【Azure 架构师学习笔记 】- Azure AI(12)-Azure OpenAI(3)-Azure OpenAI 费用管控+全维度监控实操
前两篇教程,我们已经完成了 Azure OpenAI GPT-4o Mini 的「基础Demo调用」和「进阶实操」(提示工程+多轮对话),成功打通从本地环境到Azure云端的全链路。本章聚焦 费用管控 和 全维度监控 —— 这是进阶最容易忽略、但实操中必不可少的一步。介绍如何精准监控Token消耗、控制费用、设置告警,彻底避免“免费额度耗尽不知情”“付费订阅超额扣费”的坑。多轮对话、长文本提问会导
本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure AI】系列。
接上文 【Azure 架构师学习笔记 】- Azure AI(11)-Azure OpenAI(2)-进阶demo
前言
前两篇教程,我们已经完成了 Azure OpenAI GPT-4o Mini 的「基础Demo调用」和「进阶实操」(提示工程+多轮对话),成功打通从本地环境到Azure云端的全链路。
本章聚焦 费用管控 和 全维度监控 —— 这是进阶最容易忽略、但实操中必不可少的一步。介绍如何精准监控Token消耗、控制费用、设置告警,彻底避免“免费额度耗尽不知情”“付费订阅超额扣费”的坑。
基础知识点:
- 查看模型费用:可以通过下面网址,或者从foundry的模型页面查看:
Foundry Models pricing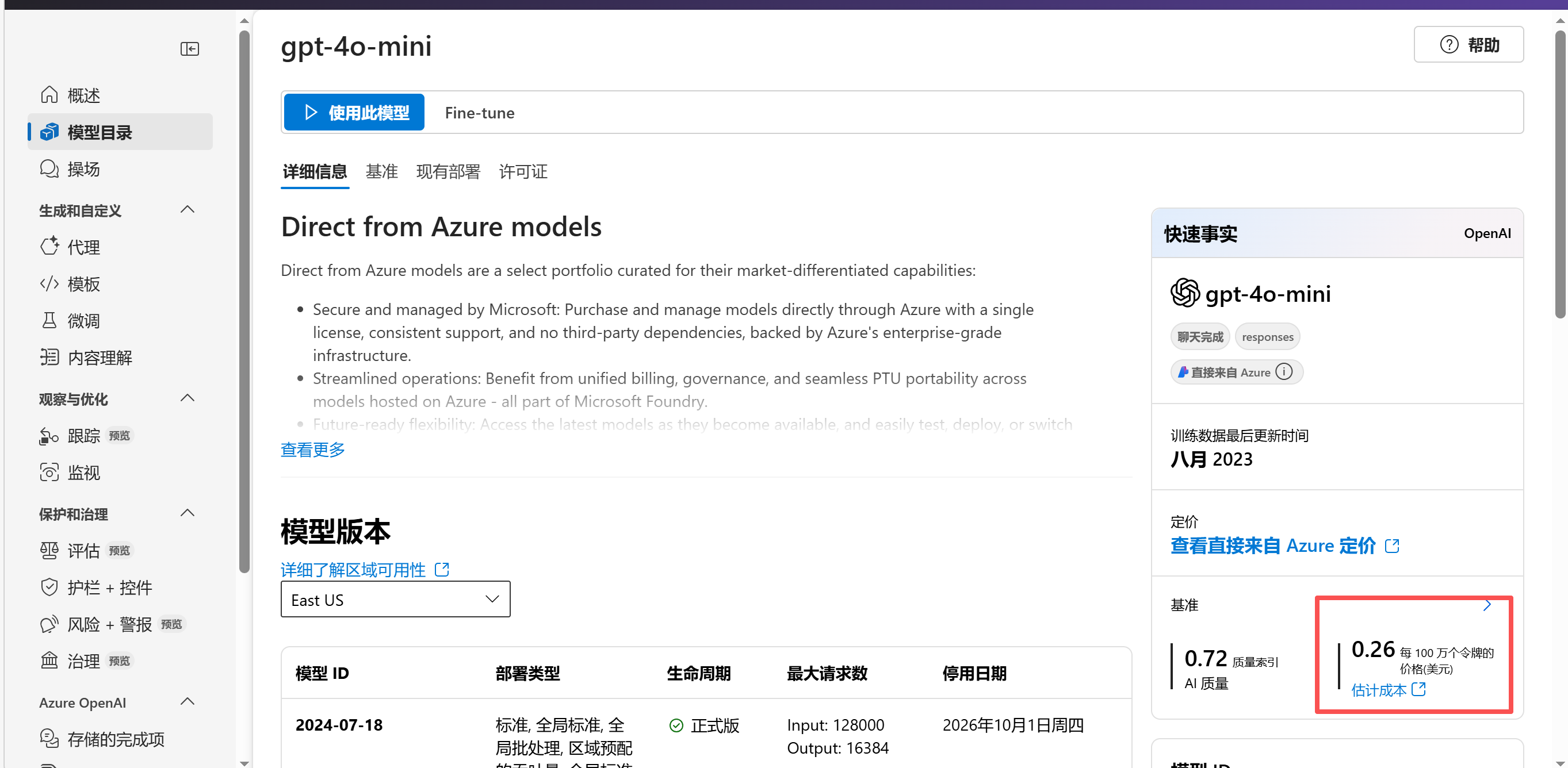
- 多轮对话、长文本提问会导致Token消耗翻倍,进而增加费用,需重点监控。
- Token计算规则——1个中文汉字≈1个Token,1个英文单词≈1个Token,空格、标点不计入Token统计,可大致估算每次调用的消耗。
实操1 代码层监控
代码层监控是“实时提醒”,适合在实操中快速了解每次调用的消耗和花费,可直接嵌入前两篇的基础Demo、多轮对话代码。
1. 基础版:单次调用监控(基础Demo)
封装Token+费用监控函数,调用模型后自动输出消耗和花费,直接复制替换你基础Demo的调用部分即可:
from openai import AzureOpenAI
# 基础初始化(替换成你的信息,和前两篇一致)
client = AzureOpenAI(
azure_endpoint="https://你的资源名.openai.azure.com/",
api_key="你的Key",
api_version="2024-08-01-preview" #从endpoint中获取
)
DEPLOYMENT_NAME = "你的部署名" # 从Azure AI Foundry复制的部署名
# 核心:Token+费用监控函数
def monitor_token_cost(response):
# 1. 提取Token消耗数据(从模型响应中获取,精准无误差)
prompt_tokens = response.usage.prompt_tokens # 输入Token(你的提问)
completion_tokens = response.usage.completion_tokens # 输出Token(模型回复)
total_tokens = response.usage.total_tokens # 单次总消耗Token
# 2. 计算单次调用费用
prompt_cost = (prompt_tokens / 1000) * 0.00015 # 输入费用(美元)
completion_cost = (completion_tokens / 1000) * 0.0006 # 输出费用(美元)
total_cost = prompt_cost + completion_cost # 单次总花费
# 3. 直观输出监控信息
print("\n===== Token+费用监控 ======")
print(f"输入Token:{prompt_tokens} | 输出Token:{completion_tokens}")
print(f"单次总消耗Token:{total_tokens}")
print(f"输入费用:${prompt_cost:.6f} | 输出费用:${completion_cost:.6f}")
print(f"单次调用总花费:${total_cost:.6f}")
print("==========================\n")
return total_tokens, total_cost
# 测试:基础Demo调用+监控
response = client.chat.completions.create(
model=DEPLOYMENT_NAME,
messages=[
{"role": "user", "content": "用30字介绍Azure OpenAI GPT-4o Mini的核心优势"}
]
)
# 输出模型回复
print("模型回复:", response.choices[0].message.content.strip())
# 调用监控函数,查看消耗和花费
monitor_token_cost(response)

2. 进阶版:多轮对话监控
在多轮对话中加入监控,不仅能查看单次调用花费,还能统计整个对话的总花费,避免长时间对话导致额度耗尽,代码可直接复制运行:
from openai import AzureOpenAI
import sys
# 基础初始化(不变)
client = AzureOpenAI(
azure_endpoint="", # 你的 Endpoint
api_key="XXXX",# 你的 Key
api_version=""
)
DEPLOYMENT_NAME = "你的部署名"
# 复用监控函数
def monitor_token_cost(response):
prompt_tokens = response.usage.prompt_tokens
completion_tokens = response.usage.completion_tokens
total_tokens = response.usage.total_tokens
prompt_cost = (prompt_tokens / 1000) * 0.00015
completion_cost = (completion_tokens / 1000) * 0.0006
total_cost = prompt_cost + completion_cost
print("\n===== Token+费用监控 ======".encode('utf-8').decode('utf-8'))
print(f"输入Token:{prompt_tokens} | 输出Token:{completion_tokens}".encode('utf-8').decode('utf-8'))
print(f"单次总消耗Token:{total_tokens} | 单次总花费:${total_cost:.6f}".encode('utf-8').decode('utf-8'))
print("==========================\n".encode('utf-8').decode('utf-8'))
return total_tokens, total_cost
# 进阶:多轮对话+总花费统计
def multi_turn_chat_with_monitor(max_history=5):
# 系统提示词用英文,避免中文编码冲突,同时保证功能正常
messages = [{"role": "system", "content": "You are a professional Azure OpenAI assistant, answer concisely and professionally."}]
total_all_tokens = 0 # 统计整个对话的总Token消耗
total_all_cost = 0 # 统计整个对话的总花费
# 中文输出统一做utf-8编码处理,无需依赖setdefaultencoding
print("多轮对话已启动(实时监控费用),输入'exit'退出\n".encode('utf-8').decode('utf-8'))
while True:
user_input = input("你:".encode('utf-8').decode('utf-8'))
if user_input.lower() == "exit":
print(f"\n===== 对话总结 =====".encode('utf-8').decode('utf-8'))
print(f"本次对话总Token消耗:{total_all_tokens}".encode('utf-8').decode('utf-8'))
print(f"本次对话总花费:${total_all_cost:.6f}".encode('utf-8').decode('utf-8'))
print("====================".encode('utf-8').decode('utf-8'))
break
# 加入历史上下文
messages.append({"role": "user", "content": user_input})
# 限制历史消息长度,节省额度和费用
if len(messages) > max_history + 1:
messages = [messages[0]] + messages[-max_history:]
# 调用模型(无需额外处理,英文提示词已避免编码异常)
response = client.chat.completions.create(
model=DEPLOYMENT_NAME,
messages=messages
)
# 提取回复并加入上下文
assistant_reply = response.choices[0].message.content.strip()
messages.append({"role": "assistant", "content": assistant_reply})
print(f"GPT-4o Mini:{assistant_reply}\n".encode('utf-8').decode('utf-8'))
# 累加总消耗和总花费
single_tokens, single_cost = monitor_token_cost(response)
total_all_tokens += single_tokens
total_all_cost += single_cost
# 启动多轮对话
if __name__ == "__main__":
multi_turn_chat_with_monitor()
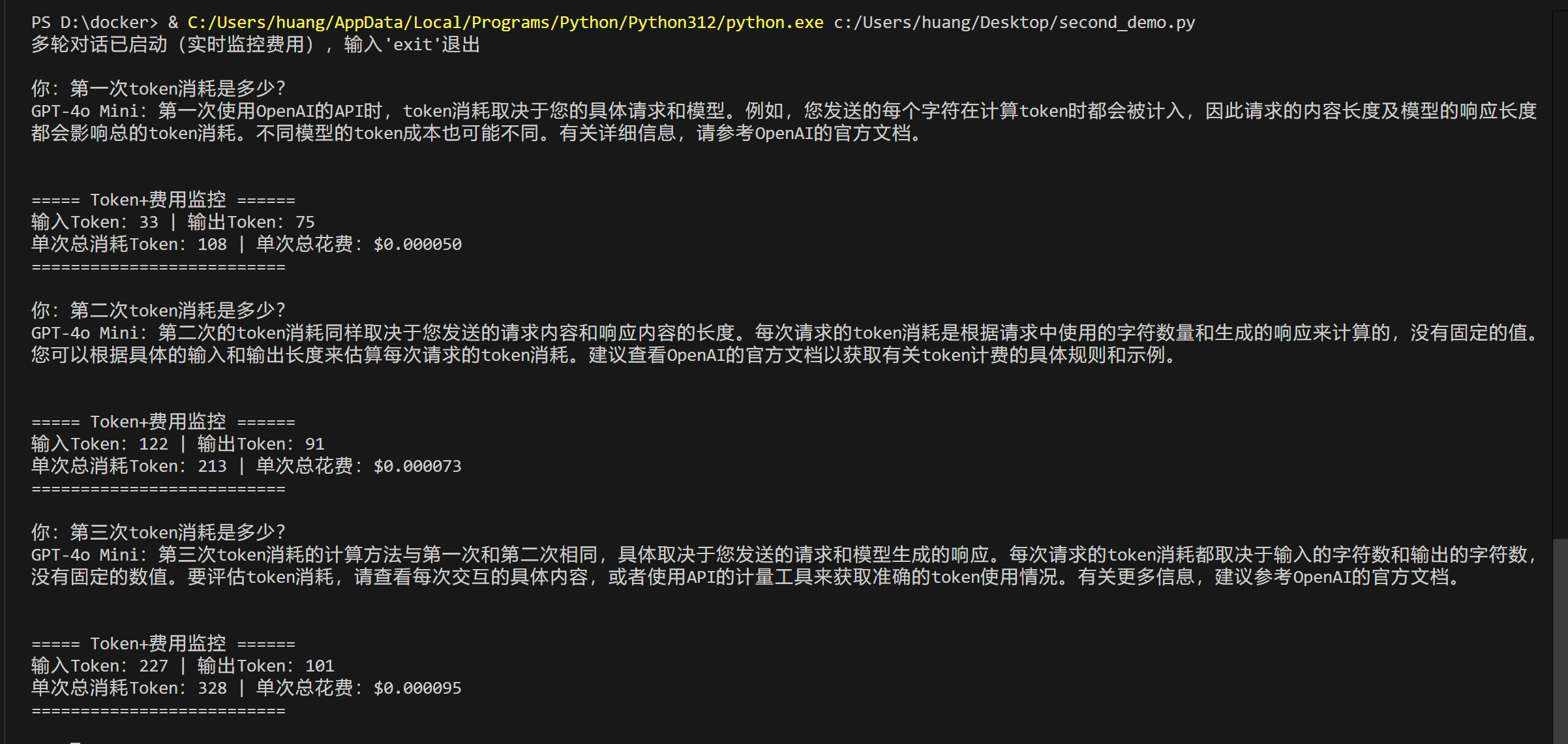
实操2:云端监控
代码层监控是“实时提醒”,但无法主动告警,云端监控(Azure门户+Azure AI Foundry)是“兜底保障”,能设置额度告警、查看消耗明细,即使忘记查看代码输出,也能避免超额。
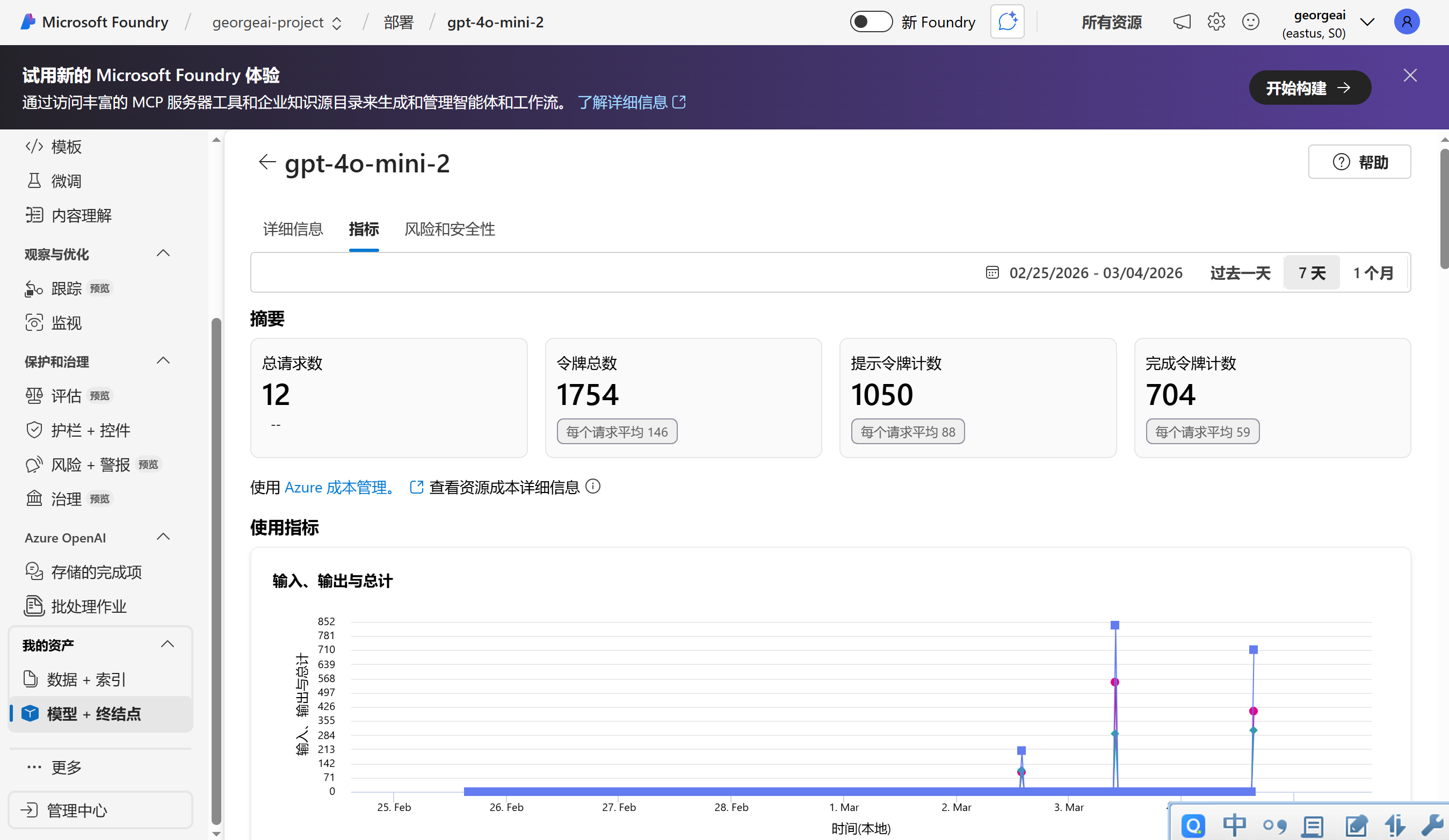
第一步:Azure AI Foundry 查看消耗明细(实时掌握每日/每周花费)
这里能精准查看Token消耗、费用明细,知道每一笔花费的来源(单次调用/多轮对话):
-
打开浏览器,访问 Azure AI Foundry:ai.azure.com,登录你的Azure账号;
-
左侧导航栏按照下图找到你要查看的模型:
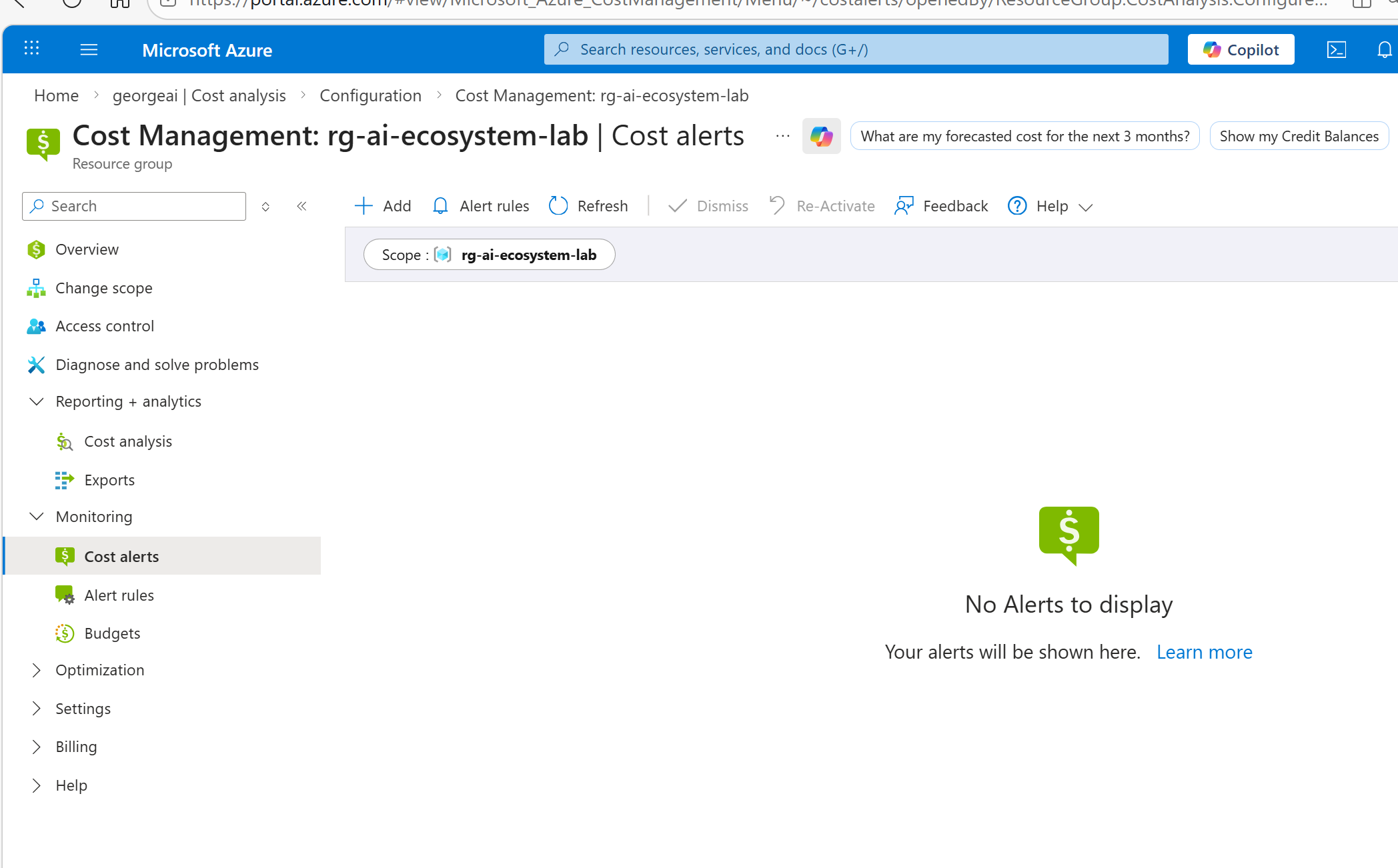
第二步:Azure门户 设置预算+告警(核心,避免超额)
这是最关键的一步,设置预算后,当费用达到阈值(比如剩余10%额度),会自动给你发送邮件/短信提醒,彻底避免额度耗尽不知情:
- 登录 Azure portal 搜索cost management;
- 配置预算:
- 设置告警:
进阶:费用优化技巧(减少消耗,延长额度使用时间)
监控的同时,我们可以通过简单的优化,减少Token消耗和费用,尤其适合免费订阅用户,延长额度使用时间,同时也是面试中“成本优化”的高频考点:
-
- 限制对话上下文长度:多轮对话中,通过
max_history限制历史消息数量(建议5-8条),避免上下文过长导致Token消耗翻倍;
- 限制对话上下文长度:多轮对话中,通过
-
- 优化提示词:提示词简洁明了,避免冗余描述,减少输入Token消耗(比如“用30字介绍XXX”比“详细介绍XXX,越详细越好”更省Token);
-
- 限制模型回复长度:调用模型时,加入
max_tokens参数,限制输出Token数量(比如max_tokens=100),避免模型回复过长;
- 限制模型回复长度:调用模型时,加入
-
- 避免频繁测试:测试时,尽量复用代码,避免重复调用模型,减少不必要的消耗。
小结
这一章主要展示了如何在成本上进行管理和监控。下一章继续尝试Azure OpenAI的其他功能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)