【AI Agent实战】 0 成本视频处理全流程:ffmpeg + whisper 实现去水印、双语字幕、品牌片尾 | 实战SOP
这篇文章详细介绍了如何使用ffmpeg和whisper工具链实现零成本的视频处理全流程,主要包括以下几个核心步骤: 使用ffmpeg的delogo滤镜去除视频水印,通过精准定位水印区域坐标实现无损处理 通过whisper turbo模型进行高效的语音识别,生成英文字幕文件 利用AI翻译工具将英文字幕转换为中文,并合并生成双语字幕 使用ffmpeg进行自定义品牌片尾的合成与视频拼接 最终实现带软字幕
0 成本视频处理全流程:ffmpeg + whisper 实现去水印、双语字幕、品牌片尾 | 实战SOP
不用 Sora,不用剪映会员,不用任何视频生成大模型。一个 7 分 40 秒的英文教程视频,15 分钟完成:去水印 → 英文识别 → 中文翻译 → 双语字幕 → 品牌片尾替换 → 叮声音效合成。全程命令行。
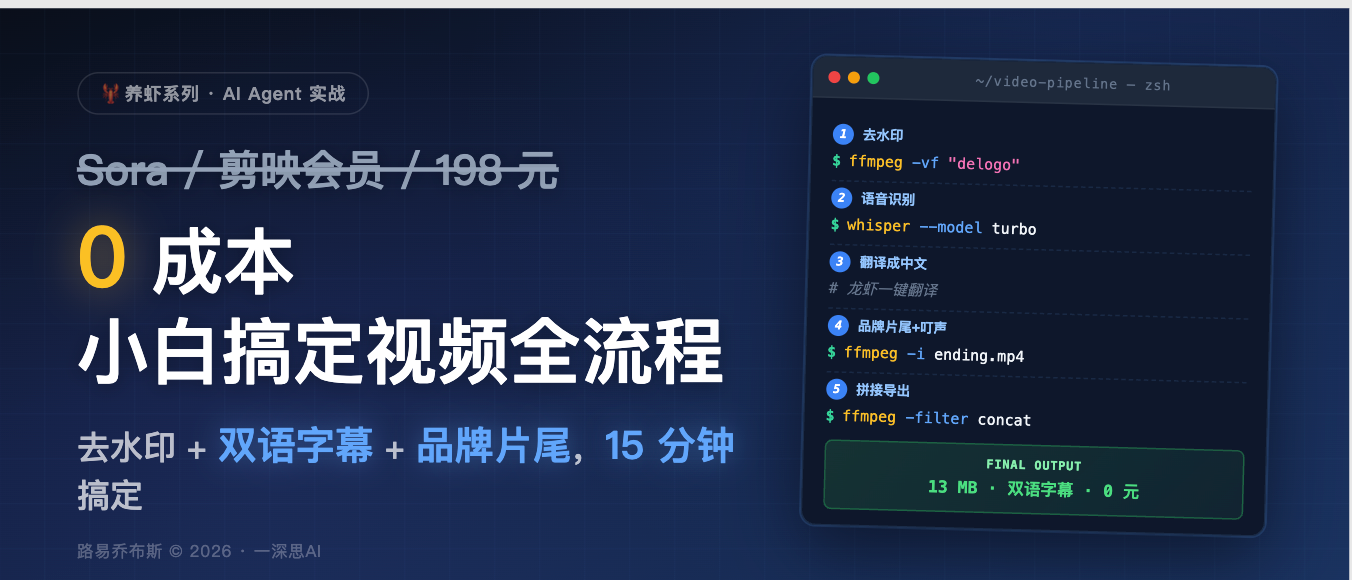
目录
- 一、技术背景
- 二、环境准备
- 三、去水印:ffmpeg delogo 滤镜
- 四、语音识别:whisper turbo
- 五、翻译与双语字幕合并
- 六、自定义片尾合成
- 七、主视频处理与拼接
- 八、软字幕挂载
- 九、完整 SOP 与踩坑记录
- 十、常见问题
一、技术背景
需求场景
手头有一个视频,需要同时完成四件事:
- 去除右下角的 NotebookLM 水印
- 生成中英双语字幕(视频是英文内容,目标受众是中文)
- 替换结尾为自定义品牌片尾(带二维码、提示音)
- 保持原画质和音频无损
为什么不用剪辑软件
| 方案 | 问题 |
|---|---|
| 剪映/Premiere/DaVinci | GUI 操作,无法脚本化;字幕一句一句对齐费时;不可复用 |
| Sora/Runway 等视频生成模型 | 这些是"创造"视频的,不是"处理"视频的,用错方向 |
| 在线去水印网站 | 有水印残留、上传限制、隐私风险 |
| ffmpeg + whisper(本方案) | 免费、开源、可脚本化、100% 本地运行、可嵌入 Agent 工作流 |
核心工具栈
输入视频 (MP4)
↓
┌─────────────────────────────────┐
│ ffmpeg delogo → 去水印 │
│ ffmpeg extract → 抽音频 │
│ whisper turbo → 语音识别 │
│ AI / DeepL → 翻译 │
│ ffmpeg generate → 片尾合成 │
│ ffmpeg concat → 拼接 │
│ ffmpeg mov_text → 软字幕挂载 │
└─────────────────────────────────┘
↓
最终视频 (MP4 + 双语字幕流)
二、环境准备
安装依赖
# macOS
brew install ffmpeg
pip3 install openai-whisper
# Ubuntu/Debian
sudo apt-get install ffmpeg
pip3 install openai-whisper
# Windows(推荐用 WSL2,原生 ffmpeg 配置复杂)
# 或直接从 https://www.gyan.dev/ffmpeg/builds/ 下载静态编译版
验证环境
ffmpeg -version
whisper --help
可选:GPU 加速
Whisper 默认使用 CPU,如果有 NVIDIA GPU,安装 PyTorch CUDA 版本可以加速 3-5 倍:
pip3 install torch --index-url https://download.pytorch.org/whl/cu121
三、去水印:ffmpeg delogo 滤镜
原理
delogo 滤镜通过周围像素插值,填补指定矩形区域。原理类似于图像修复(inpainting),用邻域像素的梯度平滑过渡。
视觉效果:水印区域变成轻微模糊的色块,肉眼可察但不影响观看。
Step 1:定位水印坐标
# 提取视频第 N 秒的一帧,用于确认水印位置
ffmpeg -ss 19 -i input.mp4 -vframes 1 frame.png
用系统预览工具打开 frame.png,测量水印坐标。本案例视频为 1280×720,NotebookLM 水印位于右下角:
左上角: (x=1100, y=650)
宽高: w=160, h=50
Step 2:应用 delogo 滤镜
ffmpeg -i input.mp4 \
-vf "delogo=x=1100:y=650:w=160:h=50" \
-c:a copy \
output.mp4
参数说明
| 参数 | 作用 |
|---|---|
-vf |
video filter,只处理视频流 |
delogo=x=X:y=Y:w=W:h=H |
指定去水印区域 |
-c:a copy |
音频直接复制,不重编码(节省时间 10x+) |
为什么不用裁剪
crop 滤镜会改变视频尺寸(1280×720 → 1280×670),上传平台会被识别为"非标尺寸",导致平台二次转码降低质量。delogo 保持原尺寸,兼容性更好。
delogo 的局限
- 如果水印占比过大(超过 10% 画面),模糊区域会非常明显
- 如果水印是动态移动的,需要用
enable='between(t,0,5)'分段处理 - 对于透明度很高的水印,效果一般(这种情况下可以先用
unsharp加锐化再去)
四、语音识别:whisper turbo
为什么选 turbo
Whisper 官方模型对比:
| 模型 | 参数量 | 速度(7分钟视频) | WER(英文) | 下载大小 |
|---|---|---|---|---|
| tiny | 39M | ~30s | 9.5% | 75MB |
| base | 74M | ~45s | 7.8% | 142MB |
| small | 244M | ~2min | 5.5% | 466MB |
| medium | 769M | ~4min | 4.1% | 1.5GB |
| large-v3 | 1550M | ~10min | 3.2% | 3GB |
| turbo | 809M | ~5min | 3.5% | 1.5GB |
turbo 是目前最佳平衡点:接近 large-v3 的准确度,速度接近 small。
Step 1:提取音频
ffmpeg -i input.mp4 \
-vn \
-acodec pcm_s16le \
-ar 16000 \
-ac 1 \
audio.wav
| 参数 | 作用 |
|---|---|
-vn |
丢弃视频流 |
-acodec pcm_s16le |
16-bit PCM 无损 |
-ar 16000 |
采样率 16kHz(whisper 内部采样率,避免重采样) |
-ac 1 |
单声道 |
Step 2:运行 whisper
whisper audio.wav \
--model turbo \
--language en \
--output_format json \
--output_dir .
第一次运行会下载模型(1.5GB),模型缓存到 ~/.cache/whisper/。之后秒起。
Step 3:JSON 转 SRT
whisper 的 JSON 输出包含每段的精确时间戳:
import json
def ts(s):
"""秒数转 SRT 时间戳格式:HH:MM:SS,mmm"""
h = int(s // 3600)
m = int((s % 3600) // 60)
sec = s % 60
return f'{h:02d}:{m:02d}:{sec:06.3f}'.replace('.', ',')
with open('audio.json') as f:
data = json.load(f)
lines = []
for i, seg in enumerate(data['segments'], 1):
text = seg['text'].strip()
lines.append(f'{i}\n{ts(seg["start"])} --> {ts(seg["end"])}\n{text}\n')
with open('en.srt', 'w', encoding='utf-8') as f:
f.write('\n'.join(lines))
print(f'生成 {len(data["segments"])} 条字幕')
whisper 常见问题
| 问题 | 解决方案 |
|---|---|
| 中英混合识别不准 | 用 large-v3 而不是 turbo,或拆分场景分别识别 |
| 专业术语错译 | 用 --initial_prompt "LLM, token, context, agent" 提供领域词表 |
| 背景噪音大 | 先用 ffmpeg -af "afftdn" 做降噪再识别 |
| 识别时间戳偏移 | 用 --word_timestamps True 获取更精细时间戳 |
五、翻译与双语字幕合并
翻译方案对比
| 方案 | 优点 | 缺点 |
|---|---|---|
| 大模型 API(GPT-4/Claude) | 上下文理解好、术语准 | 付费(小量约 $0.1/视频) |
| DeepL API | 译质高 | 免费额度 500K 字符/月 |
| Google Translate Python 库 | 免费 | 有时被 rate limit |
| 本地 LLM(Llama/Qwen) | 零成本 | 长文本翻译慢 |
推荐方案:直接把整个 en.srt 扔给 AI 对话窗口,要求保持时间戳不变、只替换文本行。一次对话处理几百条字幕。
Prompt 模板
请将下面的英文 SRT 字幕翻译为中文。要求:
1. 保持 SRT 格式(编号、时间戳完全不变)
2. AI 领域术语保留英文并加中文解释,如 "LLM(大语言模型)"
3. 翻译要自然,不要字面翻译
4. 保持每条字幕简短(手机屏幕友好)
原文:
[粘贴 en.srt 内容]
合并双语字幕
import re
def parse_srt(path):
with open(path, encoding='utf-8') as f:
content = f.read()
entries = []
for block in content.strip().split('\n\n'):
lines = block.strip().split('\n')
if len(lines) >= 3:
idx, timing = lines[0], lines[1]
text = '\n'.join(lines[2:])
entries.append((idx, timing, text))
return entries
en = parse_srt('en.srt')
zh = parse_srt('zh.srt')
bilingual = []
for i in range(len(en)):
idx, timing, en_text = en[i]
zh_text = zh[i][2] if i < len(zh) else ''
# 中文在第一行(渲染时在下方更显眼),英文在第二行
bilingual.append(f'{idx}\n{timing}\n{zh_text}\n{en_text}\n')
with open('bilingual.srt', 'w', encoding='utf-8') as f:
f.write('\n'.join(bilingual))
双语字幕显示效果
1
00:00:02,000 --> 00:00:05,000
在这个视频中我们会构建一个 AI 助手
In this video we're building an AI assistant
播放器会按行顺序渲染,视觉上形成"上中文下英文"的双语效果。
六、自定义片尾合成
Step 1:HTML 生成片尾图
用 HTML + Chrome headless,好处是完全可编程——改字、换二维码、换配色都只改 CSS,不需要打开任何 GUI 工具。
ending.html 示例结构:
<!DOCTYPE html>
<html>
<head>
<style>
body { margin: 0; width: 1280px; height: 720px;
background: linear-gradient(135deg, #0a0f1a, #1a3260);
display: flex; flex-direction: column; align-items: center;
justify-content: center; font-family: PingFang SC; }
h1 { color: #fff; font-size: 72px; }
h2 { color: #60a5fa; font-size: 36px; }
.qr { width: 240px; margin-top: 40px; }
</style>
</head>
<body>
<h1>一深思AI</h1>
<h2>DEEPTHINK AI</h2>
<img class="qr" src="qrcode.png">
<p style="color:#94a3b8;margin-top:30px;">关注获取更多 AI 硬核知识</p>
</body>
</html>
渲染为 PNG:
"/Applications/Google Chrome.app/Contents/MacOS/Google Chrome" \
--headless --disable-gpu \
--window-size=1280,720 \
--screenshot=ending.png \
file://$(pwd)/ending.html
Step 2:生成"叮"提示音
用 ffmpeg 的 lavfi 虚拟设备生成正弦波:
ffmpeg -f lavfi -i "sine=frequency=1200:duration=0.4" \
-af "volume=0.7,aecho=0.8:0.9:60:0.3,afade=t=in:st=0:d=0.005,afade=t=out:st=0.2:d=0.2" \
-ar 44100 -ac 1 \
ding.wav
音频滤镜拆解:
| 滤镜 | 作用 |
|---|---|
sine=frequency=1200:duration=0.4 |
生成 1200Hz 正弦波,时长 0.4 秒 |
volume=0.7 |
音量 70%,避免爆音 |
aecho=0.8:0.9:60:0.3 |
回声:输入增益 0.8,输出增益 0.9,延迟 60ms,衰减 0.3 |
afade=t=in:st=0:d=0.005 |
前 5ms 淡入,避免爆音 |
afade=t=out:st=0.2:d=0.2 |
0.2 秒开始淡出 0.2 秒,铃铛尾音 |
Step 3:静态图 + 音频合成 5 秒片尾视频
# 3.1 先合成 5 秒音频(前置叮声 + 静音填充)
ffmpeg -f lavfi -i anullsrc=r=44100:cl=mono:d=5 \
-i ding.wav \
-filter_complex "[0:a][1:a]amix=inputs=2:duration=first:dropout_transition=0" \
-ar 44100 -ac 1 \
ending-audio.wav
# 3.2 静态图 loop 成 5 秒视频 + 配音频
ffmpeg -loop 1 -i ending.png \
-i ending-audio.wav \
-c:v libx264 -t 5 -pix_fmt yuv420p -r 24 \
-vf "scale=1280:720" \
-c:a aac -b:a 128k \
-shortest \
ending.mp4
| 关键参数 | 作用 |
|---|---|
-loop 1 |
单张图片循环 |
-t 5 |
限制输出时长 5 秒 |
-pix_fmt yuv420p |
兼容几乎所有播放器的像素格式 |
-r 24 |
固定帧率 24fps(与主视频一致) |
-shortest |
以最短流为准,避免画面长音频短或反之 |
七、主视频处理与拼接
Step 1:去水印 + 截取前 N 秒
砍掉原视频最后的 NotebookLM 默认片尾(约 9 秒):
ffmpeg -i input.mp4 \
-t 450 \
-vf "delogo=x=1100:y=650:w=160:h=50" \
-c:v libx264 -preset fast -pix_fmt yuv420p -r 24 \
-c:a aac -b:a 128k \
main.mp4
Step 2:concat 拼接主视频 + 自定义片尾
ffmpeg -i main.mp4 -i ending.mp4 \
-filter_complex "[0:v][0:a][1:v][1:a]concat=n=2:v=1:a=1[v][a]" \
-map "[v]" -map "[a]" \
-c:v libx264 -preset fast \
-c:a aac -b:a 128k \
final-no-subs.mp4
concat 滤镜的关键要求
两段视频的编码参数必须完全一致,否则拼接处会卡顿甚至失败:
| 参数 | 必须统一 |
|---|---|
| 分辨率 | 两段都是 1280×720 |
| 帧率 | 两段都是 24fps |
| 像素格式 | 两段都是 yuv420p |
| 音频采样率 | 两段都是 44100Hz |
| 音频声道数 | 两段都是单声道 |
上一步的 main.mp4 生成时就统一了这些参数,所以 concat 能无缝拼接。
两种拼接方式对比
| 方式 | 特点 | 适用场景 |
|---|---|---|
concat filter(本文) |
重编码,强制统一参数 | 两段编码参数不同 |
concat demuxer |
无损拼接,不重编码 | 两段编码参数完全一致 |
demuxer 方式(作为备选):
# 创建拼接清单
cat > list.txt << EOF
file 'main.mp4'
file 'ending.mp4'
EOF
# 无损拼接
ffmpeg -f concat -safe 0 -i list.txt -c copy output.mp4
八、软字幕挂载
软字幕 vs 硬字幕
| 类型 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 软字幕 | 字幕作为独立流存入容器 | 原画质不受损、可开关、可提取翻译 | 抖音/视频号等会重编码丢失 |
| 硬字幕 | 字幕直接烧录到画面像素 | 所有平台兼容 | 不可关闭、画面多一层字幕 |
实战建议:做双份——软字幕版存档和发 B 站/YouTube,硬字幕版发抖音/视频号。
MP4 软字幕挂载
ffmpeg -i final-no-subs.mp4 -i bilingual.srt \
-c:v copy -c:a copy \
-c:s mov_text \
-metadata:s:s:0 language=zho \
-metadata:s:s:0 title="中英双语" \
final.mp4
| 参数 | 作用 |
|---|---|
-c:s mov_text |
MP4 容器的字幕编码格式 |
-metadata:s:s:0 language=zho |
给第 0 个字幕流打语言标签(ISO 639-2) |
-metadata:s:s:0 title |
字幕流显示名 |
硬字幕方案(需要 libass)
如果你的 ffmpeg 编译时带了 libass 支持:
ffmpeg -i final-no-subs.mp4 \
-vf "subtitles=bilingual.srt:force_style='FontName=PingFang SC,FontSize=18,PrimaryColour=&H00FFFFFF,OutlineColour=&H00000000,BorderStyle=1,Outline=2,MarginV=30,Alignment=2'" \
-c:a copy \
final-hardsub.mp4
踩坑记录:Homebrew 默认的 ffmpeg bottle 版没有 libass,需要:
brew tap homebrew-ffmpeg/ffmpeg
brew install homebrew-ffmpeg/ffmpeg/ffmpeg
或者用 evermeet.cx 提供的静态编译版。
九、完整 SOP 与踩坑记录
完整命令清单(按顺序执行)
# === 输入 ===
INPUT=input.mp4
WORK=./_work
mkdir -p $WORK && cd $WORK
# 1. 去水印 + 截取
ffmpeg -i ../$INPUT -t 450 \
-vf "delogo=x=1100:y=650:w=160:h=50" \
-c:v libx264 -preset fast -pix_fmt yuv420p -r 24 \
-c:a aac -b:a 128k main.mp4
# 2. 提取音频
ffmpeg -i ../$INPUT -vn -acodec pcm_s16le -ar 16000 -ac 1 audio.wav
# 3. whisper 识别
whisper audio.wav --model turbo --language en --output_format json --output_dir .
# 4. JSON → SRT(Python 脚本)
python3 json2srt.py audio.json en.srt
# 5. AI 翻译 en.srt → zh.srt(对话式或 API)
# 6. 合并双语字幕
python3 merge_bilingual.py en.srt zh.srt bilingual.srt
# 7. 生成片尾图
"/Applications/Google Chrome.app/Contents/MacOS/Google Chrome" \
--headless --disable-gpu --window-size=1280,720 \
--screenshot=ending.png file://$(pwd)/ending.html
# 8. 生成叮声
ffmpeg -f lavfi -i "sine=frequency=1200:duration=0.4" \
-af "volume=0.7,aecho=0.8:0.9:60:0.3,afade=t=out:st=0.2:d=0.2" \
ding.wav
# 9. 合成 5 秒片尾视频
ffmpeg -f lavfi -i anullsrc=r=44100:cl=mono:d=5 -i ding.wav \
-filter_complex "[0:a][1:a]amix=inputs=2:duration=first" ending-audio.wav
ffmpeg -loop 1 -i ending.png -i ending-audio.wav \
-c:v libx264 -t 5 -pix_fmt yuv420p -r 24 \
-c:a aac -b:a 128k -shortest ending.mp4
# 10. 拼接主视频 + 片尾
ffmpeg -i main.mp4 -i ending.mp4 \
-filter_complex "[0:v][0:a][1:v][1:a]concat=n=2:v=1:a=1[v][a]" \
-map "[v]" -map "[a]" \
-c:v libx264 -preset fast -c:a aac -b:a 128k \
final-no-subs.mp4
# 11. 挂载软字幕
ffmpeg -i final-no-subs.mp4 -i bilingual.srt \
-c:v copy -c:a copy -c:s mov_text \
-metadata:s:s:0 language=zho \
../final.mp4
踩坑记录
| 坑 | 现象 | 解决 |
|---|---|---|
| concat 拼接处卡顿 | 主视频和片尾帧率不一致 | 统一 -r 24 重编码 |
-c:a copy 报错 |
源音频流参数与目标容器不兼容 | 用 -c:a aac 重编码 |
| whisper 识别语言识别错 | 自动检测把中英混合识别为日语 | 显式 --language en |
| subtitles 滤镜报错 | ffmpeg 编译没带 libass | 换 homebrew-ffmpeg tap 版 |
| mov_text 字幕乱码 | SRT 不是 UTF-8 编码 | 保存时显式 encoding='utf-8' |
| 静态图 loop 视频黑屏 | 没加 -pix_fmt yuv420p |
强制指定像素格式 |
| 音频淡出太突兀 | 没加 afade 滤镜 | 前后各加 5ms/200ms 淡入淡出 |
性能数据
基于 M1 Mac,7 分 40 秒 720p 视频:
| 步骤 | 耗时 |
|---|---|
| whisper turbo 第一次下载模型 | 5 分钟(一次性) |
| whisper turbo 识别 | 5 分钟 |
| ffmpeg delogo + 截取重编码 | 45 秒 |
| 片尾合成(图+音+视频) | 10 秒 |
| concat 拼接重编码 | 50 秒 |
| 软字幕挂载(无重编码) | 2 秒 |
| 总计(首次,含下载) | 约 12 分钟 |
| 总计(第二次起) | 约 7 分钟 |
十、常见问题
Q1:whisper 识别中文效果如何
中文效果在 medium 及以上模型是可用的。turbo 模型对中文支持也很好,WER 约 5% 左右(基于 Common Voice 评测)。识别普通话讲座、播客、访谈都没问题。
识别中文的注意事项:
- 显式指定
--language zh - 如果包含专业术语,用
--initial_prompt提供词表 - 方言支持有限,闽南话/粤语建议用 PaddleSpeech
Q2:如何批量处理多个视频
写成 shell 脚本遍历目录:
#!/bin/bash
for video in videos/*.mp4; do
name=$(basename "$video" .mp4)
./process_video.sh "$video" "output/${name}_processed.mp4"
done
这就是 ffmpeg 方案相对剪辑软件的降维打击——GUI 软件没法批处理 100 个视频。
Q3:如何嵌入到 AI Agent 工作流
把这套 SOP 封装成一个 Skill:
video-processor/
├── SKILL.md # 方法论和触发词
├── scripts/
│ ├── remove-watermark.sh
│ ├── transcribe.sh
│ └── merge-bilingual.py
└── templates/
└── ending.html
Agent 收到"处理这个视频"指令后:
- 探测视频参数(ffprobe)
- 询问用户水印位置
- 并行执行去水印 + 提取音频 + whisper 识别
- 翻译 + 合并字幕
- 生成片尾 + 拼接 + 挂字幕
Q4:如果 ffmpeg 编译没带 libass 怎么办
硬字幕需要 libass。三种解决方案:
- Homebrew 完整版:
brew install homebrew-ffmpeg/ffmpeg/ffmpeg - 静态编译版:从 evermeet.cx 下载 macOS 版
- Docker 方案:
docker run -v $(pwd):/work jrottenberg/ffmpeg:latest ...
Q5:视频上传平台后字幕丢失了
抖音、视频号等平台会对上传视频做二次转码,丢弃 mov_text 字幕流。两种对策:
- 上传带硬字幕版(libass 烧录)
- 利用平台原生字幕功能(上传 SRT 文件)
B 站、YouTube 会保留软字幕,优先选这些平台。
参考资料
结语
三条可以带走的硬结论:
- 视频"处理"不需要视频生成大模型。Sora/Runway 是用来"创造"的。处理工作用 ffmpeg 就够。
- 命令行方案的价值是可编程性。批处理、自动化、嵌入 Agent 工作流——GUI 软件做不到。
- 学会 ffmpeg 的 ROI 远高于买剪辑会员。一次学习,终身使用,可脚本化。
下次拿到一个视频想改点什么,先问一句:「这事 ffmpeg 能不能干?」90% 的情况是能。
作者:路易乔布斯 · 一深思AI
如有帮助请点赞收藏,技术讨论评论区见。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)