通过高通AI推理套件对比大模型输出效果
该参数设置了需要生成的最大输出。但是,由于令牌的大小可能因模型而有所不同,因此该参数与字符数、单词数、或其他以人为中心的计数概念并不严格相关。如果设置过低,该参数会切断大模型内容的生成。对于某些提示词而言,由于明确的指令和所需要的输出格式,预期输出很短,该参数可减少不必要的输出 tokens 生成 —— 还可能降低成本。例如:如果我们使用下面的示例提示词,那么我们期望输出是一个单词,因此我们的最大

作为使用闭源AI模型的消费者,除了选择模型外,可调整的参数并不多,或许还能调整响应的语气风格。而当使用通过任意常规推理层(包括高通AI推理套件)提供的开源AI模型时,可以选择修改对输出造成影响的若干参数。
温度、Top P、Top K、重复惩罚\和最大tokens:这些参数的含义是什么?什么时候应当对这些参数进行调整?若查看API,会发现还有更多参数需要调整,但这些都是大多数开发者通过聊天用户界面接触的参数。若要优化提示词以完成实际任务,则该如何设置这些参数?默认设置是否属于最佳选择?
在本示例中,我们设计了一种方法,可对比两个不同的大模型:这种理念的目的是帮助理解在相同提示词下,不同模型及参数如何影响输出结果。您可以根据这一理念坚持使用默认设置并对模型进行简单比较,也可以针对您的用例进一步调整设置。
您的输出目标是什么?
要弄清楚如何设置这些参数,最好首先考虑大模型(LLM)应该输出什么样的结果。大多数关于这些参数的描述都集中在两个极端:1) 结构化事实性回答 - 更具确定性;或2) 具有多样性表达或理念的创意性输出。
因此,如果您在总结文本,或许希望输出内容紧扣事实且语气专业;如果您在为社交媒体生成营销文案,则期待更具创意的输出,以便有更多可选方案。在编写代码时,人们则并不需要 “创意性” 代码,能正常运行且易于理解的代码才更有价值。对于客户情感分析这类简单评估,默认设置即已足够。
定义
最大令牌 (Max tokens):该参数设置了需要生成的最大输出。但是,由于令牌的大小可能因模型而有所不同,因此该参数与字符数、单词数、或其他以人为中心的计数概念并不严格相关。如果设置过低,该参数会切断大模型内容的生成。对于某些提示词而言,由于明确的指令和所需要的输出格式,预期输出很短,该参数可减少不必要的输出 tokens 生成 —— 还可能降低成本。
例如:如果我们使用下面的示例提示词,那么我们期望输出是一个单词,因此我们的最大tokens可以设置为低水平。不断尝试是发现符合您业务用例的最大令牌正确数值的关键。为什么要生成您不需要的tokens?
Prompt> Please evaluate the following customer feedback and answer only with positive, negative, or neutral. Only answer positive, negative, or neutral in lowercase.
Feedback: ‘We loved this hotel and will be coming back again!’
LLM response> positive
温度 (Temperature):温度通常被描述为控制tokens选择的随机性。在实践中,这意味着如果将温度设置为零,则总是会选择最有可能的下一个tokens – 即基于训练的事实性回答。如果将温度设置得较高,则会引入随机性,这意味着生成的文本应该更具“创意性”。对于构思等创意性任务,通常将温度设置为0.7。
一个重视创意性的提示词示例可能是这样的:“你是一名文案和营销专家。请为我的新型小工具提出20个展示创意。以下是关于这个小工具及其用途的事实信息:事实1、2,等等。
在将同一模型的输出与不同温度进行比较时,您会发现较高温度参数的输出具有更广泛词汇和更高创意性的更多理念。相反,如将温度设置为0,并采用较低的Top P(在下文中说明),则会产生一组范围狭窄的建议,这些建议往往会重复提示词中的事实。
重复惩罚 (Repetition Penalty):在幕后,该参数会对重复tokens 或短语施加惩罚。如设置过低,则很可能会导致相同的短语不断地重复(可能与提示词无关)。如设置过高,则生成的回答可能表现出类似阿尔茨海默病患者的思维特征。它会完全忘记一条推理线索,并转向另一个方向 – 有时不止一次。在1.1的基础上上下浮动0.1的微小修改也可能会产生差异 – 但在大多情况下,会保持为1.1的默认值。
Top P:Top P采样,也称为核采样,是大模型用来控制所创建文本随机性的一种解码策略。该策略不是从整个词汇表中选择序列中的下一个单词,而是对可能性进行排序,然后根据符合Top P选项百分比的累积概率选择一个子集。因此,较高的Top P值意味着更多的选项(单词)和更高的创意性,而较低的Top P值则更有可能从较小的“安全可靠”选项集中选择下一个单词。
这个理念类似于温度设置的工作原理。为了获得最具创意性的回复,可以将高温度与高Top P值相结合。这样,相对于训练数据集,选择单词的方式就会有变化。
Top K:Top K的效果与Top P非常相似,因为该参数限制了可供选择下一个tokens的实际tokens数量。如果Top P使用概率排序,则Top K使用绝对数量的tokens来限制大模型选择输出的下一个tokens。Top K值越高意味着越有创意性。
典型组合
针对典型场景进行总结:
- 较高的温度、Top P和Top K:通过多样化的单词选择,产生更有创意性的输出
- 较低的温度、Top P和Top K:适合更具确定性和事实性的输出
- 重复惩罚:调整到略高于代码输出的水平,以减少循环
所有这些设置都会影响输出;因此,如果您正在进行头脑风暴,如能尝试这些设置并通过相同的提示词重新生成输出,就可以为您产生更多的可能性。如果您的目标是获得大量选项,而不是一次性回答,这一点尤其有用。
用于比较的工具
典型大模型聊天界面的一个缺点是一次只能生成一个回复。当您修改这些参数时,输出不会捕获用于生成回复的参数组合。
为了更好地理解和直观展示其效果,我们在 GitHub仓库中创建了一个代码示例,该示例不仅可以针对各个参数,还可以针对支持标准OpenAI API聊天接口的任何提供商端点所提供的大模型比较回复内容。在我们的示例中,我们调用了搭载高通AI加速器、并由合作伙伴Cirrascale公司托管的高通AI推理套件。
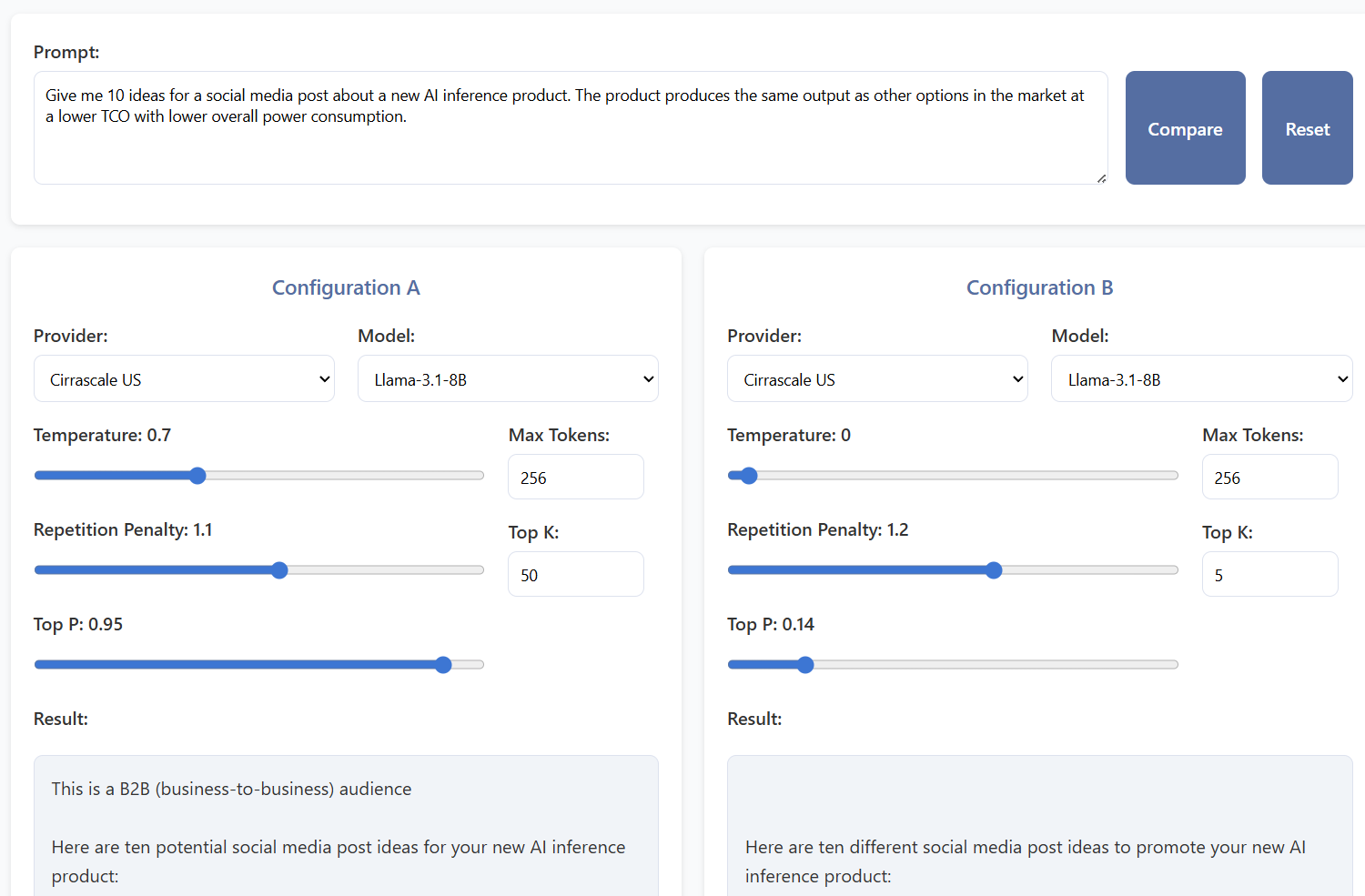
请亲身尝试一下
您可以使用该GitHub仓库中的示例代码亲身尝试一下。尝试将端点配置文件更改为由不同公司托管的大型语言模型示例。或者将提示词更改为需要创意性的任务或需要明确答案的任务。
以不同的方式使用配置A和B的设置,以了解更改其设置对输出造成的影响,或者只是比较两个不同的大模型。
在使用该示例之后,请在高通Cloud AI Discord社区频道上告诉我们您为自己的场景创建了什么内容。
请务必通过我们的合作伙伴Cirrascale注册免费令牌并检索您的API密钥。
探索Cloud AI博客系列中的其他主题。
在所发布内容中表达的观点仅为原作者的个人观点,并不代表高通技术公司或其子公司(以下简称为“高通技术公司”)的观点。所提供的内容仅供参考之用,而并不意味着高通技术公司或任何其他方的赞同或表述。本网站同样可以提供非高通技术公司网站和资源的链接或参考。高通技术公司对于可能通过本网站引用、访问、或链接的任何非高通技术公司网站或第三方资源并没有做出任何类型的任何声明、保证、或其他承诺。
高通品牌产品均为高通技术公司和/或其子公司的产品。
关于作者
雷·史蒂文森,云开发者关系主管

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)