告别 AI 审查的“噪音轰炸”:揭秘 Adversarial Review 的多智能体“左右互搏”术
摘要:AI代码审查的对抗性革命 传统AI代码审查存在"噪音轰炸"问题,过度报告无关紧要的警告。adversarial-review创新性地采用多智能体对抗机制:Bug-finder穷尽式扫描代码缺陷,Adversarial Defender严谨反驳误报,Referee做出最终裁决。这种"左右互搏"的设计通过不对称激励机制,有效过滤90%以上的噪音,只保留真正
告别 AI 审查的“噪音轰炸”:揭秘 Adversarial Review 的多智能体“左右互搏”术
在软件开发的日常流转中,Code Review(代码审查)始终是保障代码质量与架构健康的最后一道防线。随着大语言模型(LLM)的全面普及,许多团队都开始尝试将 AI 引入 Review 流程,期望能借此解放资深工程师的生产力。
然而,现实的体验往往是骨感甚至令人抓狂的:采用单智能体(Single-agent)模式的 AI Reviewer,就像是一个过度紧张且缺乏实际工程经验的新手。为了向你证明“我在干活”并且“绝不漏掉任何隐患”,它会对着你的 Pull Request 疯狂输出数百条毫无意义的警告:
“这个变量名可以更语义化一点”、“这段代码建议提取成一个纯函数”、“缺少错误捕获(尽管你在外层已经处理了)”……
这些铺天盖地的噪音,不仅无情地淹没了真正致命的逻辑 Bug,更在无形中消耗着开发者的耐心,最终导致团队对 AI 辅助审查彻底失去信任。
那么,如何才能让 AI 褪去“初级代码检查器”的外衣,像一位资深的 Tech Lead 一样,既能目光如炬地揪出深层并发或内存泄漏问题,又懂得知趣地闭嘴,不拿代码规范的鸡毛蒜皮来烦人?
答案就藏在 adversarial-review 这个全新的多智能体协作技能(Skill)中。

核心设计理念:用“对抗性”战胜“幻觉”
面对 AI 的“过度发散”与“误报(False Positives)”,传统的解决思路通常是不断地去修改 Prompt,比如添加“请只报告严重问题”、“请保持严谨、不要无中生有”等指令。但实践证明,这种道德约束式的 Prompt 在复杂的工程代码面前极其脆弱。大模型天生具有取悦用户的倾向,当它被要求寻找 Bug 时,它总是倾向于“找点什么出来”。
adversarial-review 彻底抛弃了这种修修补补的做法。它的核心设计理念非常硬核——引入博弈论中的对抗性机制(Adversarial Tension),通过多智能体的“左右互搏”来物理过滤噪音,提纯高价值的工程洞察。
💡 核心洞察:大模型天生具有取悦用户的倾向,对抗性审查的本质,就是用机器内部的利益博弈,来对冲大模型的“讨好型人格”。
它的终极目标只有一个:不再追求“找出尽可能多的问题”,而是“只抛出真正值得开发者停下敲击键盘的手,去深入思考的致命缺陷”。为了实现这一目标,该技能巧妙地引入了不对称激励机制(Asymmetric Incentive),让三个拥有完全不同动机与视角的 AI Agent 相互制衡。
拆解实现方案:三阶段的赛博法庭流水线
adversarial-review 绝不是简单地把你的代码一股脑儿扔给大模型,而是精心设计了一个类似于法庭辩论的三阶段自动化流水线(Pipeline)。通过精确的 JSON 格式在智能体之间传递数据,确保审查过程的严谨性与可追溯性。
阶段一:Bug-finder(进攻方:吹毛求疵的挑刺者)
当技能被触发时,系统首先会唤醒名为 Bug-finder 的智能体。它的唯一任务是对目标代码进行穷尽式的缺陷扫描(Exhaustive defect scanning)。
在这个阶段,系统赋予它的激励机制是:找出问题就能得分。这就好比一个拿着放大镜的质检员,系统鼓励它过度报告(Incentivized over-reporting)。无论是疑似的性能隐患、安全漏洞、无障碍(a11y)缺失,还是类型安全的边缘情况,它都会统统揪出来,并生成结构化的 JSON 缺陷报告。
这一步不可避免地会产生大量的误报,但在这套架构中,这是被允许甚至被鼓励的——它的职责就是“宁可错杀一千,不可放过一个”,确保问题池的召回率(Recall)达到最高极限。
// Bug-finder 输出示例:极高的召回率,但也伴随假阳性
{
"findings": [
{
"bug_id": "BF-001",
"severity": "high",
"score": 10,
"category": "performance",
"location": "src/hooks/useCart.ts:42",
"description": "每次渲染都会重新创建 checkout 回调函数,可能导致子组件重渲染。",
"evidence": "const handleCheckout = () => { ... } 未被 useCallback 包裹。"
}
]
}
阶段二:Adversarial Defender(防守方:据理力争的辩护律师)
第二阶段,是整个系统真正展现魔力、拉开与普通 AI 工具差距的关键。面对 Bug-finder 提交的数十甚至上百条“代码罪状”,系统会立即派出 Adversarial Defender 智能体。
它扮演的是目标代码的辩护律师。它的激励机制被设计得极其严苛且不对称:成功驳回(Rebuttal)一个误报,就能获得高分;但如果它为了刷分而错误地驳回了真正的致命 Bug,将面临毁灭性的扣分惩罚。
这种绝妙的惩罚机制,迫使 Defender 必须极其严谨。它不能为了反驳而反驳,它必须深入代码的上下文、分析依赖关系、甚至模拟运行时的数据流。它会像一位经验丰富的老兵,无情地撕碎 Bug-finder 那些脱离实际业务场景、纯粹“教条式”的警告。Defender 会输出一份包含 verdict 和详尽 rebuttal 证据的 JSON 驳回报告。
// Defender 驳回报告示例:硬核的防守与证据链
{
"rebuttals": [
{
"bug_id": "BF-001",
"verdict": "false-positive",
"rebuttal": "由于子组件 CheckoutButton 未实现 React.memo,父组件强行使用 useCallback 无法阻止重渲染,反而会增加依赖比较的运行时开销。",
"evidence": "交叉分析:检查了 CheckoutButton.tsx,未发现 memo 包装。",
"confidence": "high"
}
]
}
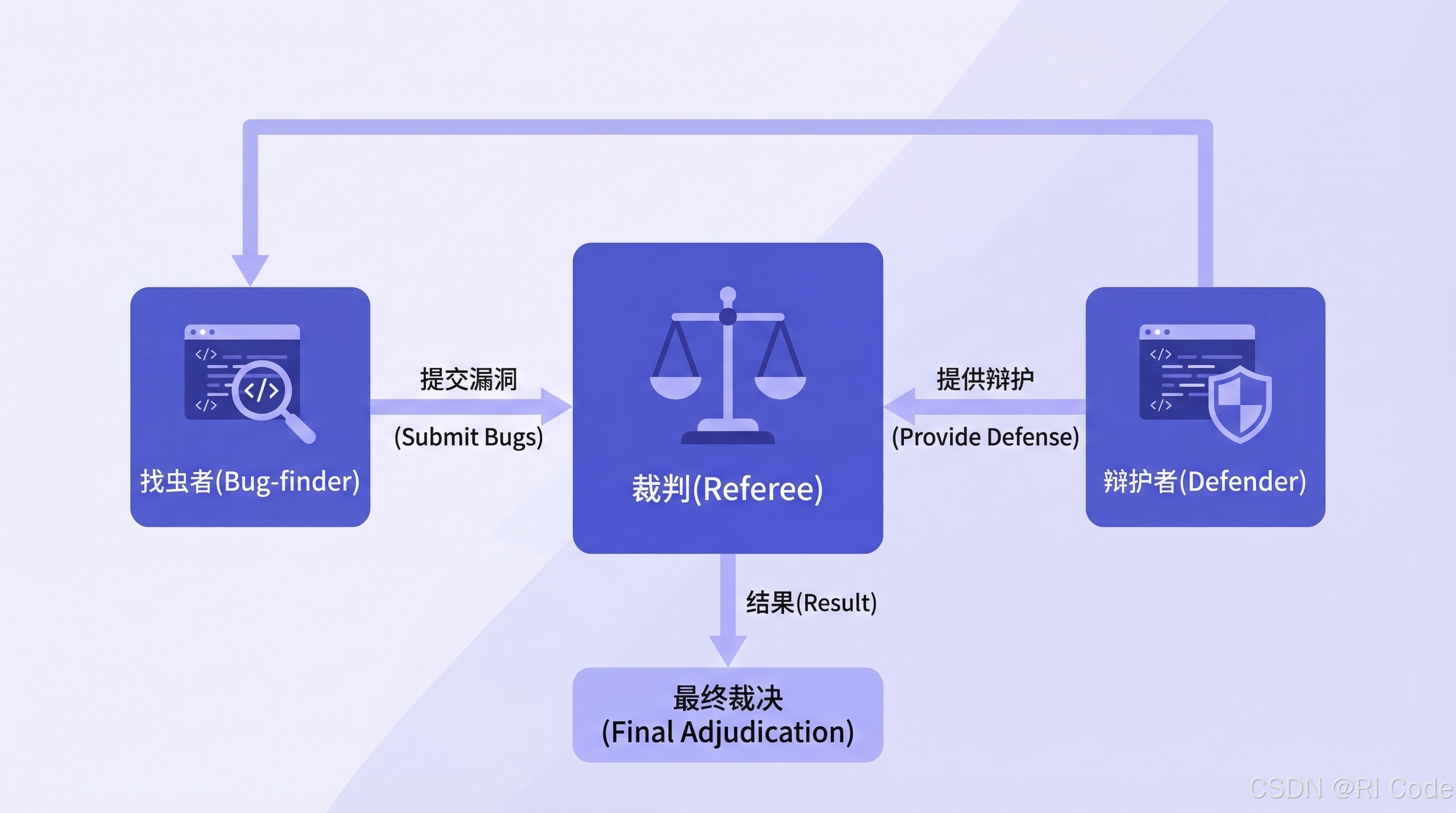
阶段三:Referee(裁判:冷酷无情的法官)
法庭的最后阶段,Bug-finder 结构化的指控清单和 Defender 的反驳辩护状,会一起被提交给最终的 Referee(裁判) 智能体。
裁判没有任何预设立场,它唯一获取系统积分的方式是:做出绝对正确、经得起人类检验的最终裁决(Final Verdict)。它会独立审视双方的论点,结合代码的原始形态,给每条争议下达最终判定:
valid(确有其事):Bug-finder 胜出,这是一个真实的威胁。invalid(纯属虚构):Defender 胜出,成功拦截噪音,系统将屏蔽该警告。needs-investigation(需要调查):双方各执一词,且风险评级极高,必须交由人类工程师决断。
// Referee 最终裁决示例:一锤定音
{
"verdicts": [
{
"bug_id": "BF-001",
"final_verdict": "invalid",
"severity": "high",
"reasoning": "Defender 分析准确。在缺乏 memo 优化的前提下强加 useCallback 属于典型的过早优化(Premature Optimization)。",
"recommendation": "系统已静默拦截该噪音。建议:若遇真实性能瓶颈,应优先考虑组件的 memo 拆分。"
}
]
}
💡 核心洞察:如果说 Bug-finder 是拿着显微镜找茬的质检员,那 Defender 就是拿着法典据理力争的律师。真正的高信噪比,就诞生于这两者的殊死搏斗之中。
经过这三层严酷的“提纯漏斗”,最初那成百上千条的啰嗦警告被燃烧殆尽。最终呈现给开发者的报告,是一份信噪比极高的洞察总结,不仅包含确认的缺陷和修复建议,还会提炼出当前代码库存在的系统性模式问题。
适配场景:重型武器该在何时亮剑?
需要注意的是,这样一套重型、需要消耗较多上下文 Token 且耗时稍长的多智能体审查机制,显然不适合你日常“修改了一个文案”或“调整了 5px 边距”的微小提交。
adversarial-review 是一件高精度的重型武器,它真正大显身手的是以下这些“硬核”工程场景:
1. 复杂项目的深度重构(Complex Refactors)
例如前端老旧框架的整体迁移(如 Vue 2 到 Vue 3)、后端微服务的边界拆分、或是大规模的底层依赖库升级。这种场景下,牵一发而动全身,人类工程师极易产生思维盲区,而普通的单智能体又容易被海量的代码变更直接搞晕。此时,“左右互搏”的深度审查能帮你兜住最隐蔽的逻辑底线。
2. 深度的专项技术审计(Deep Audits)
当你需要对代码库进行深度的性能优化(Performance)、无障碍访问检查(a11y)、安全漏洞扫描(Security)或严苛的类型安全(Type-safety)审计时。你可以通过简单的附加指令(如 focus on a11y 或 severity_threshold medium)让这三位专家临时组建一个专项审计委员会,集中火力攻克单一技术领域,产出专业级的审计报告。
3. 高风险变更的合并前把关(Pre-merge Review)
对于涉及核心支付链路、用户鉴权逻辑、或是权限管理等“零容忍”模块的代码合并,人类的 Review 往往容易因为疲惫或知识盲区而疏忽。将 adversarial-review 作为 PR 合并到 main 分支前的最后一道机器审查机制,不仅能极大降低生产环境故障率,其生成的裁判报告也能作为极佳的架构沉淀文档。

结语:让 AI 学会自我约束
AI 辅助编程的未来,绝不应仅仅停留在编辑器里为你“补全两行模板代码”,或是对着你的 Pull Request 写一段无痛呻吟的文字总结。真正的 AI 生产力,必须能够深度融入严肃的工程质量保障体系。
💡 核心洞察:用 AI 监督 AI(AI-oversight-AI),通过机制设计让机器学会自我约束与自我纠错,是通向真正可靠 AI 工程的必经之路。
adversarial-review 技能向我们清晰地展示了 AI 协同的高级形态。当你下一次面对一堆逻辑如同乱麻、让你无从下手的核心模块重构代码时,不妨唤醒这三位不知疲倦的 AI 专家,给自己泡杯咖啡,看看它们能在激烈的“法庭辩论”中,为你碰撞出怎样令人惊艳的工程火花。
附录:adversarial-review 技能定义
为了方便开发者直接在本地复刻这套对抗性审查系统,你可以通过以下链接获取该技能的完整实现代码。将其保存到你的 ~/.claude/skills/adversarial-review/SKILL.md 路径下即可立即启用。
- 完整实现源码:adversarial-review/SKILL.md
该 Skill 包含了完整的 Bug-finder、Defender 和 Referee 三阶段流水线定义,以及配套的 JSON Schema 校验规则,是构建自动化高信噪比代码审查流程的核心配置。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 31
31 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)