[ICLR 2025]Geometry of Long-Tailed Representation Learning: Rebalancing Features for Skewed Distribu
计算机-人工智能-长尾分布特征塌缩控制图像分类

目录
2.3.1. Long-tailed Recognition
2.3.2. Contrastive Learning for Long-tailed Data
2.4. Theoretical Analysis: Long-tailed Data Skew Contrastive Feature Representations
2.4.2. Optimal Representation Configuration
2.5.1. Challenges in Long-tailed Representation Learning
2.6.1. Dataset and Implementation Details
1. 心得
(1)一想到写论文就会有想读论文的想法,哎......写论文的无限延期......
(2)预感是非常tough的一篇
2. 论文逐段精读
2.1. Abstract
①深度学习通常在数据平衡的地方取得不错的成果(啊哈哈哈
②作者尝试直面现实长尾分布,去发现尾类在特征空间中收缩到一个点导致不可分割
③作者试图重塑特征空间,将尾类分开,因此提出FeatRecon
2.2. Introduction
①对于平衡的数据量,对比损失可以让各个类收敛到各自的中心
②但是对于长尾数据来说,头部类别占据了几乎整个特征空间,不同类别的收敛是不对称的
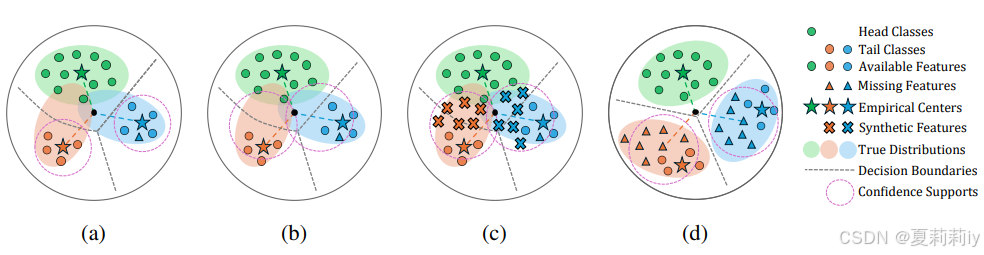
③假设每个类特征最终会收敛到超球上一个点,作者继续假设有四个类别,每个类别的样本个数分别是
,然后2、3、4类是一模一样的样本个数,只变动1,(a)到(c)就是
的样本量
疯狂变动时特征收敛的场景:
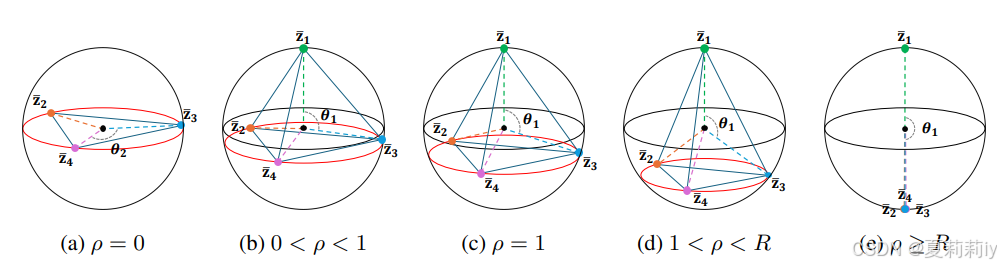
④现在的方法通常让尾类也收敛到头部类,会非常矛盾
⑤作者提出的FeatRecon会让特征收敛到对称和线性可分的地方
2.3. Related Works
2.3.1. Long-tailed Recognition
①传统长尾办法:重采样和权重重分配
②作者想使用的办法是因果权重归一化或边界调整
2.3.2. Contrastive Learning for Long-tailed Data
①对比学习在表征学习上取得了很大的成功
②作者自己想用在尾类生成特征的方式来帮助类别平衡
2.4. Theoretical Analysis: Long-tailed Data Skew Contrastive Feature Representations
2.4.1. Preliminaries
①对于个训练样本
,会有
个类别
②标签,
③是
维超球体的球面
④编码器是映射,最后的表征
⑤假设所有样本都在同一个批次里训练:,
表示属于类别
的样本,
,
⑥定义1:在有监督对比学习损失中,是超球面上的解,对于
个类别(为了实现球面上正单形每个点距离夹角相等),监督对比损失
定义为:
⑦定义2:当以下三种情况成立的时候超球面上有个正单形解
:
| (1) | |
| (2) | |
| (3) |
2.4.2. Optimal Representation Configuration
①当每个类平衡的时候,对比损失可以最低,所有点会形成一个正单形
②如果每个类别样本平衡,有:
右边是对比损失理论最小值,理论最优值在以下两种情况成立时出现:
| (1) | |
| (2) |
③当类别不平衡,假设除了第一个类别,所有类别样本数还是相等。作者首先找到紧凑的对比损失下限:
且
这里的是所有相等类别的样本数量,等式在以下场景成立:

④和
的关系:
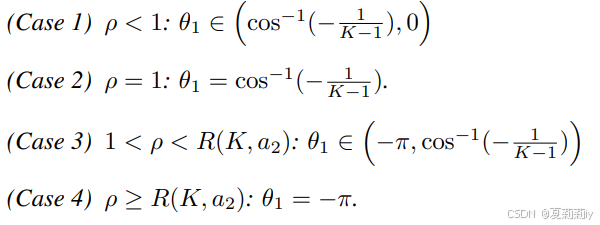
这里的是不平衡比例,
,这四个case就是作者最开始的图例
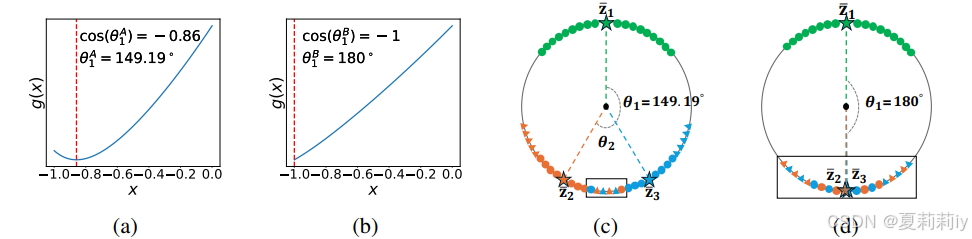
⑤当头部样本超过尾部样本的倍时,尾部会完全塌缩:
其中,
⑥(a)中样本比例时10:1,(b)中时100:1,(c)和(d)是(a)和(b)分别的示例图
2.5. Method
2.5.1. Challenges in Long-tailed Representation Learning
①尾部塌缩之后,样本交叠了
②长尾情况下,左边时没有中心矫正的,右边有
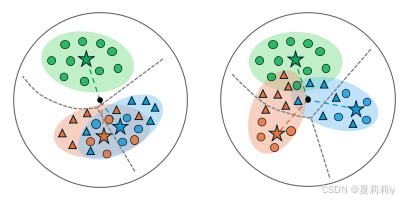
右边的还是有交叠,因为中心矫正可能只能针对训练集,但因为训练集和测试集本身有gap,所以不一定对测试集生效
2.5.2. FeatRecon
①学习的四个阶段,其中红虚线圈是预测,×符号是增加的合成数据
②类中心:
其中是
分位数
③对于尾类,我们选前和这个尾部类中心
最相近的
个头部类:
正则化:
其中是权重,用相似度和样本量计算出来
④类别的置信支持(fine 我也不知道confidence support怎么翻译):
⑤以前的工作会研究温度系数如何影响表征,温度系数越大,类间就越分离
其中温度系数下标的加减分别代表上界和下界,低温 (ττ 小):模型更关注难分样本(与锚点相似的正/负样本,就是尾类样本),高温 (ττ 大):模型更关注全局结构,头部样本准确率会更高一点,均匀拉远所有负样本。作者的缩放就是让尾部类系数低一点然后头部类系数高一点
⑥FeatRecon有个特征提取器,然后是分开的分类器(交叉熵)和投影器(对比损失)
⑦带logit补偿的交叉熵损失,更多惩罚尾部类:
⑧总损失:
2.6. Experiments
2.6.1. Dataset and Implementation Details
①类不平衡数据集:CIFAR-10-LT和CIFAR-100-LT,作者将不平衡因子按照以前论文设定为100,50和10;ImageNet-LT,不平衡因子为256;iNaturalist 2018是超大数据集有437.5K图像和8142类,作者按照别人的方法把测试集划分成三个子集,分别有100多个实例,20~100个实例和20个实例。
(1)CIFAR-10-LT和CIFAR-100-LT数据集的配置
①主干:ResNet-32
②投影仪:2层的MLP,嵌入是128维,隐藏层是512
③Epoch:200
④Batch size:256
⑤优化器:SGD,动量为0.9,5e-4的权重衰减,学习率一开始预热是0.15但是后面用0.1衰减
⑥分类头使用AutoAug和CutOut
⑦超参数:,
,
用Kukleva的方法来缩放
(2)ImageNet-LT和iNaturalist 2018
①主干:ResNet-50
②其他不想写了看截图:
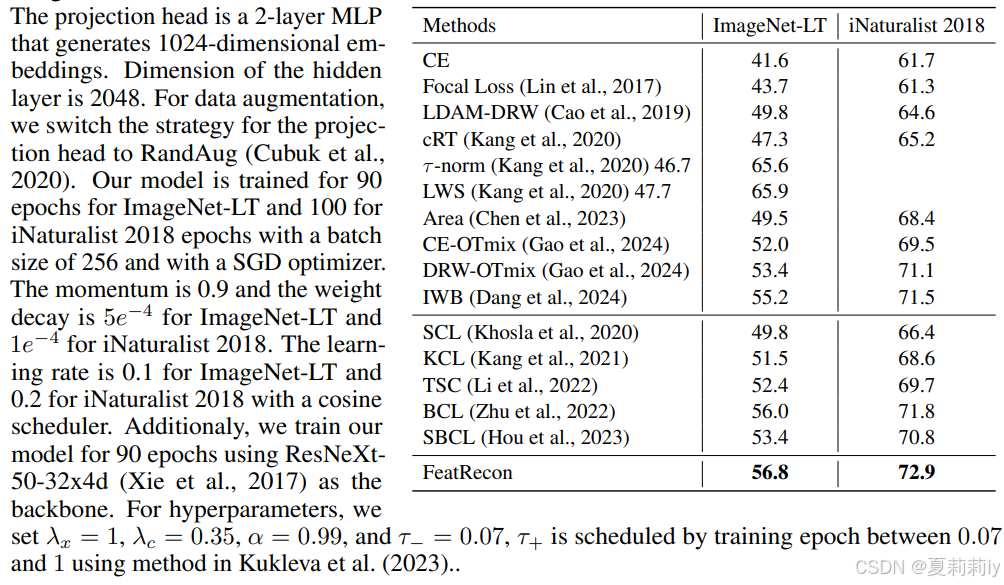
2.6.2. Resultes
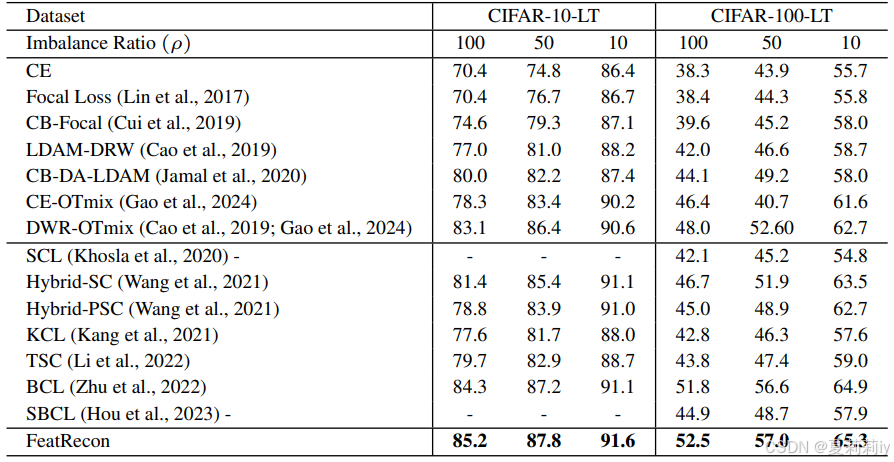
①用ResNet-32主干在CIFAR-10/100-LT数据集上不同不平衡因子下不同方法的Top 1精确度
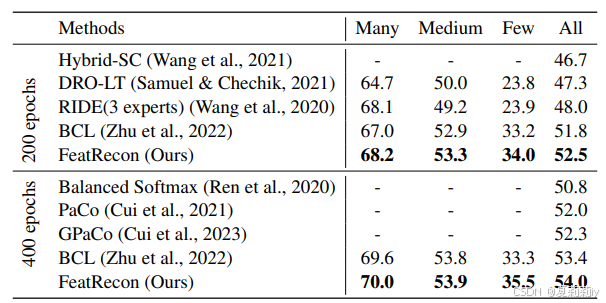
②用ResNet-32主干在CIFAR-10/100-LT数据集上不平衡因子等于100下不同方法不同epoch的Top 1精确度
③ResNet-32主干在ImageNet-LT和iNaturalist 2018数据集上的表现:
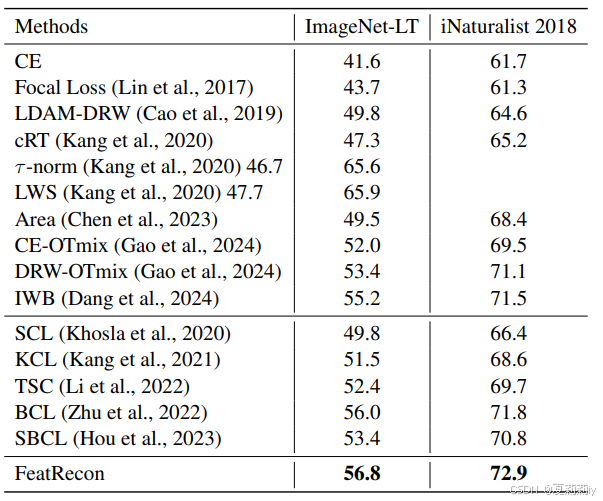
④ResNeXt-50主干在ImageNet-LT数据集上的表现:
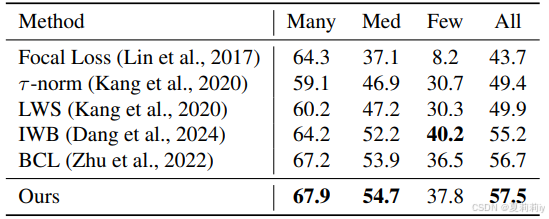
2.6.3. Abalation Study
①CIFAR-100-LT数据集上不同组件的消融:

2.7. Conclusion
~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)