大模型应用开发(二):Embedding Models嵌入模型原理及选型
本文介绍了嵌入模型(Embedding Models)的原理及选型。嵌入模型通过将非结构化数据转换为高维向量,捕捉语义信息,支持相似度计算和信息检索。主流模型分为通用型(如BGE-M3)、垂直领域型(如BGE-large-zh)和轻量化型(如nomic-embed-text),选型需考虑任务性质、领域特性和计算资源。文章以阿里百炼为例演示了API调用方法,展示了文本到向量的转换过程。嵌入模型在语义
学习目标
Embedding Models嵌入模型原理及选型
Embedding Models的使用
一.概念与核心原理
1.1 什么是嵌入(Embedding)
嵌入(Embedding)是指非结构化数据转换成向量的过程,通过神经网络模型或大模型,将真实世界的离散数据投影到高纬数据空间上,根据数据在空间中的不同距离,反映数据在物理世界的相似度
1.2 嵌入模型的本质
嵌入模型(Embedding Model)是一种将离散数据(如文本、图像)映射到连续向量空间的技术。通过高维向量表示(如 768 维或 3072 维),模型可捕捉数据的语义信息,使得语义相似的文本在向量空间 中距离更近。例如,“忘记密码”和“账号锁定”会被编码为相近的向量,从而支持语义检索而非仅关键词匹配
1.3 核心作用
语义编码
将文本、图像等转换为向量,保留上下文信息(如 BERT 的 CLS Token 或均值池化。
相似度计算
通过余弦相似度、欧氏距离等度量向量关联性,支撑检索增强生成(RAG)、推荐系统等应用。
信息降维
压缩复杂数据为低维稠密向量,提升存储与计算效率。
1.4 关键技术原理
上下文依赖
现代模型(如 BGE-M3)动态调整向量,捕捉多义词在不同语境中的含义。
训练方法
对比学习(如 Word2Vec 的 Skip-gram/CBOW)、预训练+微调(如 BERT)。
二.主流嵌入模型分类与选型指南
Embedding 模型将文本转换为数值向量,捕捉语义信息,使计算机能够理解和比较内容的"意义"。
选择 Embedding 模型的考虑因素:
| 因素 | 说明 |
|---|---|
| 任务性质 | 匹配任务需求(问答、搜索、聚类等) |
| 领域特性 | 通用vs专业领域(医学、法律等) |
| 多语言支持 | 需处理多语言内容时考虑 |
| 维度 | 权衡信息丰富度与计算成本 |
| 许可条款 | 开源vs专有服务 |
| 最大Tokens | 适合的上下文窗口大小 |
Embddding Leaderboard
参考:https://huggingface.co/spaces/mteb/leaderboard
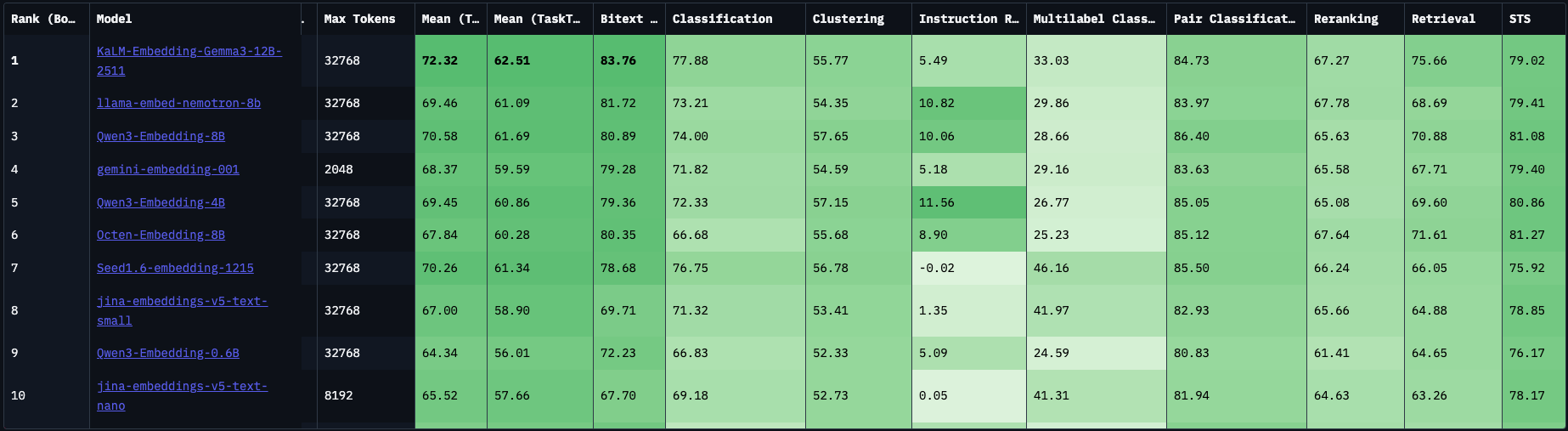
注:更新于2026-03-06
MTEB(Massive Text Embedding Benchmark)是大规模多任务的 Embedding 模型公开评测集,一个全面的评测基准,它涵盖了分类、聚类、检索、排序等8大类任务和58个数据集。
通过MTEB榜单,可以清晰地看到不同模型(如Qwen3系列)在不同任务类型上的性能表现。比如,某些模型在检索任务上表现优异,而另一些可能在聚类或分类任务上更具优势。
Embedding模型有很多种,下面是一些主流分类和选型指南
1. 通用全能型
-
BGE-M3:北京智源研究院开发,支持多语言、混合检索(稠密+稀疏向量),处理 8K 上下文,适合企业级知识库。
-
NV-Embed-v2:基于 Mistral-7B,检索精度高(MTEB 得分 62.65),但需较高计算资源。
2. 垂直领域特化型
-
中文场景: BGE-large-zh-v1.5 (合同/政策文件)、 M3E-base (社交媒体分析)。
-
多模态场景: BGE-VL (图文跨模态检索),联合编码 OCR 文本与图像特征。
3. 轻量化部署型
-
nomic-embed-text:768 维向量,推理速度比 OpenAI 快 3 倍,适合边缘设备。
-
gte-qwen2-1.5b-instruct:1.5B 参数,16GB 显存即可运行,适合初创团队原型验。
注:上面模型均可以下载到本地进行部署
选型决策树:
-
中文为主 → BGE 系列 > M3E;
-
多语言需求 → BGE-M3 > multilingual-e5;
-
预算有限 → 开源模型(如 Nomic Embed)
最佳实践:为特定应用测试多个 Embedding 模型,评估在实际数据上的性能而非仅依赖通用基准。
三.嵌入模型使用案例
嵌入模型我们这里以阿里百练举例,也可以使用其他各大厂商提供的
3.1 官网注册,然后申请apikey,并配置在环境变量里
官网地址:https://bailian.console.aliyun.com/
注册好后,申请好apikey,进入【API参考】
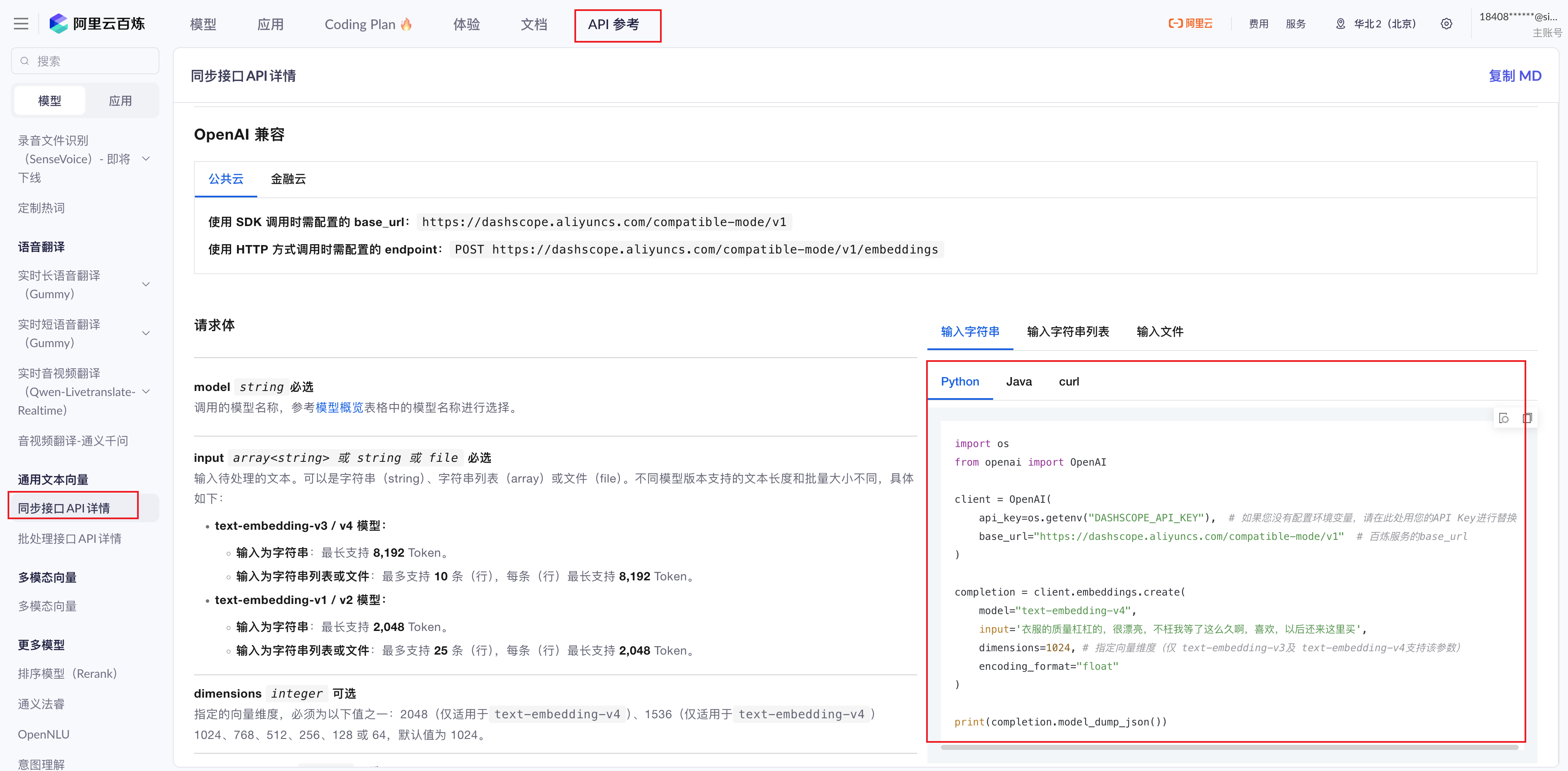
在这里可以看到很多Embedding模型使用的说明,这里我们以python示例代码进行调用
3.2 使用 API 调用方式
1、安装依赖
pip install openai2、示例代码
import os
from openai import OpenAI
# 阿里百炼配置
# DASHSCOPE_API_KEY sk-xxx
# DASHSCOPE_BASE_URL https://dashscope.aliyuncs.com/compatible-mode/v1
client = OpenAI(
# 如果您没有配置环境变量,请在此处用您的API Key进行替换
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百炼服务的base_url
)
def embedding_use():
completion = client.embeddings.create(
model='text-embedding-v3',
input="大模型应用开发",
dimensions=1024, # 指定向量维度(仅 text-embedding-v3及 text-embedding-v4支持该参数)
encoding_format="float"
)
print(completion.model_dump_json())
if __name__ == '__main__':
# 程序入口
embedding_use()3、输出结果
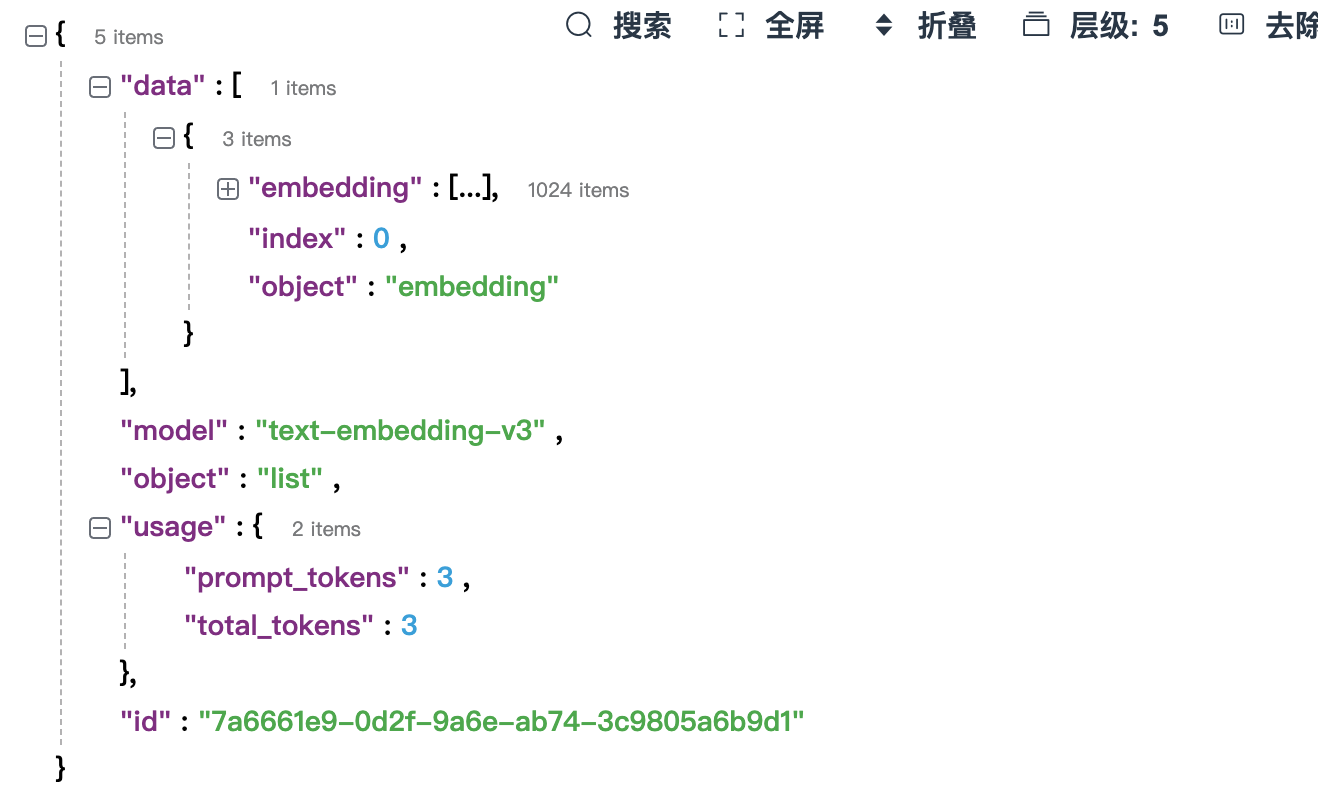
可以看到,模型把text文本“大模型应用开发”转成了一个维度为1024维的向量。
注:api的调用是需要消耗token的,在输出结果中的usage对象总可以看到消耗token的情况,但是阿里给的免费额度根本用不完。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)