Dataiku入门教程3-Data quality 数据质量
摘要:Dataiku DSS的数据质量功能教程介绍了如何通过自定义指标、质量规则和失败行提取来监控数据质量。操作包括创建列统计、常见值、百分位数等指标,设置语义有效性检查,以及使用Python探测器实现复杂逻辑。质量规则可跨数据集系统检查,失败行提取功能能定位问题数据。此外,数据血缘分析可追踪列级数据转换过程。这些功能支持从单元格到项目级的全面质量监控,但暂未集成到流程自动化中。

这里使用的data source是官方教程Data Quality
https://knowledge.dataiku.com/latest/automation/data-quality/tutorial-data-quality.html
Dataiku DSS Data quality
1. 操作步骤
Step1:创建自定义指标
(1)开始
在data preparation的过程中,可以双击已经与处理过或者还未处理的数据集,再点击metrics→compute all,可以计算默认指标(通常是column count and record count)
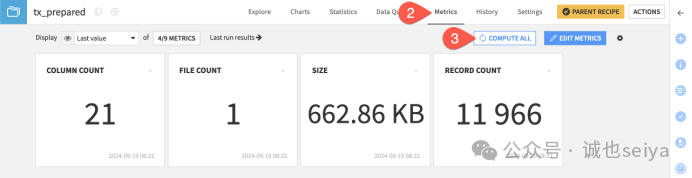
(2)接下来可以创建自定义指标。点击Edit Metrics。
可以看到能够针对Columns statistics (列统计)、 Most frequent values(常见值)、 Columns percentiles(列百分数)、Data validity(数据有效性)进行设置。
|
Columns statistics 列统计 主要用于了解数值列的分布范围和非数值列的填充情况 |
Min / Max (最小值/最大值) |
|
Avg / Sum (平均值/总和) |
|
|
Count (总数) |
|
|
Empty value count (空值计数) |
|
|
Std. dev. (标准差) |
|
|
Distinct value count (去重计数) |
|
|
Unique value count (唯一值计数) |
|
|
Histogram (直方图) |
|
|
Most Frequent Values 最常见值 |
Mode (众数) |
|
Top 10 values (前10位常见值) |
|
|
Top 10 values (with counts) (带计数的前10位常见值):不仅列出这10个值,还告诉你每个值具体出现了多少次。 |
|
|
Columns Percentiles 列百分位数 |
Median (中位数 / P50) |
|
P25 / P75 (下/上四分位数) P25:有 25% 的数据小于或等于这个值。 P75:有 75% 的数据小于或等于这个值。 |
|
|
Interquartile range (IQR, 四分位距):P75 - P25 |
|
|
Quartiles (四分位数汇总):一次性计算 P25、Median 和 P75 |
|
|
Data Validity 数据有效性 基于dataiku的“meaning”功能(自动识别某一列的内容意思) |
Meaning validity (语义有效性): Valid (有效):符合该列定义格式的数据量。 Invalid (无效):不符合格式的数据(例如在“日期”列里写了“张三”)。 Empty (空):未填写的数据。 |
比方说authorized_flag 的值应始终为 0 或 1,我们可以创建自定义的“最小值”和“最大值”指标来验证这一点。
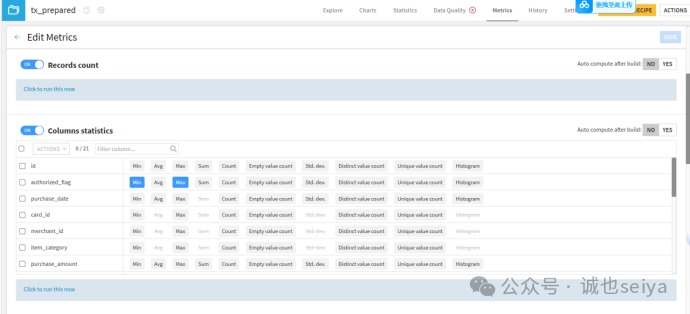
勾选框可以批量操作,点击多个字段→Actions→选择你想要的指标计算,但是不勾选直接点蓝也可以计算。
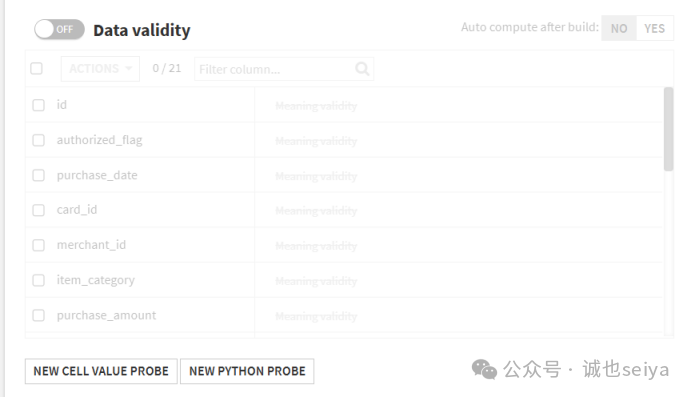
其它功能:
①New Cell Value Probe:单元格值探测器
Metrics通常是看一整列的平均值、最大值,而 Cell Value Probe 直接将数据集的值直接作为指标展示,并保留历史记录。
Example:数据集里有一行是专门用来记录“预期总预算”的,可以通过id或某个标签定位到这一行,提取 purchase_amount。这样你就能直接在 Metrics 界面看到这个特定的预算值,而不需要每次都去翻原始数据。
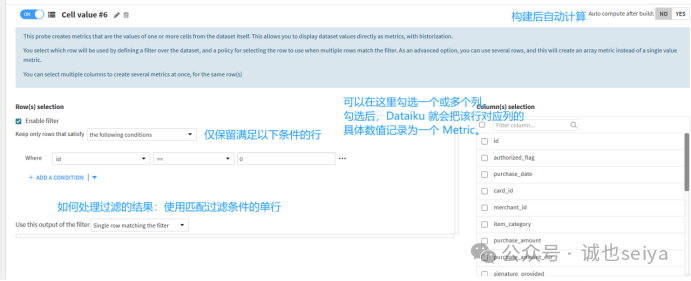
②New Python Probe (Python 探测器)
可以用于自己编写计算一些复杂的财务比率和非标准逻辑(比如“如果 A 列大于 100 且 B 列包含关键词 'Apple',则计算 C 列的加权得分”),应该也可以和外部数据交叉验证(对比当前数据集的某个值与外部 API 或另一个文件的值是否匹配,但是没测试过)
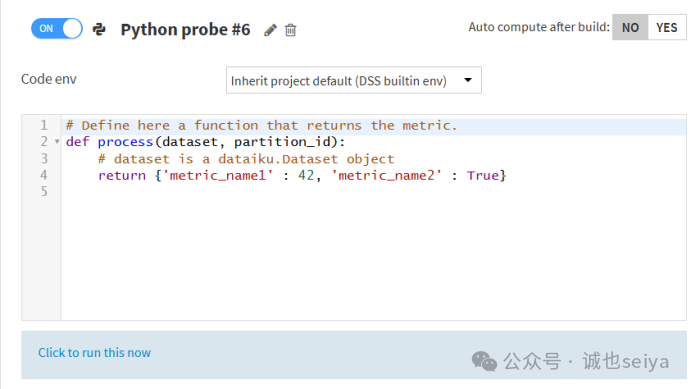
开启这些指标后,记得点击右上角的SAVE,并点击 "Click to run this now"。如果希望每次运行 Recipe后自动更新这些指标,可以把右侧的 Auto compute after build 设为 YES。
(3)显示指标:点击Edit Metrics 旁的返回按钮回到指标查看界面→点击 X/Y Metrics 查看所有可用指标→点击 Metrics available 旁的 Add all→点击 Save 将这些指标包含在显示列表中。
Step2:创建数据质量规则
虽然指标适合在处理项目时进行临时检查,但数据质量规则可以跨数据集、项目乃至整个Dataiku 实例执行系统性的质量检查。
(1)路径:数据集的Data Quality 选项卡
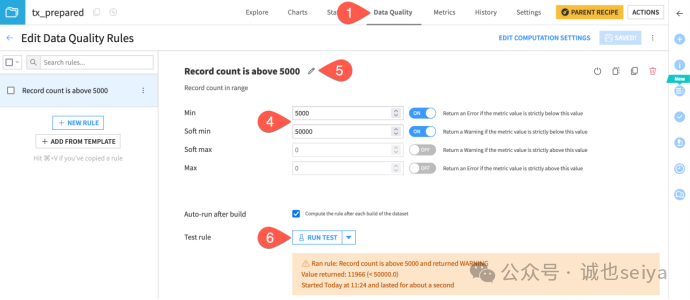
点击 Edit Rules或者+New rule,可以自己选择相对应的规则,比方说记录数据量是否在范围内、列最小值是否在范围内、列值不能为空否则报错等。
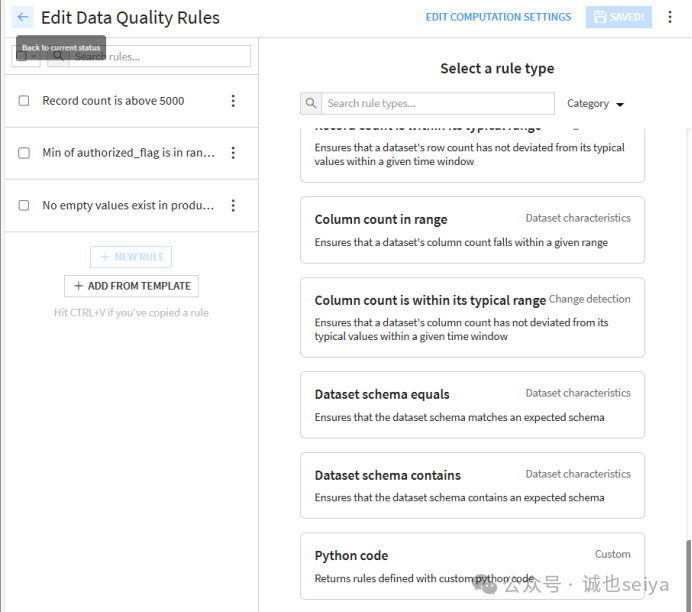
除了已有规则之外,也可以使用python自定义数据质量规则。
(2)查看数据质量
点击返回箭头回到Current Status (当前状态) 视图→点击 Compute All→注意 Monitoring (监控) 标志。只要你在数据集上创建了规则,监控默认开启
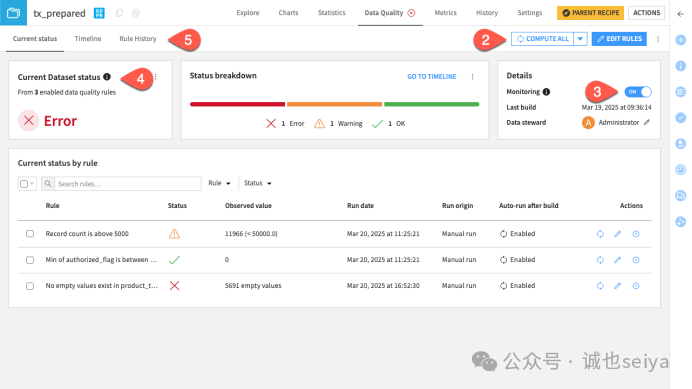
可以通过time line和rule history来看每天的指标状况与rule修改情况。
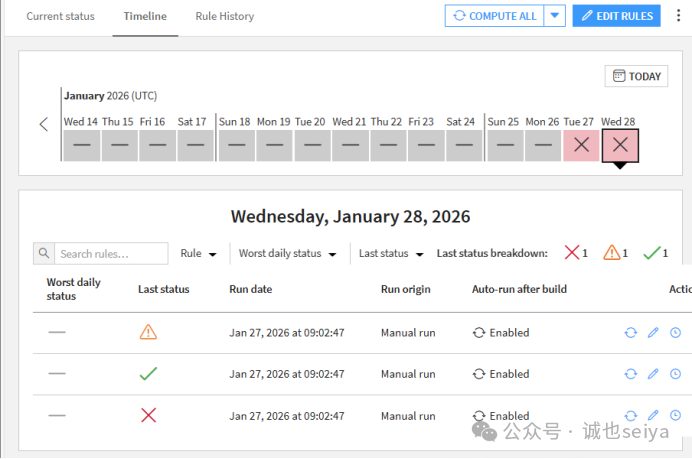
查看不同层级的质量:
|
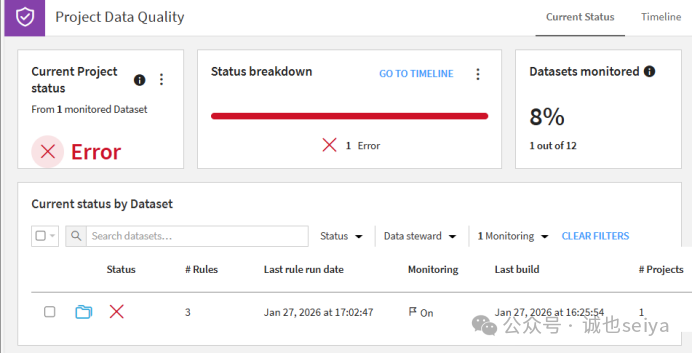
Project级 |
在 Jobs 菜单中选择 Data Quality(或按 g + q)。会看到整个项目的当前状态。 |
|
Example级 |
从顶部导航栏的 Waffle 图标 (九宫格) > Data Quality 进入,查看有权访问的所有项目的概览。 |
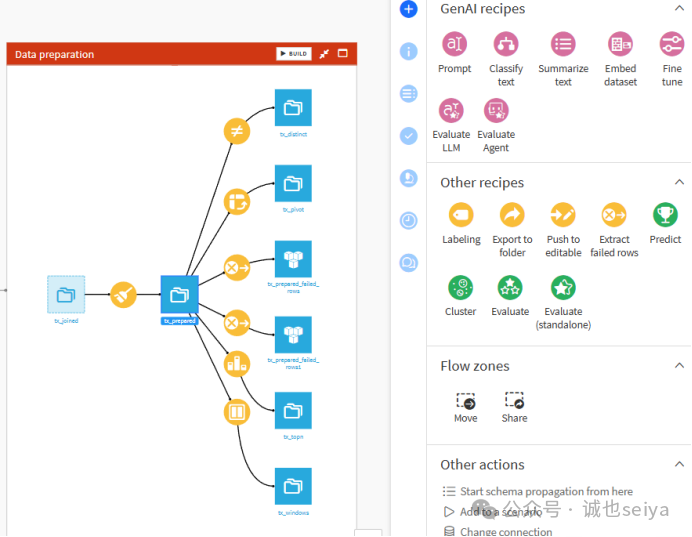
Step3:提取失败行
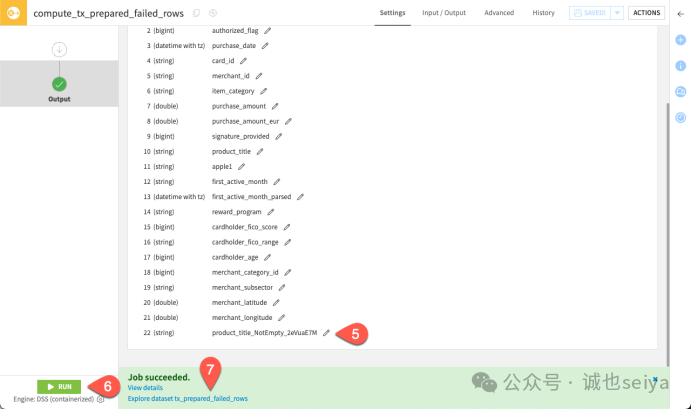
回到Flow,选择 tx_prepared 数据集→在右侧 Actions 面板的 Other recipes 下,选择 Extract failed rows (提取失败行)→点击 Create Recipe。该操作会增加一个新列来显示规则状态。→点击 Run 并在运行结束后探索生成的 tx_prepared_failed_rows 数据集。
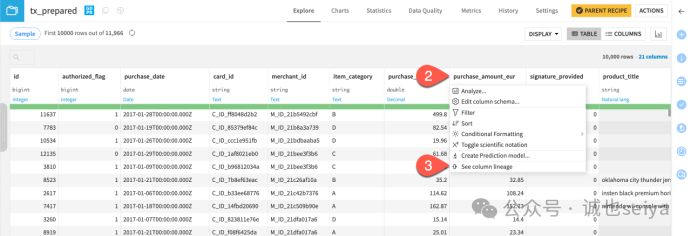
Step4:查看Data Lineage
可以帮助追踪数据在pipeline中的转换过程,诊断上游问题或评估下游影响。
打开 tx_prepared 数据集,点击 purchase_amount_eur 列标题→选择 See column lineage→在 Data Lineage 视图中,
你可以看到该列是由 purchase_date 和 purchase_amount 通过 Prepare 步骤创建的,并被下游的 tx_windows 使用。
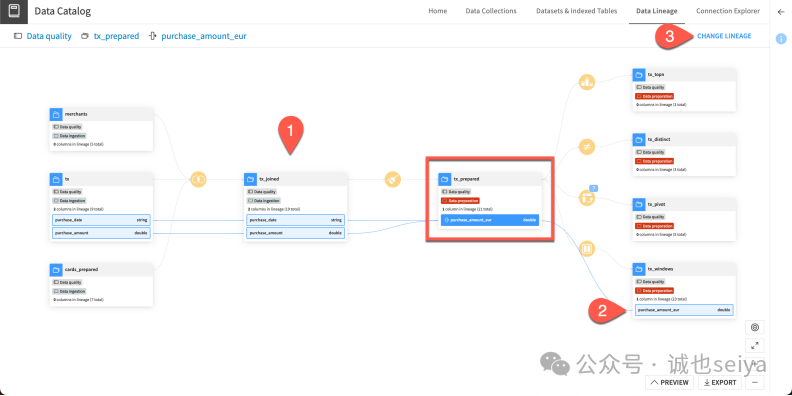
沿着左边的蓝线,可以看到这列是在Prepare recipe中创建的,输入列尾purchase_date和purchase_amount。
沿着右侧的蓝线,可以看到该列被用于一个下游数据集,tx_windows。
data quality目前只探索到了可视化的功能,只能说目前更方便看,之后再试试能不能用到flow里。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)