ARPO:GUI智能体的强化学习新突破
2026.03.06,Eric Huang
论文链接:ARPO: End-to-End Policy Optimization for GUI Agents with Experience Replay
原文摘要
将大型语言模型(LLM)训练为用于控制图形用户界面(GUI)的交互式智能体,面临着一项独特的挑战:如何利用来自复杂环境的多模态反馈来优化长时程动作序列。尽管近期的研究已推动了多轮强化学习(RL)在 LLM 推理和工具使用能力方面的进步,但由于奖励稀疏、反馈延迟和部署成本高等问题,其在基于 GUI 的智能体中的应用仍相对欠缺。本文研究了基于视觉语言的 GUI 智能体的端到端策略优化,旨在提升其在复杂、长时程计算机任务上的性能。我们提出了一种端到端的强化学习方法——智能体回放策略优化(ARPO),该方法在组相对策略优化(GRPO)的基础上增加了一个回放缓冲区,以便在训练迭代中重用成功经验。为了进一步稳定训练过程,我们提出了一种任务选择策略,该策略基于基线智能体的性能筛选任务,使智能体能够专注于从信息丰富的交互中学习。此外,我们将 ARPO 与离线偏好优化方法进行比较,突显了基于策略的方法在 GUI 环境中的优势。在 OSWorld 基准测试上的实验表明,ARPO 取得了具有竞争力的结果,为通过强化学习训练的基于 LLM 的 GUI 智能体建立了一个新的性能基准。我们的研究结果强调了强化学习在训练能够处理复杂真实世界 UI 交互的多轮、视觉语言 GUI 智能体方面的有效性。
实验部分分析
4.1 Implementation Details
该工作基于 UI-TARS-1.5 7B 模型进行训练,并使用 VERL 完成强化学习训练流程。整体实验采用典型的 LLM-as-policy 的在线 RL 设置:模型通过与 GUI 环境交互生成轨迹,并根据环境奖励进行策略优化。
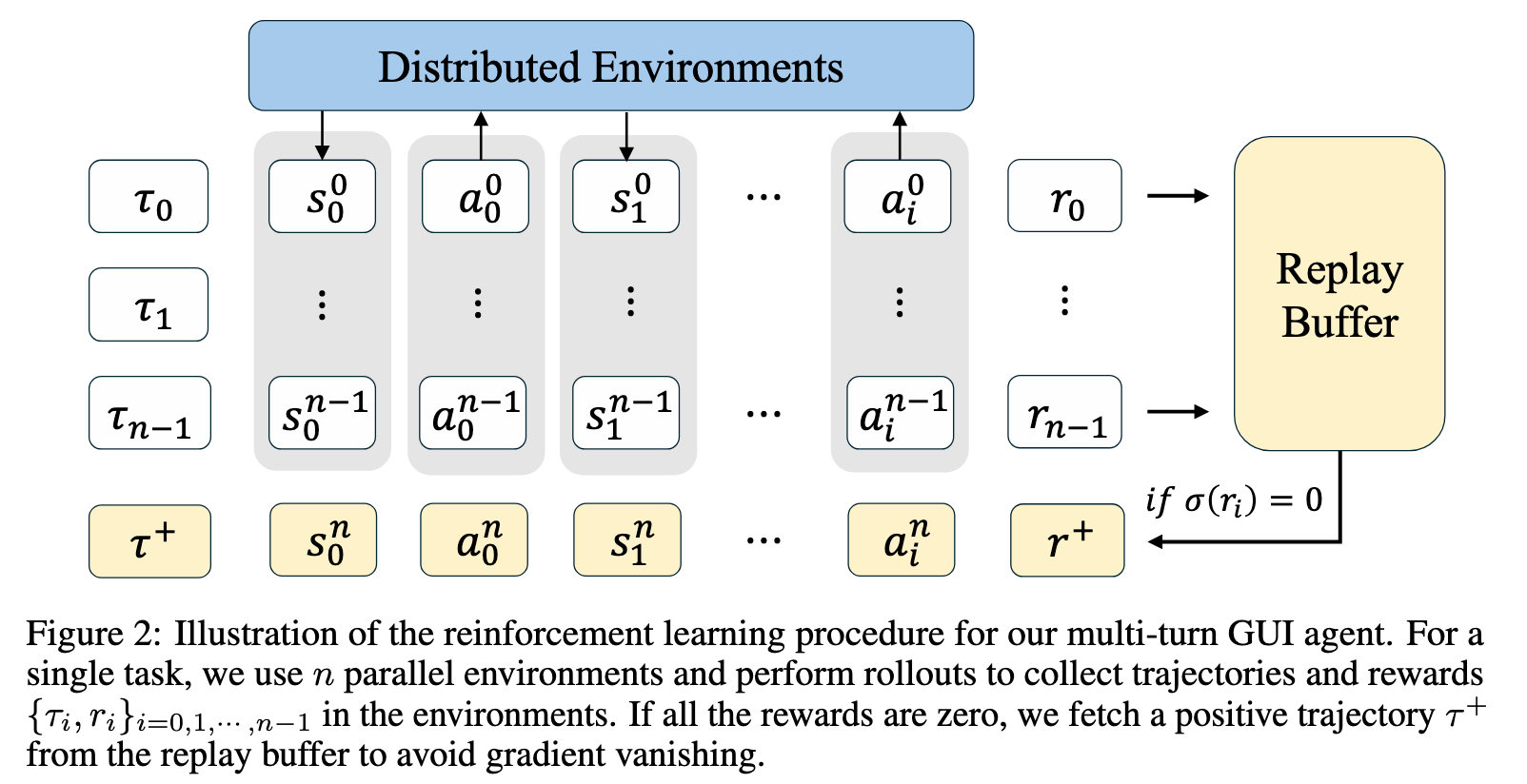
在轨迹生成阶段,作者构建了一个 大规模并行环境的 rollout 系统。具体来说,训练过程中同时运行 256 个并行虚拟环境,并且 每个任务采样 8 条 rollout 轨迹。这种设计显著提高了 RL 训练的数据吞吐量,使模型能够在较短时间内获得足够多的交互经验。训练任务来自 OSWorld benchmark,每轮训练从中采样 128 个任务。整个训练持续 15 个 epoch。
为了鼓励探索,rollout 采样时设置 temperature = 1.0。每次 rollout 的 batch size 为 32。策略优化阶段使用 AdamW 优化器,学习率为 1×10⁻⁶,并采用 per-device mini-batch size = 8 的训练配置。同时,为了在有限 GPU 显存条件下维持有效的 batch size,训练中使用 gradient accumulation = 4。这一配置意味着一次策略更新实际整合了多个小 batch 的梯度,从而保持训练稳定性。
在策略更新机制上,该方法沿用了 DAPO 中的 clipping 策略。具体而言,策略更新的 clipping 参数被设置为 ε_low = 0.2 和 ε_high = 0.3,用于在策略优化过程中平衡 exploration 与 exploitation。在评估阶段,采样温度降低至 0.6,以获得更加稳定和确定性的策略行为。
值得注意的是,作者在训练目标中 移除了 KL divergence loss,从而不再需要 reference model。这一点与传统 RLHF 或 PPO-RLHF 方法不同:传统方法通常依赖 KL 正则项限制策略偏离 reference policy,而 ARPO 选择直接进行策略优化,使训练流程更加简化。
Datasets and Benchmarks
实验在 OSWorld benchmark 上进行评测。OSWorld 是一个近期提出的 真实计算机环境评测基准,用于评估多模态智能体在 开放式 GUI 任务中的能力。该 benchmark 共包含 369 个任务,覆盖多个现实应用领域,包括:
- 办公软件操作
- Web 浏览
- 系统管理
- 多应用协作流程
每个任务都在 真实应用程序的虚拟机环境中执行。评估方式采用 execution-based scripts,即通过脚本检查智能体是否成功完成任务。OSWorld 支持 完整 GUI 交互,包括鼠标点击与键盘输入,因此能够较为真实地评估 多轮视觉-行动(vision-action)智能体在桌面环境中的能力。
Evaluation Metrics
评估采用 OSWorld 官方定义的 rule-based evaluation protocol。在该评测框架下,每一条 agent trajectory 都会从环境中获得一个 0 到 1 的标量 reward,用于衡量任务完成程度。
作者指出,部分先前工作在 rollout 达到最大步数时,会将最后一个动作替换为 FAIL action,以避免评测过程中的不稳定行为(例如无限循环)。然而这种做法会在 真实不可完成任务(impossible tasks)中人为改变奖励结构,从而影响评测的真实性。
因此,为了更准确地衡量 RL agent 的真实能力,作者提出一个更加严格的评测协议 OSWorld Hard。在该协议中,禁止进行 final action replacement,即不允许用 FAIL 动作替换最后一步行为,从而避免对真实奖励信号的干扰。
Implementation Insights(补充理解)
从 RL 系统设计角度看,这一实验配置体现了几个关键工程思路:
首先,大规模并行环境(256 envs)是 GUI agent 训练的核心。GUI任务通常 trajectory 长且 reward 稀疏,如果 rollout 数量不足,策略优化将难以收敛。因此高并行环境是保证 sample efficiency 的关键。
其次,temperature=1.0 的 rollout体现了典型的 RL exploration 策略:在训练阶段鼓励探索,而在 evaluation 阶段降低 temperature(0.6)以获得更稳定策略。
最后,移除 KL loss意味着该方法不再依赖传统 RLHF 的 reference policy 约束,而是更接近 纯 policy optimization 的 RL setting。这使得训练框架更加简单,同时也与论文核心思想——end-to-end policy optimization for GUI agents——保持一致。
4.2 Experimental Results
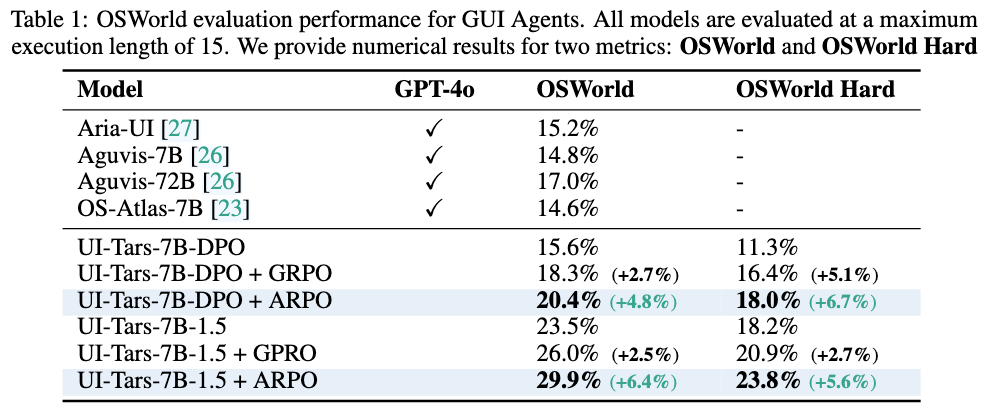
作者在 OSWorld benchmark 上评估 ARPO,并与多种近期的 GUI agent 方法进行对比。实验结果表明,ARPO 在 所有评估设置下均取得最高成功率。
具体而言,在 UI-Tars-1.5 7B 基础模型上应用 ARPO 后:
- 在 标准 OSWorld 设置下,任务成功率达到 29.9%
- 在 更严格的 OSWorld Hard 设置下,成功率为 23.8%
相比原始 UI-Tars-1.5 模型,这分别带来了 6.4% 和 5.6% 的绝对提升。
这些结果表明,将 GRPO 强化学习优化 与 结构化经验重放(experience replay)结合,可以显著提升 GUI agent 在 多轮交互决策任务中的能力。
此外,该方法在 不同基础模型版本上也表现出一致收益。例如,在 UI-Tars-7B-DPO 模型上,成功率从 15.6% 提升至 20.4%。这说明 ARPO 并不是针对某个特定模型的优化,而是一种 具有较好泛化性的 RL training strategy。
所有实验均设置 trajectory 最大步数为 15。这意味着 agent 必须在较短的交互序列内完成任务,因此策略优化的效率与稳定性尤为关键。
4.3 Ablation Study
Impact of the Replay Buffer
为了分析经验回放机制的作用,作者对比了 有 replay buffer 与 无 replay buffer 的训练过程。
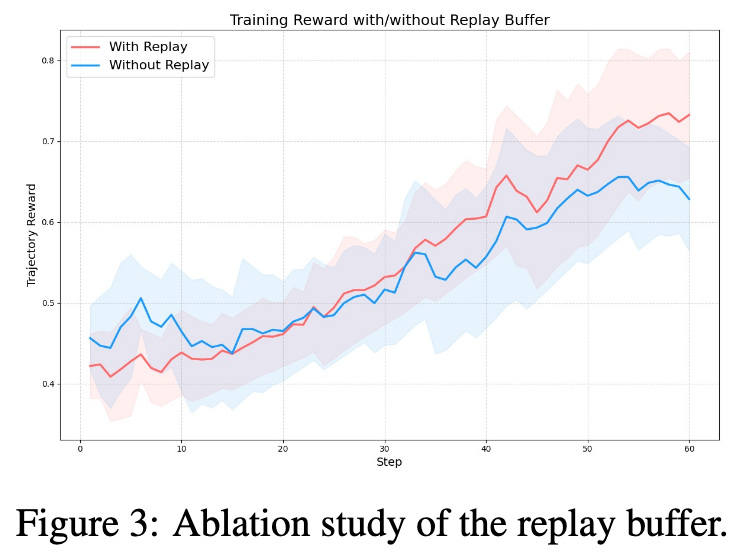
实验结果显示,使用 replay buffer 的模型在 训练约 Step 30 时开始超越 baseline,并在后续训练过程中持续保持优势。这一结果说明 replay buffer 能够提供稳定且持续的学习信号,而不仅仅是在训练早期产生短期收益。
性能提升的关键原因在于:replay buffer 能够保留早期训练阶段产生的高奖励轨迹。
在 GUI agent 训练中,由于环境奖励 稀疏且不稳定,成功轨迹往往非常少见。如果仅依赖当前策略生成的数据,模型可能很难再次遇到类似成功路径。Replay buffer 通过保存这些高价值轨迹,使其能够在后续训练中反复被利用,从而持续强化正确行为模式。
此外,replay buffer 还能在 GRPO 的 group sampling 过程中维持 reward diversity。这保证了 advantage 计算不会退化为零,从而维持稳定的策略梯度信号。
Training Efficiency and Policy Quality
从训练结果来看,使用 replay buffer 的模型在训练结束时获得了更高的平均 trajectory reward:
- ARPO + replay buffer:0.75
- baseline(无 replay):0.65
这一差异说明 replay buffer 不仅提高了最终策略质量,还显著提升了 sample efficiency。在 稀疏奖励的 GUI 环境中,这一点尤为重要,因为有效交互样本本身就十分稀缺。
Downstream Task Performance
Replay buffer 的优势不仅体现在 reward 曲线,还体现在 真实任务成功率上。
在 in-domain GUI tasks 上:
- GRPO baseline success rate:68.8%
- ARPO success rate:81.25%
带来了 12.5% 的绝对提升。
这一结果表明 replay buffer 不只是加快训练收敛,还能显著提升 策略泛化能力和实际任务表现。
* Key Experimental Insight
从实验设计可以看出,这篇论文真正想证明的核心结论是:
在稀疏奖励、多步决策的 GUI 环境中,简单的在线 RL(如 GRPO)往往难以稳定学习,而引入 experience replay 可以显著提升样本效率与策略性能。
其背后的机制在于:
- 成功轨迹极其稀缺
- Replay buffer 允许重复利用这些成功经验
- 从而持续强化正确决策路径
因此,ARPO 的核心思想可以理解为:
将传统 RL 中的 experience replay 引入到 LLM-based GUI agent 的策略优化过程中,从而缓解 sparse reward 与长轨迹带来的训练困难。
示意图如下:
GRPO
↓
+ Replay Buffer
↓
ARPO
4.4 Generalization Analysis
Does RL Training Generalize to OOD GUI Tasks?
为了评估强化学习训练是否能够提升 GUI agent 的泛化能力,作者分别在 in-domain tasks 和 out-of-domain (OOD) tasks 上进行了评测。
具体实验设置如下:从训练任务集合中选择 32 个任务用于 RL 训练,其余 96 个任务作为 OOD 测试任务。这一设置可以评估 RL 优化后的策略是否仅仅记住训练任务,还是能够迁移到未见过的 GUI 任务。
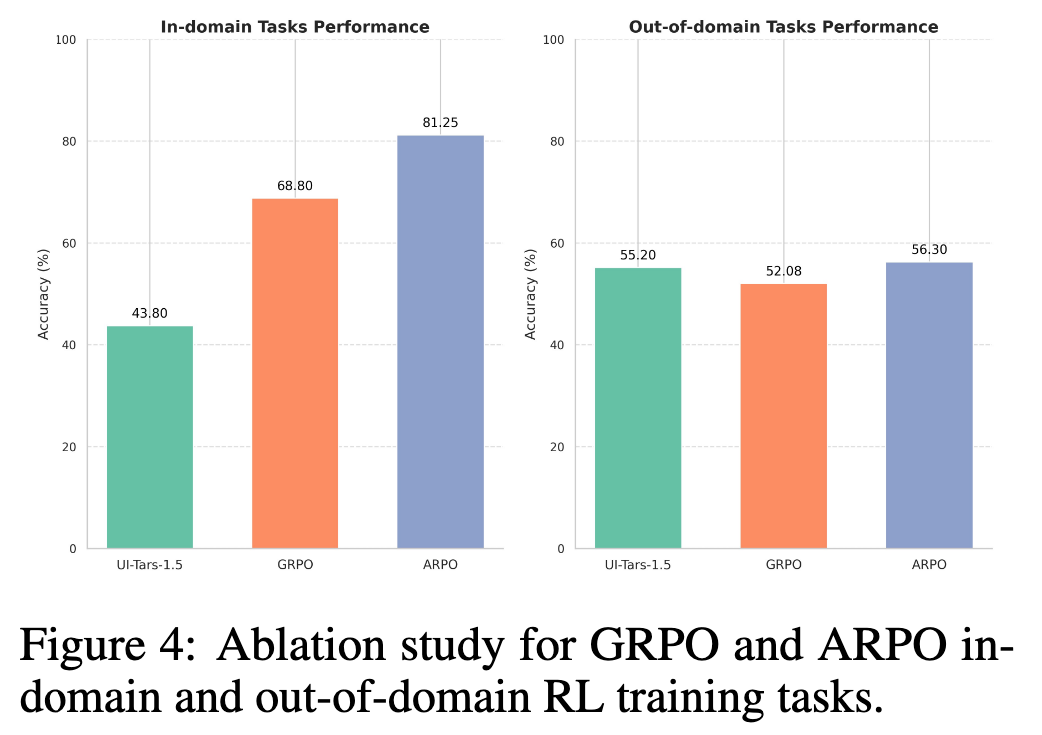
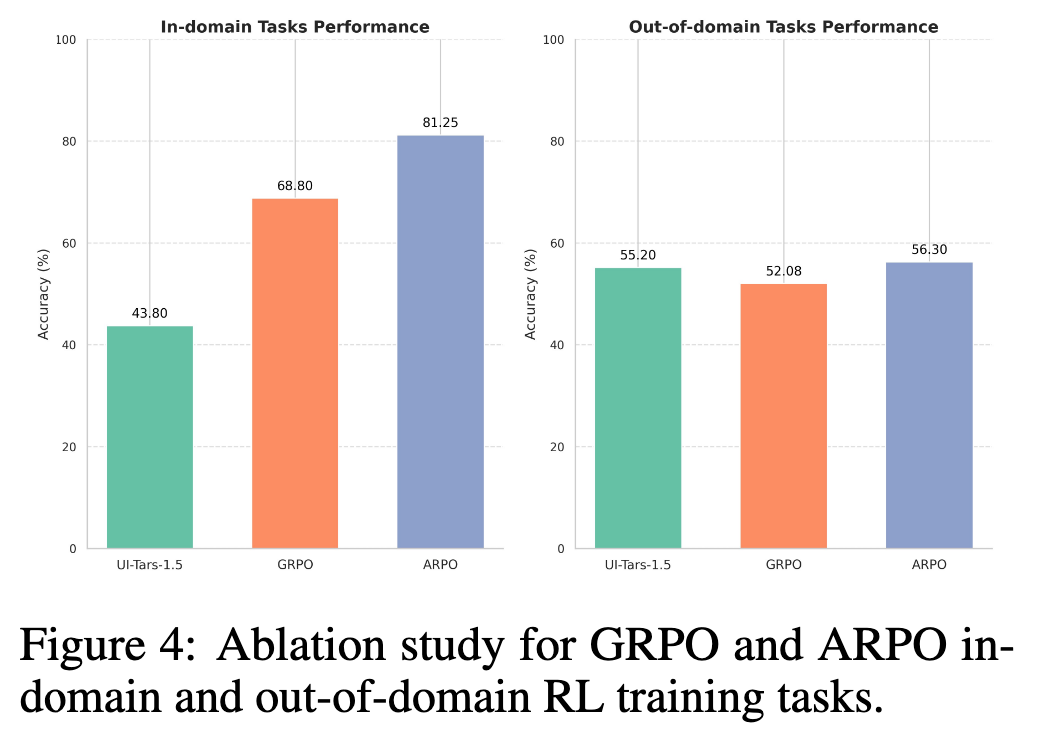
实验结果显示,强化学习训练在 in-domain 任务上带来了显著提升:
- Base UI-Tars-1.5: 43.8%
- GRPO: 68.8%
- ARPO: 81.25%
这一结果说明 RL 能够显著提高 VLM agent 在熟悉任务上的决策能力,特别是在多步 GUI 操作场景中。
然而,在 OOD 任务上,提升则相对有限:
- Base UI-Tars-1.5: 55.2%
- GRPO: 52.08%(略微下降)
- ARPO: 56.3%
值得注意的是,GRPO 在 OOD 上出现了一定程度的性能退化,而 ARPO 恢复了部分泛化能力,甚至略高于基础模型。这表明 ARPO 中的 结构化轨迹分组与 replay buffer 机制能够在一定程度上缓解 RL 训练中的过拟合问题。
总体来看,实验揭示了一个重要结论:
RL training 对 in-domain GUI task success rate 提升明显,但 强泛化能力仍依赖更丰富任务分布、更好的 reward 设计以及更大规模训练数据。
换句话说,RL 更擅长 优化已有能力,而不是 创造新的泛化能力。
4.5 Training Data Strategy
Valuable Task Selection for GRPO Training
除了 replay buffer 之外,论文还提出了一种 任务筛选策略(task selection strategy),用于提升 GRPO 训练的有效性。
核心思想是:过滤掉那些始终无法产生有效 reward 信号的任务。
在 GUI 环境中,部分任务可能由于环境限制、策略能力不足或奖励稀疏等原因,长期无法产生有效反馈。如果这些任务被持续用于 RL 训练,就会导致大量 零奖励轨迹(zero-reward trajectories),从而削弱策略优化信号。
因此作者构建了一个 128 个高价值任务的子集,并将其与完整任务集合进行对比训练。
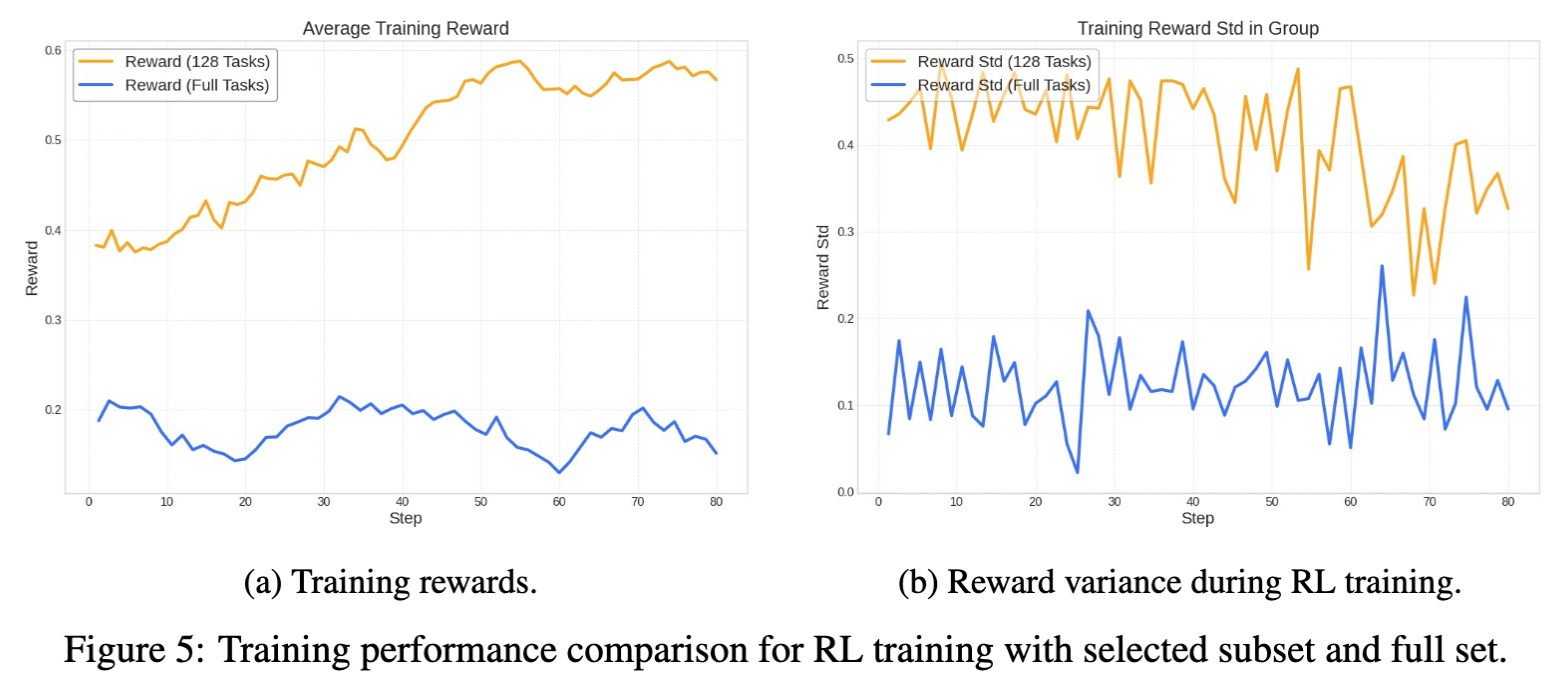
实验结果表明,在筛选后的任务子集上进行训练:
- 平均 trajectory reward 更高
- 训练收敛速度更快
- 早期训练阶段优势明显
这说明在 RL 训练中,任务质量往往比任务数量更重要。
Reward Variance Analysis
进一步分析发现,使用筛选后的任务集合训练时,GRPO group 内 reward 的标准差显著更高。
这一点对于 GRPO 算法至关重要,因为:
GRPO 依赖 group 内 reward 差异来计算 token-level advantage。如果所有轨迹的 reward 都接近(例如大多数为零),那么 advantage 也会接近零,从而导致策略梯度信号消失。
筛选任务后:
- reward variance 更高
- group 内 reward distribution 更丰富
- advantage signal 更强
而在完整任务集合上训练时,由于大量任务无法产生有效 reward,reward 分布会变得更加平坦,从而降低策略优化效果。
图 5 的实验结果进一步验证了这一点:
在训练 reward 曲线中,使用 128 个筛选任务的模型(橙色曲线)明显高于使用 完整任务集合训练的模型(蓝色曲线)。同时,在 reward variance 曲线中,筛选任务集合也保持更高的方差水平,这直接增强了 GRPO 的训练信号。
* Key Insight from Section 4.4–4.5
这两节实验其实揭示了 GUI agent RL training 的两个核心规律:
1️⃣ RL 提升更多来自 策略优化,而非 泛化学习
RL 可以显著提高 agent 在 seen tasks 上的 success rate,但在 unseen tasks 上提升有限。因此 RL 更像是一种 capability refinement,而不是 capability discovery。
2️⃣ Reward Signal Quality 决定 RL Training Effectiveness
对于 GRPO 这类 group-based policy optimization 方法来说:
Reward Diversity
↓
Advantage Signal
↓
Policy Gradient Quality
↓
Training Effectiveness
如果 reward variance 太低,RL 训练几乎无法进行。因此:
任务筛选 → 提高 reward variance → 提升 RL 学习信号
是 GUI agent RL 训练中的一个关键工程技巧。
* Section-Level Takeaway
从整个 Section 4 的实验可以总结出 ARPO 的三个关键优势:
1️⃣ Replay Buffer
允许重复利用高质量成功轨迹,提高 sample efficiency。
2️⃣ Structured Trajectory Grouping(GRPO)
利用 group 内 reward 差异生成稳定 advantage。
3️⃣ Task Selection Strategy
通过筛选有效任务提高 reward variance,从而增强 RL 学习信号。
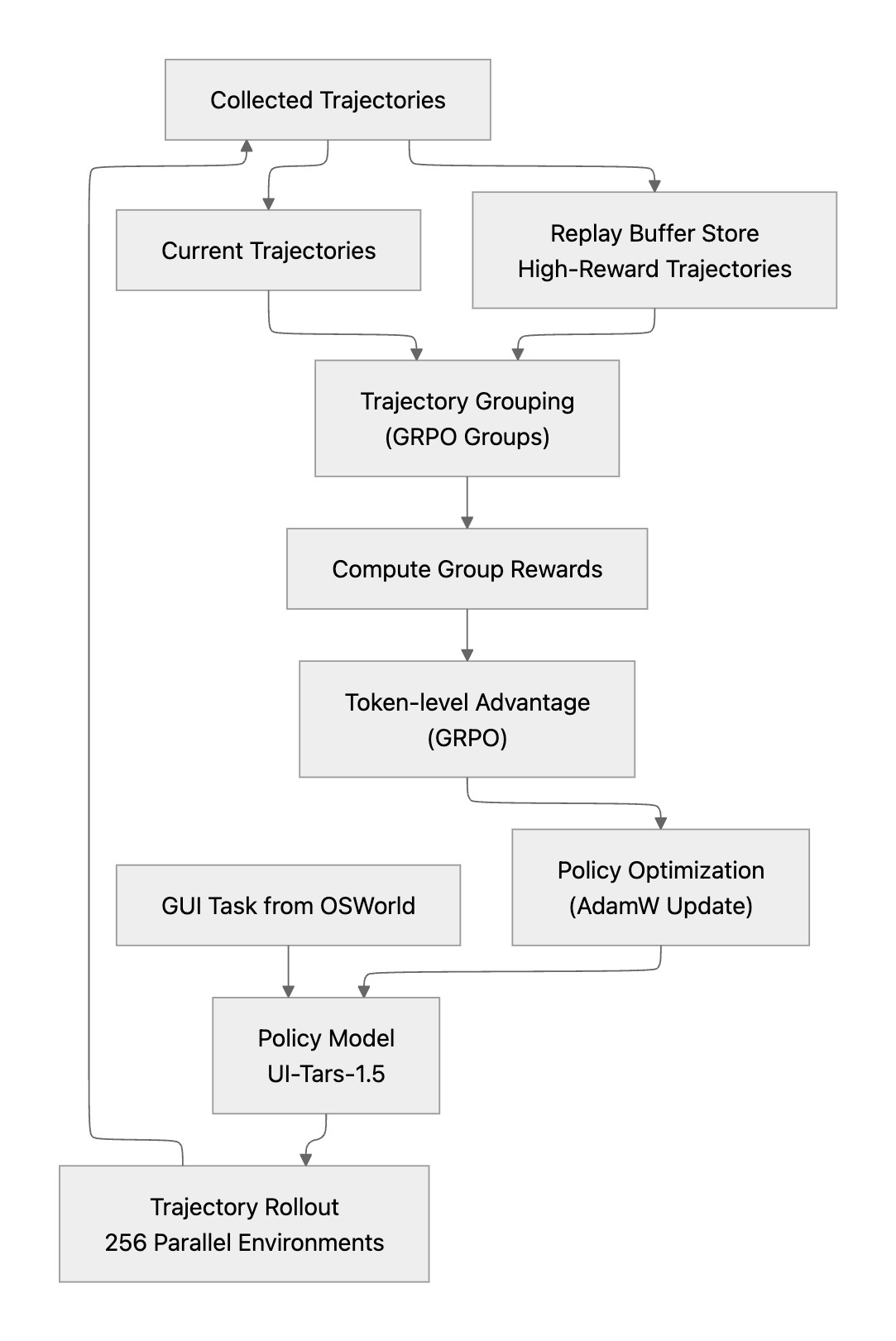
三者共同构成了 ARPO 在 GUI agent 训练中的核心优化机制。流程图如下:
4.6 Comparison with Offline Preference Optimization
为了评估 ARPO 在策略优化方面的优势,作者将其与多种 offline preference optimization 方法进行了系统对比,包括 Reject Sampling、DPO(Direct Preference Optimization)以及 KTO。为了保证比较公平,所有方法均在 相同任务集合与相同 rollout 数量下训练,这意味着不同方法的性能差异主要来源于 训练目标函数与优化方式,而不是数据规模差异。
在具体实现上,不同方法的数据构造方式有所不同。对于 Reject Sampling,训练数据仅保留 reward 为正的成功轨迹,并直接用于 SFT 训练,这种方法本质上是一种简单的 reward-filtered imitation learning。在 DPO 设置中,作者从 rollout 数据中随机采样一条 正向轨迹(positive trajectory)与一条 负向轨迹(negative trajectory)构造 pairwise preference 数据,用于训练模型学习“更优轨迹”的概率分布。对于 KTO 方法,则首先将环境返回的 scalar reward 按阈值 0.5 进行二值化,将 reward 高于阈值的轨迹标记为正样本,低于阈值的标记为负样本,再进行偏好优化训练。
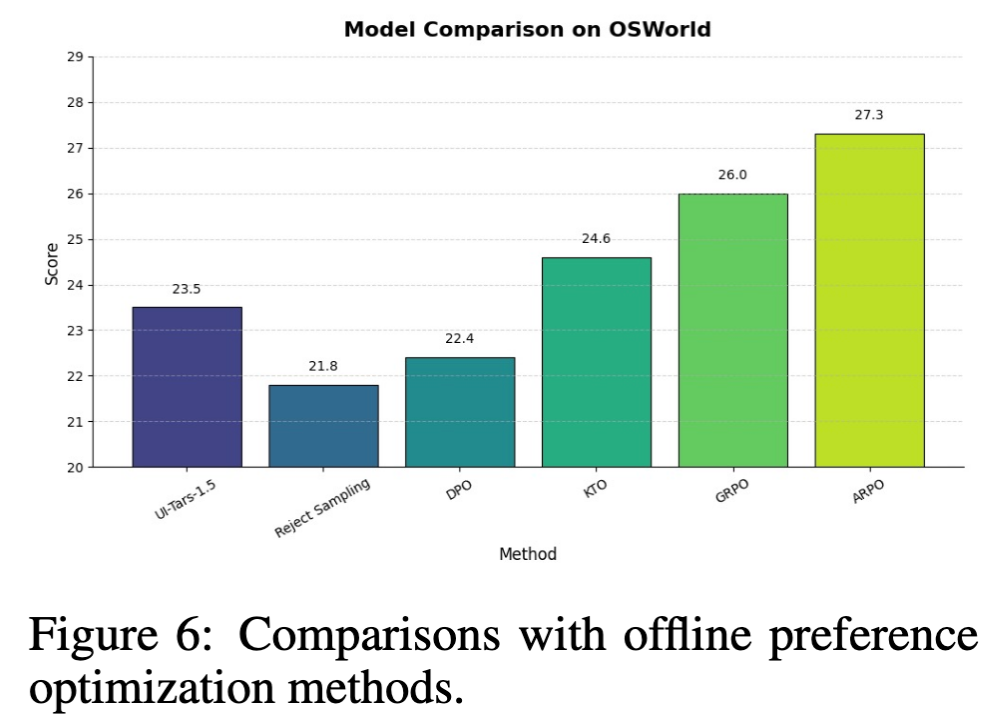
实验结果显示,ARPO 在所有方法中取得了最佳表现。在 OSWorld benchmark 上,ARPO 达到 27.3% 的成功率,略高于 GRPO 的 26.0%。两者都显著优于 offline preference optimization 方法,其中 KTO 为 24.6%,而 DPO 与 Reject Sampling 分别为 22.4% 与 21.8%。这一结果表明,在 GUI agent 的强化学习场景中,直接基于 trajectory-level reward 进行在线策略优化,比依赖离线 preference 建模更有效。
作者进一步指出,这一性能差距的关键原因在于 学习信号的质量差异。Offline preference optimization 方法依赖于 pairwise comparison 或 binary preference labels,这会在一定程度上压缩原始 reward 信号中的信息量。例如,在 DPO 或 KTO 中,连续 reward 被离散化为偏好关系或二元标签,从而丢失了 reward 的细粒度差异。相比之下,GRPO 与 ARPO 直接使用 rule-based scalar rewards 进行策略梯度优化,使模型能够充分利用 reward 的强弱信息来调整策略。
在 ARPO 框架中,这一优势被进一步放大,因为 experience replay 机制允许模型反复利用高质量成功轨迹,从而持续强化正确行为模式。特别是在 GUI agent 训练这种 稀疏奖励环境(sparse-reward environments)中,成功轨迹往往极为稀缺。Replay buffer 能够保存这些关键经验并在后续训练中重复利用,从而显著提升 样本效率与训练稳定性。因此,相比仅依赖当前 rollout 数据的 GRPO,ARPO 能够在相同训练预算下获得更强的策略学习效果。
从更宏观的角度来看,这一实验揭示了 GUI agent 训练中的一个重要规律:offline preference optimization 更适合静态文本任务,而在需要真实环境交互的 agent 场景中,在线 RL 仍然提供更强的学习信号。Preference learning 在构建安全或对齐模型时具有优势,但在 GUI 操作这种 多步决策问题(long-horizon decision making)中,直接优化环境奖励能够更有效地引导策略学习。
综上,实验结果表明 ARPO 在策略优化效率与样本利用率方面均优于离线偏好优化方法。通过结合 GRPO 的在线策略优化能力与 experience replay 的成功轨迹复用机制,ARPO 能够在稀疏奖励 GUI 环境中提供更稳定、更高效的训练信号,从而显著提升 GUI agent 的整体性能。
4.7 Rollout Efficiency Analysis
为了评估 RL 训练在真实 GUI 环境中的可扩展性,作者分析了 并行环境数量(parallel environments)对 rollout 效率的影响。在 GUI agent 的强化学习训练中,环境交互往往是最主要的时间瓶颈,因为每个动作都需要真实地执行 GUI 操作并等待系统响应。因此,提升 rollout 吞吐量是使 RL 训练在实际桌面环境中可行的关键工程问题。
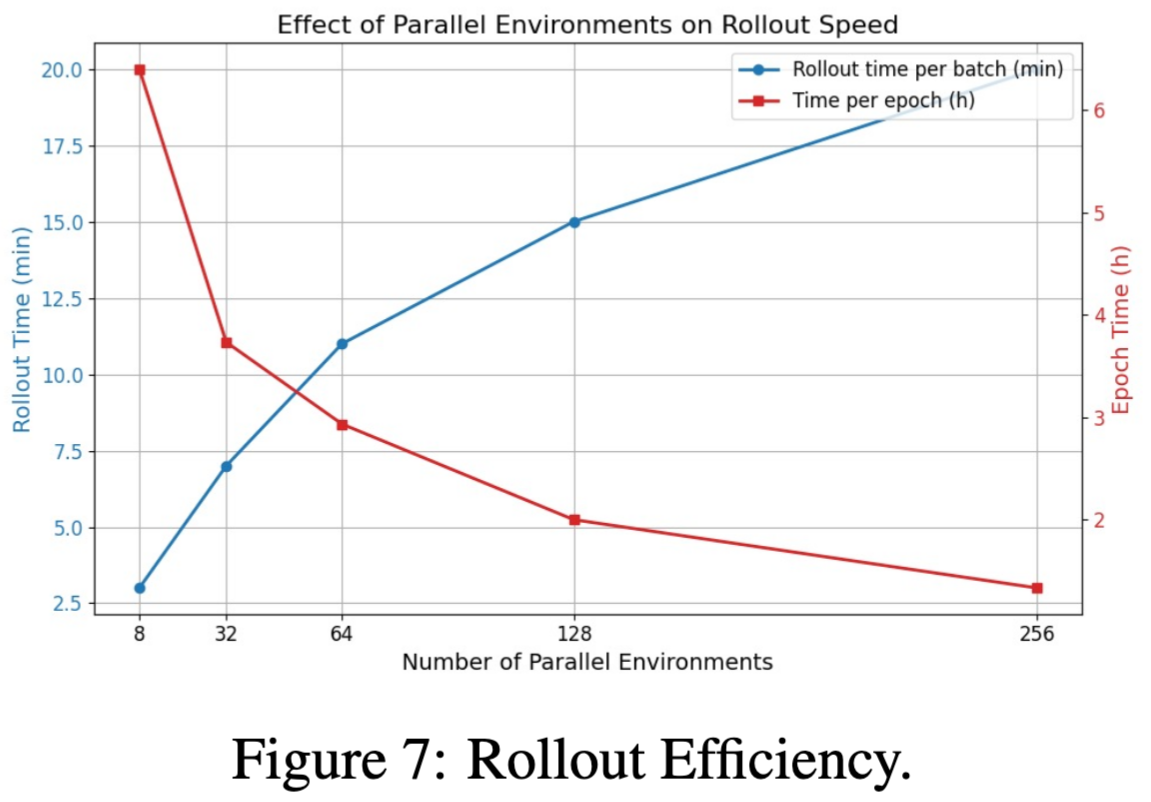
实验结果表明,增加并行环境数量可以显著提高训练效率。随着并行环境数量增加,单个 batch 的 rollout 时间确实会上升。例如,当环境数量从 8 增加到 256 时,每个 batch 的 rollout 时间从 约 3 分钟增加到 19 分钟。然而,由于每个 batch 可以同时收集更多轨迹,总体数据采样效率显著提升,从而使 每个 epoch 的总时间大幅下降。具体而言,随着并行环境规模扩大,总训练时间从 超过 6 小时缩短到约 1.2 小时。这一结果说明,在 GUI agent 的 RL 训练中,系统级并行化能够显著提高整体训练吞吐量。
这种加速主要来源于两个关键因素。首先,更大的 batch size 能够提高 VLLM 推理阶段的 GPU 利用率。当更多环境同时请求策略模型进行推理时,GPU 能够以更高吞吐量执行批量 inference,从而降低单位轨迹的计算成本。其次,在 GUI 环境中,系统层面的操作延迟(例如应用启动、窗口切换、页面加载等)往往占据较大时间比例。当多个环境并行运行时,这些 OS 级延迟可以被自然重叠,从而减少整体等待时间。换言之,并行环境不仅提高了模型推理效率,还有效掩盖了 GUI 环境中的 I/O 延迟。
实验结果表明,当并行环境规模扩展到 256 个实例时,可以实现 高吞吐量 rollout 采样,从而使基于真实桌面环境的 RL 训练变得更加实际可行。这一点对于 GUI agent 研究尤为重要,因为相比传统模拟环境,真实 GUI 环境具有更高的交互复杂度和系统开销。通过大规模并行化策略,ARPO 能够在保证环境真实性的前提下维持可接受的训练效率。
从系统设计角度来看,这一实验揭示了 GUI agent RL 训练的一个关键工程原则:在真实环境交互任务中,扩展 rollout 并行度往往比单次 rollout 速度更重要。虽然单个 batch 的采样时间会随着并行规模扩大而增加,但总体训练效率却可以通过高并发采样得到显著提升。这种设计思想与现代大规模 RL 系统中的 environment-level parallelism 一致,是实现高吞吐量 agent 训练的重要基础。
4.8 Qualitative Analysis: Self-Correction Behavior in GUI Agent
为了更直观地展示 ARPO 对 GUI agent 行为策略的影响,作者对 agent 的交互轨迹进行了定性分析。图 8 展示了一个典型示例,在该示例中,经过 ARPO 训练的 agent 展现出了明显的 自我纠错(self-correction)能力。这一行为模式在 GUI 操作任务中尤为重要,因为真实环境中的多步交互往往不可避免地包含误操作,而一个高质量的 agent 不仅需要完成任务,还需要能够识别并修正自己的错误。

在该任务中,agent 的目标是在文本 “H2O” 中将数字 2 转换为 下标(subscript)。为完成这一操作,agent 首先通过鼠标拖拽选中数字 2,随后尝试点击工具栏中的下标按钮。然而在执行过程中,agent 误点击了上标(superscript)按钮,导致数字 2 被错误地转换为上标格式。此时,ARPO 训练后的 agent 并没有继续沿着错误状态执行后续操作,而是通过观察当前 GUI 状态意识到操作结果与目标不符,并主动采取 Ctrl-Z 撤销(undo)操作,将界面恢复到之前的状态,然后重新尝试正确的操作步骤。
这一轨迹展示了 ARPO 训练所带来的一个重要行为特征:agent 不仅能够执行规划好的操作序列,还能够在执行过程中根据环境反馈动态调整策略。这种能力体现为一种 闭环决策过程(closed-loop decision making),其中每一步动作都会根据当前界面状态进行重新评估,而不是机械地执行预先生成的固定动作序列。
实验结果表明,ARPO 显著提高了 agent 在该类任务中的成功率。对于这一具体任务,ARPO 训练前后的成功率从 25% 提升至 62.5%。这一提升说明,通过强化学习优化后的策略不仅能够更准确地执行操作,还能够在复杂交互场景中展现出更强的鲁棒性。
从更深层的角度来看,这一案例揭示了强化学习在 GUI agent 训练中的一个关键优势:RL 可以通过环境反馈逐步塑造更稳定的行为策略,使 agent 学会在错误发生时进行修正。相比纯粹的模仿学习或离线偏好优化方法,RL 在训练过程中直接利用环境奖励信号,使模型能够学习到哪些行为会导致失败,从而在策略空间中逐渐形成更可靠的决策路径。因此,在多步 GUI 操作任务中,强化学习不仅提升了任务完成率,还促进了 agent 行为模式从 一次性动作预测(one-shot prediction)向 持续状态反馈驱动的交互策略(interactive policy learning)转变。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)