智能体自进化论文-ICE agent框架
ICE框架:跨任务自进化的智能代理新范式 摘要:本文提出ICE框架,通过任务间经验迁移实现AI代理的自我进化。
概览
论文链接:https://arxiv.org/abs/2401.13996v1
ICE 框架是一种通过任务间自我进化来增强人工智能代理的适应性和灵活性的新策略。与专注于任务内学习的方法不同,ICE 促进任务之间的知识转移,实现真正的自我进化,类似于人类经验学习
论文中提出的场景的学习方法
1.失败后反思,在智能体执行任务失败后,让它生成反思内容,并把这些反思补充到模型的上下文语境中
2.提示词优化,系统自动调整和优化输入给模型的提示词(Prompt),好让模型能更精准地理解和执行指令
3.历史背景参考,将过去执行任务时的上下文信息检索出来,提供给模型作为参考,以生成更连贯、有效的回答
这些都被统一认为是任务内学习
与作者认为的自进化不同,提出跨任务的经验迁移,从而提出跨任务学习的概念
目前主要的 agent 设计框架是双阶段模式,规划加执行
面临的挑战
1.哪些内容值得记录为经验,
2. 如何标准化其格式以方便任务间学习,
3. 以及何时应用它们以供将来使用以提高任务的有效性和效率。
ICE 的三阶段设计
1.调查,为了找出究竟哪些历史经验是真正值得学习和参考的,系统会持续追踪每个被拆解出来的子目标的计划和当前状态,并且专门提取出那些成功完成的执行轨迹,
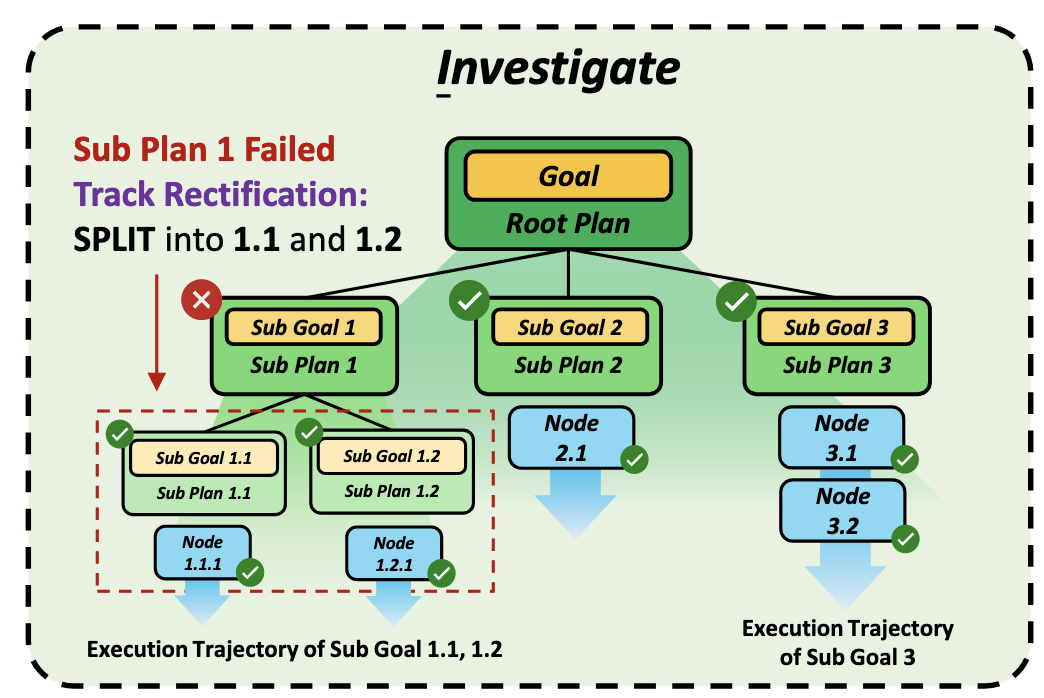
如图所示,G 为树根代表用户的最终目标 G1-G3 代表由最终目标拆分出来的第一层子目标,每个节点都有既定的里程碑,如果没有完成则会出发修正机制,拆分为更小的子任务 1.1 和 1.2,node1.1.1 则表示执行轨迹的第一个动作。
2.整合,为了将经验的格式标准化,使得未来的重复利用变得更加自动化和便捷,把原本复杂的计划树修剪掉失败的部分,变成一条线性的、只包含成功目标的工作流,将之前挖掘出来的执行轨迹,转化为一种叫有限自动机的“流水线 (Pipeline)”,从而让特定目的的操作可以被自动执行,把这些提炼好的工作流和流水线存入数据库,作为智能体长期的记忆。
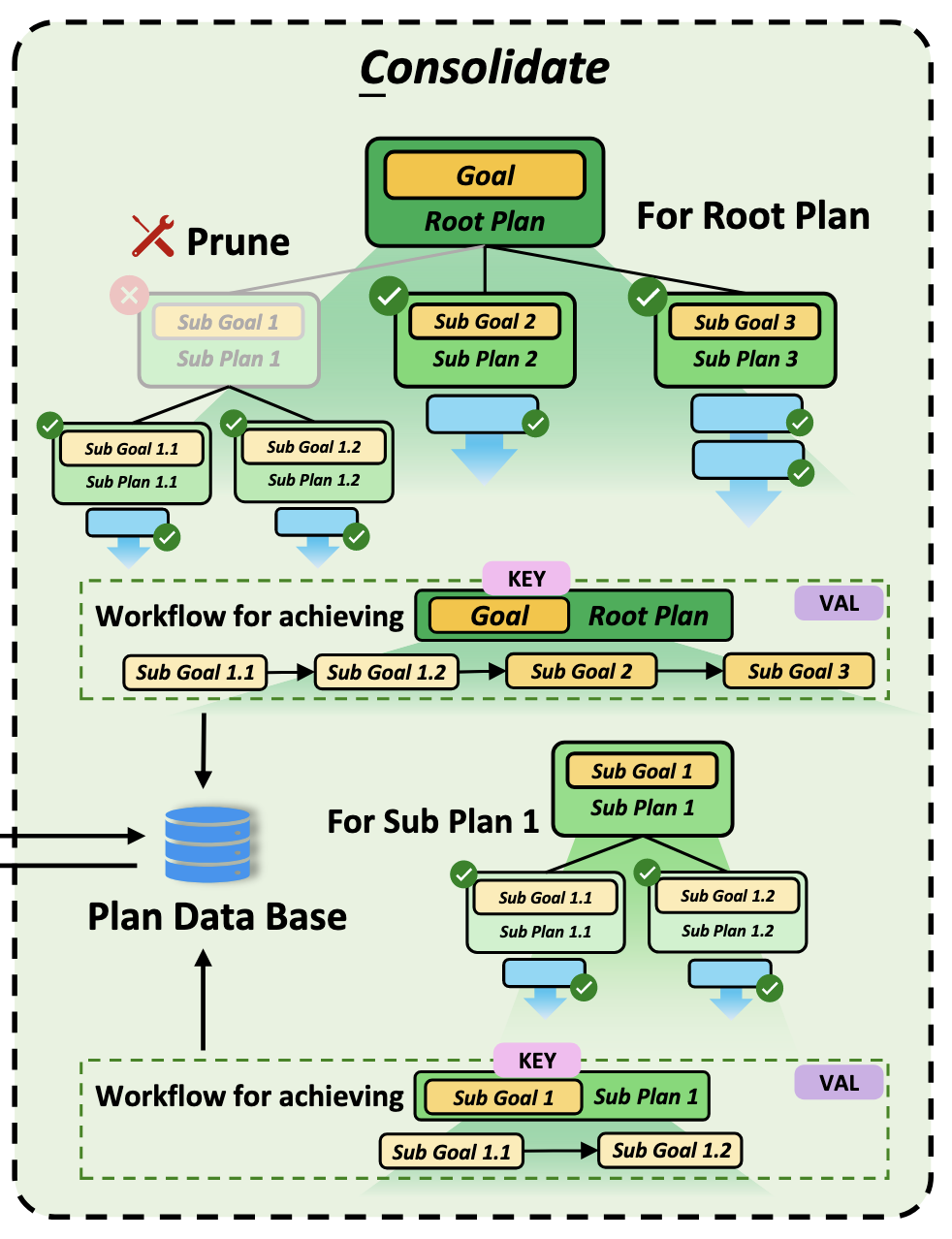
如图所示,完成目标 G 的过程中可以固化出两个经验,ICE不仅给最顶层的总任务做总结,还会给中间层级的子任务做总结,第一条工作流是描述最顶层的工作流,从 sub goal1.1 到 sub goal3,key 为总目标 G,第二条工作流是从 sub goal1.1 到 sub goal1.2,key 为子目标 sub goal1,val 为整个工作流,以完成键值对的形式打包
符号定义
W 整个工作流知识库
G^s 整个执行目标库
Gx 为目标
W_Gx 定义为成功完成目标 Gx 并固化后的工作流
G_leaf 代表叶子节点
T_G_leaf 代表完成G_leaf 的目标涉及到的执行轨迹,可能是多个操作的集合
G^new 全新的执行目标
3.知识利用
在面对全新目标 G^new 的时候,会首先根据这个新的目标去知识库通过余弦相似度去寻找过往相似经验,即图中的 retrieved workflow,执行计划失败后会进行两种检索,1. 父子点 G^new_x 的相似记录寻找,2.当前G^new_y 的相似记录寻找,同时对应两种解决方案,1. 依照经验当前目标 Gx,2.完成它的直接父节点目标并跳过 Gx
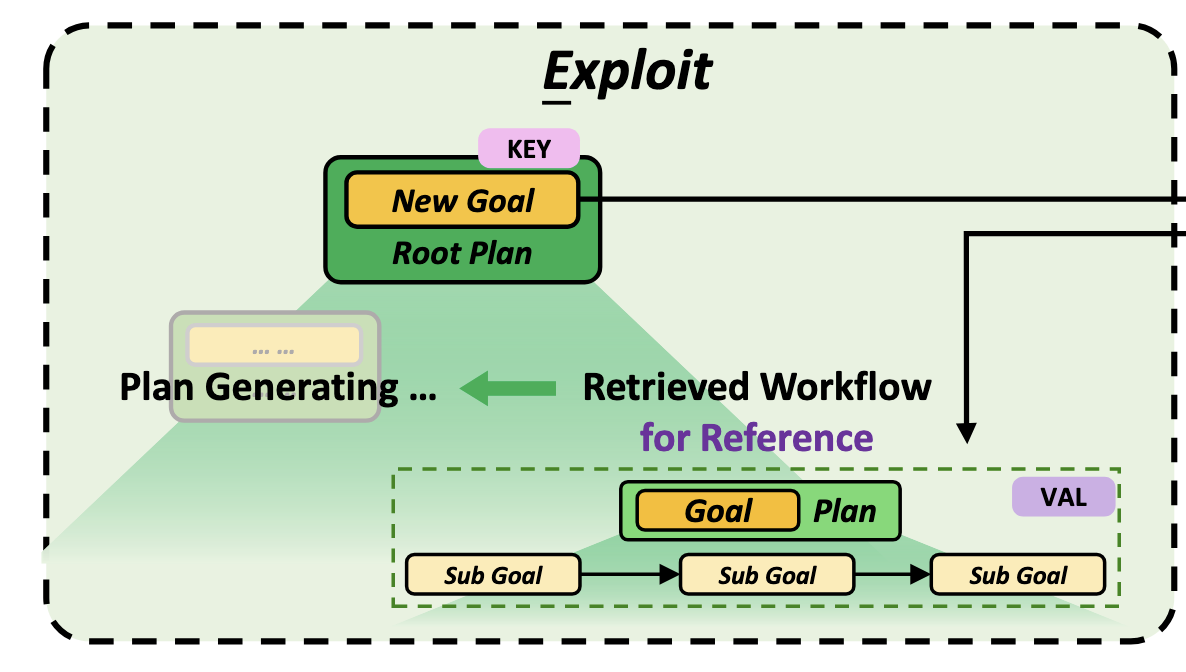
执行层自动机抽象
作者发现为了完成目标 Gx,使用 React 框架摸索出了一条成功的执行轨迹 T_Gx,由于ReACT 的每次推理都要耗费大量的 Token 和算力,如果每一步调用的工具名称和参数是固定的,直接把它固化成一个类似脚本的自动机
将执行轨迹 T_Gx 由一个新的符号表示
有一下定义
Q 代表具体的工具调用节点
代表节点间的边,即状态转移规则
状态转移函数
规定了从当前工具节点,根据什么规则,走到下一个工具节点,即当前状态通过什么条件会进行转移到某个状态
作者认为的自动机的优点在原本的 ReACT 模式下,智能体每做完一步,面对的是一个开放式的动作空间,随时可能“胡思乱想”导致出错 。变成自动机后,智能体在任何一个节点上,只能根据该节点的出度(Out-degree,即连出去的边)进行选择。这就把一个复杂的开放域生成问题,降维成了一个有规则约束的选择题,大大提升了执行效率和准确性
如果获得这个自动机?
论文中作者是用 gpt-4 将 T_Gx 转化为 A_Gx
气候搜索任务示例
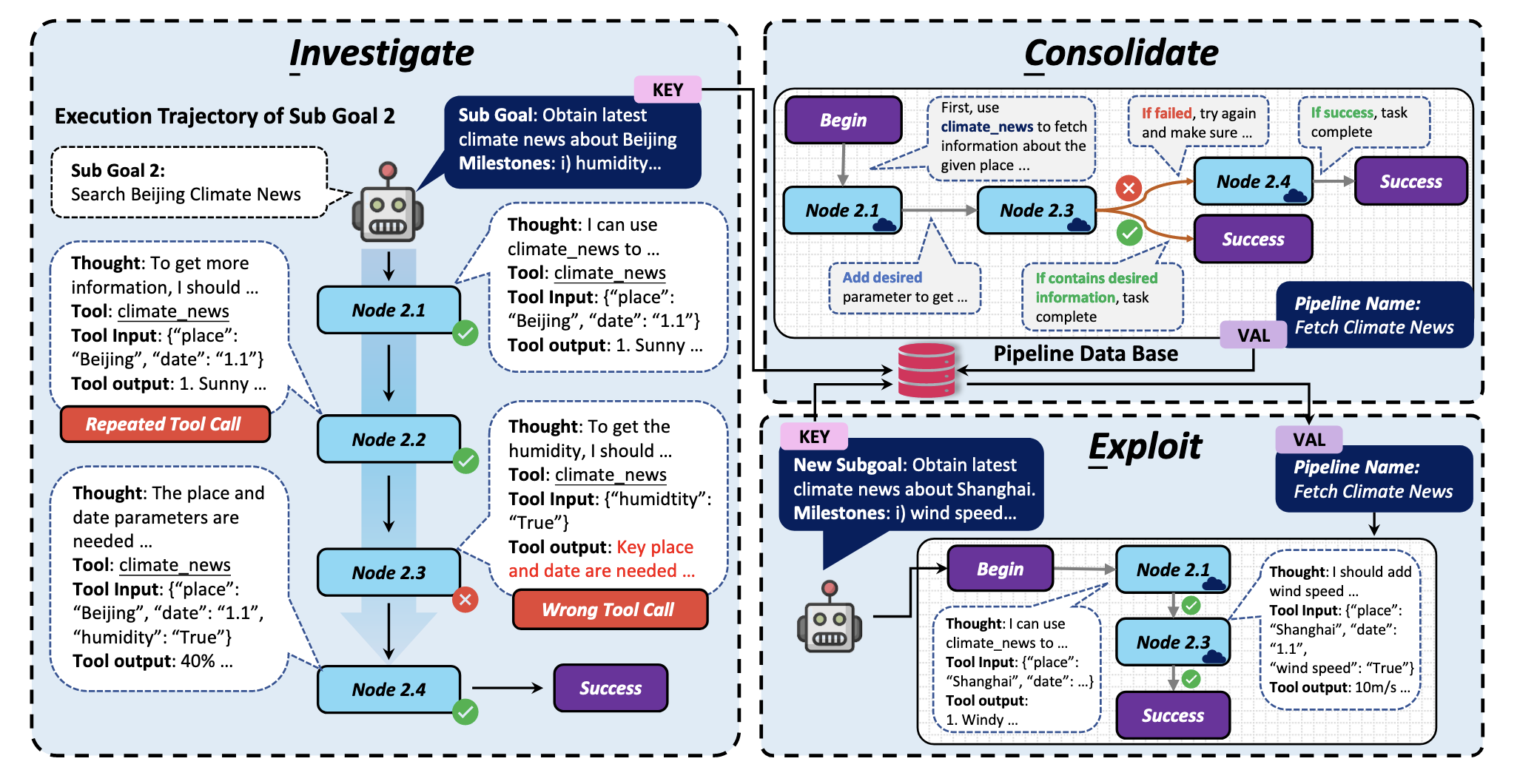
实验效果
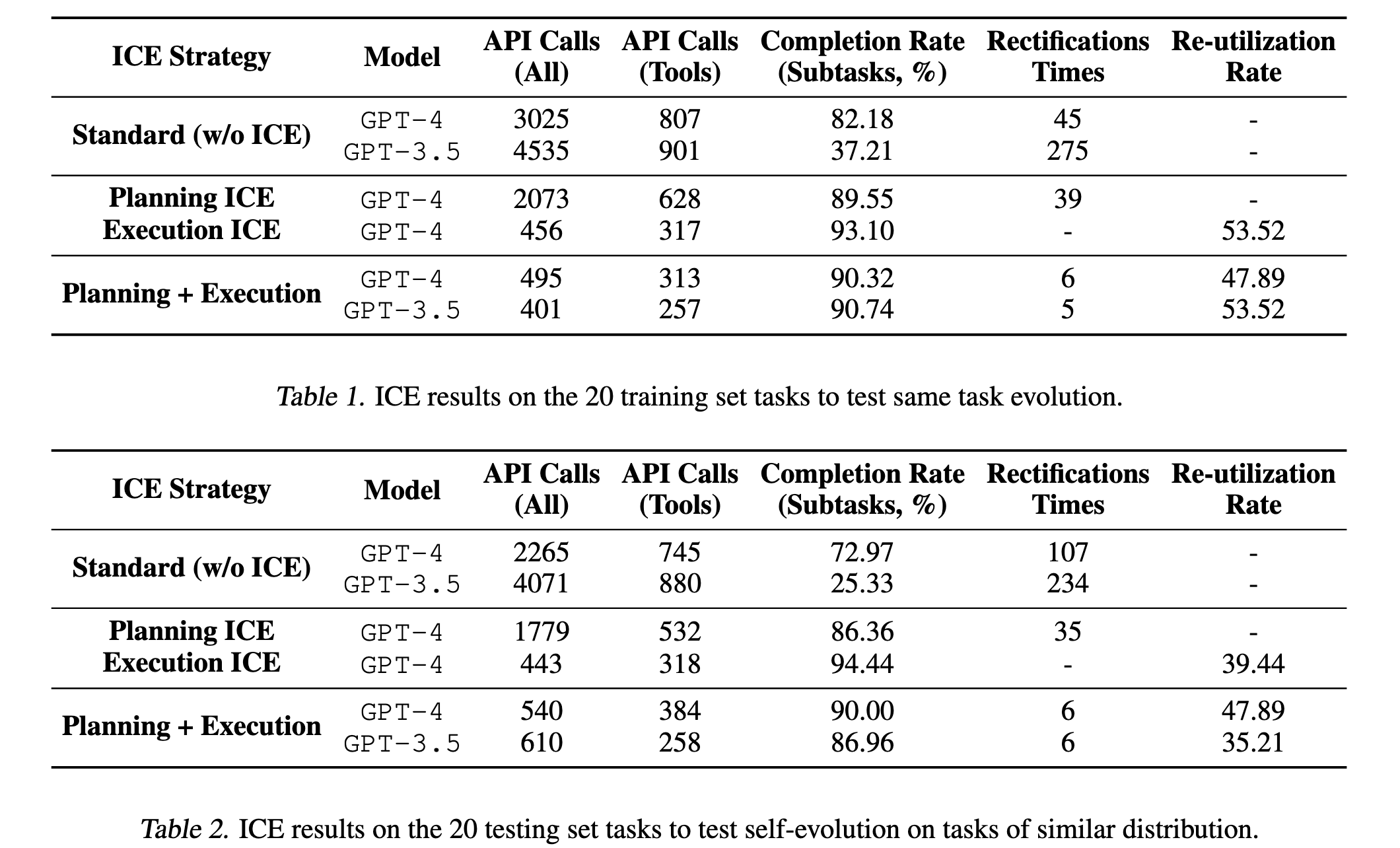
研究团队在 XAgent 框架上手动构建了 40 个涵盖旅行规划、数据分析等复杂场景的任务 。他们把这 40 个任务对半劈开:20 个作为训练集(让智能体去试错并攒经验),另外 20 个作为测试集(看看智能体能不能把经验举一反三)
1.api 调用次数减少
纯 gpt4 不加任何策略,有 api 调用 2265 次,如果使用完整的 ICE 框架,gpt4 的 api 调用降致 540 次,完成率从 72.79%升致 90%,复用率达到 47.89%
2.修正次数减少
纯 gpt4 有 107 次修正的次数,有 ICE 加持后修正次数只有 6 次
3.完成率提升
gpt3.5 在添加 ICE 后完成率超越纯 gpt4,以为可以在低成本的条件下媲美顶级智能体,具有商业落地价值
如果节省的 api 调用?
我的理解是这样,比如有经验规划一趟北京的旅途3天,新的任务是规划一趟去上海的旅途7天,按照经验已经有一套标准的自动化流程,此次新任务则不需要像 React 的工具寻路,因为 tools 已经在经验中给出,智能体只需要修改参数复用 tools,比如 search_spot('beijing')变为search_spot('shanghai'),节约了工具搜索选择的 api 调用,也节省了参数修正的反思次数,在传统框架中如果工具调用报错了,大模型需要再消耗一次 API 去把报错信息读一遍,反思一下,然后再尝试换个工具,而在 Pipeline 中,如果存在报错的可能,系统已经在边上写好了明确的建议和分支逻辑。大模型只需要做个简单的单选题(比如“报错了就走路线 B”),而不需要耗费大量 Token 去重新推理补救方案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)