Linux系统编程—线程同步于互斥
本文深入探讨了多线程编程中的同步与互斥问题。首先分析了售票系统超卖问题的根源,指出非原子操作导致的竞态条件是关键原因。接着详细讲解了互斥量的实现原理和使用方法,包括RAII风格的锁封装。在同步方面,重点解析了条件变量的正确使用方式,强调必须配合互斥量使用while循环检查条件。文章通过生产者消费者模型展示了同步互斥的实际应用,比较了阻塞队列和环形队列两种实现方案。最后介绍了线程池的实现原理和线程安
在日常的多线程开发中,你是不是也遇到过这些问题:明明逻辑没问题,并发跑起来就出现数据错乱?秒杀活动里库存超卖,100 件商品卖出去了 120 件?写的多线程程序跑一会就卡住不动,查了半天才发现是死锁?
其实这些问题,本质上都是没有正确处理线程的同步与互斥。作为并发编程的核心基础,同步与互斥是每个后端开发者必须吃透的知识点。今天我们就从最基础的概念出发,一步步拆解原理,再到实战中的生产者消费者模型、线程池实现,把这些知识点彻底讲透。
一、线程互斥
多线程编程里,最基础也最容易踩坑的,就是共享资源的并发访问问题。我们先从最基础的概念开始,一步步搞懂互斥的本质。
1.1 基础概念
要理解互斥,首先要搞懂这几个基础概念:
-
临界资源:多线程执行流可以同时访问的共享资源,比如全局变量、文件、网络连接等,这些资源如果不加保护,并发访问就会出问题。
-
临界区:每个线程内部,访问临界资源的那段代码,我们要保护的其实就是这段代码,保证同一时间只有一个线程能执行它。
-
互斥:任何时刻,保证有且只有一个执行流进入临界区,访问临界资源,这就是互斥的核心,本质上就是给临界区加一把锁。
-
原子性:不会被任何调度机制打断的操作,要么完全执行完成,要么完全没执行,没有中间状态。
1.2 售票系统的超卖问题
光说概念太抽象,我们来看一个最经典的案例:多线程售票系统。
我们有 100 张票,4 个售票线程同时卖票,不加任何保护的代码是这样的:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
int ticket = 100;
void *route(void *arg)
{
char *id = (char*)arg;
while ( 1 ) {
if ( ticket > 0 ) {
usleep(1000); // 模拟售票的业务耗时
printf("%s sells ticket:%d\n", id, ticket);
ticket--;
} else {
break;
}
}
}
int main( void )
{
pthread_t t1, t2, t3, t4;
pthread_create(&t1, NULL, route, (void*)"thread 1");
pthread_create(&t2, NULL, route, (void*)"thread 2");
pthread_create(&t3, NULL, route, (void*)"thread 3");
pthread_create(&t4, NULL, route, (void*)"thread 4");
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
}这段代码看起来逻辑没问题,但是运行之后,你会发现出现了这样的结果:
thread 4 sells ticket:1
thread 2 sells ticket:0
thread 1 sells ticket:-1
thread 3 sells ticket:-2票居然卖成了负数?这就是典型的超卖问题,也是并发里最常见的竞态条件 —— 因为时序的问题,导致程序结果异常。
那为什么会这样?核心原因就是 ticket-- 这个操作,它根本不是原子操作!我们把这段代码反汇编之后,会发现它拆成了三条汇编指令:
# 把ticket从内存加载到寄存器
mov 0x2004e3(%rip),%eax
# 寄存器里的值减1
sub $0x1,%eax
# 把寄存器的值写回内存的ticket
mov %eax,0x2004da(%rip)# 把ticket从内存加载到寄存器
mov 0x2004e3(%rip),%eax
# 寄存器里的值减1
sub $0x1,%eax
# 把寄存器的值写回内存的ticket
mov %eax,0x2004da(%rip)这三步操作,每一步都可能被 CPU 打断,调度其他线程执行。比如线程 A 刚把 ticket 加载到寄存器,还没减,CPU 就切到线程 B,线程 B 把 ticket 减到 0 了,然后切回线程 A,线程 A 继续执行,把自己寄存器里的值减 1,写回内存,就变成了 - 1,这就出现了超卖。
1.3 互斥量
要解决这个问题,我们就需要给临界区加一把锁,保证同一时间只有一个线程能进入这段代码,这就是 Linux 提供的互斥量。
互斥量的使用非常简单,核心接口就这几个:
-
初始化:可以静态初始化,也可以动态初始化
-
加锁:进入临界区之前加锁,锁被占用的话就阻塞等待
-
解锁:离开临界区之后解锁,唤醒等待的线程
-
销毁:用完之后销毁互斥量
我们用互斥量改造一下刚才的售票代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
int ticket = 100;
pthread_mutex_t mutex; // 定义互斥量
void *route(void *arg)
{
char *id = (char*)arg;
while ( 1 ) {
pthread_mutex_lock(&mutex); // 加锁
if ( ticket > 0 ) {
usleep(1000);
printf("%s sells ticket:%d\n", id, ticket);
ticket--;
pthread_mutex_unlock(&mutex); // 解锁
} else {
pthread_mutex_unlock(&mutex); // 退出的时候也要解锁!
break;
}
}
return nullptr;
}
int main( void )
{
pthread_t t1, t2, t3, t4;
pthread_mutex_init(&mutex, NULL); // 初始化互斥量
pthread_create(&t1, NULL, route, (void*)"thread 1");
pthread_create(&t2, NULL, route, (void*)"thread 2");
pthread_create(&t3, NULL, route, (void*)"thread 3");
pthread_create(&t4, NULL, route, (void*)"thread 4");
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
pthread_mutex_destroy(&mutex); // 销毁互斥量
}改造之后,再运行代码,就再也不会出现负数的票了,所有的售票结果都是正确的,这就是互斥量的作用。
1.4 锁是怎么实现的?
很多人会好奇,互斥量到底是怎么保证原子性的?难道加锁的操作本身不会被打断吗?
其实,大部分体系结构都提供了一个原子的交换指令:swap 或者 exchange,这个指令可以把寄存器和内存单元的数据交换,而且它是一条指令,天生就是原子的,不会被打断。
基于这个指令,我们的加锁和解锁的伪代码就变成了这样:
// 加锁的伪代码
lock:
movb $0, %al
xchgb %al, mutex // 原子交换,把mutex的值和al交换
if(al寄存器的内容 > 0) {
return 0; // 拿到锁了,返回
} else {
挂起等待; // 没拿到,等待
goto lock; // 醒来之后再试一次
}
// 解锁的伪代码
unlock:
movb $1, mutex // 把mutex设为1
唤醒等待Mutex的线程; // 唤醒等待的线程
return 0;这样一来,不管有多少个线程同时执行加锁,只有一个线程能交换到 mutex 的 1,其他的线程拿到的都是 0,就会挂起等待,这就保证了同一时间只有一个线程能拿到锁,完美实现了互斥。
1.5 RAII 风格的锁封装
手动加锁解锁有个很大的问题:很容易忘记解锁!比如临界区里有 return,或者抛异常,代码就直接跳走了,解锁的代码根本没执行,这就会导致锁永远不会释放,其他线程永远拿不到锁,也就是死锁。
为了解决这个问题,我们可以用 RAII 的思想,把锁封装起来,构造的时候加锁,析构的时候自动解锁,这样不管代码怎么跳,只要离开作用域,锁就会自动释放,再也不用担心忘记解锁了。
封装后的锁代码是这样的:
#pragma once
#include <iostream>
#include <string>
#include <pthread.h>
namespace LockModule
{
// 互斥锁的封装
class Mutex
{
public:
// 禁用拷贝和赋值
Mutex(const Mutex &) = delete;
const Mutex &operator =(const Mutex &) = delete;
Mutex()
{
int n = pthread_mutex_init(&_mutex, nullptr);
(void)n;
}
void Lock()
{
int n = pthread_mutex_lock(&_mutex);
(void)n;
}
void Unlock()
{
int n = pthread_mutex_unlock(&_mutex);
(void)n;
}
pthread_mutex_t *GetMutexOriginal()
{
return &_mutex;
}
~Mutex()
{
int n = pthread_mutex_destroy(&_mutex);
(void)n;
}
private:
pthread_mutex_t _mutex;
};
// RAII风格的锁守卫
class LockGuard
{
public:
LockGuard(Mutex &mutex):_mutex(mutex)
{
_mutex.Lock();
}
~LockGuard()
{
_mutex.Unlock();
}
private:
Mutex &_mutex;
};
}用了这个封装之后,我们的售票代码就变得非常简洁安全了:
// 错误的设计!
pthread_mutex_lock(&mutex);
while (condition_is_false) {
pthread_mutex_unlock(&mutex);
// 解锁之后,等待之前,这里有个窗口!
pthread_cond_wait(&cond, &mutex);
pthread_mutex_lock(&mutex);
}
pthread_mutex_unlock(&mutex);其实 C++11 标准库的 std::lock_guard 也是同样的原理,这也是现在工业级代码里最常用的锁的使用方式,彻底解决了忘记解锁的问题。
1.6 同步原语的性能对比
不同的同步机制,性能差异其实非常大,我们整理了常见同步原语的性能开销,给大家做个参考:
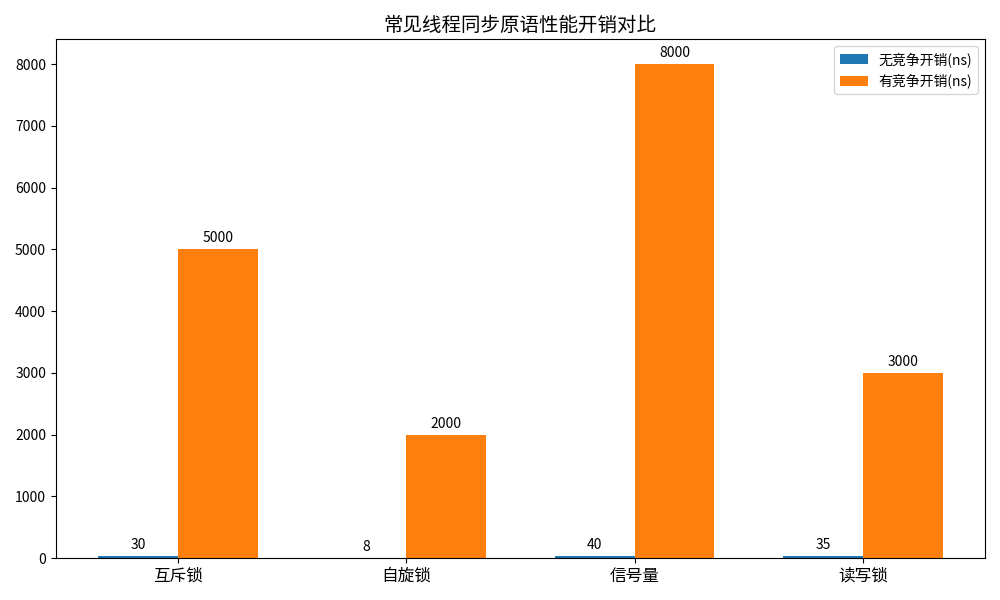
可以看到,无竞争的时候,所有的锁开销都非常小,都是纳秒级的;但是一旦有竞争,互斥锁和信号量因为涉及到上下文切换,开销就会暴涨到微秒级,而自旋锁因为不需要上下文切换,在锁持有时间短的场景下,性能会好很多。
二、线程同步
解决了数据安全的问题,我们还需要解决另一个问题:如何让线程按照我们想要的顺序执行?
比如我们有生产者和消费者,生产者生产数据,消费者处理数据,如果生产者还没生产,消费者就不能去拿数据,不然拿到空的就没用了。这就是同步:在保证数据安全的前提下,让线程按照特定的顺序访问临界资源,避免线程饥饿。
要实现同步,最常用的就是条件变量。
2.1 条件变量
条件变量是干什么的?简单来说,就是让线程在条件不满足的时候,主动阻塞等待,等条件满足了,另一个线程再把它唤醒,这样就不用让线程一直循环检查条件,浪费 CPU 了。
条件变量的核心接口有这几个:
-
pthread_cond_wait:等待条件满足,调用这个函数的线程会阻塞,直到被唤醒
-
pthread_cond_signal:唤醒一个等待在这个条件变量上的线程
-
pthread_cond_broadcast:唤醒所有等待的线程
2.2 为什么 wait 需要互斥量?
很多人刚学条件变量的时候都会有这个疑问:为什么 pthread_cond_wait 一定要传互斥量?不能分开吗?
其实这是为了避免错过信号!我们来想一下,如果我们把解锁和等待分开,写成这样的代码:
// 错误的设计!
pthread_mutex_lock(&mutex);
while (condition_is_false) {
pthread_mutex_unlock(&mutex);
// 解锁之后,等待之前,这里有个窗口!
pthread_cond_wait(&cond, &mutex);
pthread_mutex_lock(&mutex);
}
pthread_mutex_unlock(&mutex);在解锁之后,等待之前,这个时间窗口里,其他线程完全可能已经获取到锁,把条件改好了,然后发了唤醒信号。但是这时候我们的线程还没开始等待,所以这个信号就错过了,之后我们的线程再开始等待,就永远等不到信号了,永远阻塞在这里。
所以,解锁和等待必须是一个原子操作!pthread_cond_wait 这个函数,内部就帮我们把这两个操作做成了原子的:调用它的时候,会自动释放互斥量,然后开始等待,这两个操作不会被打断,这样就不会错过信号了。等线程被唤醒之后,它又会自动重新获取互斥量,然后才返回,这样我们就可以安全的检查条件了。
2.3用 while 不用 if
使用条件变量还有一个非常重要的规范:等待条件的时候,一定要用 while 循环检查,不能用 if!
这是因为存在伪唤醒:Linux 内核有时候会在没有信号的情况下,唤醒一些等待的线程,这是内核为了避免一些极端情况下的死锁,做的保护机制。所以就算线程被唤醒了,条件也不一定真的满足了,我们必须重新检查一遍,如果条件还是不满足,就继续等待。
所以正确的使用方式是这样的:
// 等待条件的代码
pthread_mutex_lock(&mutex);
while (条件为假) // 必须用while!
pthread_cond_wait(cond, mutex);
修改条件
pthread_mutex_unlock(&mutex);
// 发送信号的代码
pthread_mutex_lock(&mutex);
设置条件为真
pthread_cond_signal(cond);
pthread_mutex_unlock(&mutex);2.4 条件变量的封装
和互斥锁一样,我们也可以把条件变量封装起来,方便后续使用:
#pragma once
#include <iostream>
#include <string>
#include <pthread.h>
#include "Lock.hpp"
namespace CondModule
{
using namespace LockModule;
class Cond
{
public:
Cond()
{
int n = pthread_cond_init(&_cond, nullptr);
(void)n;
}
void Wait(Mutex &mutex)
{
int n = pthread_cond_wait(&_cond, mutex.GetMutexOriginal());
(void)n;
}
void Notify()
{
int n = pthread_cond_signal(&_cond);
(void)n;
}
void NotifyAll()
{
int n = pthread_cond_broadcast(&_cond);
(void)n;
}
~Cond()
{
int n = pthread_cond_destroy(&_cond);
(void)n;
}
private:
pthread_cond_t _cond;
};
}三、生产者消费者模型
有了互斥锁和条件变量,我们就可以实现并发编程里最经典的模型:生产者消费者模型。
3.1 模型核心:321 原则
生产者消费者模型,其实就是通过一个缓冲区,把生产者和消费者解耦,生产者生产数据放到缓冲区,消费者从缓冲区拿数据处理,两者不用直接通信。
这个模型我们可以用 321 原则来记:
-
3 种关系:
-
生产者和生产者:互斥,不能同时往缓冲区放数据
-
消费者和消费者:互斥,不能同时从缓冲区拿数据
-
生产者和消费者:互斥 + 同步,不能同时操作缓冲区,而且必须生产者先生产,消费者才能消费
-
-
2 个角色:生产者、消费者
-
1 个交易场所:共享的缓冲区
这个模型有三个非常大的优点:
-
解耦:生产者和消费者不用依赖对方,只要操作缓冲区就行,后续改其中一个,不会影响另一个
-
支持并发:生产者和消费者可以同时工作,不用互相等
-
忙闲不均:高峰期生产者快,缓冲区可以先把任务存起来,消费者慢慢处理,不会把任务丢了,也能削峰填谷。
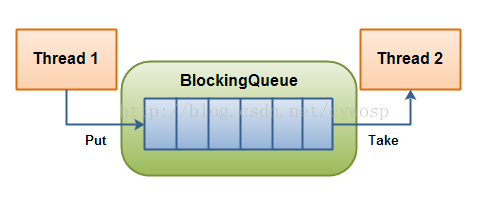
3.2 基于阻塞队列的实现
最常见的实现方式,就是用阻塞队列作为缓冲区。阻塞队列的特点是:
-
队满的时候,生产者的入队操作会阻塞,直到队列有空闲位置
-
队空的时候,消费者的出队操作会阻塞,直到队列有数据
我们来实现一个通用的阻塞队列:
#ifndef __BLOCK_QUEUE_HPP__
#define __BLOCK_QUEUE_HPP__
#include <iostream>
#include <string>
#include <queue>
#include <pthread.h>
template <typename T>
class BlockQueue
{
private:
bool IsFull()
{
return _block_queue.size() == _cap;
}
bool IsEmpty()
{
return _block_queue.empty();
}
public:
BlockQueue(int cap) : _cap(cap)
{
_productor_wait_num = 0;
_consumer_wait_num = 0;
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_product_cond, nullptr);
pthread_cond_init(&_consum_cond, nullptr);
}
void Enqueue(T &in) // 生产者入队
{
pthread_mutex_lock(&_mutex);
while(IsFull()) // 队满了,生产者等待
{
_productor_wait_num++;
// 等待的时候自动释放锁,唤醒了自动抢锁
pthread_cond_wait(&_product_cond, &_mutex);
_productor_wait_num--;
}
// 入队
_block_queue.push(in);
// 入队完了,通知消费者来消费
if(_consumer_wait_num > 0)
pthread_cond_signal(&_consum_cond);
pthread_mutex_unlock(&_mutex);
}
void Pop(T *out) // 消费者出队
{
pthread_mutex_lock(&_mutex);
while(IsEmpty()) // 队空了,消费者等待
{
_consumer_wait_num++;
pthread_cond_wait(&_consum_cond, &_mutex);
_consumer_wait_num--;
}
// 出队
*out = _block_queue.front();
_block_queue.pop();
// 出队完了,通知生产者来生产
if(_productor_wait_num > 0)
pthread_cond_signal(&_product_cond);
pthread_mutex_unlock(&_mutex);
}
~BlockQueue()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_product_cond);
pthread_cond_destroy(&_consum_cond);
}
private:
std::queue<T> _block_queue;
int _cap; // 队列容量
pthread_mutex_t _mutex;
pthread_cond_t _product_cond; // 生产者的条件变量
pthread_cond_t _consum_cond; // 消费者的条件变量
int _productor_wait_num;
int _consumer_wait_num;
};
#endif这个阻塞队列,天生就支持多生产多消费,不管多少个生产者线程,多少个消费者线程,都可以安全的并发工作。
3.3 基于环形队列 + 信号量的实现
除了阻塞队列,我们还可以用环形队列 + POSIX 信号量来实现生产者消费者模型。
POSIX 信号量,其实就是一个计数器,核心操作是 P 和 V:
-
P 操作:把计数器减 1,如果计数器小于 0,就阻塞等待
-
V 操作:把计数器加 1,然后唤醒等待的线程
我们用两个信号量:
-
空位置的信号量:初始值是队列的容量,生产者要放数据,先 P 这个,代表拿一个空位置
-
数据的信号量:初始值是 0,消费者要拿数据,先 P 这个,代表拿一个数据
然后环形队列,我们用数组来模拟,用模运算实现环状:
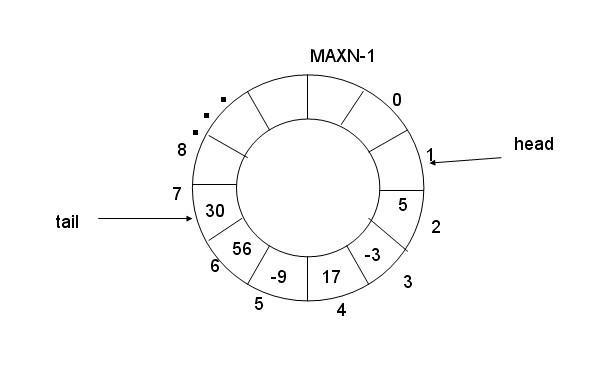
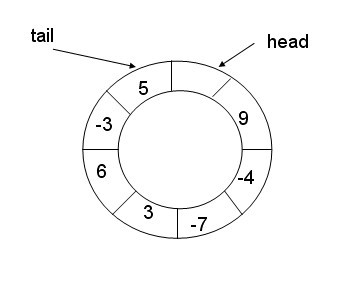
实现的代码是这样的:
#pragma once
#include <iostream>
#include <semaphore.h>
#include <vector>
#include <pthread.h>
// 信号量的简单封装
class Sem
{
public:
Sem(int n)
{
sem_init(&_sem, 0, n);
}
void P()
{
sem_wait(&_sem);
}
void V()
{
sem_post(&_sem);
}
~Sem()
{
sem_destroy(&_sem);
}
private:
sem_t _sem;
};
template<typename T>
class RingQueue
{
private:
void Lock(pthread_mutex_t &mutex)
{
pthread_mutex_lock(&mutex);
}
void Unlock(pthread_mutex_t &mutex)
{
pthread_mutex_unlock(&mutex);
}
public:
RingQueue(int cap)
: _ring_queue(cap),
_cap(cap),
_room_sem(cap), // 空位置初始是cap
_data_sem(0), // 数据初始是0
_productor_step(0),
_consumer_step(0)
{
pthread_mutex_init(&_productor_mutex, nullptr);
pthread_mutex_init(&_consumer_mutex, nullptr);
}
void Enqueue(const T &in) // 生产
{
_room_sem.P(); // 申请空位置
Lock(_productor_mutex);
_ring_queue[_productor_step++] = in;
_productor_step %= _cap;
Unlock(_productor_mutex);
_data_sem.V(); // 数据加1
}
void Pop(T *out) // 消费
{
_data_sem.P(); // 申请数据
Lock(_consumer_mutex);
*out = _ring_queue[_consumer_step++];
_consumer_step %= _cap;
Unlock(_consumer_mutex);
_room_sem.V(); // 空位置加1
}
~RingQueue()
{
pthread_mutex_destroy(&_productor_mutex);
pthread_mutex_destroy(&_consumer_mutex);
}
private:
std::vector<T> _ring_queue;
int _cap;
int _productor_step; // 生产者的下标
int _consumer_step; // 消费者的下标
Sem _room_sem; // 空位置信号量
Sem _data_sem; // 数据信号量
pthread_mutex_t _productor_mutex; // 生产者之间的互斥
pthread_mutex_t _consumer_mutex; // 消费者之间的互斥
};这种实现方式,比阻塞队列的性能还要高,因为信号量的开销比条件变量更小,非常适合高性能的场景。
四、线程池
有了前面的基础,我们就可以实现工业级的线程池了,这也是后端开发最常用的组件之一。
4.1 线程池的价值
为什么要线程池?因为创建和销毁线程的开销太大了!比如一个任务执行只需要 1ms,但是创建一个线程就要 10ms,那大部分时间都花在创建线程上了,太亏了。
线程池的作用就是复用线程,提前创建好一堆线程,任务来了就丢给线程池,线程池里的线程循环处理任务,不用每次都创建销毁线程,这样就省了大量的开销。同时线程池还能控制并发数,防止你创建太多线程,把内存撑爆。
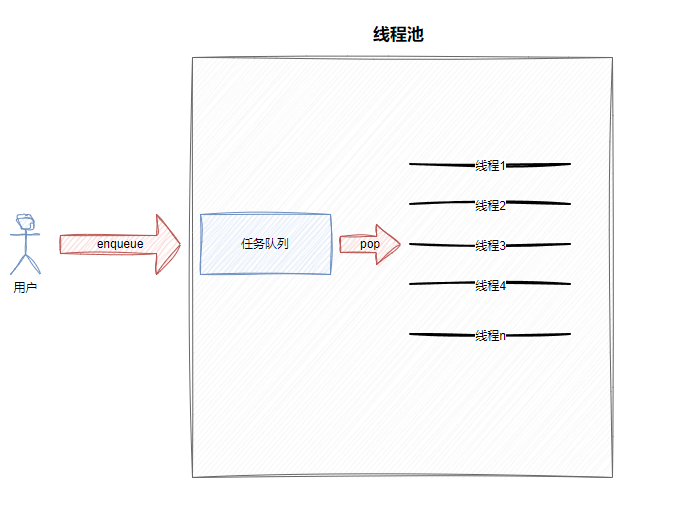
4.2 线程安全的日志系统
做线程池之前,我们先做一个线程安全的日志系统,方便我们调试,毕竟多线程的问题,日志是最好的排查工具。
日志我们用策略模式来实现,支持控制台输出和文件输出,随时可以切换,而且保证线程安全,因为控制台和文件都是临界资源,多线程同时写会乱,所以我们要加锁。
日志的代码比较长,核心的结构是这样的:
// 策略接口
class LogStrategy
{
public:
virtual ~LogStrategy() = default;
virtual void SyncLog(const std::string &message) = 0;
};
// 控制台日志策略
class ConsoleLogStrategy : public LogStrategy
{
public:
void SyncLog(const std::string &message) override
{
LockGuard lockguard(_mutex);
std::cerr << message << std::endl;
}
private:
Mutex _mutex;
};
// 文件日志策略
class FileLogStrategy : public LogStrategy
{
public:
void SyncLog(const std::string &message) override
{
LockGuard lockguard(_mutex);
// 把日志写到文件里
}
private:
std::string _logpath;
std::string _logfilename;
Mutex _mutex;
};这样我们就可以随时切换日志的输出方式,而且保证多线程写日志不会乱,非常方便。
4.3 实现线程池
线程池的核心逻辑很简单:
-
提前创建好 N 个线程,这些线程循环从任务队列里取任务
-
如果任务队列为空,线程就阻塞等待
-
主线程把任务丢到任务队列里,然后唤醒等待的线程
我们来实现这个线程池:
#pragma once
#include <iostream>
#include <vector>
#include <queue>
#include <memory>
#include <pthread.h>
#include "Log.hpp"
#include "Thread.hpp"
#include "Lock.hpp"
#include "Cond.hpp"
using namespace ThreadModule;
using namespace CondModule;
using namespace LockModule;
using namespace LogModule;
const static int gdefaultthreadnum = 10;
template <typename T>
class ThreadPool
{
private:
void HandlerTask() // 线程的处理函数
{
std::string name = GetThreadNameFromNptl();
LOG(LogLevel::INFO) << name << " is running...";
while (true)
{
_mutex.Lock();
// 任务队列为空,而且线程池还在运行,就等待
while (_task_queue.empty() && _isrunning)
{
_waitnum++;
_cond.Wait(_mutex);
_waitnum--;
}
// 如果线程池要退出,而且任务队列空了,就退出
if (_task_queue.empty() && !_isrunning)
{
_mutex.Unlock();
break;
}
// 取任务
T t = _task_queue.front();
_task_queue.pop();
_mutex.Unlock();
LOG(LogLevel::DEBUG) << name << " get a task";
t(); // 执行任务
}
}
// 私有构造,单例模式
ThreadPool(int threadnum = gdefaultthreadnum) : _threadnum(threadnum),
_waitnum(0), _isrunning(false)
{
LOG(LogLevel::INFO) << "ThreadPool Construct()";
}
// 禁用拷贝
ThreadPool<T> &operator=(const ThreadPool<T> &) = delete;
ThreadPool(const ThreadPool<T> &) = delete;
public:
// 单例获取,双重检查锁定
static ThreadPool<T> *GetInstance()
{
if (nullptr == _instance)
{
LockGuard lockguard(_lock);
if (nullptr == _instance)
{
_instance = new ThreadPool<T>();
_instance->InitThreadPool();
_instance->Start();
LOG(LogLevel::DEBUG) << "创建线程池单例";
}
}
LOG(LogLevel::DEBUG) << "获取线程池单例";
return _instance;
}
void InitThreadPool()
{
for (int num = 0; num < _threadnum; num++)
{
_threads.emplace_back(std::bind(&ThreadPool::HandlerTask, this));
LOG(LogLevel::INFO) << "init thread " << _threads.back().Name() << " done";
}
}
void Start()
{
_isrunning = true;
for (auto &thread : _threads)
{
thread.Start();
LOG(LogLevel::INFO) << "start thread " << thread.Name() << "done";
}
}
void Stop()
{
_mutex.Lock();
_isrunning = false;
_cond.NotifyAll();
_mutex.Unlock();
LOG(LogLevel::DEBUG) << "线程池退出中...";
}
void Wait()
{
for (auto &thread : _threads)
{
thread.Join();
LOG(LogLevel::INFO) << thread.Name() << " 退出...";
}
}
bool Enqueue(const T &t)
{
bool ret = false;
_mutex.Lock();
if (_isrunning)
{
_task_queue.push(t);
if (_waitnum > 0)
{
_cond.Notify();
}
LOG(LogLevel::DEBUG) << "任务入队列成功";
ret = true;
}
_mutex.Unlock();
return ret;
}
~ThreadPool()
{}
private:
int _threadnum;
std::vector<Thread> _threads;
std::queue<T> _task_queue;
Mutex _mutex;
Cond _cond;
int _waitnum;
bool _isrunning;
// 单例的静态成员
static ThreadPool<T> *_instance;
static Mutex _lock;
};
// 静态成员初始化
template <typename T>
ThreadPool<T> *ThreadPool<T>::_instance = nullptr;
template <typename T>
Mutex ThreadPool<T>::_lock;4.4 双重检查锁定
刚才的单例,我们用了双重检查锁定,这是懒汉单例的线程安全实现,很多人对这个有误解,我们来解释一下:
懒汉单例的核心是延时加载,用到的时候才创建对象,不用的时候不创建,优化启动速度。但是普通的懒汉实现,多线程下会有问题,两个线程同时调用 GetInstance,就会创建两个对象。
所以我们用了两次检查:
-
第一次检查:如果对象已经创建了,就直接返回,不用加锁,这是为了提高性能,不用每次都加锁
-
加锁:保证只有一个线程能进入
-
第二次检查:加锁之后再检查一遍,防止多个线程同时等锁,然后重复创建
但是这里还有个问题:为什么要加 volatile?因为 new T() 这个操作,CPU 可能会指令重排,把它变成:
-
分配内存
-
把指针指向这块内存(这时候对象还没构造)
-
构造对象
这样的话,另一个线程就会拿到一个未构造完成的对象,就出问题了。而 volatile 可以禁止指令重排,保证这三步的顺序,不会出现这种问题,这就是 DCL 的正确实现。
4.5 线程数怎么设?
很多人问,线程池的线程数设多少最合适?其实这个要看你的任务是 CPU 密集型还是 IO 密集型:
-
CPU 密集型任务:任务一直占着 CPU 跑,比如计算、排序这种,这时候线程数最好是CPU核心数 + 1,太多线程会导致频繁的上下文切换,反而变慢,加 1 是为了防止有线程偶尔阻塞。
-
IO 密集型任务:任务大部分时间在等 IO,比如读文件、网络请求,这时候线程可以多一点,因为线程阻塞的时候 CPU 是闲着的,所以一般设为2 * CPU核心数,让 CPU 别闲着。
我们来看一下 8 核 CPU 下,CPU 密集型任务的性能测试:
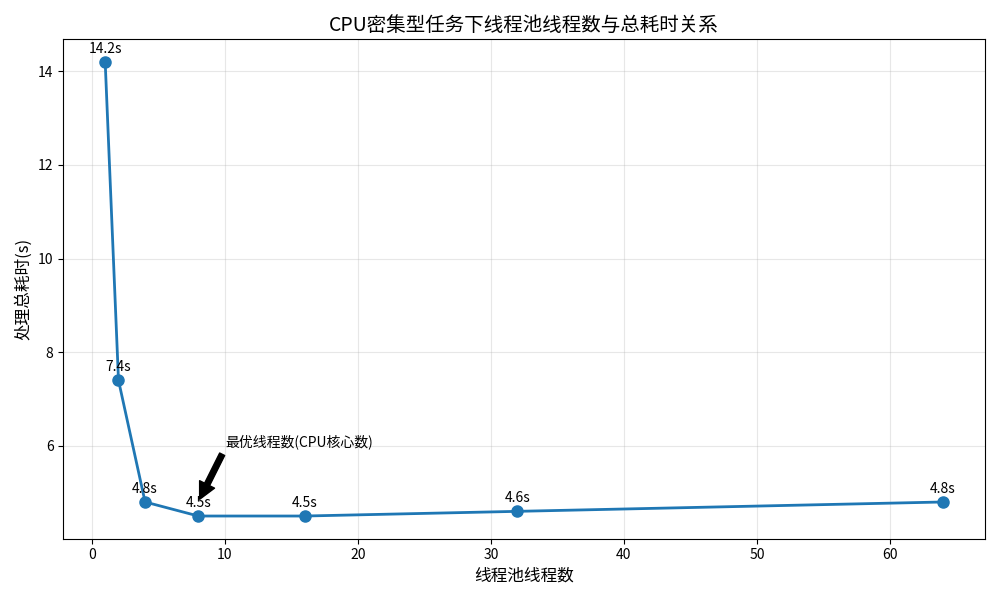
可以看到,线程数到 8的时候,耗时就降到最低了,再增加线程,耗时反而开始上升,因为上下文切换的开销越来越大,这也验证了我们的结论。
五、线程安全与可重入
学了这么多,我们来搞清楚两个很容易搞混的概念:线程安全和可重入。
5.1 核心概念
-
线程安全:多个线程同时调用同一个函数,能够正确的执行,不会互相干扰,结果正确。
-
可重入:同一个函数,一个执行流还没执行完,另一个执行流就进来了,也就是重入了,这时候结果还是正确的,那这个函数就是可重入的。重入可能是多线程,也可能是信号处理函数,比如信号来了,打断当前的函数,进入信号处理函数,又调用了这个函数。
5.2 联系和区别
这两个的关系其实很简单:
-
可重入的函数,一定是线程安全的,因为它根本不会用共享的状态,怎么调用都没问题。
-
但是线程安全的函数,不一定是可重入的!
举个最典型的例子:printf函数
-
它是线程安全的:因为它内部有锁,多个线程同时调用 printf,输出不会乱,结果是对的。
-
但是它是不可重入的:如果你在信号处理函数里调用 printf,这时候就会重入 printf,printf 的锁还没释放,就会自己把自己锁死,导致程序卡死。
这就是两者的区别:线程安全是针对多线程并发的,可重入是针对函数能不能被重复进入的。
我整理了常见的情况,给大家做个参考:
|
常见的线程不安全的情况 |
常见的不可重入的情况 |
|
不保护共享变量的函数 |
调用了 malloc/free |
|
函数状态会随调用变化 |
调用了标准 I/O 库函数 |
|
返回静态变量指针的函数 |
使用了静态数据结构 |
|
调用了线程不安全的函数 |
调用了不可重入的函数 |
六、死锁
讲完了同步互斥,我们不得不提一下并发里最头疼的问题:死锁。
6.1 什么是死锁?
死锁就是,一组线程,每个线程都拿着对方需要的资源,但是都不释放,然后都等对方释放资源,结果就永远等下去了,程序就卡住不动了。
比如我们有两个锁,锁 1 和锁 2,线程 A 拿了锁 1,要申请锁 2;线程 B 拿了锁 2,要申请锁 1,然后两个都等对方,就死锁了:
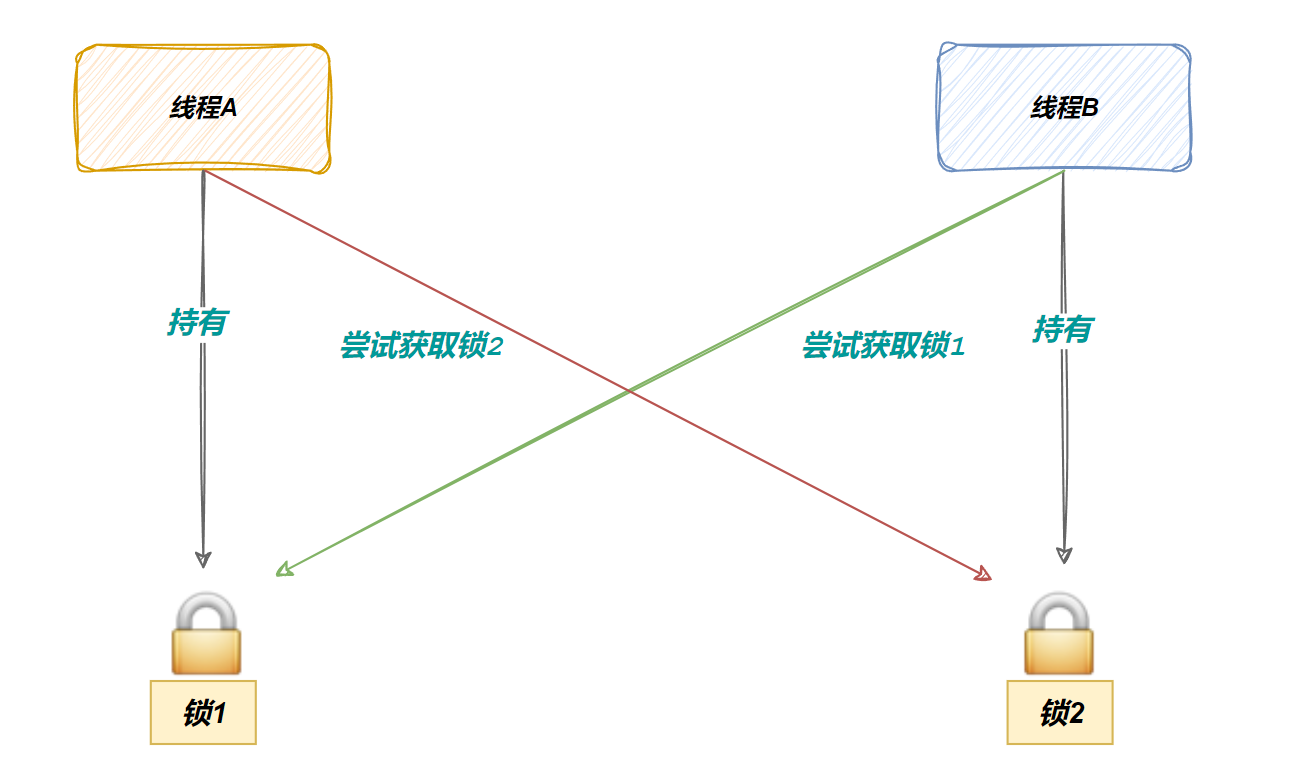
最后的结果就是,两个线程都阻塞了,永远醒不过来:

6.2 死锁的四个必要条件
-
互斥条件:资源只能一个线程用,比如锁,同一时间只能一个线程拿。

-
请求与保持条件:线程拿着自己的资源,不释放,还要申请别人的资源。
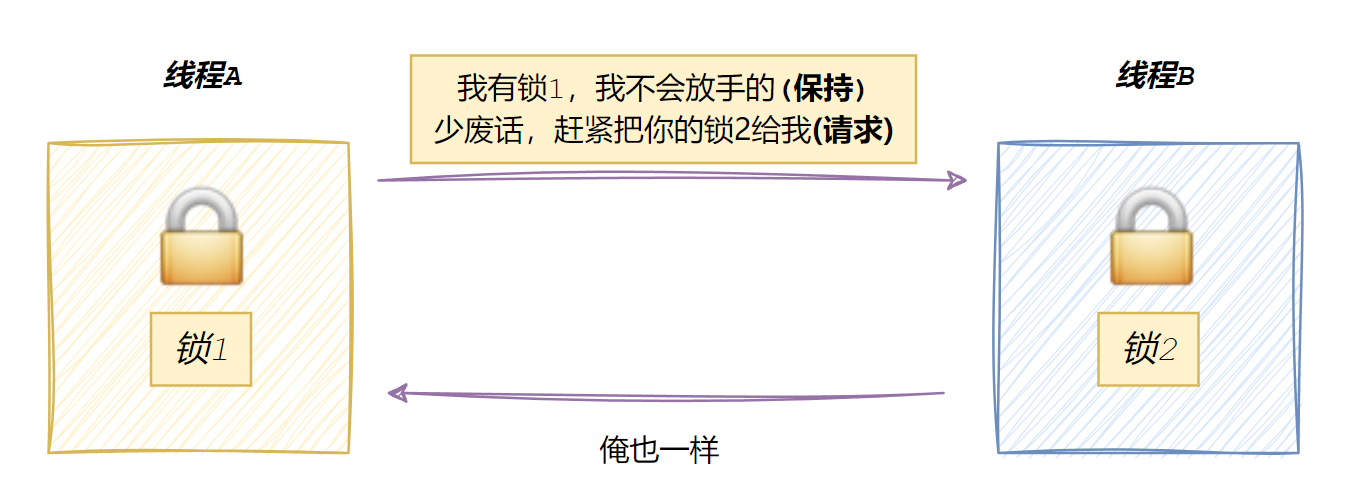
就像线程 A 说:我有锁 1 了,我不放手,我就要你的锁 2!
-
不剥夺条件:不能抢别人的资源,只能等别人主动释放,系统不能把资源抢过来给你。
-
循环等待条件:线程之间形成了一个循环,每个线程都等下一个线程的资源。
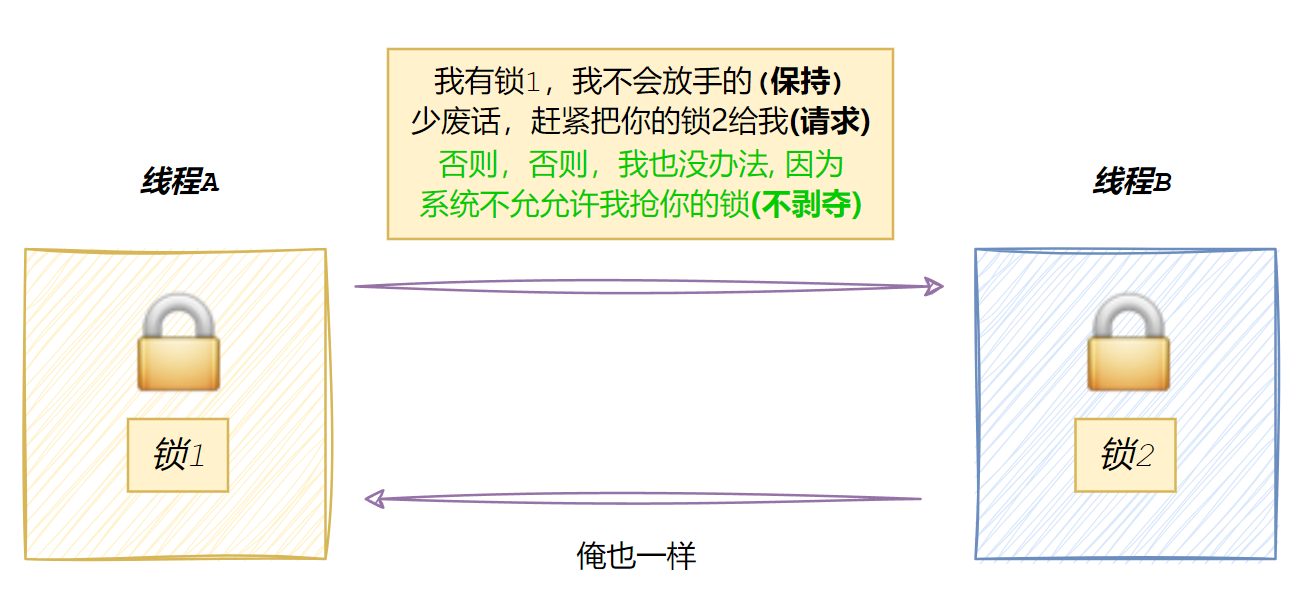
6.3 如何避免死锁?
既然死锁需要这四个条件,那我们只要破坏其中一个,就可以避免死锁了:
-
破坏循环等待:所有线程都按照同一个顺序申请锁,比如都先申请锁 1,再申请锁 2,这样就不会出现交叉申请的情况了。
-
破坏请求与保持:一次性申请所有需要的锁,要么都拿到,要么都不拿,这样就不会拿着一个锁要另一个了。
-
破坏不剥夺:申请锁的时候加超时,如果超时了,就释放自己的锁,重试,这样就不会永远等了。
我们来测试一下,一次性申请锁的效果:
void access_shared_resources()
{
std::unique_lock<std::mutex> lock1(mtx1, std::defer_lock);
std::unique_lock<std::mutex> lock2(mtx2, std::defer_lock);
// 一次性申请两个锁,原子的
std::lock(lock1, lock2);
int cnt = 10000;
while (cnt)
{
++shared_resource1;
++shared_resource2;
cnt--;
}
}测试结果:
# 分开申请锁,会出现死锁或者数据错误
$ ./a.out
Shared Resource 1: 94416
Shared Resource 2: 94536
# 一次性申请,结果完全正确
$ ./a.out
Shared Resource 1: 100000
Shared Resource 2: 100000可以看到,一次性申请锁之后,就完全不会有问题了,数据都是正确的。
6.4 常见的锁的扩展
除了我们之前讲的互斥锁,还有很多常见的锁,我们简单提一下:
-
悲观锁:每次访问数据都加锁,担心别人改,比如我们的互斥锁就是悲观锁。
-
乐观锁:不加锁,认为别人不会改,更新的时候检查有没有人改,用版本号或者 CAS 操作,比如无锁编程就是乐观锁。
-
CAS:比较并交换,就是更新的时候,判断当前值是不是我之前拿到的,如果是就更新,不是就重试,这个操作是原子的,是乐观锁的核心。
-
自旋锁:拿不到锁的时候,不阻塞,一直循环检查锁是不是释放了,适合锁持有时间短的场景,不用上下文切换,性能高。
-
读写锁:读的时候可以多个线程同时读,写的时候只有一个线程,适合读多写少的场景,比如缓存。
七、常见组件的线程安全避坑
最后,我们来聊一下日常开发中,常见组件的线程安全问题,很多人都踩过坑。
7.1 STL 容器的线程安全?
很多人问,STL 的容器是不是线程安全的?答案是:不是。
因为 STL 的设计目标是极致的性能,加锁会带来很大的性能开销,所以 STL 默认不加锁,需要调用者自己保证线程安全。
具体来说:
-
多个线程同时读同一个容器,是安全的,因为读不会改容器。
-
如果有一个线程写,其他的线程读或者写,就不安全了,会导致数据错乱、迭代器失效等问题。
比如 vector 的 push_back,多个线程同时 push_back,就会导致容量增长的时候,迭代器失效,数据拷贝错了,所以多线程用 STL,一定要自己加锁。
7.2 智能指针的线程安全?
还有智能指针,很多人以为 shared_ptr 是线程安全的,其实也不全是:
-
unique_ptr:没问题,因为它独占资源,不会共享,所以没有并发问题。
-
shared_ptr:它的引用计数的操作是原子的,所以多个线程同时修改引用计数,是安全的,这也是很多人说它线程安全的原因。
-
但是!shared_ptr 指向的对象本身的访问,不是线程安全的!如果多个线程同时修改这个对象,还是需要加锁的!
很多人都踩过这个坑,以为用了 shared_ptr 就不用加锁了,结果还是出了数据错乱的问题,一定要注意。
总结
线程的同步与互斥,是并发编程的核心,从最基础的互斥锁、条件变量,到经典的生产者消费者模型,再到工业级的线程池实现,本质上都是基于这些基础的原语构建的。
搞懂了这些,你就能写出正确的多线程代码,避开超卖、死锁、数据错乱这些坑,这也是每个后端开发者必须掌握的基本功。
希望这篇文章能帮你彻底搞懂线程同步与互斥,如果你觉得有用,欢迎点赞收藏,有问题也可以在评论区交流。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)