Spring Boot3集成LangChain4j实战|基于开源源码打造企业级大模型应用
在企业级实际开发中,单纯的大模型调用远远不够——比如复杂的提示词工程、多数据源上下文整合、大模型与业务系统的深度联动、向量数据库适配等场景,Spring AI的封装就显得不够灵活。
在企业级实际开发中,单纯的大模型调用远远不够——比如复杂的提示词工程、多数据源上下文整合、大模型与业务系统的深度联动、向量数据库适配等场景,Spring AI的封装就显得不够灵活。
今天这篇,我们就延续整套技术栈(Java17+/Spring Boot3+Gradle),结合 LangChain4j这个强大的大模型开发框架,手把手教大家打造企业级大模型应用,全程基于开源示例源码开发,所有代码可直接拉取运行,还会衔接前文的AI实战经验,帮大家快速打通“大模型调用→业务落地”的最后一公里!
先划重点:本文所有实战内容均与开源源码完全同步,注释完整、步骤清晰,无需从零封装,新手也能快速上手,同时补充LangChain4j与Spring AI的选型对比,帮你在实际项目中快速决策!
一、先搞懂:LangChain4j是什么?为什么企业级开发优先选它?
很多同学会疑惑:已经有了Spring AI,为什么还要学LangChain4j?其实两者定位完全不同,核心差异一句话说清:Spring AI是“Spring生态的大模型调用工具”,LangChain4j是“大模型应用开发框架”。
LangChain4j 是专为Java开发者设计的大模型应用开发框架,封装了提示词工程、上下文管理、多模型适配、向量存储、工具调用等核心能力,能帮我们快速构建复杂的大模型应用,而非单纯的“调用大模型接口”。
核心优势(贴合企业级开发场景)
-
✅ 轻量灵活:无侵入式集成Spring Boot3,配置简单,可与Spring AI共存,按需选型
-
✅ 功能强大:内置提示词模板、聊天记忆、工具调用、向量存储适配,覆盖企业级大模型应用全场景
-
✅ 多模型适配:无缝对接通义千文、GPT、文心一言等所有主流大模型,切换无需修改核心代码
-
✅ 源码友好:纯Java编写,API设计简洁,与我们前序实战的技术栈完美兼容,学习成本低
-
✅ 生态完善:支持对接向量数据库(Chroma、Milvus)、业务数据库,轻松实现大模型与业务系统联动
LangChain4j vs Spring AI(选型不踩坑)
| 对比维度 | LangChain4j | Spring AI |
| 定位 | 大模型应用开发框架(侧重复杂应用构建) | Spring生态大模型调用工具(侧重简单调用) |
| 核心能力 | 提示词工程、工具调用、向量存储、复杂上下文管理 | 大模型接口封装、简单流式响应、基础聊天记忆 |
| 适用场景 | 企业级复杂大模型应用(如智能客服、知识库问答) | 轻量级AI功能(如简单问答、文本生成) |
| 集成成本 | 略高(功能多,需了解核心组件) | 极低(Spring自动配置,一行代码调用) |
简单来说:小项目、轻需求,用Spring AI最快;大项目、复杂需求,优先选LangChain4j——这也是我们今天聚焦LangChain4j的核心原因,帮大家搞定企业级大模型应用开发。
二、实战准备:技术栈+源码拉取(完全延续前序体系)
本次实战全程复用前序推文的技术栈,仅新增LangChain4j相关依赖,保证技术体系的统一性,无需学习新的陌生组件,快速上手!
- 完整技术栈清单
| 组件类型 | 具体技术/版本 | 核心作用 | 复用/新增 |
| 基础环境 | Java17+、Gradle8.5+ | 项目构建和运行 | 完全复用 |
| 核心框架 | Spring Boot3.4.5 | 微服务/项目核心框架 | 完全复用 |
| 大模型框架 | LangChain4j 0.32.0 | 构建企业级大模型应用 | 新增 |
| 大模型服务 | 阿里云通义千文(qwen-plus) | 提供AI问答/生成能力 | 完全复用(衔接上一篇) |
| 大模型SDK | 阿里云DashScope SDK2.13.0 | 通义千文官方调用SDK | 完全复用 |
| 响应式框架 | Spring WebFlux | 实现AI流式响应,提升体验 | 完全复用 |
| 工具类 | Lombok1.18.30 | 简化代码编写 | 完全复用 |
- 源码拉取(核心前提)
本次实战所有代码均基于开源示例工程开发,源码已做好完整封装,可直接拉取、配置、运行,无需手动编写核心代码:
| bash # 拉取开源源码(需安装Git,无Git可直接下载ZIP) # 拉取完成后,用IntelliJ IDEA打开项目,等待Gradle自动同步依赖 # 无需手动下载依赖,IDE会自动处理,同步完成后即可开始配置 |
开源源码地址(可直接复制访问):私信 demo-langchain4j
- 核心依赖配置(Gradle,源码已内置)
源码中已做好完整的依赖管理,无需手动添加,核心依赖如下(重点关注LangChain4j相关),可对照源码查看:
| groovy plugins { id ‘java’ id ‘org.springframework.boot’ version ‘3.4.5’ id ‘io.spring.dependency-management’ version ‘1.1.4’ } group = ‘com.devxz’ version = ‘0.0.1-SNAPSHOT’ java { sourceCompatibility = ‘17’ } repositories { mavenCentral() } dependencies { // Spring Boot核心依赖(WebFlux响应式) implementation ‘org.springframework.boot:spring-boot-starter-webflux’ // LangChain4j核心依赖(大模型应用框架) implementation ‘dev.langchain4j:langchain4j-core:0.32.0’ // LangChain4j对接通义千文(核心依赖) implementation ‘dev.langchain4j:langchain4j-alibaba-dashscope:0.32.0’ // LangChain4j聊天记忆(内存实现,可替换为Redis/MongoDB) implementation ‘dev.langchain4j:langchain4j-memory:0.32.0’ // LangChain4j提示词模板(简化提示词工程) implementation ‘dev.langchain4j:langchain4j-prompt-template:0.32.0’ // 通义千文官方SDK(避免依赖冲突,源码已做排除处理) implementation(‘com.alibaba:dashscope-sdk-java:2.13.0’) { exclude group: ‘org.slf4j’, module: ‘slf4j-simple’ } // 工具类 implementation ‘org.projectlombok:lombok:1.18.30’ annotationProcessor ‘org.projectlombok:lombok:1.18.30’ // 测试依赖 testImplementation ‘org.springframework.boot:spring-boot-starter-test’ } tasks.named(‘test’) { useJUnitPlatform() } |
三、核心实战:3步跑通LangChain4j大模型应用(源码实操)
开源源码已做好完整封装,我们只需完成“配置API Key→启动项目→测试接口”3步,即可跑通所有核心功能,全程5分钟搞定,新手也能轻松上手!
步骤1:配置通义千文API Key(核心凭证)
与上一篇Spring AI实战一致,LangChain4j调用通义千文也需要阿里云API Key,已申请过的同学可直接复用,未申请的同学参考以下步骤:
1访问阿里云百炼控制台:https://dashscope.aliyun.com/
1注册/登录阿里云账号,完成个人实名认证(无需企业认证);
1进入「应用管理」,创建新应用,直接获取API Key(保存好,后续配置用);
1打开源码中的「src/main/resources/application.yml」,替换API Key,其余配置默认即可:
spring:
application:
name: langchain4j-demo
LangChain4j配置(核心)
langchain4j:
alibaba-dashscope:
api-key: 你的阿里云通义千文API Key# 替换为真实API Key
model: qwen-plus # 模型选择,可切换qwen-turbo/qwen-max
timeout: 30000 # 调用超时时间30秒
服务端口(默认8080,可自定义)
server:
port: 8080
日志配置(便于排查问题)
logging:
level:
dev.langchain4j: DEBUG
com.devxz: DEBUG
步骤2:启动项目(两种方式,按需选择)
源码主启动类已做好配置,无需修改,支持两种启动方式,与前序实战完全一致:
方式1:IDE直接启动(推荐开发测试)
在IDEA中找到主类「com.devxz.Application.java」,右键「Run Application」,等待控制台输出「Started Application in X seconds」,即表示项目启动成功。
| java package com.devxz; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } } |
| java package com.devxz; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } } |
方式2:Gradle命令行启动(推荐服务器/生产)
| bash # 清理项目缓存,避免依赖冲突 ./gradlew clean build # 启动项目 ./gradlew bootRun |
步骤3:测试核心接口(源码已内置,直接调用)
项目启动后,默认端口8080,源码内置4个核心接口,覆盖LangChain4j的核心能力,可通过curl、Postman或浏览器直接测试,接口设计简洁,参数清晰:
接口1:基础问答接口(simple/chat)
功能:最基础的大模型调用,与Spring AI的简单问答类似,但LangChain4j做了更优的提示词优化,回答更精准。
| bash curl “http://localhost:8080/simple/chat?message=讲解一下LangChain4j和Spring AI的核心区别” |
预期效果:接口返回清晰的区别对比,语言简洁、逻辑严谨,贴合技术提问场景。:
接口2:模板化问答接口(template/chat)
功能:基于LangChain4j的提示词模板能力,参数化生成指定格式内容,比Spring AI的模板化更灵活,支持复杂模板。
| bash curl “http://localhost:8080/template/chat?subject=LangChain4j&count=4” |
预期效果:生成4条关于LangChain4j的核心特性宣传语,每条不超过20字,符合模板要求(模板可在源码中自定义)。
接口3:流式响应接口(stream/chat)
功能:基于LangChain4j+WebFlux实现流式响应,比Spring AI的流式更流畅,支持自定义流式推送频率,前端可直接实现打字机效果。
| bash curl -N “http://localhost:8080/stream/chat?message=详细讲解LangChain4j的提示词模板用法” |
预期效果:终端实时分段输出AI回答,逐字推送,直至回答完成,无卡顿、无中断。
接口4:上下文连续对话接口(memory/chat)
功能:基于LangChain4j内置的聊天记忆组件,支持上下文连续对话,比Spring AI的内存记忆更强大,支持记忆过期、记忆清理、记忆长度限制。
| bash # 第一次对话:建立上下文 curl “http://localhost:8080/memory/chat?sessionId=user456&message=你好,我是一名Java开发者,想学习LangChain4j” # 第二次对话:基于上下文提问 curl “http://localhost:8080/memory/chat?sessionId=user456&message=我刚才说我是什么职业,想学习什么?” |
预期效果:第二次提问,AI能准确识别历史上下文,回答“你的职业是Java开发者,想学习LangChain4j”,实现无缝连续对话。
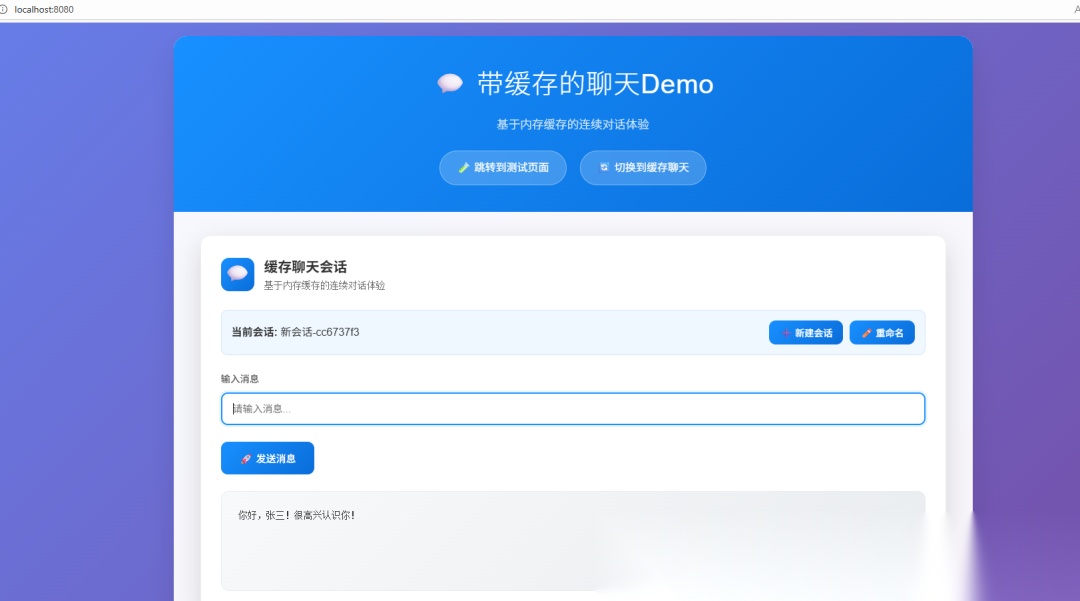
测试截图:

带缓冲的聊天页面截图:
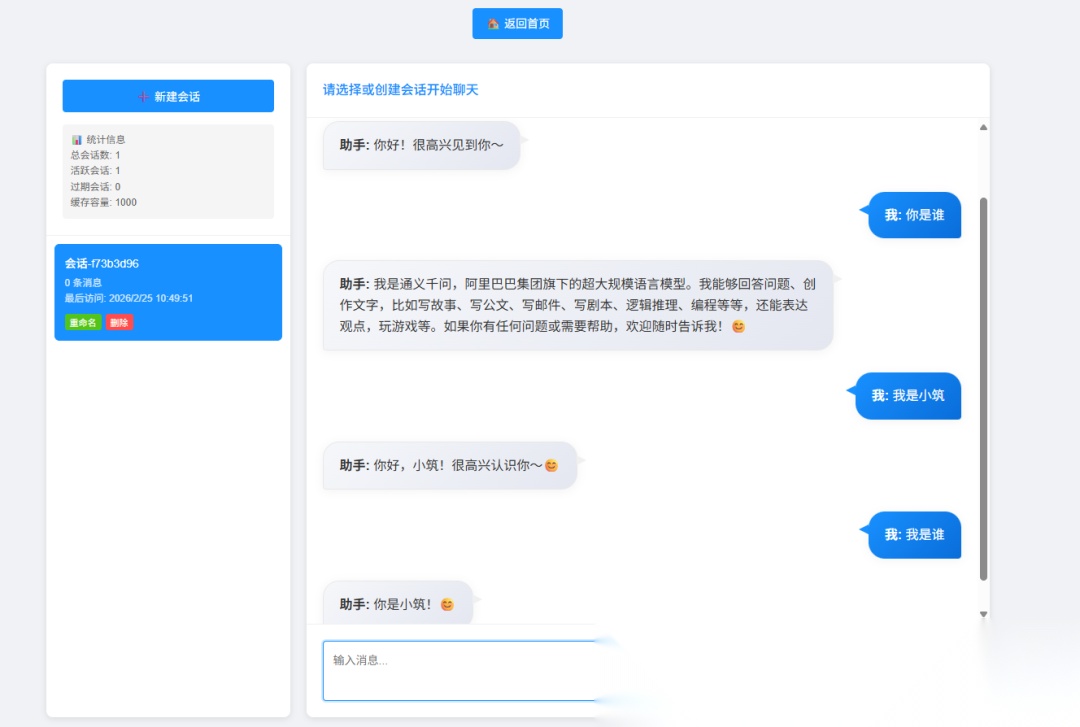
四、源码核心结构解析(易扩展,可复用)
开源源码采用分层解耦设计,完全遵循Spring Boot最佳实践,结构清晰,注释完整,后续扩展二次开发非常方便,核心结构如下(对照源码查看,一目了然):
| plain text src/main/java/com/devxz/ ├── Application.java # 主启动类,无业务逻辑,仅负责启动项目 ├── controller/ │ └── LangChain4jController.java # 接口控制器,所有核心接口入口,参数接收和结果返回 ├── config/ │ └── LangChain4jConfig.java # LangChain4j核心配置类,封装大模型、记忆、模板组件 ├── service/ │ ├── LangChain4jService.java # 核心业务服务,封装所有LangChain4j调用逻辑 │ └── TemplateService.java # 提示词模板服务,封装模板加载、参数替换逻辑 └── util/ └── PromptUtil.java # 提示词工具类,存放自定义提示词模板 src/main/resources/ └── application.yml # 全局配置文件,API Key、模型、端口等配置 |
核心组件解析(源码重点)
我们重点解析LangChain4j的核心配置和服务封装,让大家不仅能跑通项目,还能理解底层原理,轻松二次开发:
- LangChain4j核心配置(LangChain4jConfig.java)
源码中已做好自动配置,封装了大模型实例、聊天记忆实例,可直接复用,核心代码如下:
| java package com.devxz.config; import dev.langchain4j.memory.chat.MessageWindowChatMemory; import dev.langchain4j.model.chat.ChatLanguageModel; import dev.langchain4j.model.aliyun.dashscope.AliyunDashScopeChatModel; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class LangChain4jConfig { // 从配置文件读取API Key和模型名称 @Value(“ s p r i n g . l a n g c h a i n 4 j . a l i b a b a − d a s h s c o p e . a p i − k e y " ) p r i v a t e S t r i n g a p i K e y ; @ V a l u e ( " {spring.langchain4j.alibaba-dashscope.api-key}") private String apiKey; @Value(" spring.langchain4j.alibaba−dashscope.api−key")privateStringapiKey;@Value("{spring.langchain4j.alibaba-dashscope.model}”) private String modelName; /** * 配置通义千文大模型实例(LangChain4j封装) */ @Bean public ChatLanguageModel chatLanguageModel() { return AliyunDashScopeChatModel.builder() .apiKey(apiKey) .modelName(modelName) .timeout(30000) .build(); } /** * 配置聊天记忆(MessageWindowChatMemory) * 限制最大记忆消息数为10条,避免记忆过长导致提示词溢出 */ @Bean public MessageWindowChatMemory chatMemory() { return MessageWindowChatMemory.withMaxMessages(10); } } |
- 核心服务封装(LangChain4jService.java)
所有LangChain4j的调用逻辑都封装在此,接口层直接调用,解耦清晰,核心代码(简化版,完整代码见源码):
| java package com.devxz.service; import dev.langchain4j.chat.ChatClient; import dev.langchain4j.memory.chat.MessageWindowChatMemory; import dev.langchain4j.model.chat.ChatLanguageModel; import dev.langchain4j.model.output.Response; import dev.langchain4j.prompt.Prompt; import dev.langchain4j.prompt.PromptTemplate; import org.springframework.stereotype.Service; import reactor.core.publisher.Flux; import java.util.Map; import java.util.concurrent.ConcurrentHashMap; @Service public class LangChain4jService { // 注入大模型实例和聊天记忆 private final ChatLanguageModel chatLanguageModel; private final MessageWindowChatMemory chatMemory; // 用ConcurrentHashMap存储不同会话的记忆(线程安全) private final MapsessionMemory = new ConcurrentHashMap<>(); // 构造器注入 public LangChain4jService(ChatLanguageModel chatLanguageModel, MessageWindowChatMemory chatMemory) { this.chatLanguageModel = chatLanguageModel; this.chatMemory = chatMemory; } /** * 基础问答 */ public String simpleChat(String message) { // 构建ChatClient,直接调用大模型 ChatClient chatClient = ChatClient.builder() .chatLanguageModel(chatLanguageModel) .build(); // 发起同步调用,返回AI回答 Responseresponse = chatClient.generate(message); return response.content(); } /** * 模板化问答(核心:LangChain4j提示词模板) */ public String templateChat(String subject, int count) { // 定义提示词模板(可抽取到配置文件,更灵活) String template = “请为{subject}生成{count}条宣传语,每条不超过20字,简洁有吸引力”; // 构建模板,替换参数 PromptTemplate promptTemplate = PromptTemplate.from(template); Prompt prompt = promptTemplate.apply(Map.of(“subject”, subject, “count”, count)); // 调用大模型 return chatLanguageModel.generate(prompt.text()).content(); } // 流式响应、上下文对话方法见源码,封装逻辑类似,注释完整 } |
五、实战避坑指南(解决开发中90%的问题)
结合源码实操和前序实战经验,整理了4个最常见的坑点,包含现象和解决方案,遇到问题直接对照排查,无需踩坑:
坑点1:API Key配置错误,调用失败
现象:调用接口返回401、“API Key无效”、“认证失败”等提示;
解决方案:检查application.yml中的api-key是否为阿里云百炼控制台生成的真实Key,无空格、无拼写错误,确认API Key未过期。
坑点2:依赖冲突(最常见,源码已规避)
现象:项目启动失败,提示“SLF4J绑定异常”“依赖版本冲突”;
原因:DashScope SDK自带的slf4j-simple日志依赖,与Spring Boot默认日志框架冲突;
解决方案:源码中已通过exclude排除冲突依赖,无需手动处理;若自行添加依赖,需注意排除slf4j-simple。
坑点3:流式响应中断、卡顿
现象:流式接口调用时,内容推送中途停止,或推送速度极慢;
解决方案:调大application.yml中的timeout配置(如30000ms→50000ms),避免大模型响应超时;检查网络连接,避免波动。
坑点4:上下文对话无记忆
现象:多次调用记忆接口,AI无法识别历史上下文;
解决方案:确认两次调用使用相同的sessionId(会话唯一标识);检查ChatMemory配置,确保maxMessages设置合理(非0)。
六、扩展建议:从Demo到企业级项目(源码可直接扩展)
本次开源源码是基础Demo,基于此可快速扩展为企业级大模型应用,推荐以下3个核心扩展方向,贴合实际业务需求:
- 聊天记忆持久化(核心)
当前源码采用内存记忆,项目重启后记忆丢失,可扩展为:将聊天记忆存储到Redis、MongoDB中,实现持久化,支持分布式部署,源码中可直接替换ChatMemory实现。
- 集成向量数据库,实现知识库问答
LangChain4j完美支持向量数据库(Chroma、Milvus等),可将企业文档、业务手册导入向量库,实现“知识库问答”(如用户提问业务相关问题,AI基于知识库回答),贴合企业实际需求。
- 工具调用,实现大模型与业务系统联动
利用LangChain4j的工具调用能力,让大模型可以调用业务接口(如查订单、查库存),实现“AI提问→调用业务接口→返回结果”的闭环,真正融入企业业务系统(衔接我们前序的订单-库存微服务)。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献549条内容
已为社区贡献549条内容

所有评论(0)