实验室里的数据墓地:为什么你的数据存了PB级,却喂不饱一个AI?(FAIR原则落地指南)
摘要:本文探讨科学数据管理中的FAIR原则(可发现、可访问、可互操作、可复用),揭示创腾SDH平台如何激活沉睡的研发数据。尽管企业积累了大量数据,但往往因存储分散、格式不兼容、元数据缺失等问题无法有效利用。SDH平台通过全域索引、元数据自动提取、统一数据字典等技术,实现数据的智能关联与复用,使其成为AI模型的优质训练素材。在数字化时代,FAIR化的数据管理已成为企业核心竞争力,SDH平台为科研机构
摘要:许多研发管理者发现,买了ELN,LIMS,甚至建了数据湖,数据依然是死的。本文深度解析科学数据管理的黄金法则——FAIR原则,并揭秘创腾SDH平台如何让沉睡的数据真正活过来,成为AI for Science的燃料。
在2026年的今天,数据是新时代的石油这句口号已经喊得让人耳朵起茧。然而,走进大多数制药和材料企业的研发中心,你会发现这里不是油田,更像是一座数据墓地:
- 耗资百万做出的色谱、质谱数据,死锁在仪器的本地硬盘里;
- 十年前的失败实验记录,躺在某个离职员工的加密Excel里;
- 想训练一个活性预测模型,数据科学家花了80%的时间在清洗数据,最后发现关键的实验条件(Metadata)缺失。
存下来不等于资产化。
为了解决这个问题,科学界提出了FAIR原则。其萌芽于2014年在荷兰莱顿举办的一次学术研讨会,当时学术界、工业界和出版商共同意识到,随着大数据时代的到来,现有的数据管理方式已无法支撑日益增长的计算机自动化处理需求。2016年,由Wilkinson等学者在《Scientific Data》杂志上正式发表了《FAIR科学数据管理与监管指导原则》。这一原则迅速被G20峰会、欧盟委员会及全球各大科研机构采纳,成为生命科学、材料科学等领域数字化转型的基石。
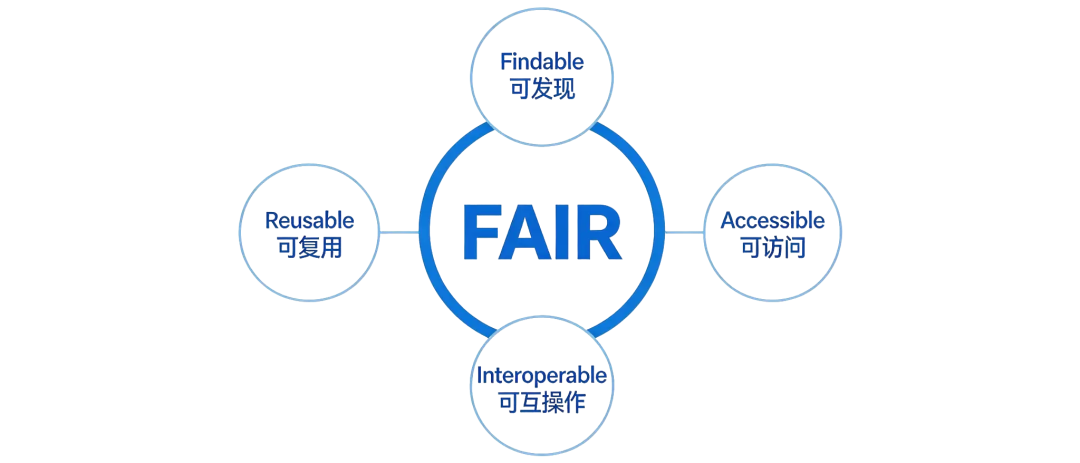
这里需要强调的一点是,FAIR ≠ Open。FAIR强调Findable可发现、Accessible可访问、Interoperable可互操作、Reusable可复用,但并不要求数据必须公开;数据完全可以在合规与权限控制下实现FAIR。其核心愿景不仅仅是让人能看懂数据,更是要让机器能够自动寻找、访问、互操作及复用数据。
今天,我们不谈枯燥的理论,只谈怎么利用创腾SDH(科学数据基因组平台),把这四个字母真正落地变成生产力。

F-Findable(可发现):
告别大海捞针:
痛点场景:
我要找三年前针对Target X的所有激酶活性数据。
通常的结果是:翻阅几十本纸质记录本,或者在共享盘的几万个文件夹里搜索文件名,还得祈祷当年的实验员命名规范是统一的。
SDH落地策略:
SDH不仅仅是存储,它是给数据装上GPS。
- 全域索引:SDH通过星链技术连接ELN、LIMS和仪器工作站。你只需在搜索框输入一个结构式、一个项目代号或一个参数,系统会横跨所有系统,把相关的文档、图谱、结论全部抓取出来。
- 元数据自动提取:当你上传一个HPLC文件时,SDH会提取其中的保留时间、峰面积、操作员、仪器型号等元数据(Metadata),并打上标签。
- 结果:数据从被遗忘变为毫秒级定位。
A-Accessible(可访问):
打破软件壁垒:
痛点场景
为了看一张NMR图谱,我得跑到实验室那台装了特定分析软件的旧电脑上去。
专用的仪器数据格式(Proprietary Formats)是数据流动的最大障碍。
SDH落地策略:
SDH打通了软件间的数据壁垒。
-
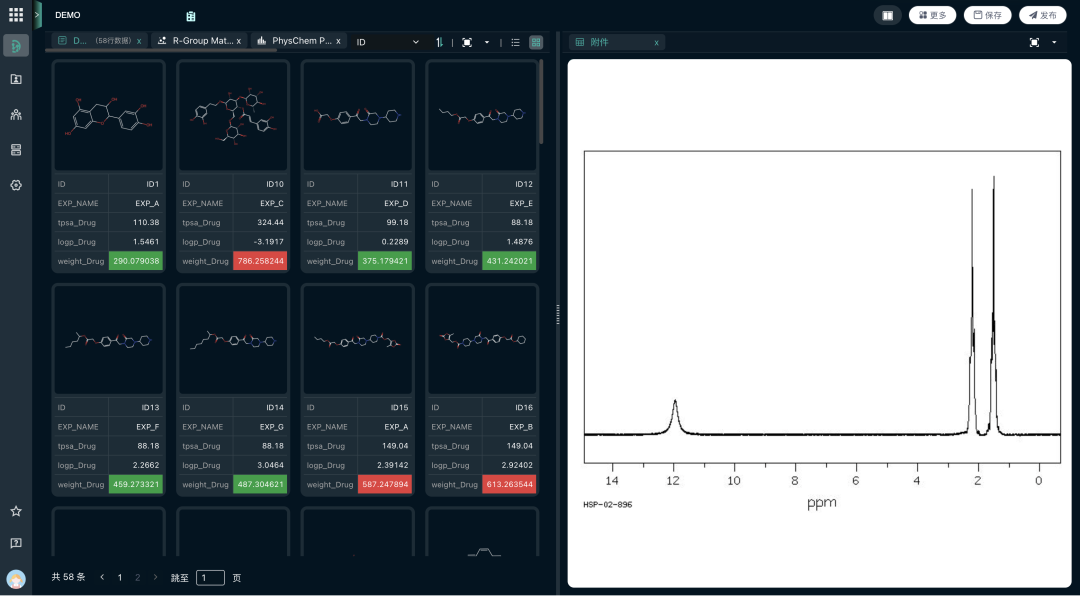
图谱随时查看:NMR图谱作为附件在SDH中可随时查看。
-
权限控制下的自由:在确保IP安全(Authentication & Authorization)的前提下,通过浏览器即可访问原始数据。研发总监出差时,在iPad上就能查看刚刚生成的晶体衍射图。
-
结果:数据不再被锁在特定的硬件或软件里,实现了民主化访问。
I-Interoperable(可互操作):
拒绝数据孤岛:
痛点场景:
合成人员用ELN,测试人员用LIMS,分析人员用Excel。
要关联一个化合物的结构和它的IC50值,需要人工复制粘贴。一旦结构改了,活性数据没同步,模型训练就是灾难。
SDH落地策略:
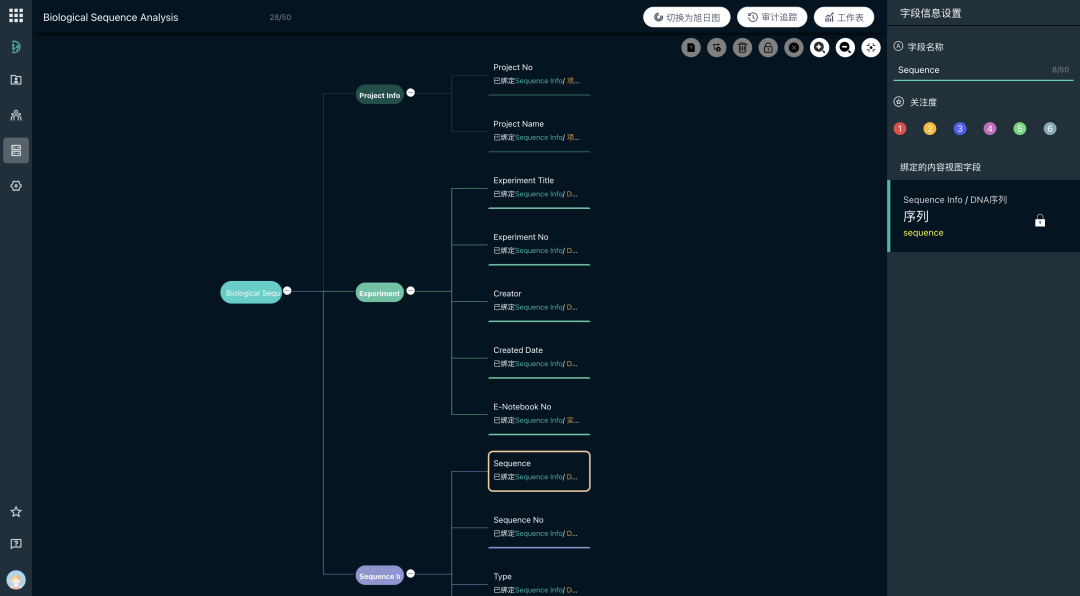
这是SDH最核心的黑科技——数据基因组。
- 统一语言:SDH可建立一套企业级的科学数据字典。它知道IC50、Half maximal inhibitory concentration和50%抑制率是同一个概念。
- 语义关联:SDH能够理解数据之间的逻辑关系。它能自动将MaXFlow计算出的结合能、ELN里的合成步骤、LIMS里的测试结果,通过样品ID自动串联起来,形成完整的证据链。
- 结果:机器能够理解数据的含义,不同系统间的数据可以无缝对话。
R - Reusable(可复用):
让数据永生:
痛点场景:
一个新药项目失败了,产生的数据就被丢进了垃圾堆。实际上,这些失败数据(Negative Data)对于AI模型的训练价值,甚至高于成功数据。但因为缺乏上下文(Context),这些数据无法被复用。
这是AI时代最大的痛点。
SDH落地策略:
SDH将数据转化为AI-Ready的资产。
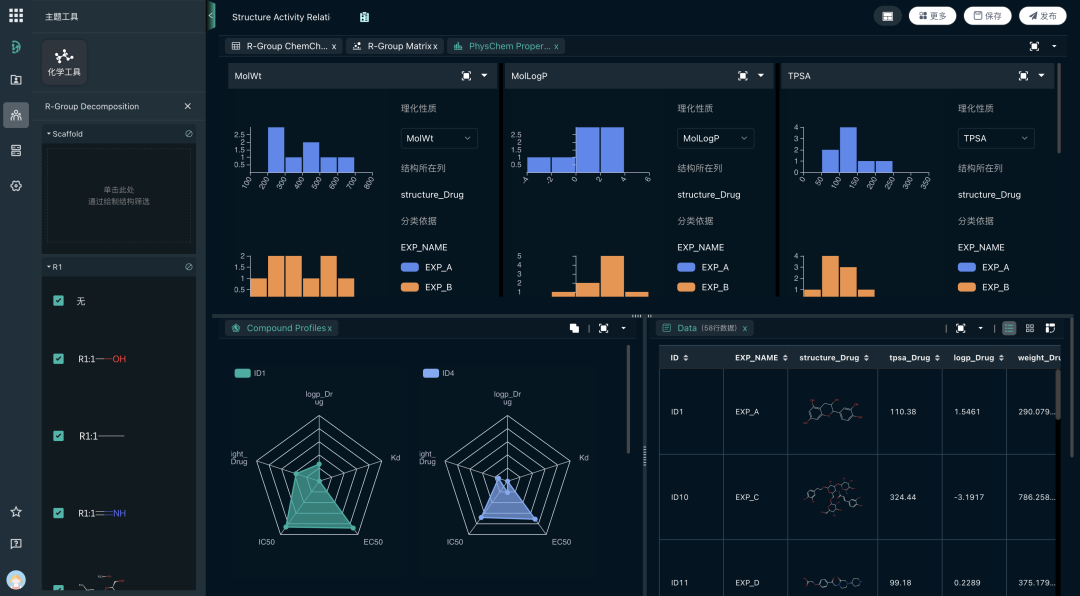
- 保留完整上下文:SDH在抓取数据时,会保留实验的环境参数(温度、湿度、仪器状态)。5年后AI需要训练时,这些上下文至关重要。
- 一键数据集构建:数据科学家可以直接在SDH中圈选:“给我导出过去10年所有Suzuki偶联反应的收率数据,包括催化剂类型和溶剂条件”。系统会自动清洗并生成标准格式的数据集(如CSV/JSON),直接喂给MaXFlow或其他AI模型进行训练。
- 结果:每一个实验数据,都在为未来的创新贡献价值,实现了从一次性使用到无限次挖掘的跃迁。
结语:
从Digitalization到Intelligence
FAIR原则不是为了合规,而是为了生存。
在2026年,企业的核心竞争力不再是拥有多少仪器,而是拥有多少FAIR数据。创腾SDH平台,正是帮助您构建这一核心竞争力的数字化基座。
别让您的实验室数据继续沉睡。
参考文献:
The FAIR Guiding Principles for scientific data management and stewardship | Scientific Data

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)