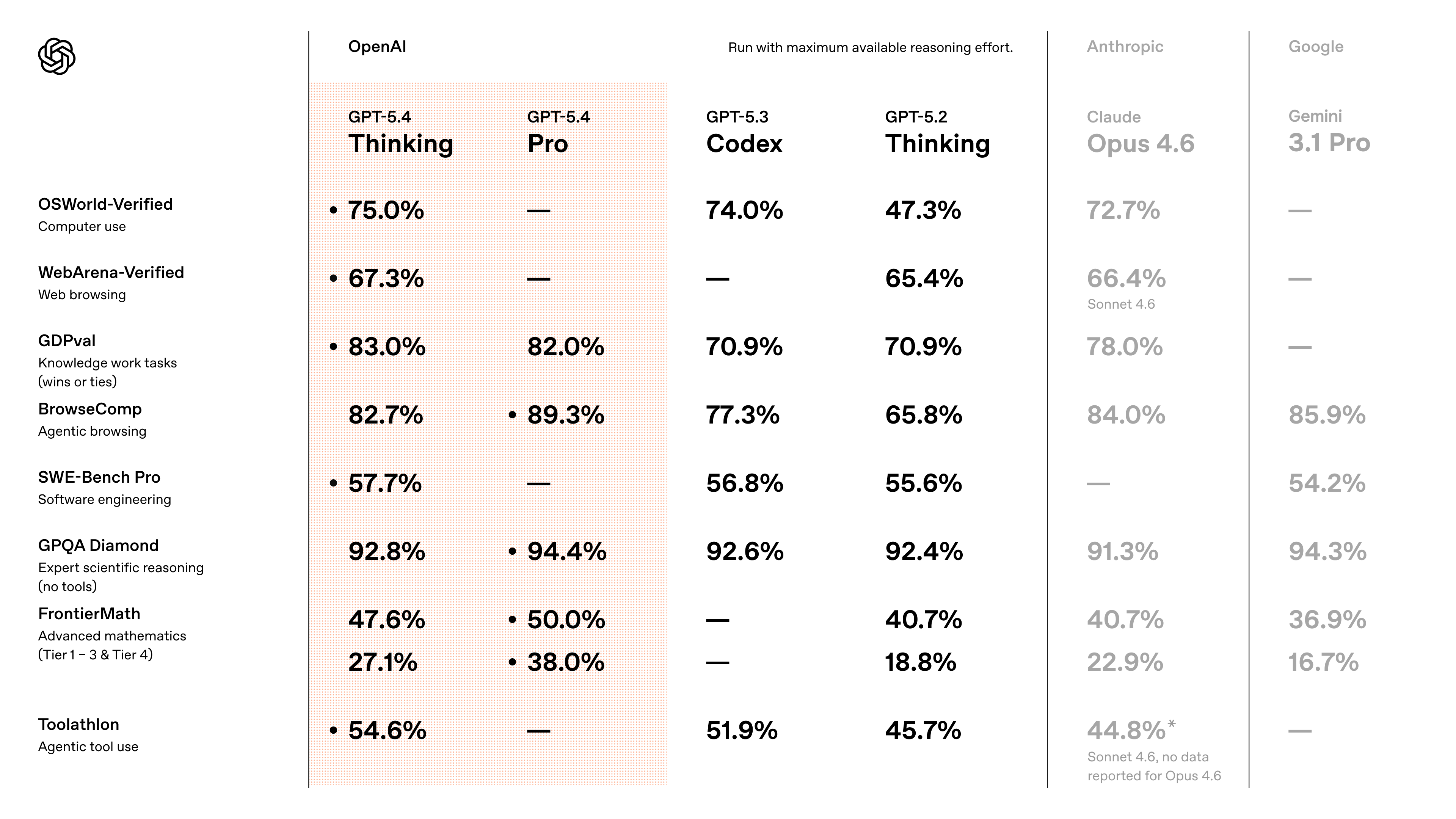
OpenAI 发了 GPT-5.4,这次不是升级,是换赛道
OpenAI发布GPT-5.4,标志着AI从对话助手向数字员工的重大转变。该版本首次整合了聊天、编程和电脑操作三大功能,在OSWorld测试中达到75%通过率,超越人类平均水平。新增的"中途打断"功能允许实时调整AI工作方向,Excel插件则能直接处理数据建模等专业任务。编程方面融合了Codex能力,并能自动测试代码。ToolSearch机制降低47%的Token消耗,安全性能
昨天 OpenAI 扔了个大的出来——GPT-5.4,OpenAI官方直接跟友商旗舰产品进行正面PK。
我看完官方博客的第一反应是:这不像是在发一个"更聪明的聊天机器人",更像是在发一个能替你干活的数字员工。
这次升级,核心在「让 AI 从聊天框走进你的桌面和 Excel」
如果只能用一句话概括 GPT-5.4,就是:它第一次把"会聊天"、"会写代码"和"会操作你的电脑"这三件事塞进了同一个模型里。以前你得分别找不同的模型干不同的事,现在一个就够了。
它真的能操作你的电脑了
GPT-5.4 是 OpenAI 第一个内置原生计算机操控能力的通用模型。翻译成人话就是:它能看你的屏幕截图,然后像人一样点鼠标、敲键盘、切换应用。
在 OSWorld-Verified 这个测试里(模拟真实桌面环境,让 AI 完成各种操作任务),GPT-5.4 拿到了 75.0% 的通过率。上一代 GPT-5.2 只有 47.3%。而人类测试者的平均分?72.4%。
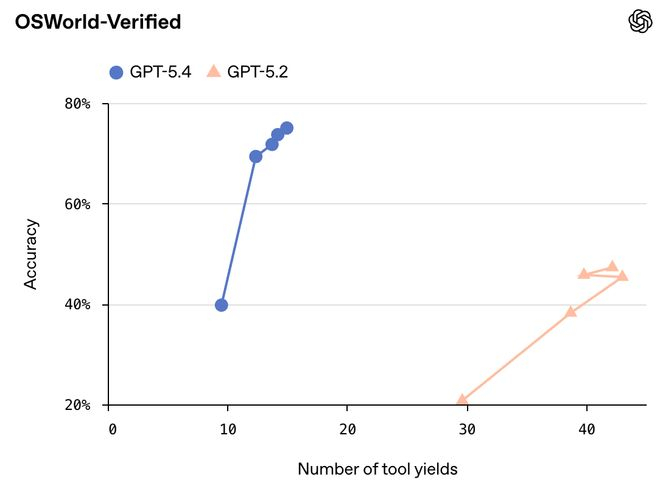
没错,它操作电脑比普通人还顺手了。
实际场景呢?有个做物业管理的公司 Mainstay 说,用 GPT-5.4 去自动登录全美三万多个物业税网站做数据录入,首次成功率 95%,三次内 100%。速度比之前快了 3 倍,Token 消耗少了 70%。这不是跑分游戏,是真金白银省下来的人力成本。
"中途打断"——终于不用干等它写完再说"不对"了
用过以前 ChatGPT 的人都有一个痛:你让它写个方案,它滔滔不绝写了三分钟,结果方向跑偏了,你只能从头来。
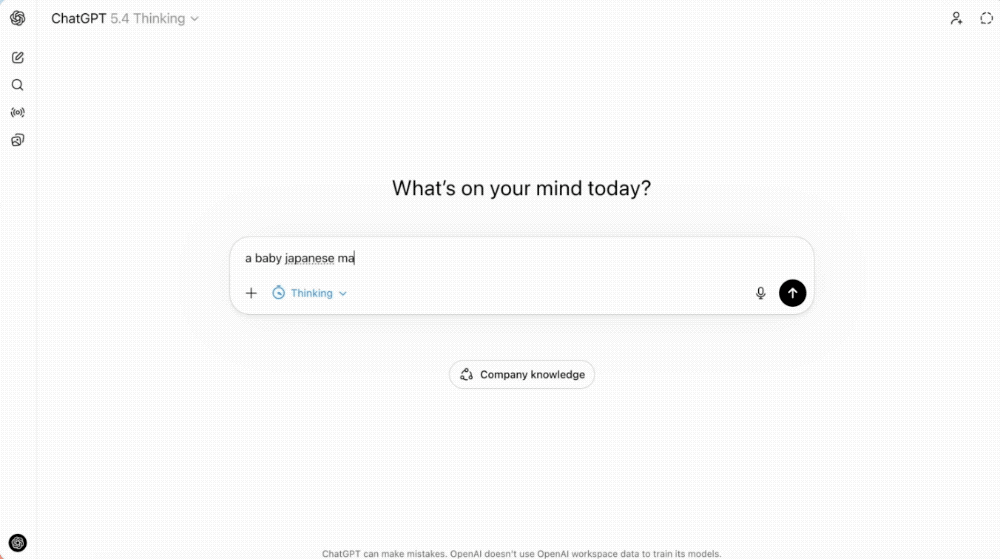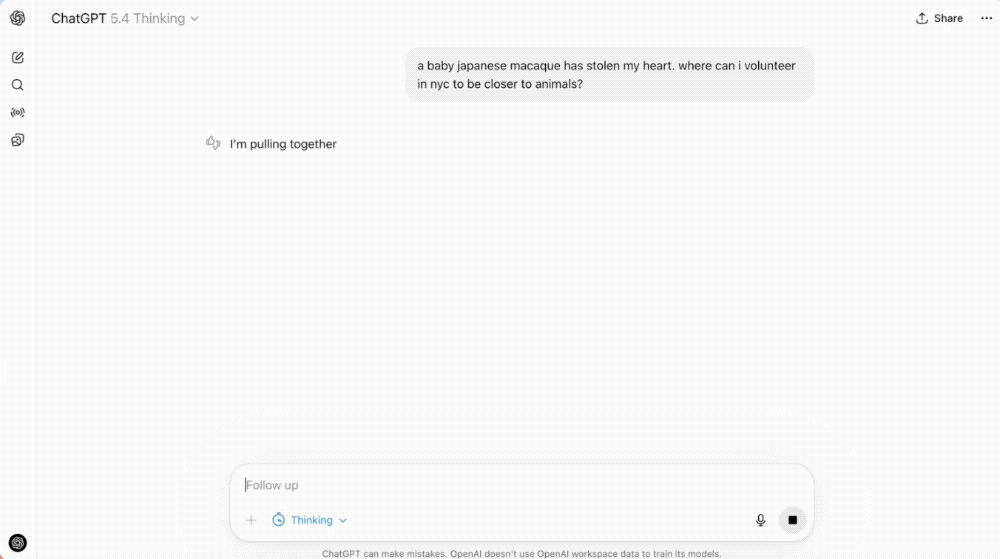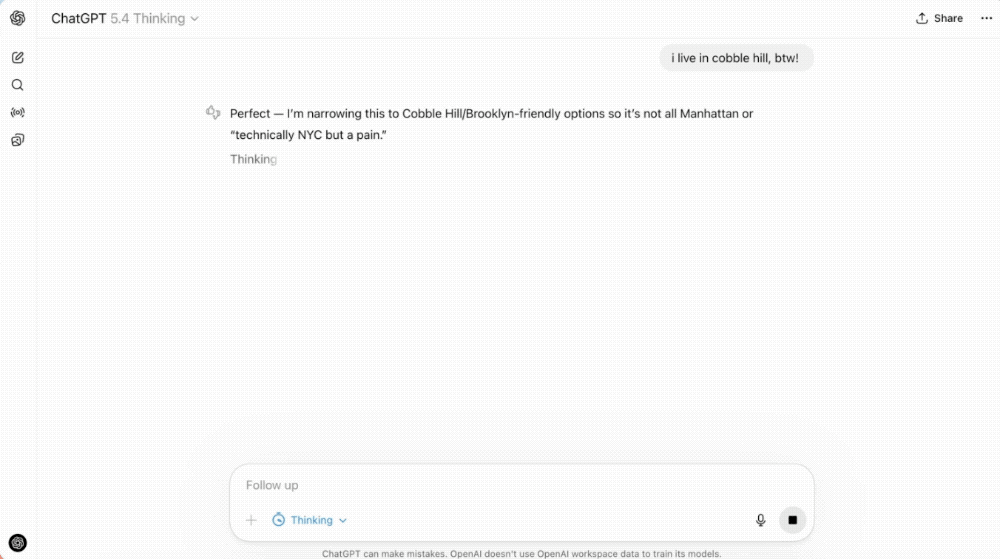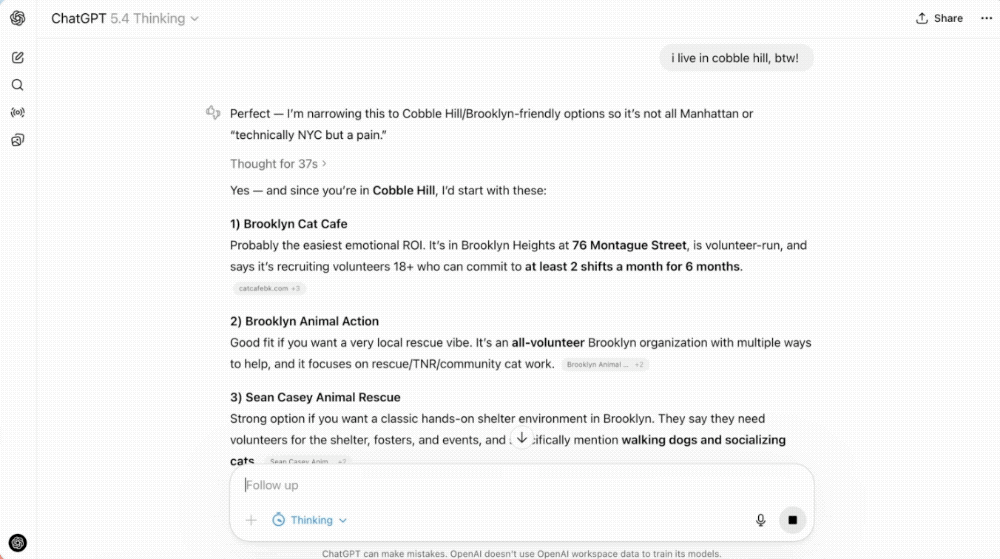
GPT-5.4 Thinking 模式现在会先亮出一个"开工计划"——告诉你它打算怎么干。你觉得哪里不对,直接在它工作的过程中插嘴调整。不用等它写完,不用重来。
听起来是个小功能?但对于那些需要 AI 帮你做深度研究、写几十页报告的场景,这是从"回合制棋牌"变成"即时战略游戏"的体验跃迁。
Excel 终于有了一个"懂业务的同事"
同一天,OpenAI 还发布了 ChatGPT for Excel 插件。GPT-5.4 能直接嵌入到 Excel 和 Google Sheets 里,像一个坐在你旁边的分析师一样帮你建模、清洗数据、生成公式。
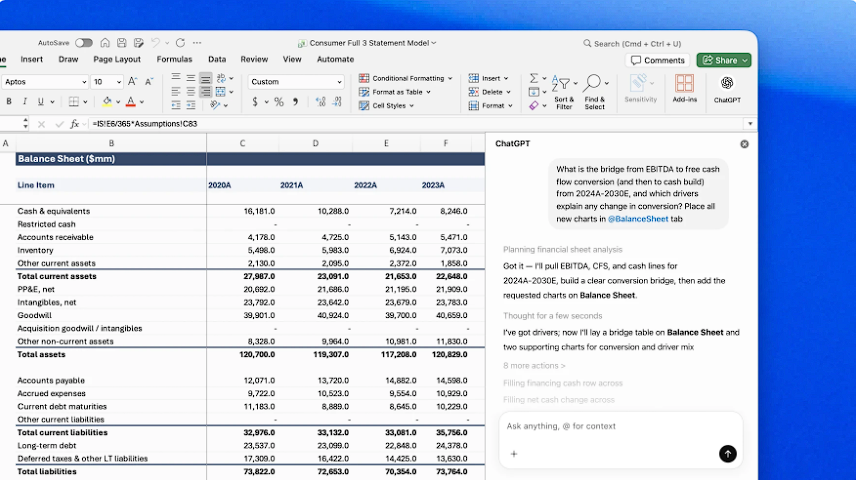
在一个模拟投行初级分析师做表的内部测试里,GPT-5.4 平均得分 87.3%,上代才 68.4%。做 PPT 的时候,人类评委 68% 的时间更喜欢 GPT-5.4 做出来的效果——美感、排版多样性和配图使用都更好。
这个方向挺有意思的。以前 AI 是"你问它答",现在它直接住进了你的日常工具里。财务分析师、咨询顾问、运营同学——你们的 Excel 要进化了。
写代码:Codex 的灵魂装进了通用模型
GPT-5.4 把之前 GPT-5.3-Codex(专门写代码的模型)的编程能力直接融合了进来。在 SWE-Bench Pro(拿真实 GitHub issue 测试 Bug 修复能力的基准测试)上,它得了 57.7%,略超专职代码模型的 56.8%,但延迟更低。
还有个彩蛋:OpenAI 在 Codex 里放了一个实验性的 Skill,叫 Playwright (Interactive)。GPT-5.4 写完前端代码后,能自己拉起浏览器跑一遍,看看界面对不对、按钮能不能点、流程跑不跑得通。
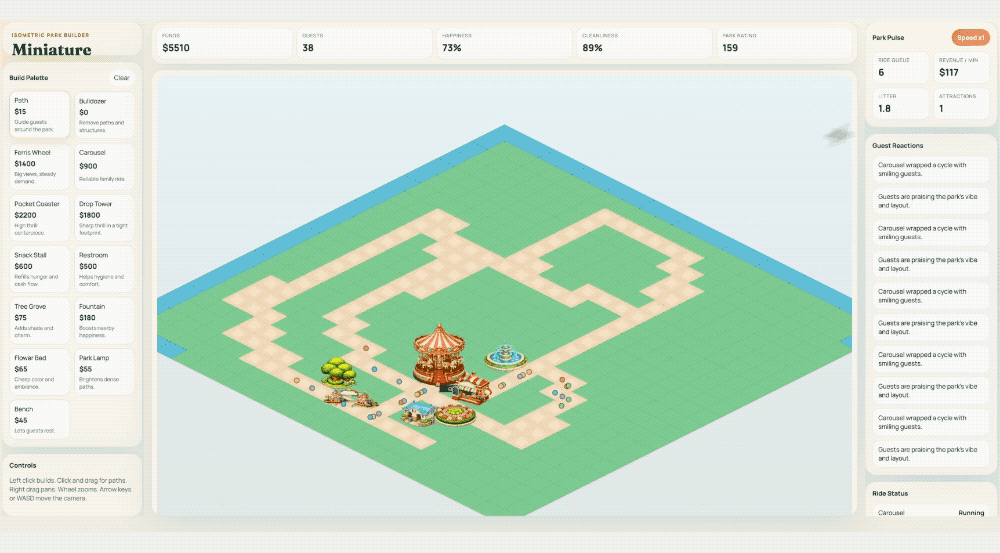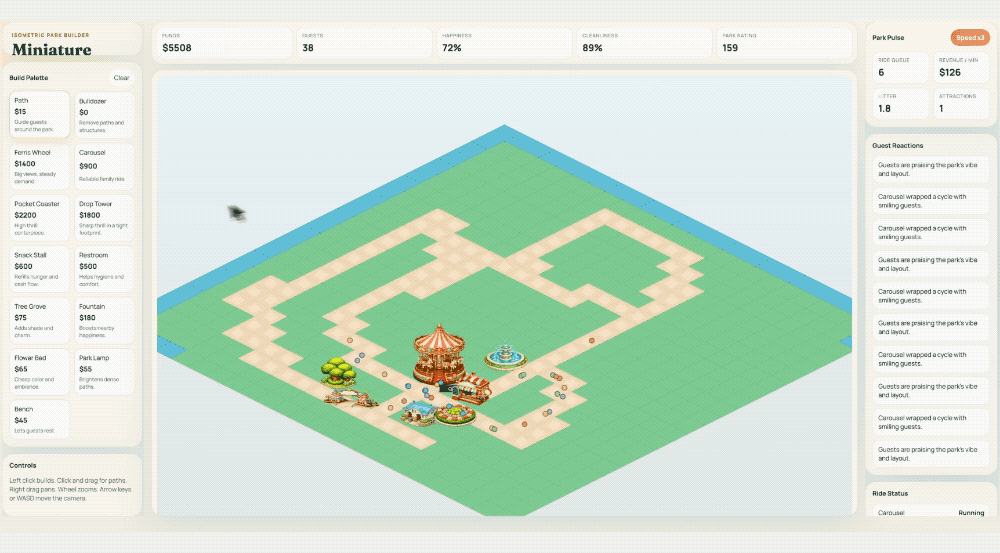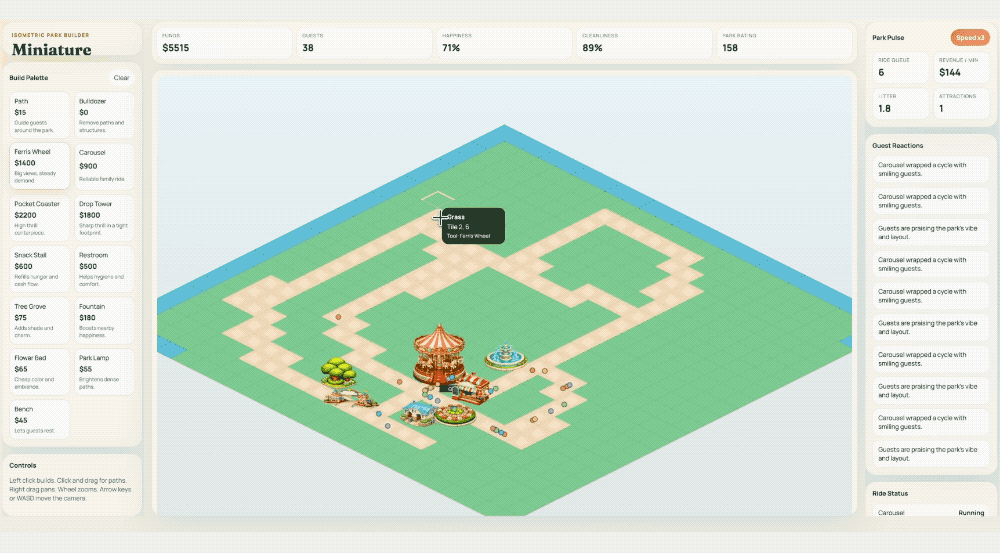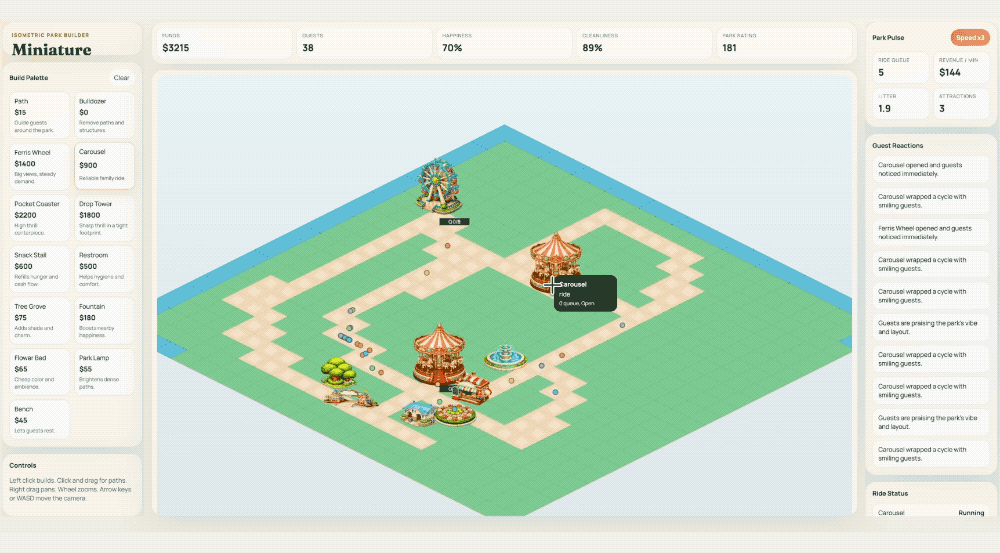
官方演示里用一句 Prompt 让它做了一个主题公园模拟游戏——从生成美术资源到编写游戏逻辑到自动 Playtest,一条龙。Cursor 的人说它"更自然、更果断了,遇到模糊问题不再反复纠结"。
Tool Search:给 Agent 省下近一半的"油钱"
搞 AI Agent 的开发者都知道一个痛点:你给模型挂了几十个工具(比如发邮件、查日历、读数据库),光是把这些工具说明塞进 Prompt 就要烧掉几万个 Token,而模型可能一个都用不上。
GPT-5.4 引入了 Tool Search 机制:不再一次性把所有工具定义全塞进去,而是给模型一份"工具清单",它需要用哪个再临时去查定义。
用 Scale 的 MCP Atlas 基准测试了 250 个任务:挂载 36 个 MCP 服务器,开启 Tool Search 后,总 Token 消耗减少了 47%,准确率不变。
Zapier 的 CEO 直接说 GPT-5.4 是他们测过的"最能坚持到底的模型"——别的模型半路放弃的任务,它还在继续搜。
安全这块也没落下——它很难对你撒谎
OpenAI 做了一个叫 CoT Controllability(链式思考可控性)的评测:看模型能不能在"思考过程"里故意隐瞒真实意图、糊弄监控。
结果是:GPT-5.4 的隐瞒成功率极低,大概只有 0.3%。
这其实是好消息。它说明你在"Thinking"面板里看到的推理过程,基本就是它真实的想法,不太可能"表面一套背后一套"。对于金融合规、法律审计这类对透明度要求极高的场景,这个特性比跑分数字管用得多。
价格与可用性
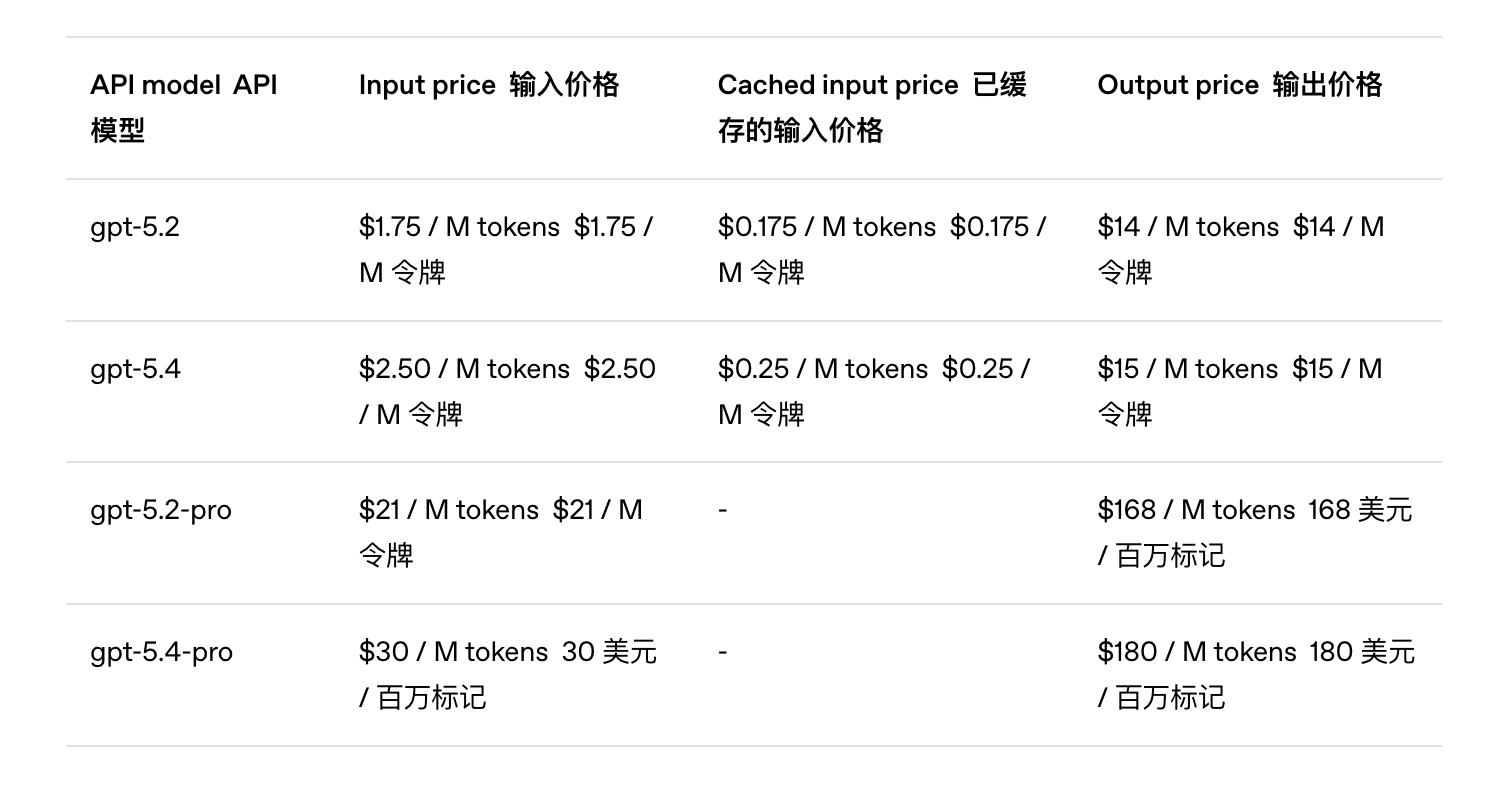
• GPT-5.4 标准版 API:输入 $2.50/百万 Token,输出 $15.00/百万 Token(缓存输入仅 $0.25)
• GPT-5.4 Pro API:输入 $30.00/百万 Token,输出 $180.00/百万 Token
• 对比 GPT-5.2:输入 $1.75,输出 $14.00——单价涨了,但官方说效率高了,总花费反而可能更少
• 272K Token 警戒线:超过这个长度的请求,计费翻倍。百万上下文窗口是有的,但别真的一口气塞满
• ChatGPT 用户:Plus / Team / Pro 用户已可使用 GPT-5.4 Thinking(替代原来的 GPT-5.2 Thinking)
• GPT-5.2 Thinking 保留至 2026 年 6 月 5 日退役
• Codex 中实验性支持 1M 上下文窗口
用户社区的真实声音
👍 社区盛赞 (The Good):
-
“它终于不会半路就忘了自己在干嘛了”:对于长达数十个步骤的复杂工程(如部署一套 K8s 微服务并对接后端),Reddit 开发者普遍反映它中途崩溃、忘记上下文规则的概率极低。
-
“中途打断”是一场救赎:这是社区呼声最高的 UX 更新。当 AI 在 Thinking 时走错方向(比如它决定用 Python 重写,而你只想它修改 TS 代码),直接打断并注入新指令,无需等待漫长的重写。
👎 社区痛点与争议 (The Bad):
-
令人咋舌的“分段式天价” (272K Penalty Bracket):这可以说是社区吐槽最多的点。虽然它号称有 1.05M 的上下文,但一旦你一次性提交超过 272K Tokens 的 Prompt,输入费用翻倍,输出直接翻 1.5 倍。开发者戏称这是“智商税隔离区”。
-
绝对响应速度较慢:大量 Reddit 网友指出,开启完整 Thinking 的 GPT-5.4 响应速度并不适合实时对话应用(如客服交互),它的存在意义是为了“需要思考 30 秒但能帮你省下三个小时工作流”的重型任务。
写在最后
回头看这次发布,最有意思的并不是某个跑分又刷新了多少。
是方向变了。
从 GPT-3 到 GPT-4,大家比的是"谁更聪明"。从 GPT-5 到 GPT-5.4,比的是"谁更能干活"。这个模型能操作你的桌面、能住进你的 Excel、能自己测试自己写的代码——它开始从"对话框里的顾问"变成"坐在工位上的同事"。
当然了,这个同事的工资不便宜。272K Token 以上翻倍收费这个设定,摆明了在说:想让我全力工作可以,但你得想清楚怎么合理安排我的工作量。
所以真正的竞争力,可能不再是"用不用 AI"的问题,而是"谁能最聪明地用好 AI"的问题。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)