大模型应用开发(一):认识向量
摘要:本文介绍了向量表征在AI领域的核心概念与应用。主要内容包括:(1)向量表征的本质是将复杂对象映射为低维向量,通过距离度量语义相似性;(2)文本向量(Embeddings)的获取方法及相似度计算(余弦相似度、欧氏距离);(3)代码实战演示了使用OpenAI API生成文本向量,并通过numpy计算向量相似度。结果显示,语义相近的文本其向量距离更近,验证了向量表征的有效性。本文为理解和使用文本向
学习目标
理解向量表征
向量与文本向量
向量间的相似度计算
一、向量表征(Vector Representation)
在人工智能领域,向量表征(Vector Representation)是核心概念之一。通过将文本、图像、声音、行为甚至复杂关系转化为高维向量(Embedding),AI系统能够以数学方式理解和处理现实世界中的复杂信息。这种表征方式为机器学习模型提供了统一的“语言”。
1.1. 向量表征的本质
向量表征的本质:万物皆可数学化
(1)核心思想
-
降维抽象:将复杂对象(如一段文字、一张图片)映射到低维稠密向量空间,保留关键语义或特征。
-
相似性度量:向量空间中的距离(如余弦相似度)反映对象之间的语义关联(如“猫”和“狗”的向量距离小于“猫”和“汽车”)。
(2)数学意义
-
特征工程自动化:传统机器学习依赖人工设计特征(如文本的TF-IDF),而向量表征通过深度学习自动提取高阶抽象特征。
-
跨模态统一:文本、图像、视频等不同模态数据可映射到同一向量空间,实现跨模态检索(如“用文字搜图片”)
1.2. 向量表征的典型应用场景
(1)自然语言处理(NLP)
-
词向量(Word2Vec、GloVe):单词映射为向量,解决“一词多义”问题(如“苹果”在“水果”和“公司”上下文中的不同向量)。
-
句向量(BERT、Sentence-BERT):整句语义编码,用于文本相似度计算、聚类(如客服问答匹配)。
-
知识图谱嵌入(TransE、RotatE):将实体和关系表示为向量,支持推理(如预测“巴黎-首都-法国”的三元组可信度)。
(2)计算机视觉(CV)
-
图像特征向量(CNN特征):ResNet、ViT等模型提取图像语义,用于以图搜图、图像分类。
-
跨模态对齐(CLIP):将图像和文本映射到同一空间,实现“描述文字生成图片”或反向搜索。
(3)推荐系统
-
用户/物品向量:用户行为序列(点击、购买)编码为用户向量,商品属性编码为物品向量,通过向量内积预测兴趣匹配度(如YouTube推荐算法)。
(4)复杂系统建模
-
图神经网络(GNN):社交网络中的用户、商品、交互事件均表示为向量,捕捉网络结构信息(如社区发现、欺诈检测)。
-
时间序列向量化:将股票价格、传感器数据编码为向量,预测未来趋势(如LSTM、Transformer编码)。
1.3. 向量表征的技术实现
(1)经典方法
-
无监督学习:Word2Vec通过上下文预测(Skip-Gram)或矩阵分解(GloVe)生成词向量。
-
有监督学习:微调预训练模型(如BERT)适应具体任务,提取任务相关向量。
(2)前沿方向
-
对比学习(Contrastive Learning):通过构造正负样本对(如“同一图片的不同裁剪”为正样本),拉近正样本向量距离,推开负样本(SimCLR、MoCo)。
-
多模态融合:将文本、图像、语音等多模态信息融合为统一向量(如Google的MUM模型)。
-
动态向量:根据上下文动态调整向量(如Transformer的注意力机制),解决静态词向量无法适应多义性的问题
二、 什么是向量
向量是一种有大小和方向的数学对象。它可以表示为从一个点到另一个点的有向线段。例如,二维空间中的向量可以表示为(x,y) ,表示从原点(0,0) 到点(x,y) 的有向线段。

以此类推,我可以用一组坐标(x0,x1,x2,...,xn-1)表示一个N维空间中的向量,N叫向量的维度。
2.1 文本向量(Text Embeddings)
-
将文本转成一组N维浮点数,即文本向量又叫 Embeddings
-
向量之间可以计算距离,距离远近对应语义相似度大小
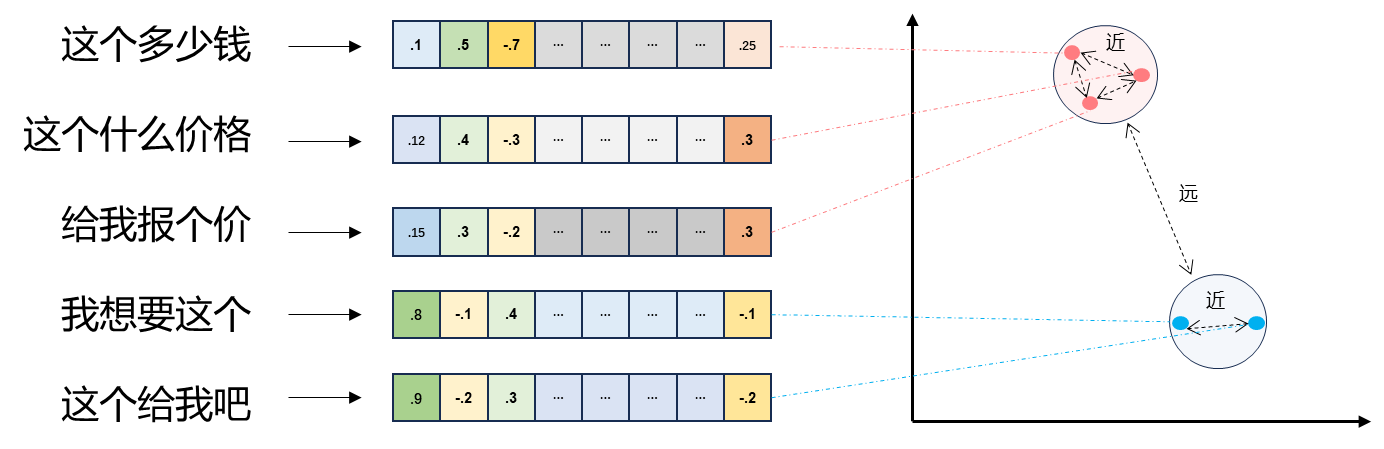
上面就是将文本转成向量,维度统一,语义相近的文本向量距离相近,不相关文本向量疏远;
从上图中可以看出:
“这个多少钱”、“这个什么价格”、“给我报个价”这三个文本对应的向量距离较近,表示语义相似,文末有代码案例
2.2 文本向量是怎么得到的(选)
-
构建相关(正例)与不相关(负例)的句子对样本
-
训练双塔式模型,让正例间的距离小,负例间的距离大
2.3 向量间的相似度计算
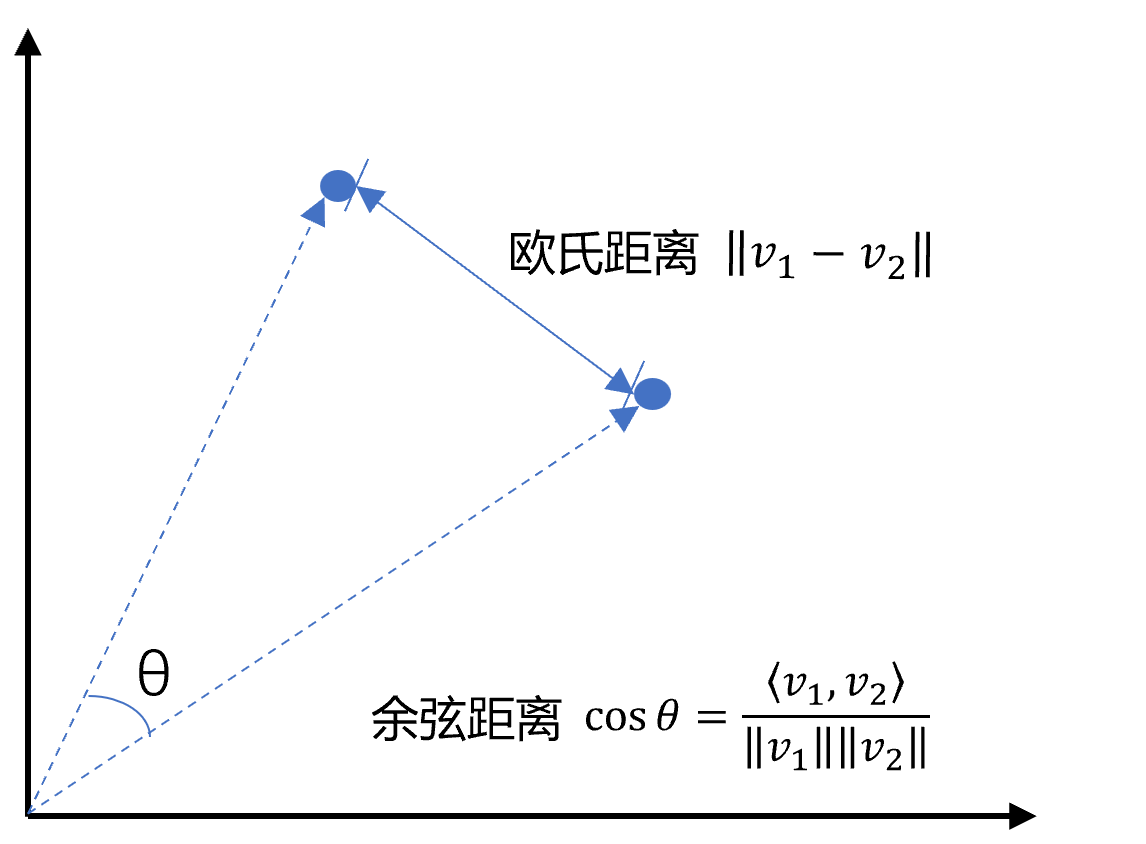
向量间的相似度计算目前有以下三种方式:
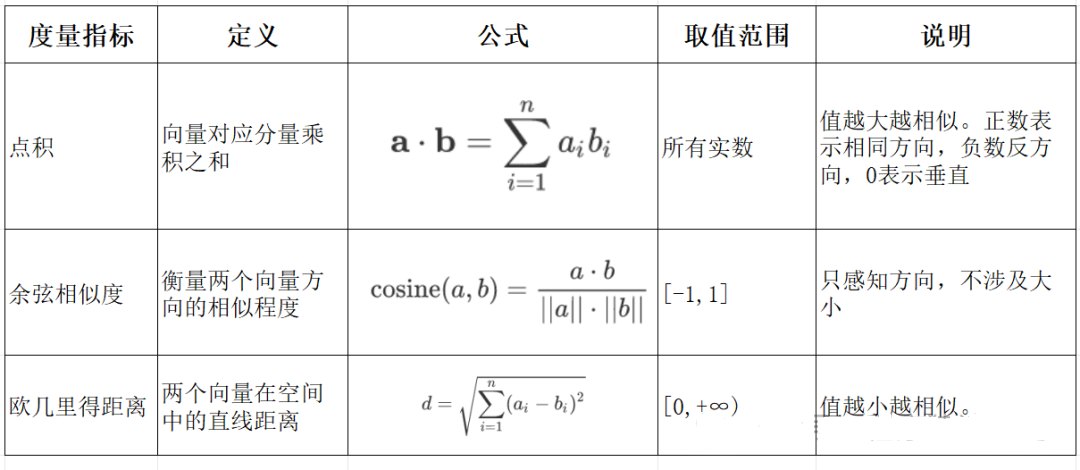
余弦距离是通过余弦相似度计算的,余弦相似度是通过计算两个向量夹角的余弦值来衡量相似性,等于两个向量的点积除以两个向量长度的乘积。
目前在RAG中常用的是余弦相似度,因为只感知向量的方向,不涉及大小;在之前传统的机器学习中常用点积方式
三、代码实战案例
3.1 安装依赖
pip install --upgrade numpy
pip install --upgrade openai3.2 代码案例
import numpy as np
from numpy import dot
from numpy.linalg import norm
from openai import OpenAI
# 需要在系统环境变量中配置好相应的key
# OpenAI key(1 代理方式 2 官网注册购买)
# 阿里百炼配置
# DASHSCOPE_API_KEY sk-xxx
# DASHSCOPE_BASE_URL https://dashscope.aliyuncs.com/compatible-mode/v1
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"), # 如果您没有配置环境变量,请在此处用您的API Key进行替换
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百炼服务的base_url
)
# 使用numpy库来计算余弦相似度、欧式距离
def cos_sim(a, b):
"""
余弦相似度 -- 越大越相似
:param a:
:param b:
:return:
"""
return dot(a, b) / (norm(a) * norm(b))
def l2(a, b):
"""
欧氏距离 -- 越小越相似
:param a:
:param b:
:return:
"""
x = np.asarray(a) - np.asarray(b)
return norm(x)
def get_embeddings(texts, model="text-embedding-v1", dimensions=None):
'''
封装 OpenAI 的 Embedding 模型接口
:param texts: 文本
:param model: 模型,这里阿里百炼平台的文本向量模型 text-embedding-v1/text-embedding-v2 默认为1536纬
text-embedding-v3 是可变纬度,默认1024 参考地址:https://bailian.console.aliyun.com/cn-beijing/?accounttraceid=10fcf5d3a80e44c1ad10b2806c4e376cwtgo&tab=doc#/doc/?type=model&url=2842587
:param dimensions:
:return:
'''
if model == "text-embedding-v1" or model == "text-embedding-v2":
dimensions = None
if dimensions:
data = client.embeddings.create(
input=texts, model=model, dimensions=dimensions).data
else:
data = client.embeddings.create(input=texts, model=model).data
return [x.embedding for x in data]
'''
res = client.embeddings.create(input=texts, model=model) 通过api来使用
结果转为json:res.model_dump_json()
{"data":[{"embedding":[-0.014563590288162231,0.017968913540244102,-0.03981896489858627,-0.011857990175485611,-0.06482243537902832,-0.012165868654847145,0.024648945778608322],"index":0,"object":"embedding"}],"model":"text-embedding-v3","object":"list","usage":{"prompt_tokens":3,"total_tokens":3},"id":"593398f2-c64d-97be-80cf-f8246b1c0456"}
'''
def test_embedding_calculate():
'''
将文本转为向量
:return:
'''
test_query = ["你好,我是周周周"]
vec = get_embeddings(test_query, model='text-embedding-v3', dimensions=128)[0]
print(f"Total dimension: {len(vec)}")
print(f"First 10 elements: {vec[:10]}")
# Total dimension: 1024
# First 10 elements: [-0.09468782693147659, 0.07092003524303436, -0.1038115918636322, -0.028578855097293854,
# -0.07578859478235245, -0.039523541927337646, -0.03273821994662285, -0.0006415148382075131,
# -0.0555092990398407, 0.010743426159024239]
'''
通过文本向量模型:输入一串文本,得到的就是一串数字,
Embedding嵌入模型是将非结构化数据(文本、图像等)转换为向量的过程,将真实世界的离散数据投影到高纬数据空间上,根据数据在空间中
的不同距离 从而反映出物理世界的相识度(相似度计算:通过余弦相似度、欧氏距离等度量向量关联性)
'''
def test_embedding_calculate_dis():
'''
测试embedding 模型度量语义相似度
:return:
'''
# 嵌入文档
query = ["出价多少"]
documents = [
"这个多少钱",
"这个什么价格",
"老板,这个要多少",
"报个价吧",
"我要买这个",
"这个给我吧",
"我想你啦"
]
query_vec = get_embeddings(query, model='text-embedding-v3', dimensions=256)[0]
documents_vec = get_embeddings(documents, model='text-embedding-v3', dimensions=256)
print("Query与自己的余弦距离: {:.2f}".format(cos_sim(query_vec, query_vec)))
print("Query与Documents的余弦距离:")
for vec in documents_vec:
print(cos_sim(query_vec, vec))
print('=' * 30)
print("Query与自己的欧氏距离: {:.2f}".format(l2(query_vec, query_vec)))
print("Query与Documents的欧氏距离:")
for vec in documents_vec:
print(l2(query_vec, vec))
'''
Query与自己的余弦距离: 1.00
Query与Documents的余弦距离:
0.8078281038055384
0.8153551773702133
0.7011658630336517
0.7418624049874367
0.5963177629468172
0.609418536589877
0.42160959331078324
==============================
Query与自己的欧氏距离: 0.00
Query与Documents的欧氏距离:
0.6199546865968806
0.6076920815415995
0.773090085562791
0.7185229179628662
0.8985346325555784
0.8838342217752884
1.0755374945946623
'''
if __name__ == '__main__':
test_embedding_calculate()
# test_embedding_calculate_dis()四、总结
-
使用numpy库来计算余弦相似度、欧式距离
-
余弦距离是通过余弦相似度来计算的;而余弦相似度不关心向量的大小,只关注方向,完全相同方向的两个向量,其余弦相似度为1,完全相反方向的两个向量,其余弦相似度为-1,夹角为90度两个向量(即正交),其余弦相似度为0 -
余弦相似度计算,值越大越相似;欧氏距离越小越相似,通过上面的例子可以初步推测出documents中前四个句子与query语义相似度较高

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)