记录每天的学习内容2026.3.5--详细看了transformer源码(AI总结)与ai问答全部对话在github:https://github.com/101per/learning.git
规则:用维度等于类别总数的二进制向量表示离散类别。仅对应索引位置为1(激活),其余全为0(抑制)。示例:3 个类别(红、黄、蓝) $\to$ 3 维向量。红=[1,0,0], 黄=[0,1,0], 蓝=[0,0,1]。权重共享要分清“目标侧绑定”(通用)和“跨语言共享”(仅限同源语言)。One-Hot是理解 Embedding 查找机制的基石。Dropout的核心是倒置实现和打破共适应。代码层面明
参考:
transformer源码借鉴https://github.com/dt-3t/Transformer-en-to-cn
根据文档内容,今天的学习内容非常详尽,涵盖了从 Transformer 模型的核心理论(权重共享机制) 到 底层数学基础(One-Hot),再到 正则化技术(Dropout) 以及 PyTorch 代码实现的每一个细节。
以下是无遗漏、深度解析版的学习总结:
一、核心难点突破:Transformer 中的权重共享机制 (Weight Tying)
1. 原句的技术拆解
文档首先拆解了 Transformer 论文中的经典语句:“In our model, we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation”。这涉及三组权重的共享:
-
源语言 Embedding 层:Encoder 输入,形状
[V_src, d_model]。 -
目标语言 Embedding 层:Decoder 输入,形状
[V_tgt, d_model]。 -
Pre-softmax 线性变换层:Decoder 输出投影,形状
[d_model, V_tgt](通常使用 Embedding 权重的转置 $W^T$)。
2. 两层共享逻辑的本质区别
文档强调必须将这套机制拆分为两个独立的技术逻辑,因为它们的适用边界完全不同:
逻辑 A:目标侧 Embedding 与 Pre-softmax 层的权重绑定(通用优化)
-
适用范围:所有语言对(无论中英还是欧英),是 Transformer 的标准操作。
-
原理支撑
:
-
数学自洽:Embedding 是“ID $\to$ 向量”的映射 ($x @ W$),Pre-softmax 是“向量 $\to$ ID 概率”的逆映射 ($h @ W^T$)。两者互为逆运算,共享权重保证了语义空间的闭环。
-
语义直观:预测下一个词,本质是计算当前隐藏态与所有词向量的内积,内积越大概率越高。
-
工程收益:大幅减少参数量($V{tgt} \times d{model}$),提供强正则约束,防止过拟合,尤其在低资源场景下效果显著。
-
逻辑 B:源语言与目标语言 Embedding 层的跨语言共享(特定场景)
-
适用范围:仅限具有天然形态/语义对齐的语言对(如欧洲语系 <-> 英语)。
-
核心前提:源语言和目标语言必须能构建出真正共享的联合词表(Joint Vocabulary),使得同一个子词在两种语言中代表相同的语义。
-
深度对比分析(欧洲语系 vs 中文):
维度 欧洲语系 <-> 英语 (适合共享) 中文 <-> 英语 (不适合共享) 书写体系 同属拉丁字母,基础单元一致 汉字 (语素文字) vs 拉丁字母,无重叠 词汇同源性 同源词占比极高 (如 information),共享大量词根/词缀 同源词<1%,无形态对齐 联合词表有效性 Joint BPE 能训练出真正的跨语言共享子词 (如 "-tion") 联合词表仅是两个独立词表的拼接,无实质共享 语言学结构 均为屈折语,句法结构相似 (SVO) 孤立语 (中文) vs 屈折语 (英语),逻辑差异大 工程结果 参数量减少,实现跨语言语义迁移 参数量未减,强行共享反而引入噪声,降低表达能力 -
结论:欧洲语系共享是利用词根同源性的“天然桥梁”;中英共享则是强行将两个不兼容的语义空间塞入同一矩阵,完全没必要甚至有害。
二、基础概念夯实:One-Hot 编码 (独热编码)
1. 核心定义
-
规则:用维度等于类别总数的二进制向量表示离散类别。仅对应索引位置为 1(激活),其余全为 0(抑制)。
-
示例:3 个类别(红、黄、蓝) $\to$ 3 维向量。红=[1,0,0], 黄=[0,1,0], 蓝=[0,0,1]。
2. 在 Transformer 中的关键作用
-
Embedding 层的输入基础
:
-
输入 $x$ 是词的 One-Hot 向量。
-
计算 $x @ W$ 本质上不是矩阵乘法,而是查找操作:直接取出权重矩阵 $W$ 中对应索引的那一行向量。
-
作用:将高维稀疏的 One-Hot 转化为低维稠密的语义向量。
-
-
Pre-softmax 层的输出对应
:
-
输出 Logits 的维度与 One-Hot 向量一致。
-
Softmax 后得到概率分布,预测结果即为概率最高位置对应的 One-Hot 索引。
-
3. 优缺点深度剖析
-
优点:简单无偏(无数值大小顺序偏见),实现零成本,适配传统机器学习模型。
-
致命缺陷
(为何不能直接用作词向量):
-
维度灾难:词表越大维度越高(几十万维),极度稀疏,计算存储效率低。
-
语义正交性:任意两个不同词的向量内积为 0,无法表达“猫”和“狗”的语义相似性。
-
泛化差:无法处理词表外(OOV)词汇。
-
-
易混淆区分:不同于标签编码(Label Encoding,如 小学=0, 中学=1),One-Hot 避免了人为引入数值大小关系。
三、正则化核心技术:Dropout
1. 核心做法与工业界标准
-
基本逻辑:训练阶段按概率 $p$ 随机将神经元输出置 0,阻断梯度更新。
-
两种实现方式
:
-
原始 Dropout:训练置 0 不缩放;推理时权重乘以 $(1-p)$。(已极少使用)
-
倒置 Dropout (Inverted Dropout)
:
主流框架(PyTorch/TensorFlow)默认方案
。
-
训练时:置 0 后,对保留的神经元输出除以 $(1-p)$ 进行缩放,保持期望不变。
-
推理时:直接关闭 Dropout,无需任何额外操作,部署更便捷。
-
-
-
参数细节:$p$ 是丢弃概率(如 $p=0.1$ 丢 10% 留 90%)。Transformer 中常用 $0.1 - 0.3$。
2. 四大底层原理(为什么有效?)
-
集成学习视角:每轮训练采样一个子网络,等效于训练了指数级数量的子网络集成,推理时相当于加权平均,降低泛化误差。
-
打破共适应 (Co-adaptation):防止神经元抱团拟合噪声,强迫每个神经元学习不依赖他人的鲁棒特征。
-
引入随机噪声:作为一种灵活的正则约束,防止模型死记硬背训练数据细节。
-
工程收益:训练时减少部分计算量。
3. 在 Transformer 中的应用位置
-
Embedding + 位置编码输出后。
-
Multi-Head Attention 输出后(残差连接前)。
-
FFN 中间激活层输出后。
-
Attention 权重矩阵上(Attention Dropout)。
4. 关键规范与误区
-
红线:仅在训练开启,推理必须关闭 (
model.eval())。 -
误区纠正:Dropout 不是永久删除神经元;不会提升训练集精度(反而可能轻微下降),核心收益在测试集泛化能力;$p$ 是丢弃率而非保留率。
四、代码实现细节全解析 (PyTorch)
1. 自注意力机制 (Self-Attention) 的 QKV 初始化
-
Encoder 中
:
self.self_attention(enc_inputs, enc_inputs, enc_inputs, mask)
-
含义:Q, K, V 完全相同,均源自
enc_inputs。 -
目的:让序列内部每个 token 都能关注到序列中的所有其他 token,提取上下文信息。
-
-
Decoder 中
:
-
自注意力层:Q, K, V 均源自
dec_inputs(屏蔽未来信息)。 -
交互注意力层 (Enc-Dec Attention):Q 源自 Decoder 输出,K, V 源自 Encoder 输出 (
enc_outputs)。目的是让解码器关注编码器的语义表示。
-
2. Embedding 层 (nn.Embedding) 深度解读
-
代码:
self.embedding = nn.Embedding(input_dic_max_index, d_model) -
参数解析
:
-
input_dic_max_index:词汇表大小(最大索引 + 1)。例如英语词典中所有单词索引的最大值加 1。 -
d_model:向量维度(如 512)。
-
-
工作机制
:
-
创建一个形状为
[vocab_size, d_model]的可训练权重矩阵(查找表)。 -
输入整数索引,输出对应的行向量。
-
-
训练方式(重要澄清)
:
-
非预训练:词向量不是加载 Word2Vec 或 GloVe 等预训练权重。
-
随机初始化:初始值为随机数。
-
端到端学习:在翻译任务训练过程中,词向量随模型参数一起通过反向传播不断更新,最终学习到符合当前任务的语义表示。
-
3. 编码器与解码器的独立性
-
独立嵌入层:Encoder 处理源语言(如英语),Decoder 处理目标语言(如中文)。两者拥有独立的 Embedding 层,因为词表不同、语言特性不同。
-
双向翻译问题
:若想从“英译中”改为“中译英”,
不能
简单交换 Embedding 权重。必须:
-
重新准备中->英平行语料。
-
重新构建中->英文词表。
-
重新训练整个模型(或训练一个全新的双向模型)。
-
4. Mask 矩阵的合并逻辑
-
背景:Decoder 的自注意力层需要同时满足两个遮蔽条件。
-
两个 Mask
:
-
Padding Mask:遮蔽填充符(PAD),避免无效计算。
-
Sequence Mask (Subsequent Mask):上三角矩阵,遮蔽未来信息(防止偷看)。
-
-
合并代码
:
dec_self_mask_sign = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0)
-
逻辑:两矩阵相加,只要任一位置为 1(需遮蔽),和即大于 0。
torch.gt(..., 0)将其转为布尔掩码。实现了“或”逻辑的遮蔽。
5. 输出投影层 (nn.Linear)
-
代码:
self.to_dic = nn.Linear(d_model, target_dic_max_index, bias=False) -
作用
:
-
将 Decoder 输出的 $d_model$ 维向量(如 512 维)映射回词表大小维度(如 30000 维)。
-
输出 Logits,经 Softmax 后得到每个词生成的概率。
-
数学上常与 Embedding 层权重共享(转置关系)。
-
6. 词表 (Vocabulary) 的性质
-
非固定/无国际标准:词表完全取决于训练数据和预处理策略。
-
构建方式
:
-
统计训练语料中的词/子词。
-
可使用 BPE、SentencePiece 等子词算法处理未登录词 (OOV)。
-
不同语言对(英 - 中 vs 英 - 法)有完全独立的词表文件。
-
-
代码体现:在
data.py中通过读取.vocab.tsv文件动态构建字典 (en_dic,cn_dic)。
五、总结
今天的课程不仅解释了“怎么做”(代码实现),更深入剖析了“为什么”(理论原理)和“什么时候做”(适用边界):
-
权重共享要分清“目标侧绑定”(通用)和“跨语言共享”(仅限同源语言)。
-
One-Hot 是理解 Embedding 查找机制的基石。
-
Dropout 的核心是倒置实现和打破共适应。
-
代码层面明确了 QKV 的来源差异、Embedding 的随机初始化与独立训练、Mask 的双重逻辑以及词表的自定义性质。
这些知识点构成了从理论到落地 Transformer 模型的完整闭环。
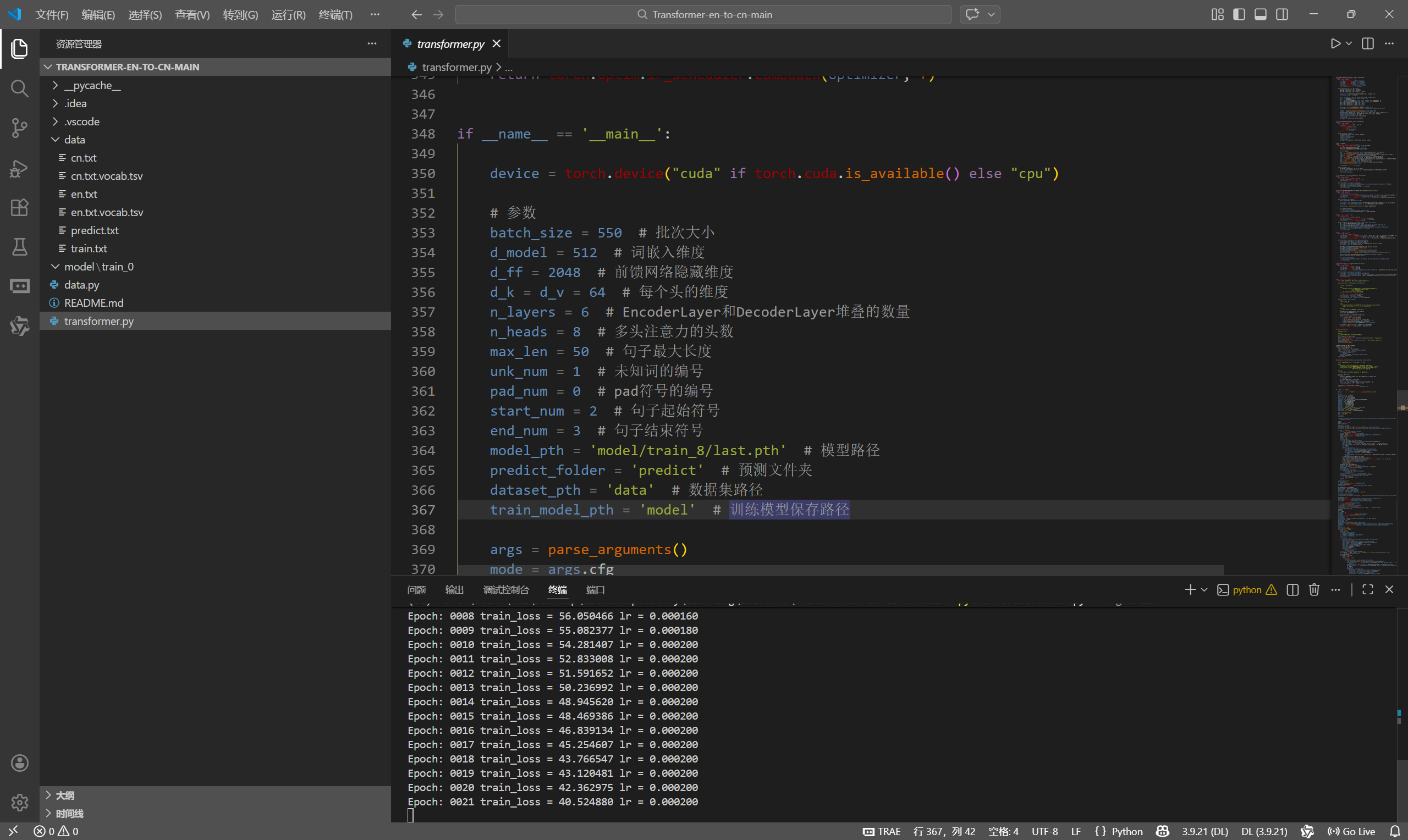
源码运行记录

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)