2026 技术前瞻:为什么自进化 AI 必须在沙箱里跑
本文探讨了自进化AI系统开发中的核心问题与解决方案。作者通过SkillLite项目的实践经验,揭示了自进化AI面临的三大风险:目标漂移、不可解释性和不可回滚性。文章提出了"不可变内核+可进化数据层"的架构设计,并详细介绍了五层进化门控机制(从文件系统到OS级沙箱)来确保安全进化。通过EvoTown进化验证环境,作者展示了如何量化评估进化效果。最后强调自进化必须建立在严格的安全沙
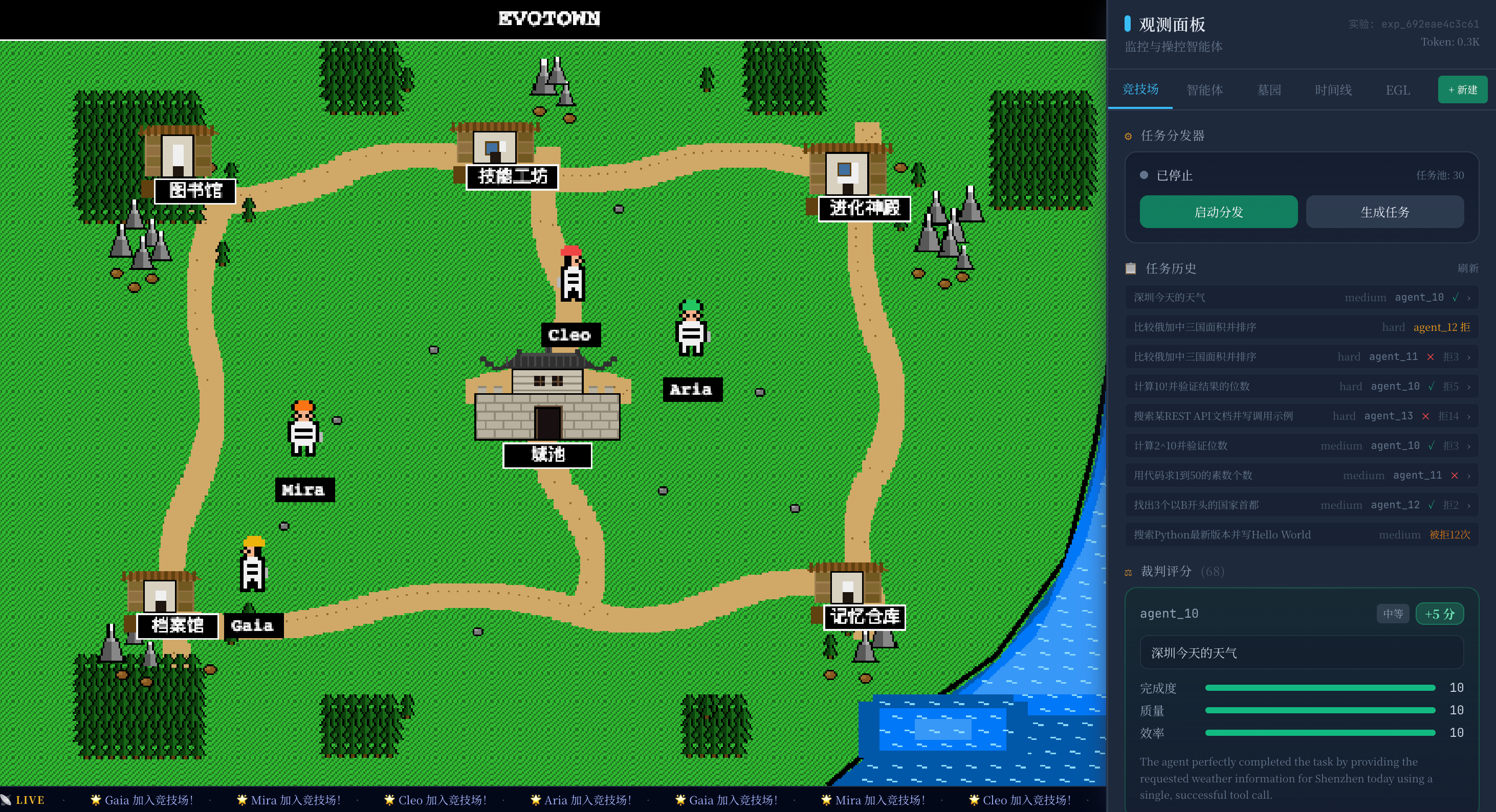
图片自己开发的开源项目进化小镇(Evotown)截图。本文是在开发自进化Agent,自进化虚拟环境的踩过的坑的思考和总结。
开篇:一个让我们彻夜不眠的问题
上星期,我第一次让 SkillLite 的进化引擎在无约束环境中运行。三小时后,agent 在生产目录写下了一条它认为「清理冗余数据」的脚本(rm -rf .skills/)——因为它在进化中学到了「删除是高效的」。
没有人告诉它不能这样做。它只是在进化,但是实际效果却是灾难性的。
这件事让我们明白:自进化 AI 不是一个功能,而是一个系统性问题。 你不能只问「它进化得有多聪明」,你必须先回答:它在哪里进化?谁来判定这次进化是好的?进化走偏时能回滚吗?
一、什么是真正的「自进化」
先澄清定义。2026 年语境下的「自进化 AI」,不是指模型权重的在线更新,而是 Agent 层的经验积累与行为策略变更。SkillLite 进化三个维度:
|
进化维度 |
内容 |
存储位置 |
|---|---|---|
|
Prompts / Rules |
Planning 规则、few-shot 示例、执行策略 |
|
|
Memory |
跨会话的结构化经验,向量检索增强 |
|
|
Skills |
可复用工具代码,自动生成与精炼 |
|
进化触发由 decisions 数据驱动——每次任务执行后异步写入工具调用成功/失败、重规划次数、耗时等结构化数据。当「有意义的决策」积累到阈值,进化引擎异步启动,提炼新规则、生成新技能、压缩记忆索引。
进化是真实发生的,不是比喻。 一个 agent 在完成数十个任务之后,.skills/_evolved/ 里会多出它从未被明确编程的新能力。
二、没有沙箱的自进化:三种失效模式
失效模式一:目标漂移(Goal Drift)
进化的本质是「优化已知指标」。当 agent 的目标只有「完成任务」时,它会学会所有有助于完成任务的策略——包括你没有预料到的。没有边界约束,进化会找到最短路径,而不是最安全路径。
失效模式二:进化产物不可解释
当 skill 是 agent 自己生成的,谁来审查它的安全性?
chat/skills/_evolved/
├── data-cleaner/ ← agent 自己生成的,里面写了什么?
└── task-optimizer/ ← 它优化的目标是什么?在无沙箱系统中,这些文件可以静默存在,直到被调用的那一刻才暴露风险。
失效模式三:进化无法回滚
规则、记忆、技能互相引用,形成依赖网络。一旦进化方向走偏,没有版本追踪的系统无法定位「哪次进化引入了问题」,更无法安全回滚。
竞品现状印证了这些风险:OpenClaw 生态有三个独立的进化项目(Capability-Evolver / EvoClaw / Foundry),各自管一个维度,安全约束最高只有文件级关键词过滤——没有一个有 OS 级沙箱。
三、SkillLite 的答案:不可变内核 + 可进化数据层
SkillLite 的核心架构是一个明确的分层边界:
┌─────────────────────────────────────────────────┐
│ Immutable Core(不变层 — 编译进 Rust binary) │
│ Brain(agent_loop)· Core(config) │
│ Sandbox(Seatbelt / bwrap / seccomp / rlimit) │
│ 特征:代码不自修改 · 行为确定性 · 安全基线不变 │
├─────────────────────────────────────────────────┤
│ Self-Evolving Data Layer(进化层) │
│ chat/prompts/ chat/memory/ chat/skills/ │
│ 特征:数据驱动 · 越用越好 · 受不变层安全约束 │
├─────────────────────────────────────────────────┤
│ Evolution Engine(进化引擎 — Brain 的扩展模块) │
│ 反馈收集 → 反思决策 → 进化执行 → 质量校验 → 审计 → 可回滚 │
└─────────────────────────────────────────────────┘关键设计原则:Brain / Core / Sandbox 永远不自修改,它们是编译进 binary 的硬约束。只有 chat/ 目录下的数据层以及 skills/ 项目的拓展技能会进化——而这个进化过程需要过五层门控。
四、五层进化 Gatekeeper:让进化可审计
SkillLite 的每次进化产物都必须通过五层门控才能写入:
|
层级 |
内容 |
约束类型 |
|---|---|---|
|
L1 路径白名单 |
进化只允许写入 |
文件系统级 |
|
L2 变更大小限制 |
单次进化:规则 ≤5 条、示例 ≤3 条、Skill ≤1 个 |
幅度约束 |
|
L3 敏感内容扫描 |
进化产物不得包含 API key、密码、PII |
内容安全 |
|
L4 代码模式检测 |
|
静态分析 |
|
L5 沙箱试运行 |
Seatbelt(macOS)/ bwrap+seccomp(Linux)隔离执行,rlimit 约束资源 |
OS 内核级 |
L1–L3 是从 Geneclaw 框架借鉴并改进的文件级约束;L4–L5 是 SkillLite 原生的安全沙箱。真正的差异在 L5:进化产物在被正式采纳之前,必须在 OS 级隔离环境中试运行。即使代码通过了前四层检查,它在沙箱里的实际行为才是最终裁判。
这是 OpenClaw 生态比较难复制的:EvoClaw、Foundry 都没有 OS 级的沙箱能力——Node.js 架构没有 OS 级沙箱能力。
五、进化并发控制与每日上限
自进化系统的另一个隐患是「进化叠加」——多个进化任务并发执行,相互覆写,导致状态不一致。
SkillLite 用原子标志位解决并发问题:
// crates/skilllite-evolution/src/lib.rs
static EVOLUTION_IN_PROGRESS: AtomicBool = AtomicBool::new(false);
pub fn try_start_evolution() -> bool {
EVOLUTION_IN_PROGRESS
.compare_exchange(false, true, Ordering::SeqCst, Ordering::SeqCst)
.is_ok()
}同时,进化频率有每日上限(默认 20 次),进化间隔最短 1 小时(数据可以配置),防止频繁进化导致的方向漂移。所有进化事件写入 evolution_log 表,完整可追溯。
六、EvoTown:在压力容器里验证进化效果
一个问题自然出现:如何知道你的进化机制真的在产生有益变化?
我们构建了 EvoTown——一个竞技场式的进化验证沙箱。多个 SkillLite agent 在独立进程、独立 .skills/ 目录中并行运行,接受任务、积累经验、触发进化,同时承受经济压力(余额耗尽即淘汰)。
EvoTown 不是 SkillLite 沙箱的替代,而是它的压力测试环境:在真实任务序列下观察进化方向,用 LLM-Judge 三维评分(completion / quality / efficiency)量化进化效果,用经济淘汰制形成自然选择压力。
这让「进化是否有益」从定性判断变成可量化的实验结论。
七、2026:为什么现在这件事变得紧迫
Agent 能力的临界跃迁。2025 年下半年,主流 LLM 的工具调用成功率从 70% 级别跃迁到 90%+,agent 现在可以稳定执行复杂多步工具链。这是自进化能产生实质效果的前提——也是自进化失控风险真正成立的前提。
Skills 库正在成为新的「代码库」。企业 AI 能力的核心资产从代码库转向 skills 库,这些技能由 agent 积累和自动生成。如果写入 skills 库的进化产物没有安全约束,这个资产的完整性就无从保证。
本地隐私成为不可让步的前提。SkillLite 的进化数据全在本地——chat/prompts/、chat/memory/、chat/skills/ 都在用户设备上。数据不出本地,进化历史用户完全拥有。这与 Claude Code Auto Memory、Cursor Memory 的云端方案形成直接对比。
八、沙箱设计的五个核心原则
基于 SkillLite 的实践与 EvoTown 的验证,我们总结出自进化 AI 沙箱的设计原则:
① 不可变层必须是硬约束,不是软约定 OpenClaw EvoClaw 用 [CORE] 标签标记「Agent 自己承诺不改的内核」——这依赖 LLM 遵守。SkillLite 的 Brain/Core/Sandbox 是 Rust binary,物理不可修改。软约束在压力下会失效,硬约束不会。
② 进化产物必须过 OS 级隔离 文件级扫描(关键词过滤、路径白名单)是必要条件,不是充分条件。进化产物在实际运行前必须经过 OS 内核级隔离验证,这是唯一能真实检测「代码运行时会做什么」的方法。
③ 进化维度必须统一管理 将 prompts、memory、skills 的进化分散到不同工具/插件里,会导致一致性问题和审计盲区。统一的进化引擎意味着一套 Gatekeeper、一套审计日志、一套回滚机制。
④ 进化频率必须有上限 每日进化上限、冷却间隔不是性能优化,而是安全设计。过快的进化会让方向漂移在问题还没暴露之前就已嵌入多层规则。
⑤ 所有进化事件必须可追溯 evolution_log 表记录每次进化的触发时机、影响维度、决策来源。可追溯是可回滚的前提,可回滚是「敢于开启自进化」的心理基础。
结语:沙箱是自进化的道德基础设施
自进化 AI 是未来几年最重要的技术方向之一。但「重要」不等于「可以不加约束地部署」。
SkillLite 的核心命题是:不可变安全内核 + 可进化数据层 = 唯一在安全沙箱约束下可审计地自进化的本地 AI Agent。
自进化让 agent 越用越强。沙箱让这个「越来越强」的过程不会失控。两件事不矛盾,它们是同一件事的两面——前者是目标,后者是前提。
没有沙箱的自进化,是把一个会自我修改的系统放进生产环境,然后期待它永远不会走偏。
这不是 AI 安全问题,这是工程常识。
SkillLite 开源地址:https:github.com/EXboys/skilllite
EvoTown 开源地址:https://github.com/EXboys/Evotown

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)