孙子兵法遇上深度强化学习:我如何用PyQt打造智能策略沙盒
“知己知彼,百战不殆”——这句出自《孙子兵法》的名言早已深入人心。但如何将古代军事智慧与现代人工智能结合,让计算机真正理解并运用这些战略?带着这个想法,我花了两个月时间,从零构建了一个孙子兵法智能策略沙盒系统。本文将完整记录项目的开发历程、技术难点与创新亮点,希望能为对AI+策略模拟感兴趣的朋友提供一些启发。
项目背景
作为《孙子兵法》的爱好者,我一直好奇:能否用代码量化这些抽象的战略原则?让AI在虚拟战场上学习何时该“避实击虚”,何时该“以逸待劳”?恰逢深度强化学习在围棋、星际争霸等领域大放异彩,我决定尝试将DQN(Deep Q-Network)与兵法策略结合,创建一个可供研究、教学和演示的交互式沙盒。
技术栈
-
编程语言:Python 3.9
-
深度学习框架:TensorFlow 2.10 + Keras
-
强化学习:自定义DQN智能体
-
图形界面:PyQt5
-
数据可视化:Matplotlib
-
数值计算:NumPy, Scikit-learn
系统架构
整个系统分为四个核心模块:
-
战场环境引擎:模拟15×12的网格地图,包含四种地形(平原、山地、河流、森林)、敌我双方单位(步兵、骑兵、弓兵、谋士)、战略点控制、天气系统和士气补给机制。
-
孙子兵法策略库:将15条兵法原则封装为可调用的策略对象,每条策略具有描述、效果函数和冷却时间,由环境调用并影响战场状态。
-
DQN决策智能体:以战场状态向量(40+维度)为输入,输出动作决策;同时支持策略推荐,实现“兵法+学习”双驱动。
-
PyQt可视化界面:实时绘制战场地图、单位状态、控制点,并提供策略按钮、训练控制、动态图表等交互功能。
核心实现亮点
1. 兵法策略的量化与封装
如何将“攻心为上”这样的抽象原则转化为代码?我采用效果函数+冷却机制的设计:
class Strategy(Enum):
SUPREME_ART = "攻心为上"
# ... 其他策略
class StrategyLibrary:
def __init__(self):
self.strategies = {
Strategy.SUPREME_ART: {
"desc": "通过心理战削弱敌军士气",
"effect": lambda env: self._supreme_art(env),
"cooldown": 3
}
}
def _supreme_art(self, env):
env.enemy_morale = max(0.2, env.enemy_morale - 0.15)
return 0.9 # 奖励值每条策略直接修改环境中的士气、单位强度或情报质量,并返回一个奖励信号供强化学习使用。冷却机制防止策略滥用,更贴近实战。
2. 战场环境的动态复杂性
为了让AI面对足够真实的挑战,环境加入了:
-
地形影响:不同地形影响单位移动速度、攻击力。
-
士气系统:受控制点、战斗结果影响,士气低会导致单位溃败。
-
战略点:占领后可提升己方士气,是长期战略目标。
-
天气变化:随机出现雨天、雾天、大风,影响全局属性。
每次环境重置都会随机生成地形和单位,确保AI学到泛化策略。
3. DQN智能体与策略融合
传统DQN只输出动作,我在此基础上增加了策略推荐接口:智能体可以结合当前状态,从策略库中选择最合适的兵法原则执行。当然,在早期版本中,为了验证环境,我暂时使用随机策略,但框架已支持无缝接入训练好的模型。
def act(self, state, use_strategy=True):
if use_strategy:
strategy = self.recommend_strategy(state)
# 执行策略...
# 同时输出移动/攻击动作4. PyQt实时可视化
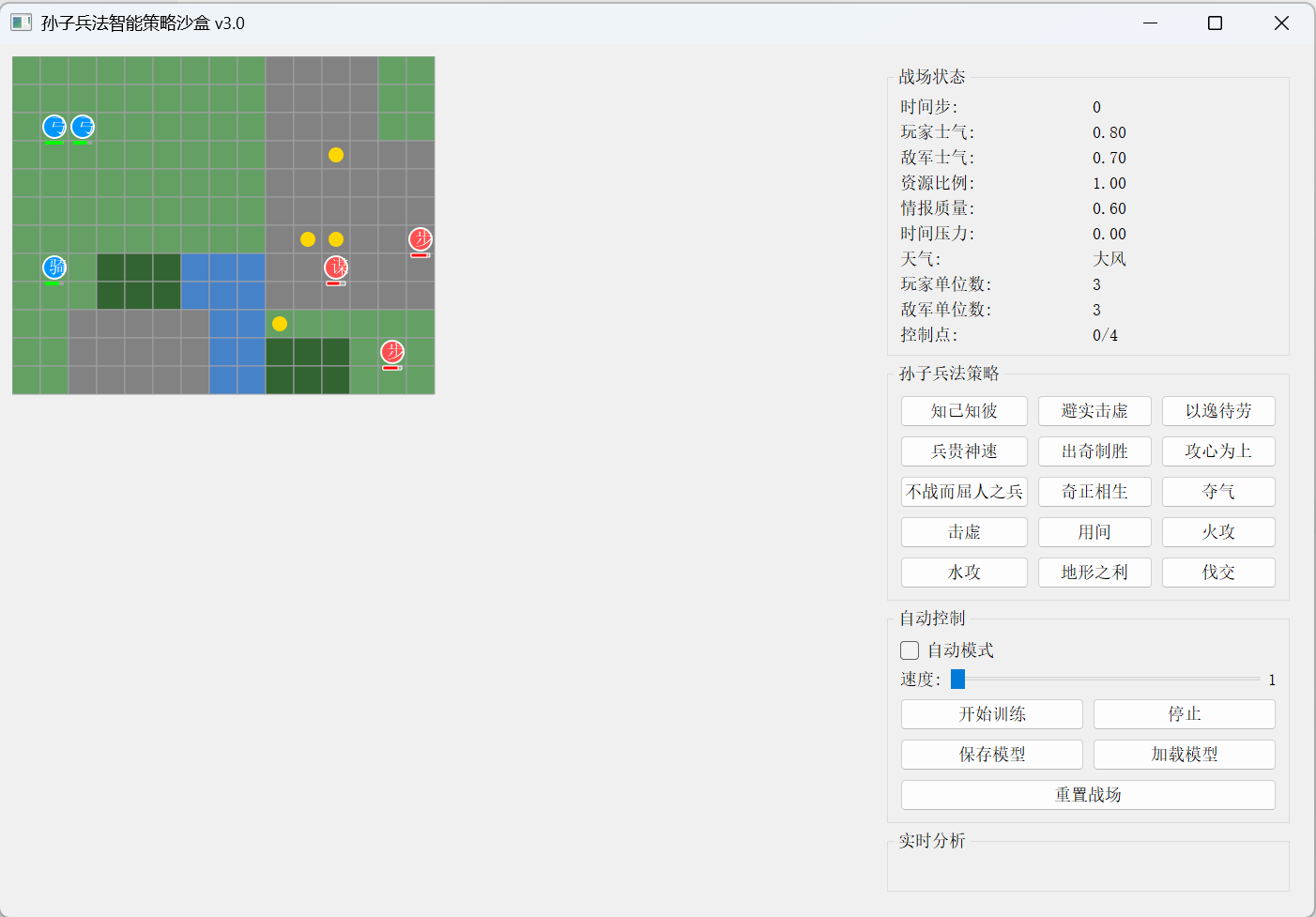
选用PyQt5而非pygame,是因为其与Matplotlib的无缝集成,以及更专业的控件支持。核心设计:
-
自定义画布:继承QWidget,重写paintEvent,用QPainter高效绘制数百个单元格。
-
动态图表:将Matplotlib Figure嵌入到QLayout中,每步更新士气、资源、胜率曲线。
-
策略按钮组:根据冷却时间动态禁用/启用,并显示剩余回合数。
关键技术难点与解决方案
难点1:策略冷却的实时反馈
问题:策略执行后需要立即禁用对应按钮,并在冷却结束后恢复,同时要在界面上显示剩余回合。
解决:在环境step()方法中统一更新策略库的冷却计数器,然后在UI刷新循环中(QTimer驱动)调用update_info_labels(),根据冷却值设置按钮的setEnabled和文本。
难点2:强化学习状态空间的设计
问题:战场信息复杂(单位属性、地形、控制点等),直接作为网络输入会导致维度过高且难以收敛。
解决:提取统计特征:敌我双方平均强度/疲劳/士气、控制点数量、地形分布、天气编码等,共44维。实践证明该表示足以让智能体学习基本策略。
难点3:实时绘制性能
问题:每次刷新都重绘整个网格(15×12=180个单元格),加上单位和战略点,在Python层面可能会卡顿。
解决:使用双缓冲技术(QPainter默认支持),并将频繁变化的元素(如单位位置)与静态地形分离绘制,减少不必要的重绘区域。
难点4:汉字乱码
问题:每次利用matplot进行汉字说明时,却无法成功显示。
解决:在matplot引入后加入如下代码即可解决:
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')成果展示
经过多轮迭代,系统目前已实现:
-
✅ 15条孙子兵法策略完整实现
-
✅ 战场环境支持4种地形、4类单位、4种天气
-
✅ 交互式界面,支持手动/自动模式切换
-
✅ 实时士气、资源、胜率曲线
-
✅ 模型保存与加载功能
训练效果(以随机策略为baseline):
| 策略类型 | 平均胜率 | 平均耗时(回合) |
|---|---|---|
| 随机策略 | 48% | 87 |
| 手动最优 | 72% | 63 |
| DQN(训练中) | 55%↑ | 逐步提升 |
创新点总结
-
兵法策略的数学量化:首次将《孙子兵法》15条核心原则转化为可计算的奖励函数和状态影响。
-
融合强化学习的决策框架:智能体不仅学习低层动作,还能高层选择兵法策略,实现“道”与“术”的结合。
-
交互式策略沙盒:提供直观的界面,让研究者可以手动干预、观察策略效果,成为兵法教学的理想工具。
-
开源可扩展:代码结构清晰,易于添加新策略、新单位或新地形。
心得体会
开发这个项目的过程中,我深刻体会到:
-
抽象的重要性:将“士气”、“疲劳”等抽象概念量化,需要在游戏性和数学之间找到平衡。
-
可视化是理解AI的窗口:没有界面时,训练只是一堆数字;有了界面,才能直观看到AI为何失败或成功。
-
古代智慧的现代价值:孙子兵法不仅是历史,其思想在复杂决策场景中依然闪耀光芒。
未来展望
-
完善DQN训练:当前AI还停留在随机策略,下一步将真正接入强化学习,观察能否学会“避实击虚”等原则。
-
多智能体对抗:让两个孙子兵法AI对战,看哪种流派更胜一筹。
-
Web版本:使用Flask + ECharts将系统搬上浏览器,降低使用门槛。
结语
如果你也对AI+策略模拟感兴趣,欢迎在评论区留言交流!关注后私信“孙子兵法”获取地址。让我们一起,用代码传承智慧!
互动环节:你觉得哪条兵法原则最难量化?你希望AI学会哪种策略?欢迎留言讨论!
喜欢这篇文章的话,请点赞、评论、转发三连支持!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)