AI人工智能-文本匹配任务-第八周(小白)
文本匹配是NLP(自然语言处理)的基础任务,核心是判断两段文本的“关联程度”,分为和。
一、什么是文本匹配任务
文本匹配是NLP(自然语言处理)的基础任务,核心是判断两段文本的“关联程度”,分为狭义和广义。
1.狭义文本匹配
-
核心目标:判断两段文本的意思是否相近,结果可是 “匹配 / 不匹配”(分类)或 “相似度分值”(0-1 之间,1 表示完全相似)。
-
例子:
-
匹配:“今天天气不错” vs “今儿个天不错呀”(相似度 0.9)
-
不匹配:“今天天气不错” vs “你的代码有 bug”(相似度 0.1)
-
2.广义文本匹配
除了语义相似,还包括更灵活的关联判断,常见场景:
-
自然语言推理(NLI):判断两句话的关系(关联 / 矛盾 / 中立),比如 “明天要下雨” vs “明天大晴天”(矛盾)。
-
文本蕴含(Text Entailment):判断一段文本是否支持 / 反驳某个假设,比如 “小明今天没上班” vs “假设:小明今天在公司”(反驳)。
-
主题判断:比如 “文章标题” 是否匹配 “文章内容”。
二、应用场景:文本匹配用在哪?
1. 问答对话场景
-
核心逻辑:用户输入问题 → 系统通过文本匹配找到 “最相似的标准答案” → 回复用户。
-
常见产品:智能客服(京东 / 淘宝的自动回复)、聊天机器人( Siri / 小爱同学)、车载导航、手机助手。
2. 信息检索场景
-
核心逻辑:用户输入关键词 → 系统通过文本匹配找到 “最相关的文档 / 内容” → 展示结果。
-
常见产品:搜索引擎(百度 / Google)、自媒体平台(头条 / 爱奇艺的内容推荐)。
3. 文本匹配的三种类型(按文本长度分)
| 匹配类型 | 应用场景 | 例子 |
|---|---|---|
| 短文本 vs 短文本 | 知识库问答、聊天机器人 | 用户问 “京东钱包是什么” vs 知识库中的标准问 “什么是京东钱包” |
| 短文本 vs 长文本 | 文章检索、广告推荐 | 用户搜 “深度学习入门” vs 多篇技术博客(长文本) |
| 长文本 vs 长文本 | 新闻关联推荐、论文查重 | 一篇体育新闻 vs 其他相关体育新闻 |
三、智能问答:文本匹配的典型应用
1.智能问答的基本流程
基础资源(Faq/书籍/网页)->问答系统(加工资源成索引/模型)->用户输入问题->系统通过文本匹配找到答案->输出答案
2.关键名词(必须记住)
-
问答对:一个问题(或多个相似问题)+ 对应的答案(比如 “什么是京东钱包?”+ 京东钱包的定义)。
-
Faq 库(知识库):大量 “问答对” 的集合(比如京东客服的常见问题库)。
-
标准问:一组相似问题中的 “代表”(比如 “什么是京东钱包?” 是标准问)。
-
相似问(扩展问):和标准问意思相近的其他问题(比如 “京东钱包是什么呀?”“这个京东钱包有什么用?”)。
-
用户问:用户实际输入的问题(比如 “我想了解京东钱包”)。
-
知识加工:人工编辑faq库的过程
3.Faq知识库问答的运行逻辑
这是必须掌握的 “实操流程”,也是文本匹配的直接应用:
用户问->预处理->与Faq库中问题计算相似度->按相似度排序->返回最相似问题的答案
步骤拆解:
1.预处理:对用户的问题做“清洁”,方便后续计算(关键步骤)常见操作:分词(把句子拆成词)、去停用词(去掉 “的 / 了 / 吗” 等无意义词)、去标点、大小写转换(英文场景)。
-
例子:用户问 “请问京东钱包是啥呀?” → 预处理后 → “京东钱包 是 啥”(去标点、去停用词 “请问”“呀”)。
2.相似度计算:用文本匹配算法,计算“预处理后的用户问”与Faq库中所有“标准问/相似问”的相似度
3.排序+返回答案:把相似度高的问题对应的答案,返回给用户
四、核心算法:文本匹配怎么算
1.算法1:编辑距离(最直观的字符级匹配)
核心思想:
计算 “把一个字符串改成另一个字符串” 需要的最少操作次数(操作包括:替换、插入、删除一个字符),次数越少,相似度越高。
关键公式:
-
编辑距离(ED):最少操作次数。
-
相似度 = 1 -(编辑距离 / 两个字符串中较长者的长度)
-
例子 1:“今天天气不错”(7 字)vs “今儿个天不错呀”(8 字)→ 编辑距离 2 → 相似度 = 1-2/8=0.75。
-
例子 2:“我没钱” vs “俺没钱” → 编辑距离 1 → 相似度 = 1-1/3≈0.66。
-
优缺分析
-
优点:简单直观、可解释性强(能看到具体改了哪些字符)、跨语种有效(比如英文和中文都能用)。
-
缺点:不考虑语义(比如 “农行” 和 “农业银行” 编辑距离大,但语义相似)、受语序影响大(“天气不错今天” 和 “今天天气不错” 相似度低)。
代码实现(动态规划)
import numpy as np
# 编辑距离
def edit_distance(string1, string2):
matrix = np.zeros((len(string1) + 1, len(string2) + 1))
for i in range(len(string1) + 1):
matrix[i][0] = i
for j in range(len(string2) + 1):
matrix[0][j] = j
for i in range(1, len(string1) + 1):
for j in range(1, len(string2) + 1):
if string1[i - 1] == string2[j - 1]:
d = 0
else:
d = 1
matrix[i][j] = min(matrix[i-1][j] + 1, matrix[i][j-1] + 1, matrix[i-1][j-1] + d)
return matrix[len(string1)][len(string2)]
# 基于编辑距离的相似度
def similarity_based_on_edit_distance(string1, string2):
return 1 - edit_distance(string1, string2) / max(len(string1), len(string2))
s1 = "今天天气不错"
s2 = "今儿个天不错呀"
result = similarity_based_on_edit_distance(s1, s2)2.算法2:Jaccard相似度(集合级匹配)
核心思想:
把两段文本看成“词/字的集合”,相似度=两个集合的“交集大小”/两个集合的“并集大小”(词袋模型,不考虑语序)
关键公式:
Jaccard 相似度 = |A ∩ B| / |A ∪ B|(A、B 分别是两段文本的词 / 字集合)
-
例子:“今天天气真不错”(字集合:{今,天,气,真,不,错})vs “估计明天天气更好”(字集合:{估,计,明,天,气,更,好})→ 交集:{天,气}(大小 2)→ 并集:{今,天,气,真,不,错,估,计,明,更,好}(大小 11)→ 相似度 = 2/11≈0.18。
优缺点分析:
-
优点:实现简单、速度快、不考虑语序(适合短文本匹配)、跨语种有效。
-
缺点:不考虑语义(“他打了我” 和 “我打了他” 相似度 1.0,但语义有差异)、受无关词影响大(比如 “的 / 了” 会增加交集)。
代码实现
def jaccard_similarity(s1, s2, level="char"):
# level:"char"(基于字)或 "word"(基于词,需先分词)
if level == "word":
# 简单分词(实际场景用jieba分词)
set1 = set(s1.split())
set2 = set(s2.split())
else:
# 基于字
set1 = set(s1)
set2 = set(s2)
# 计算交集和并集
intersection = len(set1 & set2)
union = len(set1 | set2)
# 避免除零(两个空字符串)
if union == 0:
return 0.0
return intersection / union
# 测试(基于字)
s1 = "今天天气真不错"
s2 = "估计明天天气更好"
sim = jaccard_similarity(s1, s2)
print(f"Jaccard相似度(基于字):{sim:.2f}") # 输出:0.18
# 测试(基于词,需先分词)
import jieba
s1_word = jieba.lcut("我去 农行 取钱")
s2_word = jieba.lcut("我去 农业银行 取钱")
sim_word = jaccard_similarity(" ".join(s1_word), " ".join(s2_word), level="word")
print(f"Jaccard相似度(基于词):{sim_word:.2f}") # 输出:0.67(交集:{我去,取钱},并集:{我去,农行,农业银行,取钱})3.算法3:BM25算法(搜索引擎常用,统计级匹配)
核心思想:
基于 “词的重要性” 计算相似度 —— 一个词在某类文本中出现多、在其他文本中出现少,这个词就 “重要”(比如 “黑洞” 在天文类文本中重要,在财经类中不重要)。
关键原理:
TF-IDF(词频-逆文档频率)
BM25 是 TF-IDF 的改进版,先理解 TF-IDF:
-
TF(词频):某个词在当前文本中出现的频率 → 出现次数越多,越重要。
-
公式:TF = 词在文本中出现次数 / 文本总词数。
-
-
IDF(逆文档频率):某个词在所有文本中出现的 “稀有程度” → 出现的文本越少,越重要。
-
公式:
-
N 代表文本总数,
代表包含词
的文本中的总数
-
词越常见(dfidfi 越大) → 分母
越大,整个比值越小,IDF 值越低 → 说明这个词区分度低,不重要。
-
词越罕见(dfidfi 越小) → 分子
越大,整个比值越大,IDF 值越高 → 说明这个词区分度高,重要。
-
-
TF-IDF = TF × IDF → 数值越高,词对当前文本越重要。
BM25公式
说明:
为问题中某词,
为词频,
为可调节常数,
为文档长度,
为所有文档平均长度。
- BM25中的
和IDF中的
BM25公式简化版
说明:
-
qi:查询中的第 i 个词;d:当前文档。
-
k1、b:调节参数(k1 控制词频饱和,b 控制文档长度影响,默认 k1=1.2,b=0.75)。
优缺点分析
-
优点:考虑词的重要性,效果比编辑距离、Jaccard 好;计算快,适合大规模文档匹配(比如搜索引擎)。
-
缺点:不考虑词的语义相似(“农行” 和 “农业银行” 视为不同词);需要一定量的文档集合(用于计算 IDF)。
代码实现
import json
import math
import os
import pickle
import sys
import jieba
from typing import Dict, List
class BM25:
EPSILON = 0.25
PARAM_K1 = 1.5 # BM25算法中超参数
PARAM_B = 0.6 # BM25算法中超参数
def __init__(self, corpus: Dict):
"""
初始化BM25模型
:param corpus: 文档集, 文档集合应该是字典形式,key为文档的唯一标识,val对应其文本内容,文本内容需要分词成列表
"""
self.corpus_size = 0 # 文档数量
self.wordNumsOfAllDoc = 0 # 用于计算文档集合中平均每篇文档的词数 -> wordNumsOfAllDoc / corpus_size
self.doc_freqs = {} # 记录每篇文档中查询词的词频
self.idf = {} # 记录查询词的 IDF
self.doc_len = {} # 记录每篇文档的单词数
self.docContainedWord = {} # 包含单词 word 的文档集合
self._initialize(corpus)
def _initialize(self, corpus: Dict):
"""
根据语料库构建倒排索引
"""
# nd = {} # word -> number of documents containing the word
for index, document in corpus.items():
self.corpus_size += 1
self.doc_len[index] = len(document) # 文档的单词数
self.wordNumsOfAllDoc += len(document)
frequencies = {} # 一篇文档中单词出现的频率
for word in document:
if word not in frequencies:
frequencies[word] = 0
frequencies[word] += 1
self.doc_freqs[index] = frequencies
# 构建词到文档的倒排索引,将包含单词的和文档和包含关系进行反向映射
for word in frequencies.keys():
if word not in self.docContainedWord:
self.docContainedWord[word] = set()
self.docContainedWord[word].add(index)
# 计算 idf
idf_sum = 0 # collect idf sum to calculate an average idf for epsilon value
negative_idfs = []
for word in self.docContainedWord.keys():
doc_nums_contained_word = len(self.docContainedWord[word])
idf = math.log(self.corpus_size - doc_nums_contained_word +
0.5) - math.log(doc_nums_contained_word + 0.5)
self.idf[word] = idf
idf_sum += idf
if idf < 0:
negative_idfs.append(word)
average_idf = float(idf_sum) / len(self.idf)
eps = BM25.EPSILON * average_idf
for word in negative_idfs:
self.idf[word] = eps
@property
def avgdl(self):
return float(self.wordNumsOfAllDoc) / self.corpus_size
def get_score(self, query: List, doc_index):
"""
计算查询 q 和文档 d 的相关性分数
:param query: 查询词列表
:param doc_index: 为语料库中某篇文档对应的索引
"""
k1 = BM25.PARAM_K1
b = BM25.PARAM_B
score = 0
doc_freqs = self.doc_freqs[doc_index]
for word in query:
if word not in doc_freqs:
continue
score += self.idf[word] * doc_freqs[word] * (k1 + 1) / (
doc_freqs[word] + k1 * (1 - b + b * self.doc_len[doc_index] / self.avgdl))
return [doc_index, score]
def get_scores(self, query):
scores = [self.get_score(query, index) for index in self.doc_len.keys()]
return scores
4.算法4:Word2Vec(语义级匹配,入门深度学习)
核心思想:
把 “词” 转换成 “向量”(比如 “苹果”→[0.12, 0.34, -0.56]),语义相似的词,向量在空间中距离近(比如 “苹果” 和 “梨” 的向量距离近,“苹果” 和 “电脑” 的距离远)。文本相似度可通过 “词向量的平均” 计算。
关键概念:
-
词向量:每个词对应一个固定维度的向量(比如 100 维、300 维),通过大量文本语料训练得到。
-
句向量:把句子中所有词的向量取平均,得到句子的向量表示,再通过 “余弦相似度” 计算两段文本的相似度。
余弦相似度(计算向量距离)
公式:
-
结果范围:[-1, 1],越接近 1,向量越相似。
优缺点分析
-
优点:考虑语义相似(“今儿个” 和 “今天” 向量近,相似度高);可扩展性强(后续可结合深度学习模型)。
-
缺点:一词多义无法处理(“苹果” 既指水果也指手机,向量相同);受语料质量影响大(语料少则效果差)。
代码实现
# 先安装gensim:pip install gensim
from gensim.models import Word2Vec
from gensim.models import KeyedVectors
import numpy as np
# 1. 训练Word2Vec模型(或加载预训练模型)
# 准备训练语料(大量文本,分词后)
corpus = [
jieba.lcut("今天天气不错"),
jieba.lcut("今儿个天不错呀"),
jieba.lcut("明天天气会更好"),
jieba.lcut("我喜欢晴天"),
jieba.lcut("我讨厌下雨天")
]
# 训练模型(参数:vector_size=向量维度,window=上下文窗口大小,min_count=最少出现次数)
model = Word2Vec(sentences=corpus, vector_size=100, window=5, min_count=1, workers=4)
model.save("word2vec.model") # 保存模型
# 2. 加载模型并获取词向量
model = Word2Vec.load("word2vec.model")
# 获取单个词的向量
word_vec = model.wv["天气"]
print(f"词向量维度:{word_vec.shape}") # 输出:(100,)
# 3. 计算句向量(词向量平均)
def sentence_vector(sentence, model):
words = jieba.lcut(sentence)
# 过滤掉模型中没有的词
words = [word for word in words if word in model.wv]
if not words:
return np.zeros(model.vector_size)
# 词向量平均
return np.mean(model.wv[words], axis=0)
# 4. 计算余弦相似度
def cosine_similarity(vec1, vec2):
# 计算点积
dot_product = np.dot(vec1, vec2)
# 计算模长
norm1 = np.linalg.norm(vec1)
norm2 = np.linalg.norm(vec2)
# 避免除零
if norm1 == 0 or norm2 == 0:
return 0.0
return dot_product / (norm1 * norm2)
# 测试
s1 = "今天天气不错"
s2 = "今儿个天不错呀"
vec1 = sentence_vector(s1, model)
vec2 = sentence_vector(s2, model)
sim = cosine_similarity(vec1, vec2)
print(f"Word2Vec余弦相似度:{sim:.2f}") # 输出:0.9+(语义相似,分数高)5.算法5:深度学习算法
5.1 表示型文本匹配
核心思想:“编码 - 匹配” 两步走
是用统一的编码器将文本转化为固定维度的句向量,再通过向量相似度(余弦距离、欧氏距离)计算匹配度。为了让句向量具有 “语义区分度”,通常采用对比学习或Triplet Loss训练,强制 “相似文本向量接近,不相似文本向量远离”。
关键技术核心
-
Siamese 网络结构:两个文本共享同一个编码器(如 BERT、LSTM),保证编码逻辑一致,避免向量空间错位。
-
句向量生成:对编码器输出的 Token 向量进行 Pooling(如 CLS 向量、均值 Pooling),得到整个句子的压缩向量。
-
对比学习训练:输入 “正样本对”(语义相似,如 “今天天气好” vs “今儿个天不错”)和 “负样本对”(语义无关,如 “今天天气好” vs “代码有 bug”),通过损失函数让正样本对距离更近、负样本对距离更远。
经典模型:Sentence-BERT(SBERT)
SBERT 是 BERT 的改进版,专为 “句向量生成” 优化,解决了原生 BERT 无法直接生成高质量句向量的问题,核心改进:
-
采用 Siamese/ Triplet 网络结构,支持对比学习训练;
-
对 BERT 输出的 Token 向量进行 “均值 Pooling + 归一化”,提升句向量稳定性;
-
预训练数据覆盖语义相似度任务(如 STS-B),开箱即用效果好。
训练方式(Triplet loss)
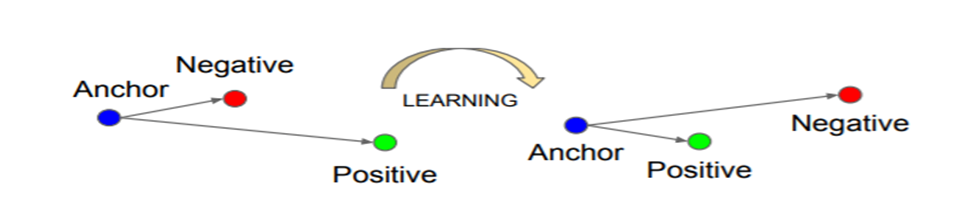
训练目标:
- 使具有相同标签的样本在embedding空间尽量接近
- 是具有不同标签的样本在embedding空间尽量远离
核心原理:
训练时输入三元组(Anchor, Positive, Negative),通过损失函数约束:其中:
- d(a,p):锚点与正例的距离;
- d(a,n):锚点与负例的距离;
- margin:间隔(让正例比负例至少近 margin 的距离)。
5.2交互型文本匹配
核心思想:边编码边交互
是在编码过程中让两个文本的特征直接交互,而非先生成独立句向量。通过 “注意力机制” 捕捉两个文本的局部关联(如 A 文本的 “白条” 与 B 文本的 “白条支付” 对应),再通过推理层组合交互特征,最终输出匹配度。
关键技术细节
-
注意力交互:计算文本 A 中每个 Token 与文本 B 中每个 Token 的关联权重(如 A 的 “支付” 与 B 的 “支付” 权重高),捕捉局部语义匹配;
-
上下文编码:用 LSTM、Transformer 等编码器捕捉文本内部的语序和上下文(如 “白条支付” 是一个整体语义);
-
推理组合:将局部交互特征(如注意力权重)与全局特征(如句子级编码)结合,通过全连接层输出匹配结果(分类:匹配 / 不匹配;回归:相似度分数)。
经典模型:ESIM(Enhanced Sequential Inference Model)
ESIM 是交互型的经典轻量模型,核心优势是 “用简单结构实现高精度”,适合小样本场景,结构拆解:
-
Embedding 层:将文本转化为词向量(可用预训练词向量如 GloVe、Word2Vec);
-
编码层:用双向 LSTM 编码文本,得到每个 Token 的上下文向量;
-
注意力交互层:计算两个文本 Token 间的注意力权重,生成交互特征;
-
推理组合层:通过 “差异特征”“乘积特征” 强化交互信息,再用 LSTM 编码组合;
-
输出层:全连接层输出相似度分数或分类结果。
两者的对比
| 维度 | 表示型(Sentence-BERT) | 交互型(ESIM/Cross-BERT) |
|---|---|---|
| 核心优势 | 速度快(预计算句向量)、支持大规模检索 | 精度高(捕捉局部交互)、适合复杂语义 |
| 推理速度 | 极快(向量检索毫秒级) | 较慢(每次需实时交互计算) |
| 数据需求 | 少量标注数据(或无),依赖预训练 | 需要更多标注数据(否则过拟合) |
| 适用场景 | 亿级 FAQ 检索、推荐系统、快速匹配 | 小样本问答、矛盾推理、高精度匹配 |
| 实现复杂度 | 低(调用预训练模型) | 中(手动搭建网络,需调参) |
五、海量向量查找:当 Faq 库很大时怎么办?
如果 Faq 库有 1 亿个问题,逐个计算相似度会很慢,这时需要 “高效向量查找算法”:
1. KD 树(精确查找)
-
核心:把向量空间分成多个小区域(类似二叉树),查找时先定位到目标区域,再逐步缩小范围。
-
适用场景:向量维度低(<20 维),需要精确结果。
2. Annoy(近似查找)
-
核心:通过 Kmeans 聚类把向量分成多个分支,查找时只在相近的分支中搜索,牺牲一点精度换速度。
-
适用场景:向量维度高(比如 100 维),大规模数据(1 亿 + 向量),允许轻微误差。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)