。
一、Agent开发的新分工
过去做Agent开发,需要手工设计奖励函数、反复对抗奖励黑客。
Context Learning改变了这个分工:产品经理和工程师只需要专注于构建更好的Context Engineering管线(更好的检索、工具编排、推理触发器)。这个管线自然产生学习信号,模型自动内化。
从「系统设计」到「持久能力」的路径被大幅缩短。轨迹不再是用完即弃的日志,而是可复用的成长燃料。
二、自迭代与自进化
很多现代系统已经能够反思错误、从智能体轨迹中生成可复用的技能。在Context Learning范式下,这些动态生成的技能不仅仅保存为文本文件等待未来检索——它们直接成为训练输入。
系统级进化和模型级进化被打通了。 动态发现的技能变成了稳定的参数化知识。
三、真正的个性化
真正的个性化模型一直遥不可及——因为为个体偏好定义干净的目标函数几乎不可能。
Context Learning提供了一条实际路径:构建个性化管线,检索用户特定记忆作为上下文,通过反复的on-policy更新,逐步将偏好编织进模型参数。
配合LoRA等参数高效微调技术,每个用户都可以维护一个个人LoRA适配器(100MB–1GB),持续更新、与用户共同进化。
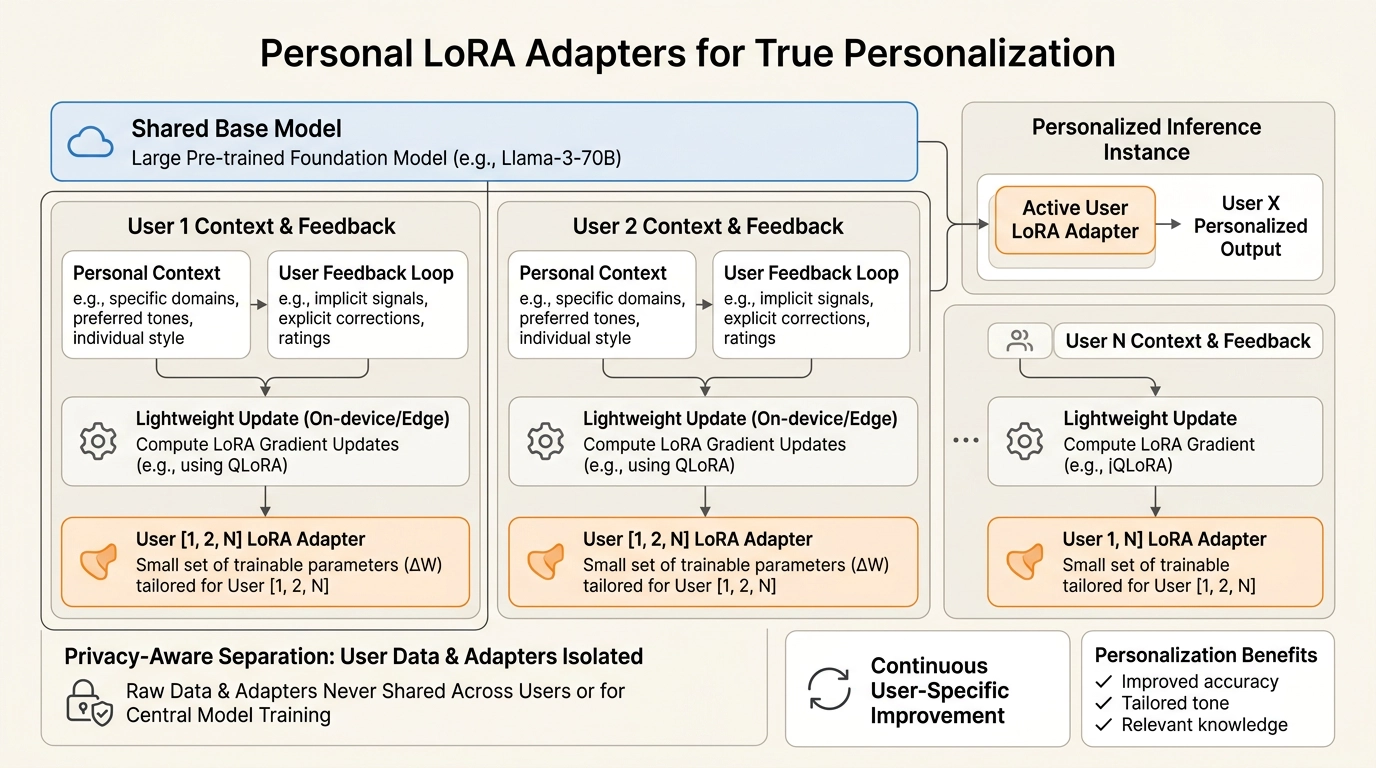
Mind Lab在做什么?
Mind Lab目前正在围绕Context Learning展开广泛实验,聚焦三个方向:
-
个性化质量
-
高级参数化记忆
-
长周期编程任务
Mind Lab的核心愿景是体验智能(Experiential Intelligence):让模型从真实用户和真实产品中持续学习。Context Learning正是闭合这个循环的关键——把临时的测试时增益转化为永久的训练时成长。
本文核心贡献者:Andrew Chen、Pony Ma。
写在最后
从Context Engineering到Context Learning,表面上只多了一个词,背后是AI Agent开发范式的根本转变。
Context Engineering问的是:怎么给模型用好上下文?
Context Learning问的是:怎么让模型学会上下文?
前者是手动喂饭,后者是教会自己吃饭。
Mind Lab认为,这是通往真正持续学习的具体一步——模型不再只是工具,而是真正「和你一起成长」的伙伴。
你觉得Context Learning能解决AI Agent的「失忆」问题吗?欢迎在评论区分享你的看法。
博客原文:https://macaron.im/mindlab/research/from-context-engineering-to-context-learning
参考链接:
-
https://macaron.im/mindlab/research/from-context-engineering-to-context-learning
-
https://macaron.im/mindlab/research/building-ai-that-learns-from-real-experience
© THE END

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)