一个“白嫖友好”的 AI 语音 + 图片 + 视频项目,完全免费用起来
这个项目的初衷,就是做一个真正能被非技术同学用起来的 AI 创作小站打开浏览器,注册一个账号,就能直接体验各种语音、图片、视频能力;不需要自己搭环境、写脚本、查接口文档;用顺手了,你可以把它当成日常创作工具,也可以把它当成以后做正式产品的雏形。如果你在使用过程中有任何想法(比如希望多加哪些页面、增加哪些玩法)。
1项目地址:http://1.12.49.218/dream
多模态应用的系统实践记录
这篇文章主要从技术实现和系统设计的角度,简单记录一个多模态 Web 小系统:
- 后端集成文本转语音(TTS)、图像生成、视频生成、多模态对话等能力;
- 前端提供统一的操作界面,支持登录、任务提交、状态轮询和结果预览;
- 主要用于个人实验、项目 Demo 和小规模多用户体验。
相比“模型层”的论文和开源仓库,这个项目更关心的是:如何把多模态能力做成一个真正可用的 Web 应用,覆盖从鉴权、队列、状态管理到前端交互的整条链路。
一、系统目标与整体思路
从一开始,这个小系统只设定了几个朴素的目标:
- 统一入口:把语音合成、图像生成、视频生成、多模态对话放到同一个 Web 界面,而不是一堆零散脚本;
- 简单鉴权:用最轻量的方式做登录/鉴权,保证基础安全性的同时降低接入成本;
- 可观测:每一个任务都有清晰的生命周期(排队、处理中、完成、失败),前端可以友好展示;
- 易于扩展:后续如果要挂接新的能力(例如其它 API 或自研模型),不需要大改整体结构。
因此,整体上采用了一个非常典型的「前后端分离 + 任务队列 + 模型推理服务」的架构。
二、功能模块拆分
系统从用户视角大致可以分成四类能力,对应前端的几个主页面。
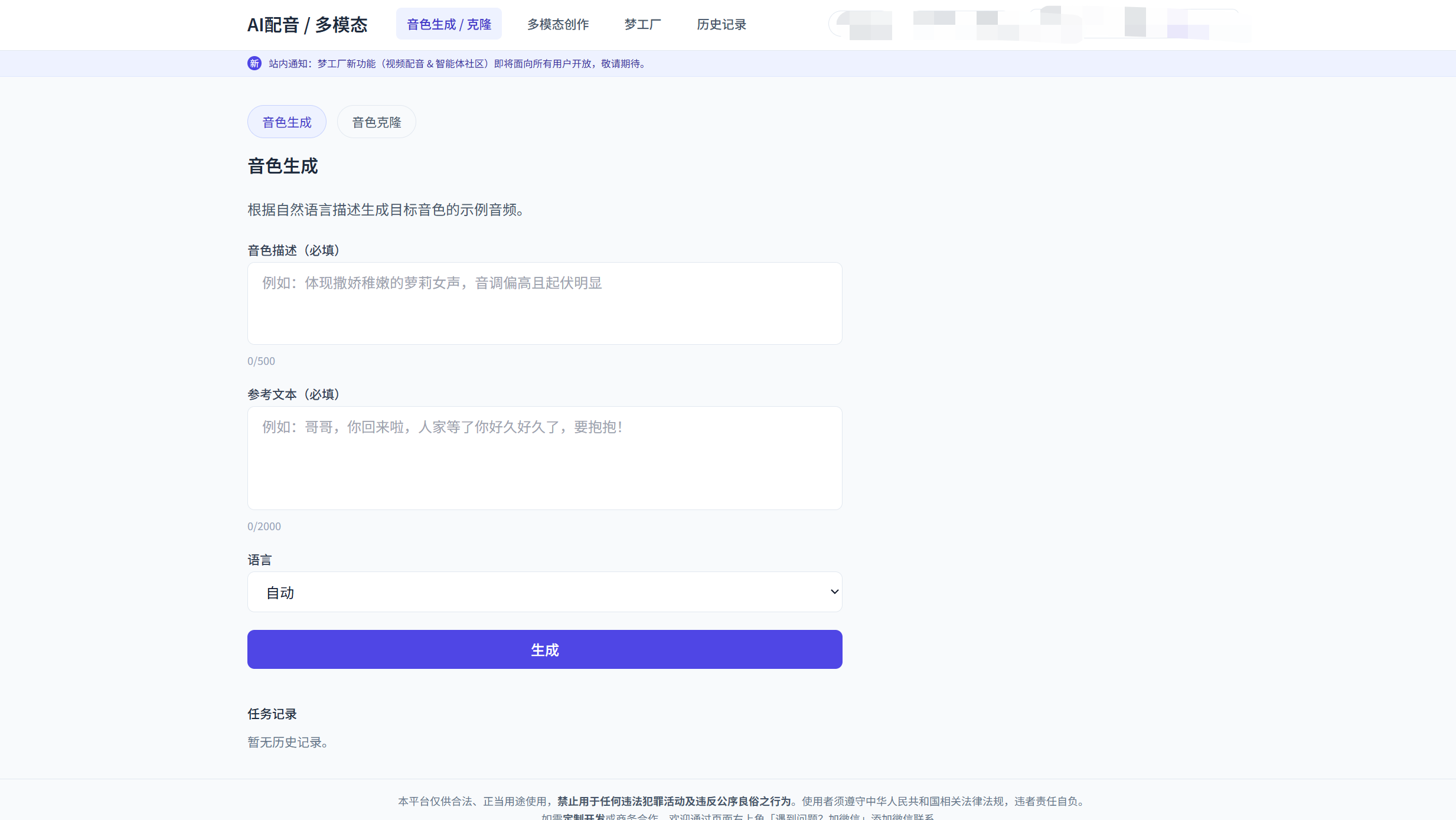
1. 文本转语音(TTS)
核心能力是:
- 接收文本、语言和简单的风格描述;
- 在后端调用语音合成组件,生成音频文件;
- 前端提供在线播放和下载。
这一块更关注的是「接口设计」而不是「具体模型细节」,例如:
- 生成参数(采样率、解码策略等)封装在后端;
- 任务记录中只存储必要的元信息和结果路径,便于审计和清理。
2. 音色风格与“角色声音”
在语音合成的基础上,进一步抽象出“角色声音”的概念:
- 用户通过一段自然语言描述来指定目标风格;
- 系统在后台将该描述与后续文本一起传入 TTS 组件;
- 多次调用时复用同一套描述,从而在体验上形成“同一个角色在说话”的感觉。
工程层面,这只是多了一个 instruct/description 字段,但对上层使用方式影响很大:可以做配音角色预设、多角色对话等更复杂的玩法。
3. 图像 / 视频生成
图像和视频部分没有引入额外的复杂流程,而是尽量与语音任务保持一致:
- 统一的任务提交流程:文本描述 + 若干配置参数;
- 同样走后台队列,避免一次性高并发直接压垮外部服务或本地资源;
- 结果统一落盘,前端通过 URL 访问。
这样做的好处是:前端只需要关心「轮询状态 + 展示结果」,后端可以自由切换具体实现(本地推理或第三方 API)。
4. 多模态对话
多模态页面主要承载两类需求:
- 纯文本对话:便于快速验证一些 NLP 能力或做解释说明;
- 图文结合:上传图片并附带问题,让后端调用视觉+语言模型产出分析结果。
这里的设计原则同样是“接口尽量简单”,例如:
- 图片统一转存到后端,再以文件路径形式传入模型;
± 聊天记录保存在数据库中,便于前端恢复上下文。
三、后端设计:鉴权、队列与任务管理
后端用一个较轻量的 Web 框架实现,主要包含三部分。
1. 鉴权与用户管理
- 采用邮箱注册 + 验证码的方式创建账号;
- 登录后发放 JWT,业务接口统一校验;
- 提供基础的密码修改和用户信息查询接口。
这套方案实现成本低,但足以支撑一个小型体验系统,后续如果要接企业登录也有扩展空间。
2. 任务队列与并发控制
所有“需要调用模型或外部多模态服务”的操作都被抽象为任务:
- 任务表记录用户、类型(TTS / image / video / vision)、参数、状态、结果路径等;
- 内部用一个队列串行处理重型任务,避免 GPU 资源和外部 API 调用被打满;
- 每个任务有明确的超时时间,超时会标记为失败并写入原因。
对于前端来说,只暴露三类接口:
submit:提交任务并拿到task_id;status:轮询状态和排队信息;result:在任务完成后获取文件流或结果数据。
3. 结果存储与清理
所有生成的音频、图片、视频都按任务维度进行目录划分:
{root}/{task_id}/result.xxx的简单结构便于溯源和清理;- 后台可以按时间或容量策略定期清理过期结果,保证磁盘可控。
四、前端实现:路由与交互细节
前端采用常见的单页应用架构,主要关注以下几点:
- 路由划分:登录/注册、TTS、图像/视频、多模态对话、任务历史、个人中心等;
- 鉴权处理:未登录访问业务路由时统一重定向到登录页;
- 任务轮询:每隔固定时间请求一次
status,根据状态更新 UI; - 表单校验:对文本长度、上传文件大小/格式等做基础检查,避免明显的错误打到后端。
视觉层面没有刻意做成“营销页”,而是偏向工具型页面:表单 + 状态卡片 + 播放/预览区域,便于后续接入更多能力。
五、几个典型的技术使用场景
从工程实践角度,这个小系统可以复用到很多场景,例如:
-
AI 配音 / 视频配音流水线的 Web 前端:
后端只要接上自己的 TTS 模型或服务,这套队列与任务管理逻辑基本可以直接复用。 -
AI 动漫 / 虚拟角色工程的声音子系统:
通过“描述 + 文本”的接口,可以较容易地为不同角色配置独立的合成风格,前端再叠加角色管理即可。 -
多智能体对话或广播剧 Demo 的基础设施:
把多角色对话脚本解析成多条 TTS 任务,利用本系统的任务管理和结果存储能力,就能快速得到一套音频素材。 -
内部多模态能力展示台:
如果团队内部有若干模型或 API,需要一个统一入口给产品/运营/非技术同学体验,这个项目可以作为集成壳。
六、一些实践中的取舍
在实现过程中,有几个刻意做“简单化”的点:
- 没有上复杂的分布式队列,而是用单进程队列先跑通流程;
- 数据库选了轻量级实现,方便在不同环境快速部署和迁移;
- 模型和多模态能力都通过清晰的接口层封装,便于以后替换实现。
这些取舍的出发点都是:先保证端到端的闭环可用,再考虑扩展性和性能优化。对于个人项目或小团队验证想法来说,这往往是更现实的路径。
七、结语
如果你已经有自己的 TTS / 图像 / 视频 / 多模态模型或 API,这个项目可以作为一个比较完整的「落地样板」:
- 前后端分离、鉴权、队列、任务生命周期这些通用问题都已经走了一遍;
- 在此基础上替换具体能力实现,就能比较快搭出一个可演示、可试用的在线系统。
后续如果有机会,会考虑补充更多关于性能调优、多实例部署以及更细粒度权限控制的实践记录。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)