【LangChain】聊天模型
我们将使用 StrOutputParser 来解析模型的输出,将 AIMessage中的消息,提取content,但是如果我们想自定义输出解析的格式,可以吗?当然可以,这就是LangChain的强大之处,支持我们自定义组件,并且解耦合式的连接进来。聊天模型的 .stream() ⽅法返回的是⼀个迭代器,该迭代器在⽣成输出时同步产生输出 消息块。那么我们的将实现的这些生成器的签名 是 Iterato
定义聊天模型
主要有两种方式
方式1:ChatOpenAI
使用三方集成的能力
lass langchain_openai.chat_models.base.ChatOpenAI 是 LangChain 为 OpenAI 的聊天模型(如 gpt-5 , gpt-5-mini )提供的具体实现类。其继承了 class langchain_openai.chat_models.base.BaseChatOpenAI ,且BaseChatOpenAI 实现了标准的 Runnable 接口。
使用方法参考:ChatOpenAI
方式2:init_chat_mode
使用Init_chat_mode,主要包括两种场景,使用invoke创建可配置模型,和带有默认参数的可配置模型
使用LangChain提供的统一模型调用接口
上面的 ChatOpenAI 用于明确创建 OpenAI 聊天模型的实例。而init_chat_model() 是⼀个工厂函数,它可以初始化多种支持的聊天模型(如 OpenAI、Anthropic、FireworksAI 等),不仅仅是 OpenAI 的聊天模型。
官方的解释:Initialize a chat model from any supported provider using a unified interface.
所有的LLM,都只需要一个统一的接口
使用不同的模型提供方,需要安装为其各自包,与设置各自的 API Key 环境变量!
函数官网:init_chat_model
init_chat_model(
model: str | None = None,
*,
model_provider: str | None = None,
configurable_fields: Literal['any'] | list[str] | tuple[str, ...] | None = None,
config_prefix: str | None = None,
**kwargs: Any = {}
) -> BaseChatModel | _ConfigurableModel所有模型统一的调用接口
from langchain.chat_models import init_chat_model
# 返回 langchain_openai.ChatOpenAI 实例
gpt_model = init_chat_model("gpt-5-mini", model_provider="openai",
temperature=0)
# 返回 langchain_deepseek.ChatDeepSeek 实例
deepseek_model = init_chat_model("deepseek-chat", model_provider="deepseek",
temperature=0)
# 由于所有模型集成都实现了ChatModel接⼝,因此可以以相同的⽅式使⽤它们。
print("gpt-5-mini: " + gpt_model.invoke("what's your name").content + "\n")
print("deepseek-chat: " + deepseek_model.invoke("what's your name").content +
"\n")
1.创建可配置模型,如果我们在创建模型时参数没有配置全,我们就可以利用在执行模型时,带上对应的参数配置
通过invoke的方法,函数原型:
invoke(
self,
input: dict,
config: RunnableConfig | None = None,
**kwargs: Any = {}
) -> OutputType的第二个参数,一个RunnableConfig 来配置模型:
示例:
config_model = init_chat_model(temperature=0)
messages = [
SystemMessage(content="请补全故事,100个字以内"),
HumanMessage(content="我是一只小猪猪___")
]
result = config_model.invoke(
messages,
config={
"configurable":{
"model" : "deepseek-chat",
}})
print(result.content)如果我们已经定义好模型了,但是在执行模型时,想修改一些模型参数,此时,我们就可以根据init_chat_model的其他参数达成这个效果:
例如,在真执行时,修改max_tokens数量:
# 可配置模型(带默认参数)
model = init_chat_model(
model = "deepseek-chat",
model_provider = "deepseek",
temperature=0,
max_tokens=100,
)
messages = [
SystemMessage(content="请补全故事,100个字以内"),
HumanMessage(content="我是一只小猪猪___")
]
# 修改默认参数
result = model.invoke(
messages,
config={
"configurable":{
"max_tokens" : 10,
}
}
)
print(result.content)这样执行没效果!
原因是init_chat_model的语法限制,如果已经有默认参数了,那么在下面这样修改是无效的,要配合configurable_fields和config_prefix这两个参数。
# 可配置模型(带默认参数)
model = init_chat_model(
model = "deepseek-chat",
model_provider = "deepseek",
temperature=0,
max_tokens=100,
configurable_fields=("max_tokens",), # 这里需要带上,
config_prefix="foo",
)
messages = [
SystemMessage(content="请补全故事,100个字以内"),
HumanMessage(content="我是一只小猪猪___")
]
# 修改默认参数
result = model.invoke(
messages,
config={
"configurable":{
"foo_max_tokens" : 10, # 这里必须是上面定义的config_prefix的前缀
}
},
)
print(result.content)不过需要注意的是,使用哪个厂商的模型需要显示安装各自的安装包和API_KEY
聊天模型--工具
LLM 本身是⼀个封闭的知识系统,其能力受限于其训练数据(存在滞后性)和内在的⽂本生成逻辑。它无法执行直接计算、查询实时信息、操作数据库或调用任何外部 API。工具调用打破了这层壁垒
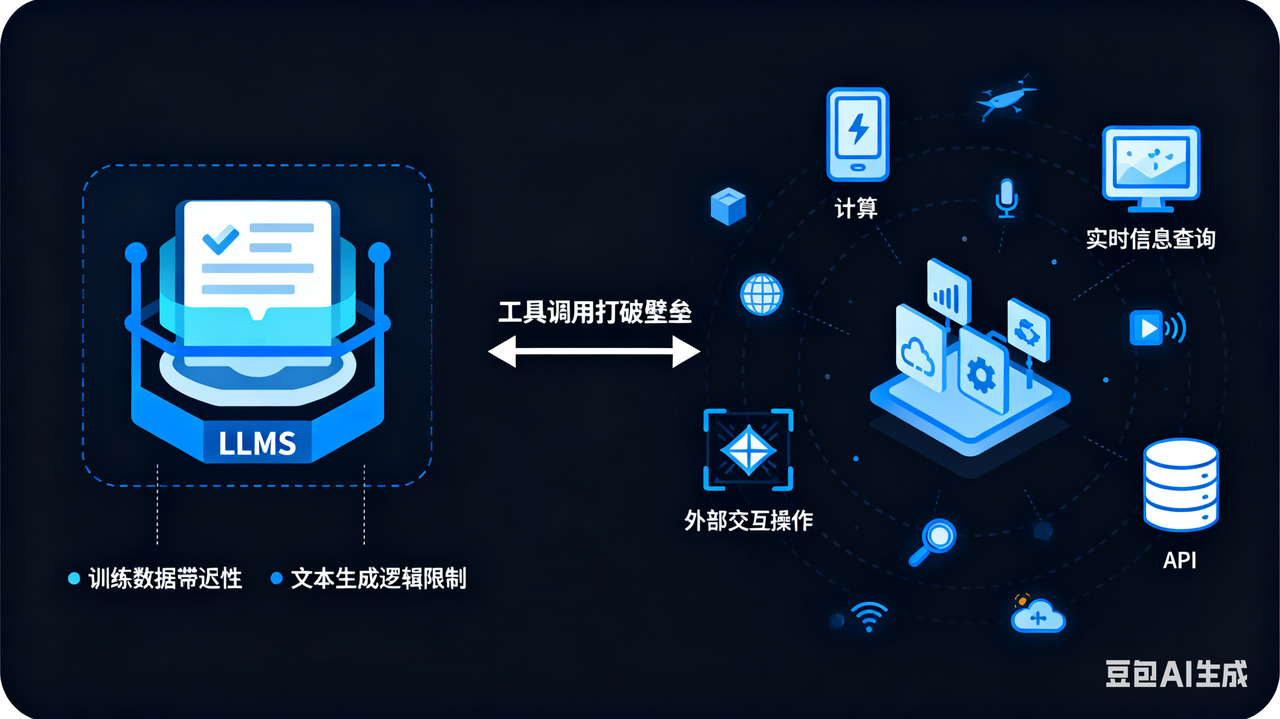
例如,当我们希望获取当前天气情况时,由于 LLM ⽆法获取实时信息,此时我们就可以借助⼯具,通过外部服务进行搜索完成查询
再例如,当我们希望获取数据库表中的数据时,由于 LLM 无法直接获取表数据,此时我们就可以借助工具,通过与数据库交互完成查询。
总之,我们可以把封装API,调用数据库等等都看工具,然后让LLM进行调用
定义工具的方式有很多,不过定义工具的核心就只有三个:工具名称,工具描述,工具参数
以一份加法作为工具为例
1:使用 @tool 装饰器创建工具
from langchain_core.tools import tool
@tool
def add(a:int, b:int)-> int:
"""
两数之和
Args:
:param a: 第一个数字
:param b: 第一个数字
Returns:
a+b 第一个数字+第二个数字
"""
return a+b
print(add.invoke({"a": 1, "b": 2}))
print(add.name)
print(add.description)
print(add.args)可以看出,工具通过 @tool 加 Python函数 实现,其中:
• 该装饰器默认使用函数名称作为⼯具名称。
• 该装饰器将使用函数的文档字符串作为工具的描述。
因此,函数名、类型提示和文档字符串都是传递给工具 Schema 的⼀部分,不可缺失。什么是Schema,简单来说就是做校验的
可是一个工具为什么要这些属性呢?工具名称,工具描述,工具参数
对于工具来说,工具的名称可以让LLM知道有哪些工具,可以调哪些工具
工具描述实际上就是在写提示词, 让模型知道调谁
工具的参数让模型知道怎么调用
定义工具的其他方式:
如果我们没有定义工具的描述,那么就会报错。
我们可以依赖 Pydantic 类,定义工具的字段描述
在 LangChain 中,可以使用Pydantic 类,提供运行时数据验证和类型检查。通过 Field(description="...") 添加字段描述,LangChain 会自动提取。
注意,除非提供默认值,否则所有字段都是 required
class AddInput(BaseModel):
"""两数之和"""
a:int = Field(..., description="第一个参数")
b:int = Field(..., description="第二个参数")
@tool(args_schema=AddInput)
def add(a:int, b:int)-> int:
# 未提供描述
return a+b
print(add.invoke({"a": 1, "b": 2}))
print(add.name)
print(add.description)
print(add.args)
另外还有一种方式对参数的构造,依赖 Annotated
在 LangChain 中,可以依赖 Annotated 和⽂档字符串传递给工具 Schema 。
@tool
def add(
a: Annotated[int, ..., "第一个参数"],
b: Annotated[int, ..., "第二个参数"],
)-> int:
"""两数之和"""
return a+b
print(add.invoke({"a": 1, "b": 2}))
print(add.name)
print(add.description)
print(add.args)使用 StructuredTool 类提供的函数创建⼯具
class ADDinput(BaseModel):
a: int = Field(..., description="第一个参数")
b:int = Field(..., description="第二个参数")
def add(a:int, b:int)-> int:
"""两数之和"""
return a+b
# 4
add = StructuredTool.from_function(
func=add,
name="ADD", #工具名称
description="两数之和", # 工具描述
args_schema=ADDinput, # 工具参数
)
print(add.invoke({"a": 1, "b": 2}))
print(add.name)
print(add.description)
print(add.args)如果希望我们的⼯具区分消息内容(content)和其他工件(artifact),让大模型读取 content,而⼀些用来构造 content的原始数据保存下来,若后续有⼀些记录、分析的步骤,就可以派上用场了,这就是artifact 。 通常需要使用字典 或列表 保存。
例如存在以下场景:
1. 我们不仅仅想要⼀个总结性的答案,还想要具体的链接、来源或多个备选答案。
2. 工具的 content 输出不符合你的预期,我们想查看原始数据来理解问题出在哪里(是工具解析
的问题,还是API本身返回的问题)。
3. 需要记录每次工具调用的完整原始响应,以满⾜数据分析的要求。
4...
从这里就可以对比出只返回 content 无法做到这些事情。
如何做到?
我们需要在定义⼯具时指定 response_format="content_and_artifact" 参数,并确保我们返回⼀个元组 (content, artifact)
如果我们直接使用工具参数调用⼯具,将只返回输出的 content 部分:
# 不仅想知道content,还想知道过程
class ADDinput(BaseModel):
a: int = Field(..., description="第一个参数")
b: int = Field(..., description="第二个参数")
def add(a: int, b: int) -> Tuple[str, list[int]]:
nums = [a, b]
content = f"两数之和{a}+{b}={a + b}"
return content, nums
add = StructuredTool.from_function(
func=add,
name="ADD", # 工具名称
description="两数之和", # 工具描述
args_schema=ADDinput, # 工具参数
response_format="content_and_artifact"
)
print(add.invoke({"a": 1, "b": 2}))

若想要看到工具返回的元组,我们需要模拟大模型调用⼯具的姿势,如下所⽰。这将返回⼀个 ToolMessage:
print(add.invoke({
"name": "ADd",
"args": {"a": 3, "b": 4},
"type": "tool_call", # 必填
"id": "123", # 必填
"b": 2, }))
定义好了工具,大模型我们也定义好了,现在我们需要给大模型绑定好定义的工具。
为了实际将这些⼯具绑定到聊天模型,可以使用聊天模型的 .bind_tools() 方法
bind_tools(
self,
tools: Sequence[builtins.dict[str, Any] | type | Callable | BaseTool],
*,
tool_choice: str | None = None,
**kwargs: Any = {}
) -> Runnable[LanguageModelInput, AIMessage]我们需要传递一个工具列表,最后返回一个Runnable实例
绑定工具调用一下:
这里以
ChatGoogleGenerativeAI为例
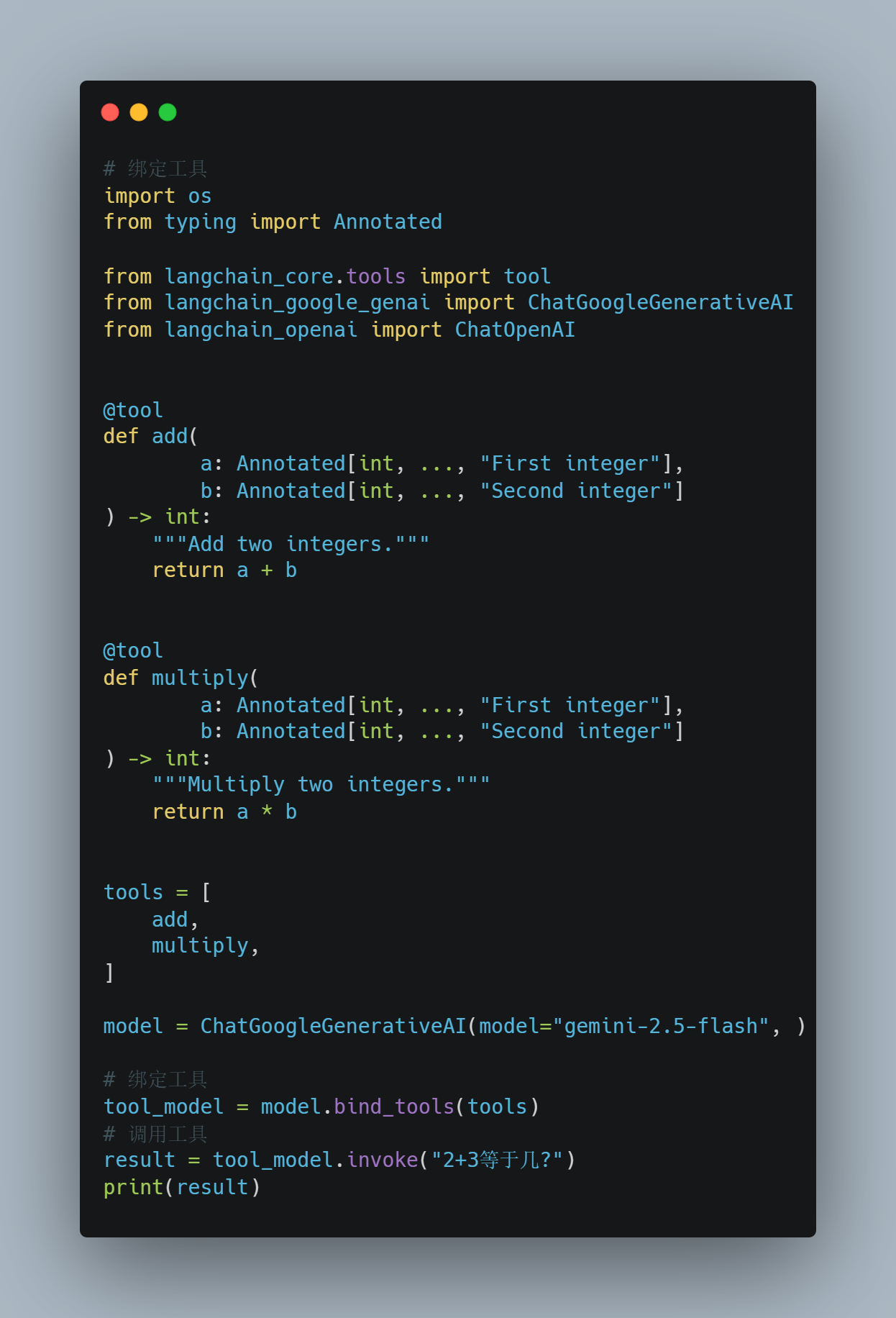
result是一个AIMessage类型
![]()
内容是:

其中有一个关键字段.tool_calls。
从输出结果看来,AI 给出的响应是进行⼯具的调用!!⼯具调用的⼀个关键原则是,模型根据输⼊的相关性决定何时使用⼯具。模型并不总是需要调用⼯具。
当然我们也可以让模型强制调用⼯具,那就需要在绑定⼯具时,设置 tool_choice="any" ,表示
强制调用至少⼀个⼯具。
现在我们知道,输出结果是⼀个 AIMessage 。但是,如果调用了⼯具,则 result 将具有⼀个
tool_calls 属性。此属性包括执行该⼯具所需的⼀切,包括⼯具名称和输入参数
tool_calls字段如下:
tool_calls=[
{
'name': 'add',
'args': {'b': 3, 'a': 2},
'id': '155c6a0e-f4e5-4524-891d-4a242c0ec90e',
'type': 'tool_call'}
]我们发现这个tool_calls是LLM告诉我们选择了哪个工具,是工具的选择,并没有真正的调用
工具选择根据输入特性决定是否调用工具
这个tool_calls就是我们当初模拟大模型的调用姿势的过程,其中参数完全一样。
那么我们就可以从中取到这个tool_calls,然后就像当初模拟大模型一样,调用。

结果:
![]()
所以我们现在知道了完整工具的流程:定义工具,绑定工具,工具选择,调用工具
到这里可以发现,我们仅仅只是成功让LLM选择了⼯具,但是聊天模型并没有给我们返回我们真正需要的答案,比如谁+谁得到谁?LLM这里只是返回了结果。此时就需要发送所有已知的消息给聊天模型,包括:
1. 将工具输出传递给聊天模型,包括 HumanMessage 、 AIMessage (⼯具调用)、ToolMessage
2. 聊天模型根据以上消息输⼊,将最终结果 AIMessage 返回
但是什么是ToolMessage呢?
就是AIMessage中的tool_calls就是ToolMessage,我们打断点看一下:
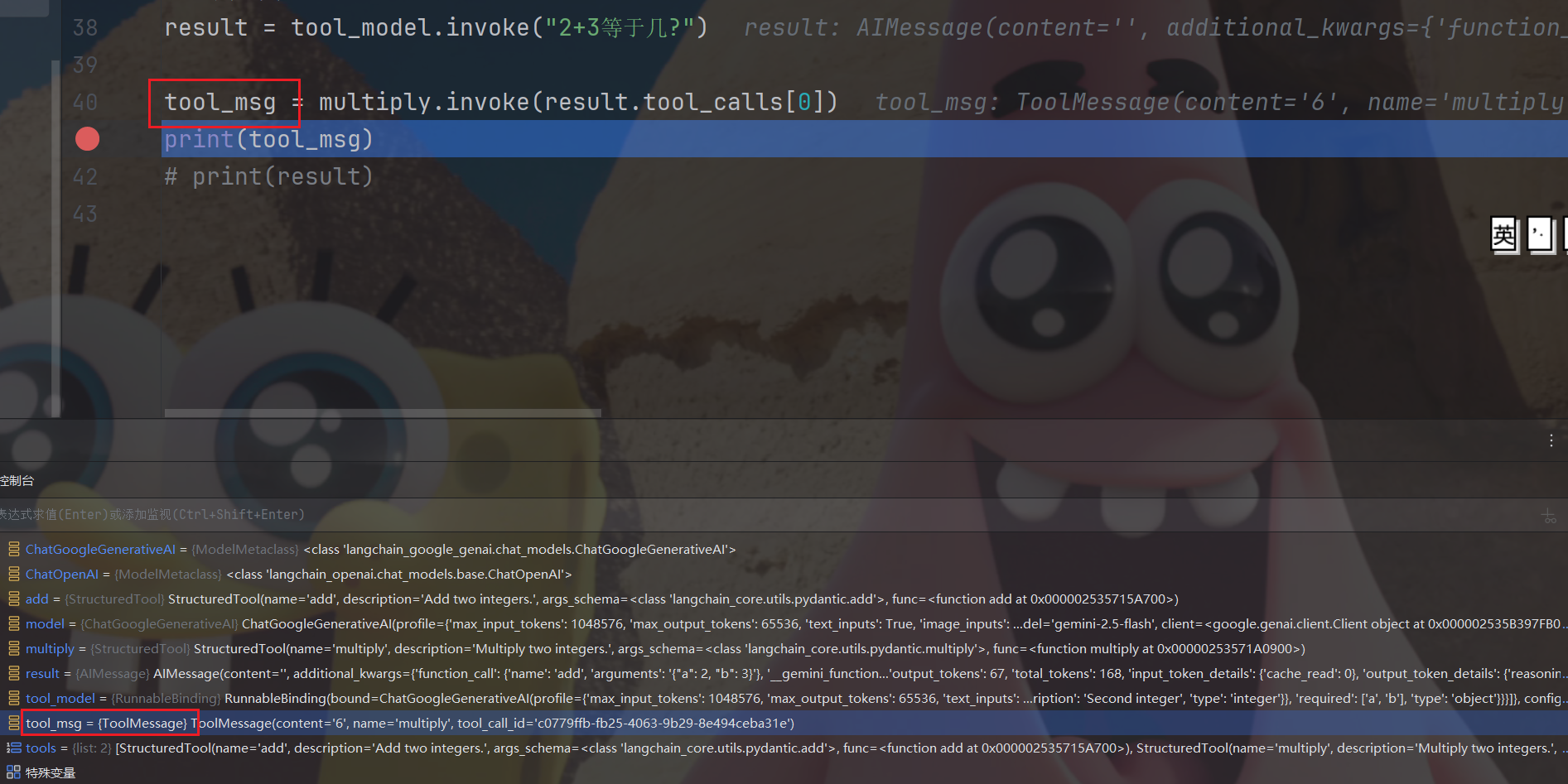
ok,下面我们就将已知的所有消息都发给LLM,LLM会组装好,并且返回给我们想要的格式化的结果。
🌻这里在补充一点,我们所谓的使用工具名+tool_calls的Schema结构化数据来模拟大模型调用的过程,官方文档是这样的:
Runnable Interface: 所有的工具都继承了 Runnable 协议,这意味着它们都统一拥有 .invoke(), .batch(), 和 .astream() 方法。在 LangChain 中,@tool 装饰器会将你的 Python 函数封装成一个 BaseTool 对象,这个对象本身就实现了 invoke 方法,因为它是Runnable实例,模型返回的 tool_calls 只是 Schema(结构化数据),它不具备执行能力。真正的执行逻辑(invoke)是在你本地代码定义的 tools 列表对象中。
ok,下面这里我们既一次性问大模型加法,同时也询问大模型乘法。
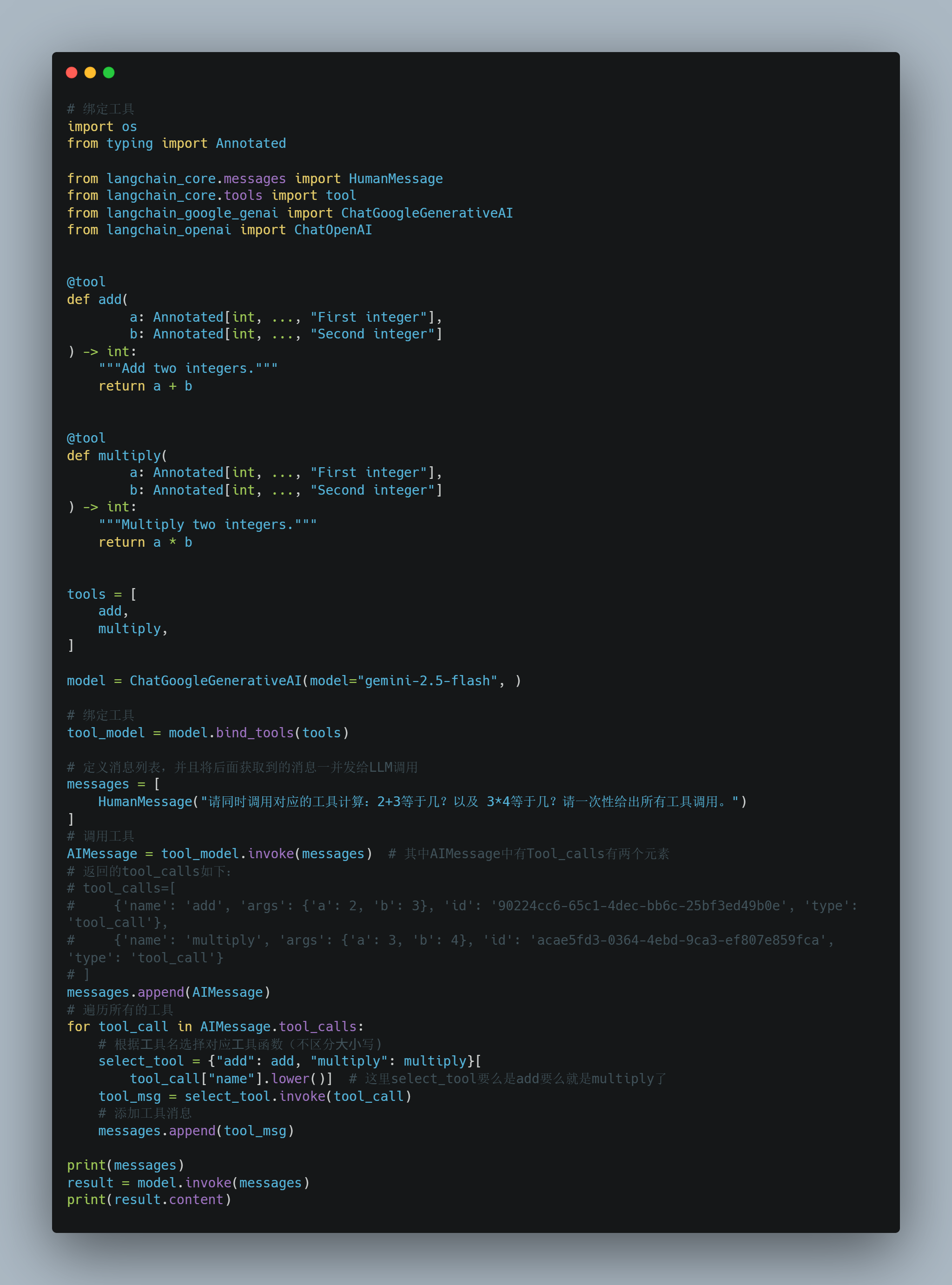
我们最后发给LLM的消息有这些

最后LLM会根据HumanMessage根据提示词,AIMessage决定了如何调用哪个工具?ToolMessage把工具调用的结果。最后LLM整理模型调用的结果。

这是整个messages:
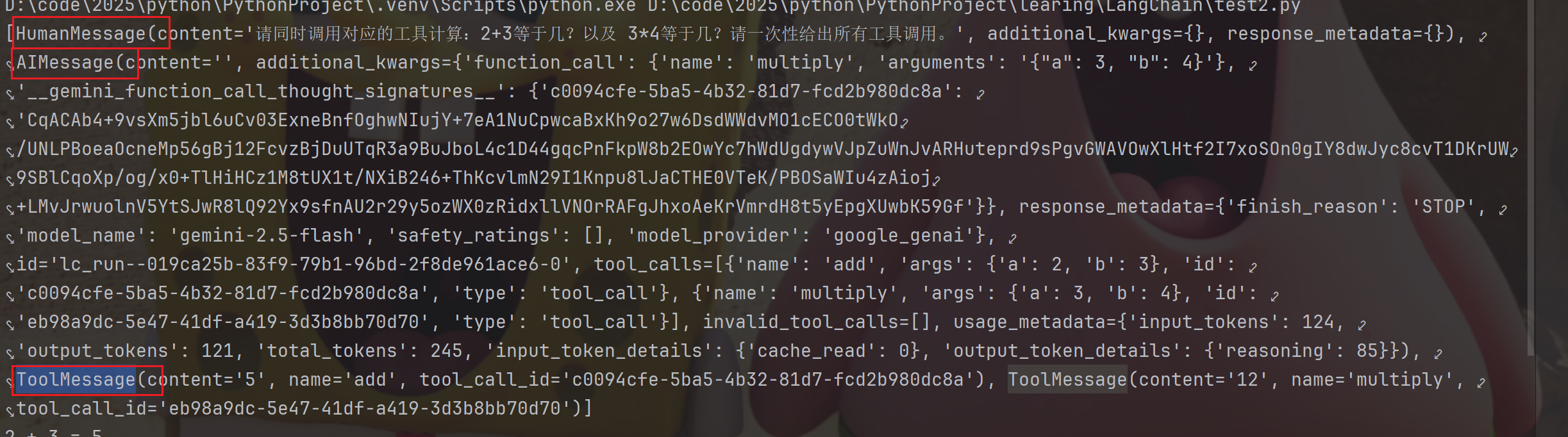
最后注意一下,如果我们用绑定工具的模型,注意不要带
tool_choice = any参数
还要保证你在字典中查找的工具名称和toolmsg返回的名称是一致的
从流程与代码中可以看到,实际上我们调⽤了两次聊天模型:• 第⼀次:仅将【 HumanMessage 】发送给聊天模型进行处理,结果返回了【包含⼯具调⽤的AIMessage 】,并没有返回我们想要的结果。然后我们执行⼯具,得到 ToolMessage 。• 第⼆次:将【 HumanMessage + AIMessage + 处理,结果返回了【包含结果的 AIMessage 】】消息记录发送给聊天模型进行ToolMessage
LangChain 提供的工具,⼯具也不是全部都需要我们自已⼿搓,其实 LangChain 官方也已经给我们提供了很多现成的工具(Tool)和工具包(Toolkit),我们就可以把这些工具集成到LLM中了
LangChain提供的一些第三方的工具:
https://docs.langchain.com/oss/python/integrations/tools
聊天模型--结构化输出
在 LangChain 中,聊天模型提供了额外的功能:结构化输出。⼀种使聊天模型以结构化格式(例如JSON)进行响应的技术。例如,可能希望将模型输出存储在数据库中,并确保输出符合数据库模式。这种需求激发了结构化输出的概念,其中可以指示模型使用特定的输出结构进行响应。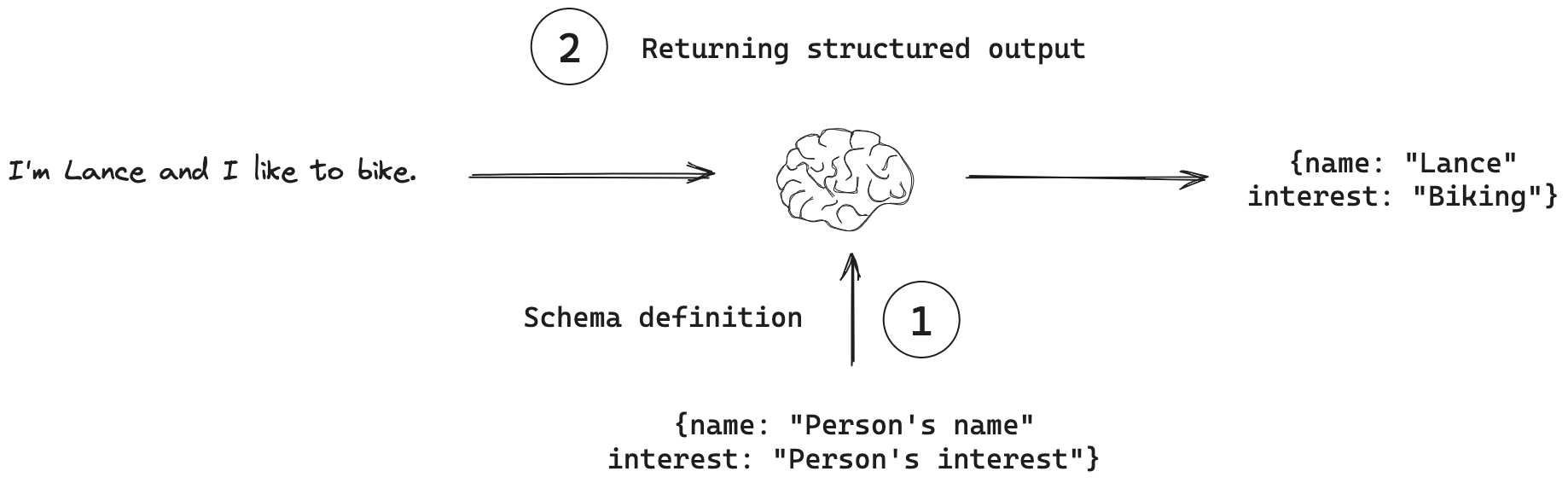
要想使用结构化输出能力,LangChain 提供了⼀种⽅法 .with_structured_output() ,该方法
需要先定义输出结构,然后执行通过 .with_structured_output() 得到的 Runnable 实例。
import os
from typing import Optional
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
model = ChatOpenAI(model="deepseek-chat",
api_key=os.environ.get("DEEPSEEK_API_KEY"),
openai_api_base="https://api.deepseek.com/v1")
# 定义schema结构的Pydantic对象
class Joke(BaseModel):
"""给用户讲个笑话"""
setup: str = Field(description="笑话开头")
punchline: str = Field(description="笑话的妙语")
rate: Optional[int] = Field(default=None, description="从1-10分,给笑话打个评分")
# 带有特定schema输出的模型
model_with_struct = model.with_structured_output(Joke, method="function_calling")
print(model_with_struct.invoke("讲一个关于猪的笑话"))
得到的特定schema的回复:

还可以嵌套
# 还可以schema嵌套一个schema
class data(BaseModel):
"""获取关于笑话的数据。"""
jokes: List[Joke]
# 带有特定schema输出的模型
model_with_struct = model.with_structured_output(data, method="function_calling")
print(model_with_struct.invoke("分别讲一个关于猪的和一个兔子的笑话"))

因此,我们也可以设置执⾏ Runnable 后的输出结果指定为 TypedDict 类,这将返回⼀个字典,且输出后,会根据设定进⾏验证。
我们只需要把BaseModel换成TypedDict
还可以让聊天模型直接返回 JSON,只不过为了声明 JSON,我们需要定义 JSON Schema,如下所示:
json_schema = {
"title": "joke",
"description": "给⽤⼾讲⼀个笑话。",
"type": "object",
"properties": {
"setup": {
"type": "string",
"description": "这个笑话的开头",
},
"punchline": {
"type": "string",
"description": "这个笑话的妙语",
},
"rating": {
"type": "integer",
"description": "从1到10分,给这个笑话评分",
"default": None,
},
},
"required": ["setup", "punchline"],
}
# 带有特定schema输出的模型
model_with_struct = model.with_structured_output(json_schema, method="function_calling", include_raw=True)
print(model_with_struct.invoke("分别讲一个关于猪的和一个兔子的笑话"))
#
但是我们这样完全定义死了LLM回答的范式,导致如果我们脱离了我们自已定义的回答范式范围,LLM可能回答的不尽人意,
print(model_with_struct.invoke("讲一个关于猪的笑话"))
print(model_with_struct.invoke("你是谁"))
为此,我们要给大模型多定义几个输出的schema,创建具有联合类型属性的父模式,让模型具有选择的结构。
import os
from typing import Optional, Union
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
model = ChatOpenAI(model="deepseek-chat",
api_key=os.environ.get("DEEPSEEK_API_KEY"),
openai_api_base="https://api.deepseek.com/v1")
# 定义schema结构的Pydantic对象
class Joke(BaseModel):
"""给用户讲个笑话"""
setup: str = Field(description="笑话开头")
punchline: str = Field(description="笑话的妙语")
rate: Optional[int] = Field(default=None, description="从1-10分,给笑话打个评分")
class Response(BaseModel):
"""用户的正常回答"""
content: str = Field(description="对于用户的提问的对话相应")
class FinallyResponse(BaseModel):
"""最终回答,选择合适的回答结构"""
final_output: Union[Joke, Response]
# 带有特定schema输出的模型
model_with_struct = model.with_structured_output(FinallyResponse, method="function_calling")
print(model_with_struct.invoke("讲一个关于猪的笑话"))
print(model_with_struct.invoke("你是谁"))
#

所以,使用结构化的输出能力,不仅可以帮我们提取到一些信息。如果有需要,我们完全可以用来清洗数据。
比如之前那个使用工具的搜索天气,我们可以将得到的结果,进行清洗。
当需要同时使用结构化输出和其他⼯具时,需要注意顺序,不要弄反:
1. 首先绑定工具
2. 其次添加结构化输出
聊天模型-流式传输
在 LangChain 聊天模型中,可以使用其 .stream() 方法,来同步生成流式响应的效果。
聊天模型的 .stream() 方法返回⼀个迭代器,该迭代器在生成输出时同步产生输出 消息块。
其实迭代器返回的每个元素都是AIMessageChunk 的东西,它代表 AIMessage 的⼀部分,也就是消息块
我们这次用流式传输调用:
model = ChatOpenAI(model="deepseek-chat",
api_key=os.environ.get("DEEPSEEK_API_KEY"),
openai_api_base="https://api.deepseek.com/v1")
chunks = []
for chunk in model.stream("讲⼀个50字的笑话", ):
print(chunk.content, end="|", flush=True)
chunks.append(chunk)
print(chunks[0] + chunks[1] + chunks[2])

![]()
可以使用 .astream() 方法,来异步生成流式响应的效果,这专为非阻塞⼯作流程而设计。
当然Invoke也支持异步方法,ainvoke
自定义流式输出解析器
我们将使用 StrOutputParser 来解析模型的输出,将 AIMessage中的消息,提取content,但是如果我们想自定义输出解析的格式,可以吗?当然可以,这就是LangChain的强大之处,支持我们自定义组件,并且解耦合式的连接进来。
聊天模型的 .stream() ⽅法返回的是⼀个迭代器,该迭代器在⽣成输出时同步产生输出 消息块 。那么我们的将实现的这些生成器的签名 是 Iterator[input]->Iterator[output]
我们再来探索一下,stream的底层原理。如果仅仅使用HTTP协议可以吗?由于是无状态的,所以服务器方发送一次,下次就无状态了。如果是websocket呢?特点是双向连接,但是缺点就是服务器方要记录连接状态,服务器方压力太大,如果仅仅是实现流失传输,没必要。
而我们要解决的问题就是,服务器能识别客户端,客户端之负责接收即可,所以是单向的。
也就是说,服务器向客户端声明,接下来要发送的是流消息(streaming),这时客户端不会关闭连接,会⼀直等待服务器发送过来新的数据流
有这样的协议吗?SSE(Server-Sent Events)是⼀种基于 HTTP 的轻量级实时通信协议,浏览器可以通过内置的 EventSource API 接收并处理这些实时事件。
SSE 仅支持服务器向客⼾端的单向数据推送,客户端通过普通 HTTP 请求建立连接后,服务器可持续发送数据流,但客户端无法通过同⼀连接向服务器发送数据。
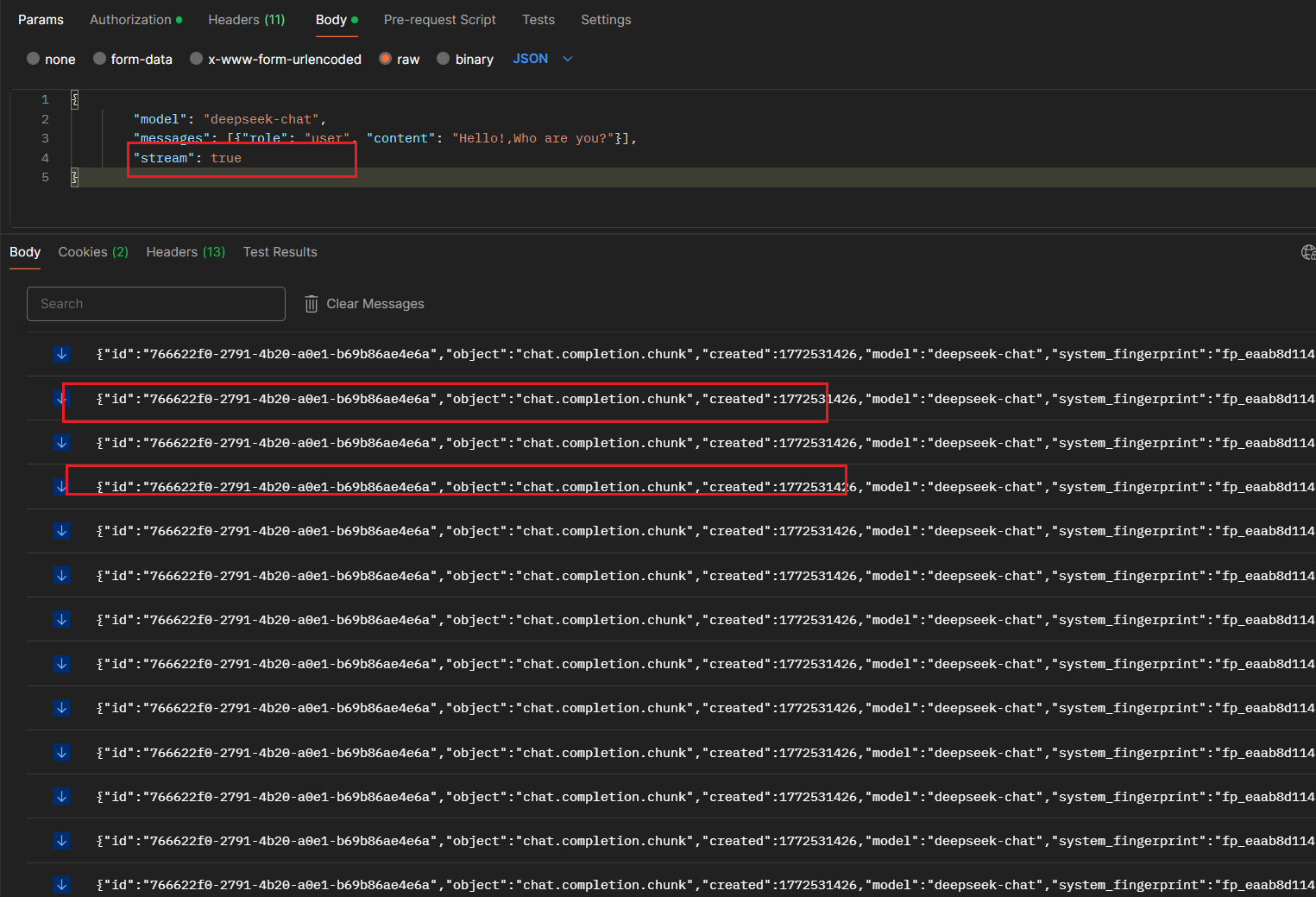
来验证一下stream流下的sse协议:
服务端向浏览器发送 SSE 数据,需要设置必要的 HTTP 头信息
Content-Type: text/event-stream;charset=utf-8
Connection: keep-alive先建立连接,服务端一直返回数据,最后断开连接
流式传输:

我们再来探索一下LangChain自已具有流式传输协议吗???
有,但是对于 LangChain 的流式传输能力,本身是因为大模型供应商提供了流式传输能力,由 LangChain 进行调用后接收并处理成⼀个个的 AIMessageChunk
所以LangChain 本身并不“创造”或“规定”⼀个底层的网络传输协议,这都是由LLM做的, LangChain负责在上层接入这些LLM的网络协议,他依赖于其底层的大模型供应商(如 OpenAI)和我们自身服务应用所使用的 Web 框架(如 FastAPI)的协议
所以LangChain是LLM的上层组织者,我们使用LangChain调用LLM的API,我们需要考虑什么,需要了解LLM的接入方式,流式传输底层,谁实现的,LLM。
最后我们可以参考一下langchain的源码,对于这一块的实现,我们会发现:
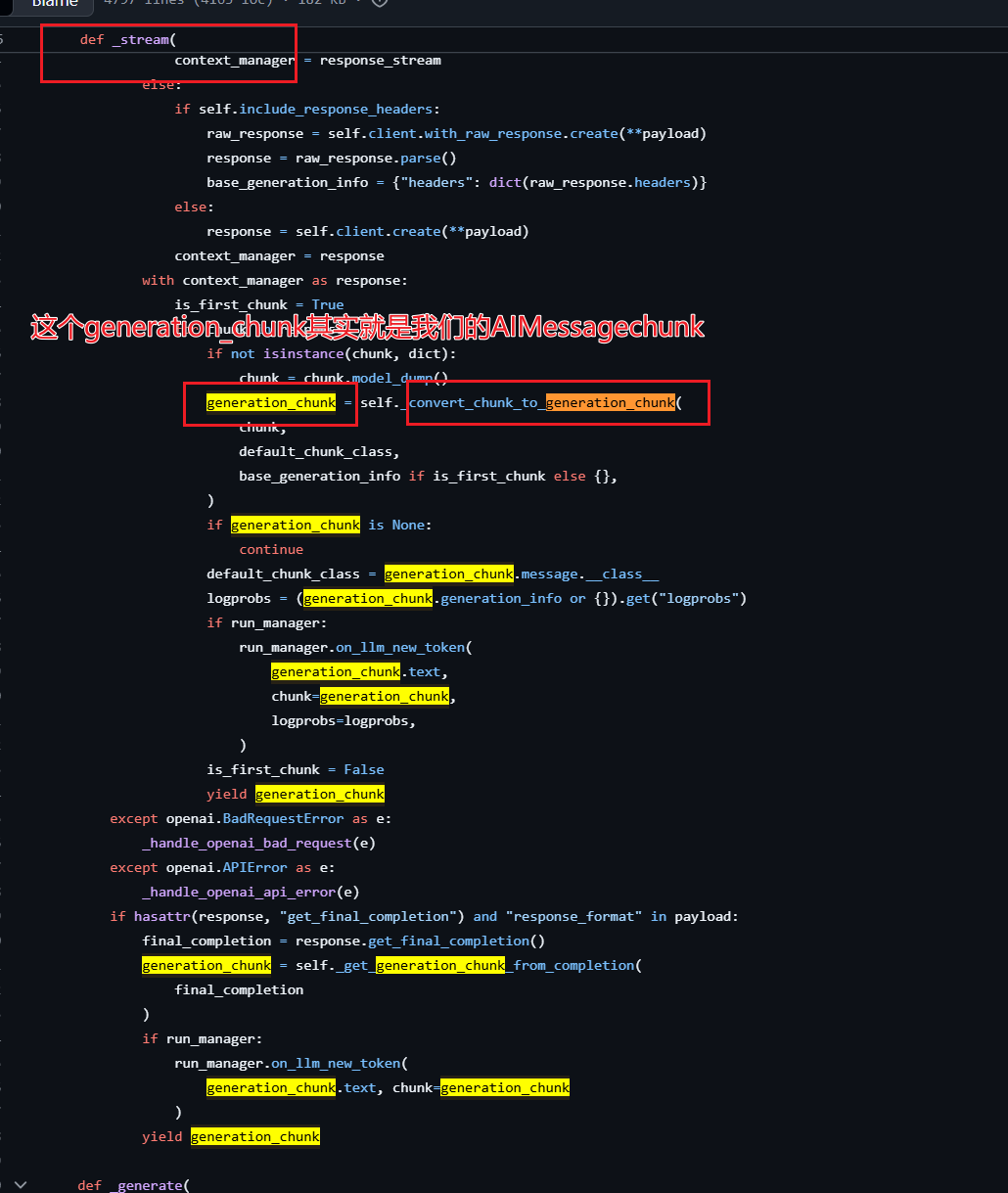
当我们发起请求时,会在请求中设置 stream=True ( _stream() 源码中的第⼀步)stream这一块的源码base.py
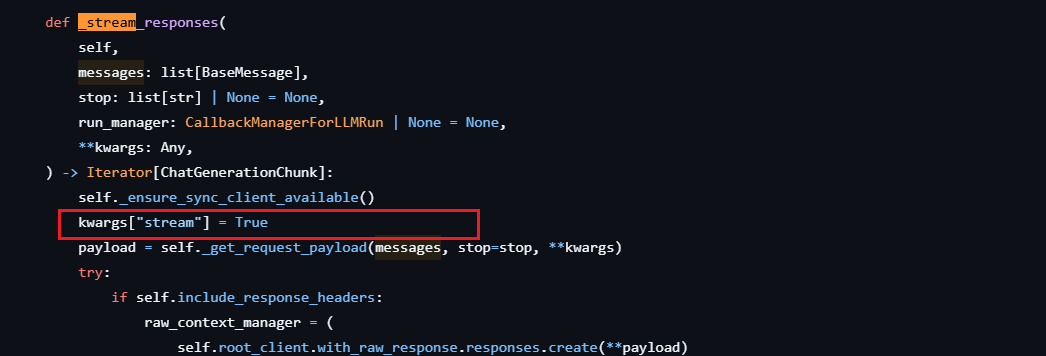
,然后LangChain会调用LLM自已的客户端(这里需要去LLM官网看一下具体访问的url是谁?(最新的)),源码_client_utils.py
然后LangChain将LLM返回给自已数据流,也就是我们抓包工具的一个个LLM的chunk:
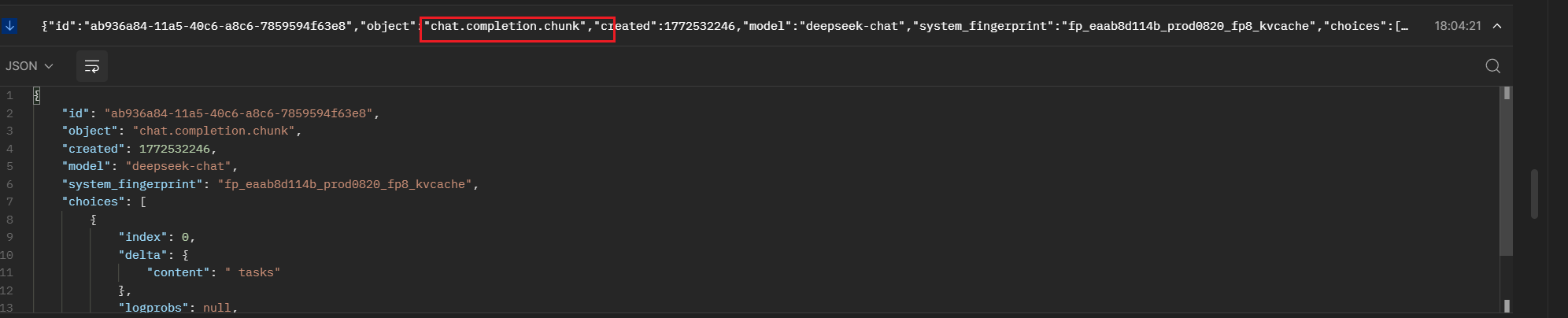
LangChain将其封装为了自已的(AIMessageChunk)如何转换的,就是取出LLM返回的块字段,最后构建AIMessageChunk,源码还是在base.py
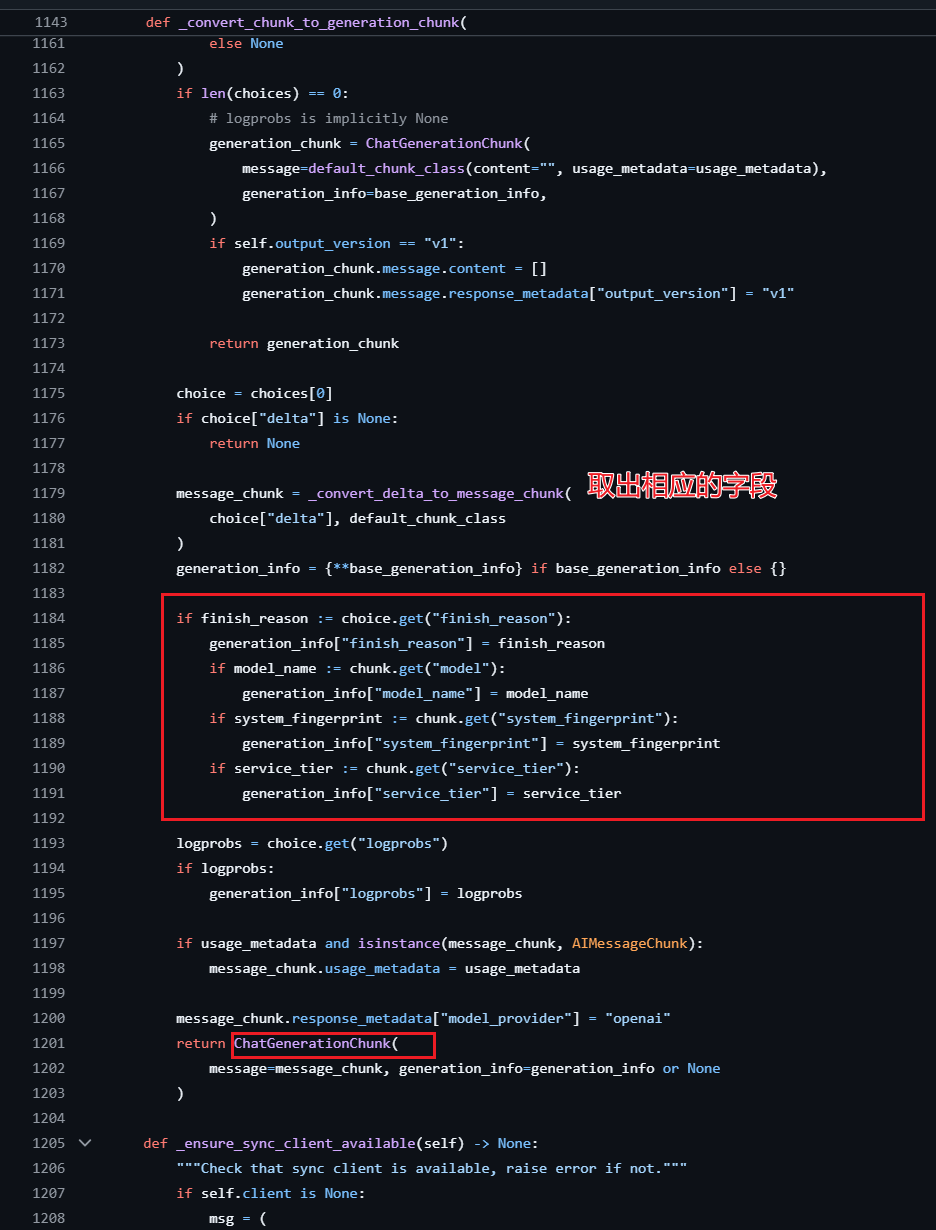
回到stream,将 OpenAI 数据块转换为 AIMessageChunk 数据块
在推荐一个LangChain的可以用于调试的工具,我们能够检查链或代理内部到底发⽣了什么变得⾄关重要。最好的方法是使用 LangSmith,接下来配置两个环境变量:
LANGSMITH_TRACING="true"
LANGSMITH_API_KEY="你的 LangSmith API Key"
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)