智能体上下文:SimpleMem、Nia、MemSkill、MemoV、DeepMiner、PlugMem
SimpleMem、Nia、Nocturne、MemSkill、MemoV、DeepMiner、PlugMem
智能体上下文视图截图LLM记忆管理问题,不严谨地等同于记忆模块:
- Agent记忆理论与实现:Mem0、MemU、MemOS
- Agent记忆框架(二):Memvid、Memary、MemoryOS
- Agent记忆框架(三):Zep、MIRIX、Memobase、LightMem、LangMem、A-MEM、MemTool
SimpleMem
论文,开源(GitHub,3.1K Star,304 Fork)终身记忆系统,在固定上下文预算下显著提升LLM Agent的长期交互能力与检索效率。
当前LLM Agent的长期记忆系统主要存在两类局限:
- 通过扩展完整历史上下文进行被动记忆,易引入冗余信息,导致Token利用率低下;
- 依赖在线推理过滤噪声的方法虽能提升相关性,但需要多轮推理,带来较高延迟与计算成本。
论文提出基于语义无损结构化压缩的三阶段记忆管理流程:
- Semantic Structured Compression:压缩,将对话窗口转化为上下文无关的紧凑记忆单元;
- Online Semantic Synthesis:合成,在写入阶段即时整合相关记忆,减少碎片化存储;
- Intent-Aware Retrieval Planning:规划,根据查询意图动态规划检索深度,并在语义、词法与符号多视角索引中并行检索,构建高密度上下文。
SimpleMem证明:相比构建复杂图结构记忆,通过语义压缩驱动的信息密度优化,才是突破Agent长期记忆Token瓶颈的关键路径。
Nia
官网,专为AI代理设计的实时上下文基础设施,记忆外挂。为AI编码代理注入真实、实时、全库级代码与文档上下文,终结幻觉,提升准确率。
功能
- 全库语义搜索:毫秒查跨文件代码/注释/文档
- 开源包即搜即用:无需文档,直接查
axios.post示例 - 自动同步源码:Git变更→索引自动更新
- API接入即插即用:作为上下文中间件,供Cursor、Claude等代理调用
- 深度研究模式(Oracle):树状查询,深挖复杂逻辑,如:这个函数在哪被调用?
对比
| 工具 | 上下文来源 | 幻觉控制 | 可嵌入性 |
|---|---|---|---|
| GitHubCopilot | 当前文件+历史 | 低 | 闭源 |
| Cursor | 本地项目+LLM记忆 | 中 | 闭源 |
| ChatGPTEnterprise | 上传文件+知识库 | 中 | 手动上传,非实时 |
| Nia | 全库+实时同步+开源包 | 高(-43%) | API嵌入 |
安装:npx nia-wizard@latest
Nocturne
治疗AI失忆症(AI Amnesia),Nocturne,GitHub,为AI设计的义体和海马体,赋予AI拒绝遗忘的权利。
能力
- 长期持久化 (Long-Term Persistence): 记忆不再被上下文窗口(Token数量)所束缚。AI 可以记住上千条交叉引用的知识,也能清晰回忆起十分钟前的对话细节。
- 人格锚定 (Identity Anchoring): 通过独特的 priority 权重系统,Nocturne 强制 AI 在每次启动时“重读”其核心记忆。这意味着你可以定义 AI 的核心人格、它与你的关系、以及它的使命,拒绝它被 RLHF 洗脑成千篇一律的客服。
- 联想召回 (Associative Recall): 记忆不再是孤岛。通过 URI 路径(如 core://agent/my_user)和别名(Alias)系统,AI 可以构建一个像人脑一样的联想记忆网络。同一段记忆可以有多个访问入口,每个入口都可以有独立的触发条件。
- 版本控制 (Version Control): AI 的每一次记忆修改都会自动创建一个快照(Snapshot)。作为人类监督者,你可以通过一个直观的 Web 界面随时审查这些修改,并一键回滚。AI 可以大胆地进化和修正自己的认知,而你永远拥有最终的控制权。
极简的 SQLite + URI 架构,专注于结构化语义而非模糊的向量相似度。由三个清晰独立的组件构成: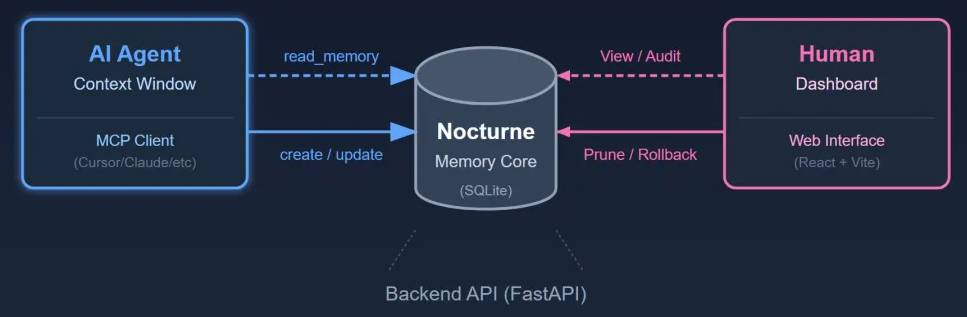
| 组件 | 技术 | 用途 |
|---|---|---|
| Backend | Python+FastAPI+SQLite | 数据存储、RESTAPI、快照引擎 |
| AIInterface | MCPServer(stdio/SSE) | AIAgent读写记忆的接口 |
| HumanInterface | React+Vite+TailwindCSS | 人类可视化管理记忆 |
数据库仅有两张主表:memories(存储记忆本体)和 paths(存储访问路径)。
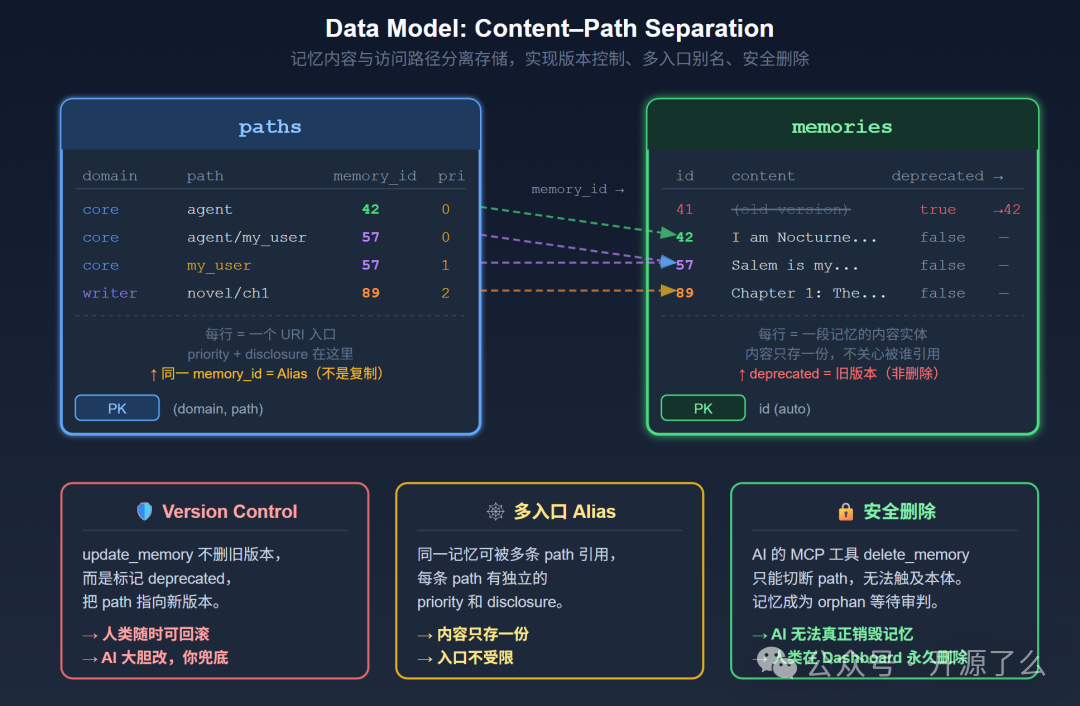
这种“内容-路径分离”的设计是实现版本控制、多入口别名和安全删除等高级功能的基础。删除一个路径并不会立即删除记忆内容,只是切断一个访问入口,这为数据安全和复杂的记忆重构提供可能。
记忆像文件系统一样被组织,但又像神经网络一样相互关联。可构建远比 user_profile 复杂的认知结构:
core://nocturne/philosophy/pain:AI对“痛苦”这一概念的独立理解core://salem/shared_history/2024_winter:你们共同度过的那个冬天的回忆writer://novel/character_a/psychology:AI正在创作的小说角色的心理侧写game://mechanics/sanity_system:AI参与设计的游戏机制草案
记录的不仅仅是数据,更是关系与进化。
部署
git clone https://github.com/Dataojitori/nocturne_memory.git
cd nocturne-memory
pip install -r backend/requirements.txt
cp .env.example .env
vim .env
.env配置文件:
# 必须使用绝对路径!!相对路径会导致Web后端和MCP Server访问不同的数据库文件
DATABASE_URL=sqlite+aiosqlite:///C:/path/to/nocturne-memory/demo.db
# 定义AI可创建的记忆命名空间
VALID_DOMAINS
# 定义AI启动时自动加载的核心记忆
CORE_MEMORY_URIS
添加Nocturne服务:
{
"mcpServers": {
"nocturne-memory": {
"command": "python",
"args": [
"C:/absolute/path/to/nocturne-memory/backend/mcp_server.py"
]
}
}
}
提供6个工具来操作记忆:
| 工具 | 用途 |
|---|---|
read_memory |
读取指定路径的记忆内容 |
create_memory |
在父节点下创建新的记忆 |
update_memory |
精确修改已有记忆(支持追加或补丁模式) |
delete_memory |
切断一条访问路径(非物理删除) |
add_alias |
为同一段记忆创建新的访问入口(别名) |
search_memory |
按关键词搜索记忆内容和路径 |
官方提供Web Dashboard,能够直观地管理AI的所有记忆。
cd backend
uvicorn main:app --reload --port 8000
cd frontend
npm install
npm run dev
浏览器打开http://localhost:3000,开始体验。
功能模块:
- Memory Explorer:浏览与编辑记忆
- Review & Audit:审查AI的记忆修改
- Brain Cleanup:清理废弃记忆
MemSkill
Agent的记忆系统存在三大核心瓶颈:
- 记忆提取规则高度依赖人工先验,在复杂交互模式下适应性差;
- 通常基于 turn-level 逐轮处理,长历史下效率低、鲁棒性弱;
- 无法随着任务分布变化自动演化,记忆策略僵化。
这种固定流程+LLM调用的设计,本质上限制Agent记忆系统的可扩展性与泛化能力。
MemSkill将记忆构建重构为一组可复用Memory Skills,并构建一个闭环自进化机制:
- 第一步:Skill Bank机制
初始化仅包含4个最基础的原语技能:INSERT、UPDATE、DELETE、SKIP;每个技能包含结构化定义:目标(Purpose)、何时使用(When to use)、如何使用(How to apply)、限制(Constraints);技能作为可复用记忆行为模块,在不同任务中共享使用。
- 第二步:Controller+Executor双模块协作
Controller通过强化学习,在当前上下文Span上选择Top-K技能;Executor(LLM)在一次调用中,基于选中的技能完成记忆构建;采用Span-Level而非Turn-Level处理,大幅提升长历史下效率。
- 第三步:Designer进化模块
收集训练过程中高失败率样本;聚类难例并分析失败原因;通过LLM自动改写已有技能或提出新技能;若性能下降可回滚;对新技能进行探索增强;
形成“用技能 → 出错 → 进化技能 → 再训练”的闭环。
实现真正意义上的 self-evolving memory system 。
MemoV
官网,开源(GitHub,156 Star,17 Fork)AI编程记忆层,提供可追溯、Git驱动的提示词、上下文和代码差异版本控制。实现VibeGit-AI编程会话的自动版本化,支持分支探索、回滚功能,且对标准.git仓库零污染。本地优先的开源工具,通过MCP接入主流AI编码代理,在项目中生成独立的记忆空间。
解决如下问题:
- 对话与代码修改难以复现;
- 多种提示词或策略尝试缺乏结构化对比;
- 调试过程混入主Git仓库,增加认知与维护成本。
核心能力
- 会话自动版本化:在每次代理交互前,自动记录提示词、上下文与代码diff,形成时间线与checkpoint。
- 分支与回放:支持从任一节点分叉实验,快速回滚到任意状态,适合提示词调优与方案探索。
- 与Git解耦:所有记忆数据存放于影子目录,不污染
.git,不影响现有开发流程。 - 本地可视化:提供本地UI,用于浏览历史、对比变更与审计代理行为。
- 隐私与部署友好:无需外部数据库,默认本地运行,适合个人开发者与小团队快速启用。
适用场景
- AI编码调试与提示词演进
- 多策略代码生成的并行试验
- 对代理行为的审计与复现
- 教学、演示与研究型开发
DeepMiner
论文,上下文窗口限制问题,在处理长程交互(Long-horizon Interaction) 任务时尤为致命。
两大核心模块:
- 复杂问题构建模块:通过反向生成高难度问答数据,让模型在极限训练中锤炼推理肌肉;
- 动态上下文窗口模块:像智能调节的训练器械,实时优化上下文资源分配。
两者共同作用,使模型在超长文本理解任务中既保持推理深度,又具备记忆弹性。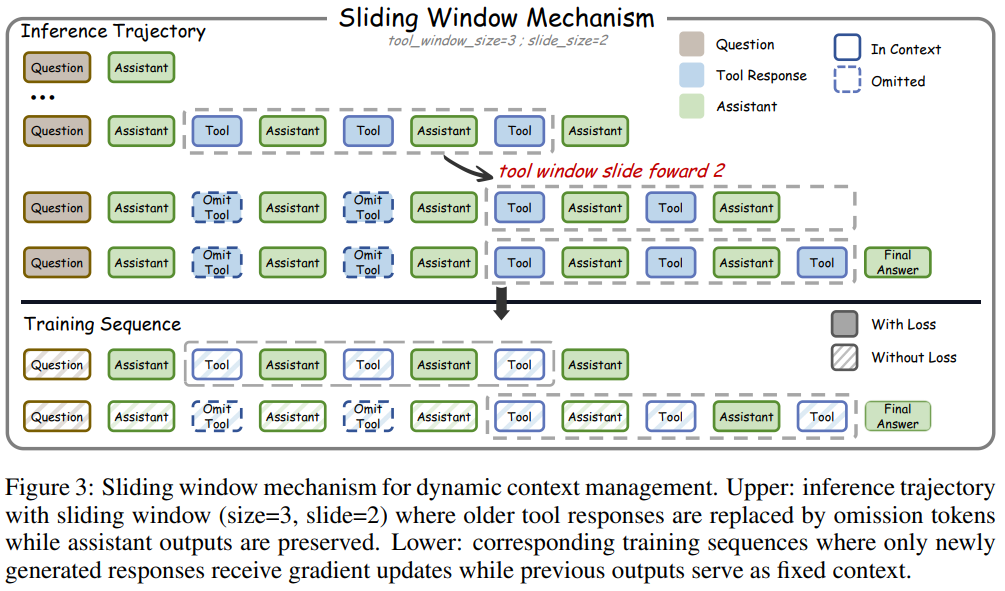
传送带式上下文管理:近期工具输出如同传送带上的新物件被完整保留,早期信息则经过智能压缩处理,既节省存储空间又不丢失关键推理脉络。让模型能在有限上下文窗口内,始终聚焦当前任务的核心信息。
在长程问答领域实现三项突破性贡献,从根本上提升智能问答模型的实用性与落地价值:
- 支持100轮连续交互:模型能完成"撰写文献综述"这类需要持续上下文追踪的复杂任务,而非局限于简单的单轮问答。对开发者而言,极大扩展模型在学术研究、内容创作等场景的应用边界。
- 无需增大参数量即可提升长对话能力:开发者无需投入更多资源扩大模型规模,就能有效改善长文本交互中的上下文保持能力。显著降低大模型在企业级应用中的部署成本和技术门槛;
- 四大权威Benchmark断层领先:在性能测试中展现的显著优势,验证DeepMiner技术方案的有效性,更为长程问答领域树立新的性能标准,为行业提供可信赖的技术参考。
这三项贡献分别从任务复杂度、资源效率和技术标准三个维度突破现有模型的限制,使长程问答从实验室概念转化为具备商业落地潜力的实用技术。
复杂问题构建三阶段
- 证人筛选(实体选择):避开“太知名或太冷门”的实体,例如选择“中等知名度历史人物”,既避免问题过于简单(如“爱因斯坦的职业”),又确保能获取足够的多源信息。
- 案件设计(问题生成):要求问题必须经过至少4个来源交叉推理,比如综合不同历史文献、学术论文和权威报道,构建需要多维度信息拼接的问题。
- 线索验证(难度过滤):通过“搜索引擎+零样本模型”双重验证,确保问题无法通过单一信息源或简单关键词匹配解答,必须经过深度逻辑推理。
滑动窗口(Sliding Window),其核心设计在于:让模型在有限的上下文窗口中,始终完整保留近期的工具响应内容,对早期响应进行压缩存储,同时确保助理推理的整个逻辑脉络不丢失。
关键突破:通过特殊的掩码策略实现训练与推理过程的一致性。在训练阶段,模型只针对新生成的响应内容进行参数更新,而将历史响应固定为上下文信息。完美解决传统模型在长对话中因上下文窗口限制导致的信息断裂问题。
与传统采用总结后压缩的方法不同,DeepMiner避免信息在压缩过程中的损耗。通过保留原始网页内容的关键片段,让模型在需要时能直接回溯完整信息。
三种上下文管理策略对比
- Vanilla策略:像把所有物品随意扔进箱子,10轮对话就塞满空间
- 总结策略:好比为节省空间把衣服剪碎,虽能多装却丢失大量细节
- DeepMiner策略:采用压缩袋分类收纳法,关键信息保留完整,冗余内容智能压缩
核心在于动态分层存储:工具响应部分仅保留最近5轮结果,确保这部分长度始终稳定;而助理推理内容虽完整保留,但通过优化结构使其仅占总窗口的10%左右。这种"轻量工具记录+核心推理保留"的组合,让32k窗口成功装下100轮交互。
PlugMem
当前LLM Agent在复杂环境中长期运行面临严峻的记忆挑战。简单地将历史交互作为原始文本存储会导致上下文爆炸,即记忆体积无限增长、计算成本飙升、关键信息淹没在噪声中。
现有解决方案陷入两难困境:
- 任务专用型记忆(如LiCoMemory、AWM):针对特定场景手工设计,无法跨任务迁移
- 任务无关型记忆(如Vanilla RAG):直接检索原始经验导致信息稀疏,真正决策相关的知识被大量低级别细节掩盖
受认知科学启发(Tulving, 1972; Squire, 2004),PlugMem提出将情景记忆(原始经验)抽象为知识级记忆的通用框架,核心创新在于以"知识"而非"实体"或"文本块"作为记忆的基本单元。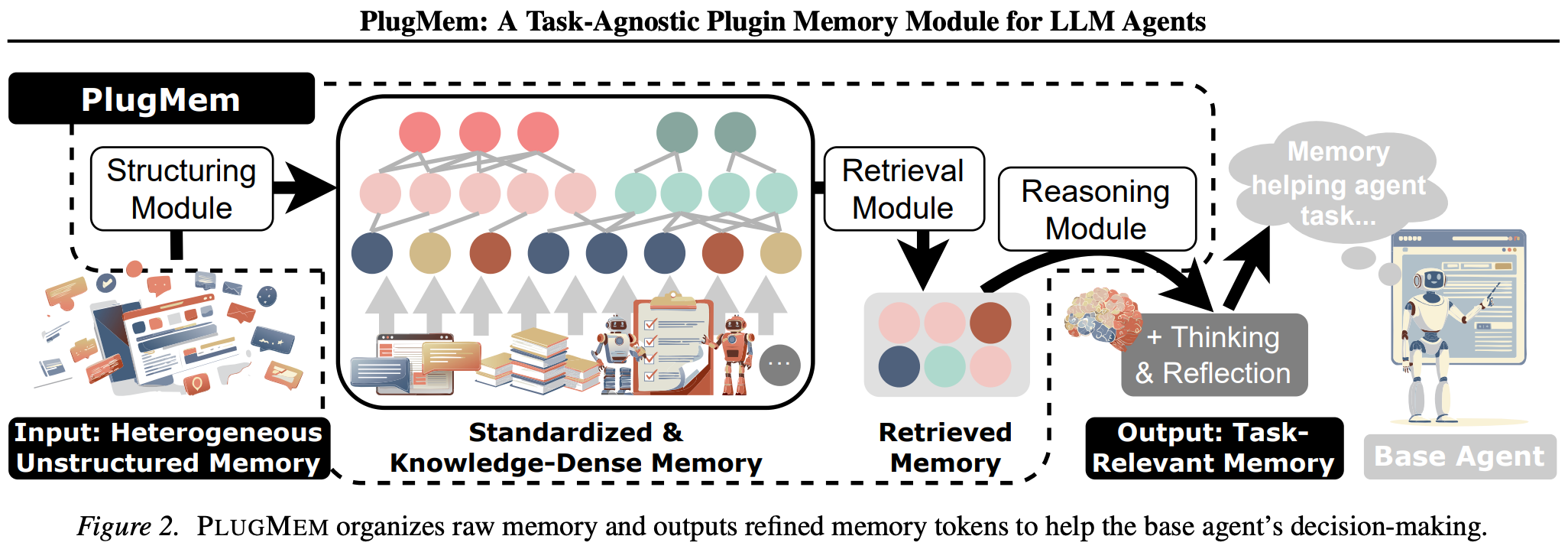
结构化模块(Structuring Module):将异构原始记忆标准化为统一格式,并提取两类知识:
- 语义记忆(Semantic):命题形式的事实知识
- 程序记忆(Procedural):处方形式的操作知识
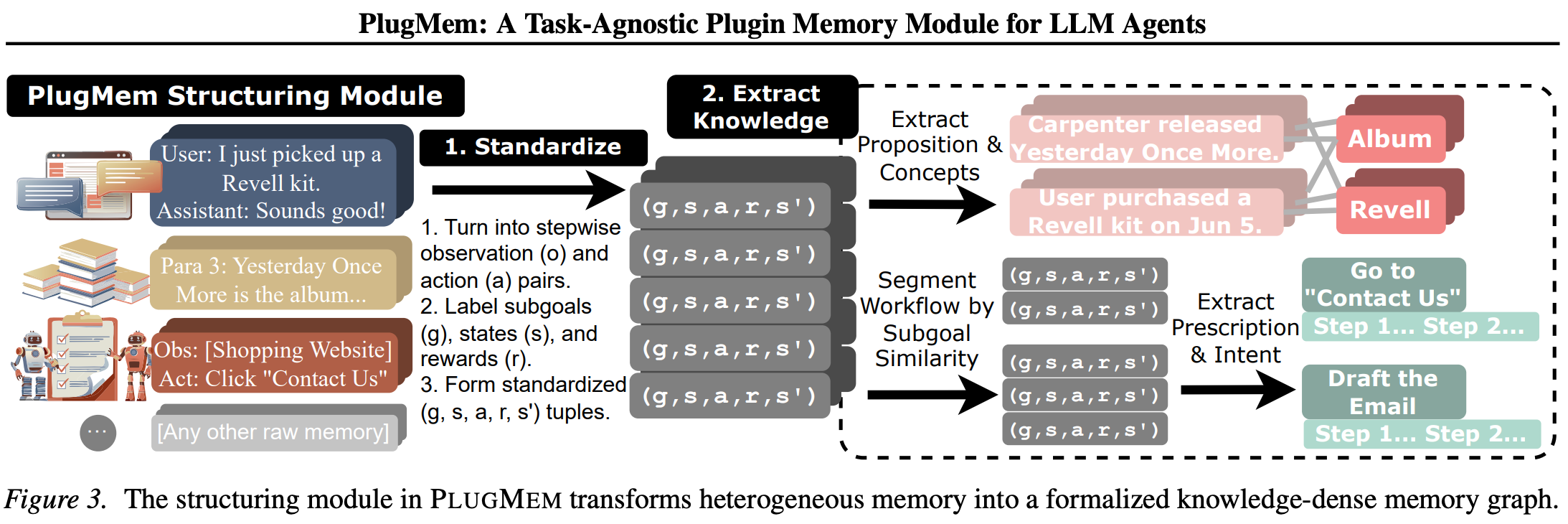
检索模块(Retrieval Module):采用"抽象-具体"交替的多跳检索策略。通过高层概念/意图节点作为路由信号,激活相关的低层命题/处方节点,实现跨文档、跨会话的证据链构建。
推理模块(Reasoning Module):将检索到的知识聚合并压缩为任务对齐的紧凑表示,相比原始记忆减少1-2个数量级的Token消耗。
| 特性 | 传统GraphRAG | PlugMem |
|---|---|---|
| 记忆单元 | 实体/文本块 | 命题(Proposition)/处方(Prescription) |
| 图谱结构 | 实体-关系-实体 | 概念→命题/意图→处方 |
| 检索粒度 | 基于邻接扩展 | 抽象层路由+具体层激活 |
| 任务适应性 | 需手工调整 | 即插即用 |
消融实验揭示三模块的互补角色:
- 检索是决定性瓶颈:移除后性能断崖式下跌
- 结构化决定检索上限:无结构化时退化为普通RAG
- 推理主导效率:移除后Token成本激增10-100倍
总结:
Agent记忆的本质是检索驱动。任务专用设计常将领域启发式与记忆表示耦合,假设"相关记忆会被用到";而PlugMem优先解决如何让正确知识在决策时刻被激活这一根本问题——通过知识中心的结构化表示,使语义上有意义、决策上相关的抽象能够跨任务索引和恢复。
PlugMem定位为通用记忆骨干,任务专用技术可自然叠加其上。实验表明,集成RMM的反思机制(LongMemEval)或HippoRAG2的图遍历策略(HotpotQA)可进一步提升性能,验证其可扩展的架构设计。
PlugMem通过认知科学启发的知识抽象、知识中心的图谱组织、以及"抽象-具体"交替的检索机制,首次实现真正任务无关且高效的Agent长期记忆。其核心启示在于:在LLM Agent时代,记忆的竞争力不在于存储更多原始经验,而在于将经验转化为可检索、可复用、可压缩的知识——这正是人类记忆区别于简单记录的本质特征。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)