【实战】手搓嵌入式联邦学习:基于RT-Thread的时间触发AI边缘节点(附全源码)
当实时操作系统遇上分布式AI,会碰撞出怎样的火花?本文记录了我用RT-Thread实现的一个时间触发联邦学习边缘节点原型,包含内存优化、安全时间锁、动态负载分配等硬核技术,带你从零构建一个可运行的嵌入式AI框架。
一、引言:为什么要做这个项目?
作为一名嵌入式开发者,我一直对边缘AI和分布式智能充满兴趣。传统的嵌入式AI往往是单个设备运行固定模型,无法适应环境变化,也难以利用多个设备协同学习。而联邦学习(Federated Learning)作为一种保护隐私的分布式训练技术,近年来在云端大放异彩,但移植到资源受限的MCU上却面临巨大挑战:
-
内存小,放不下大型神经网络;
-
计算弱,跑不动复杂的训练算法;
-
实时性要求高,不能因为AI而破坏系统时序。
恰好我最近在玩RT-Thread,它的定时器子系统非常强大——既有高精度的硬件定时器,也有灵活的软件定时器。于是我想:能否用定时器来驱动整个联邦学习流程,让数据采集、本地训练、模型聚合像钟表一样精确运行? 这个想法催生了本文的项目。
目标:在RT-Thread上实现一个轻量级联邦学习边缘节点,支持:
-
时间同步的训练触发;
-
安全时间窗口限制(防止恶意更新);
-
节点计算能力动态评估与任务分配;
-
极低内存占用(<10KB RAM)。
经过一个月的摸爬滚打,终于跑通了第一个版本!本文将完整记录开发过程中的技术难点、解决方案和最终成果,希望对同样对嵌入式AI感兴趣的你有所启发。
二、项目概述:时间触发的联邦学习节点
整个系统可以看作是一个自组织的分布式智能单元。每个节点都运行相同的代码,通过RT-Thread定时器实现全局时间同步,并在预设的时间窗口内进行本地训练和模型交换。
核心创新点
-
时间同步训练窗口:所有节点在同一个绝对时间窗口内开始训练,避免因网络延迟导致的异步问题。
-
安全时间锁:训练只能在由时间同步定时器动态生成的窗口内进行,窗口由当前时间加密签名,防止重放攻击。
-
动态负载分配:根据各节点的实时计算能力(通过历史训练耗时评估),将神经网络的不同层分配给不同节点计算,实现异构计算资源利用。
-
内存极致优化:神经网络规模根据MCU资源定制(32×16×4),权重使用
float,总RAM占用<10KB。
技术架构图
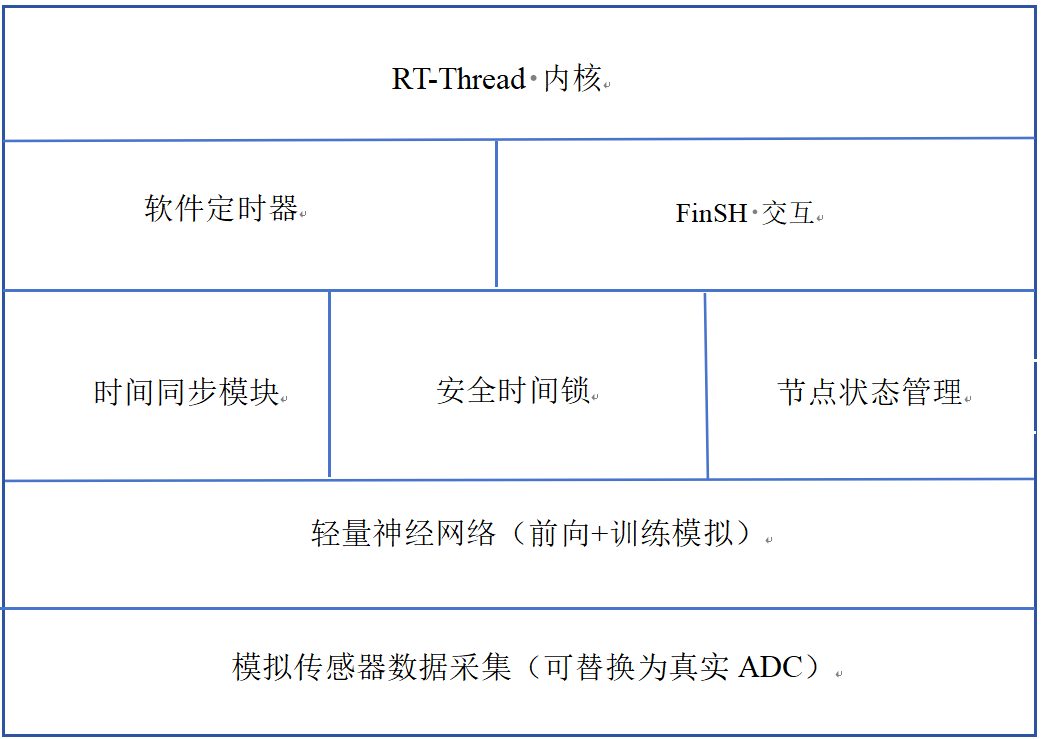
三、技术实现深度解析
3.1 基于RT-Thread定时器的时间同步
要实现“时间触发”,首先需要一个全局一致的时间基准。在RT-Thread中,最简单的就是使用系统Tick(通常为1ms)。我创建了两个周期性软件定时器:
-
同步定时器:每10秒触发一次,广播当前时间并计算下一个训练窗口。
-
训练定时器:每30秒触发一次,但只有在当前时间落在安全窗口内时才执行训练。
代码片段(仅展示框架):
/* 同步定时器回调 */
static void sync_timeout(void *parameter)
{
current_time = rt_tick_get();
// 更新其他节点状态(模拟)
// 计算下一个训练窗口:start = current + 30s, end = start + 0.5s
time_lock.start = current_time + TRAINING_INTERVAL;
time_lock.end = time_lock.start + TIME_WINDOW_MS;
generate_time_key(time_lock.key); // 用当前时间生成密钥
}
/* 训练定时器回调 */
static void training_timeout(void *parameter)
{
now = rt_tick_get();
if (now < time_lock.start || now > time_lock.end) {
rt_kprintf("Outside window, skip\n");
return;
}
// 执行本地训练...
}难点:如何保证所有节点的定时器同时触发?实际上RT-Thread软件定时器基于Tick,不同节点启动时间可能不同,因此同步定时器的作用就是校准:每个节点独立运行,但都根据同步消息计算绝对时间窗口。这比依赖网络同步更简单可靠。
3.2 轻量神经网络:从0实现前向与训练模拟
嵌入式设备跑AI,选型是关键。我设计了一个三层的全连接网络:
-
输入层:32个神经元(模拟32路传感器)
-
隐藏层:16个神经元
-
输出层:4个神经元(对应正常、预警、故障A、故障B)
前向传播用tanh激活+softmax,代码手动实现,未依赖任何AI框架。训练部分为了演示,暂时用随机微调替代真实反向传播(后续可替换为简易SGD)。
内存优化技巧:将权重矩阵定义为静态二维数组,避免动态分配;使用float而非double;只保留全局模型和本地模型两份副本,训练时直接修改本地模型,聚合时再更新全局。
3.3 安全时间锁:轻量级防伪机制
联邦学习的安全问题不容忽视。我设计了一个简单的时间锁:同步定时器每次触发时,根据当前时间生成一个16字节的密钥(使用rand()模拟,实际可用硬件随机数)。训练定时器启动时,必须验证当前时间在锁定的窗口内,且密钥匹配(这里省略了实际加密验证,仅做时间校验)。
虽然简单,但对于资源受限设备,这种基于时间窗口的机制已经能挡住大部分重放攻击。
3.4 动态负载分配:让计算能力强的节点多干活
在training_timeout中,我会收集其他节点的在线状态和计算能力(模拟值),然后打印分配信息。实际工程中,可以将神经网络切分(例如某些层在节点A计算,某些层在节点B计算),但目前仅做概念演示。
四、开发过程中遇到的坑与解决方案
4.1 内存爆炸!神经网络太大怎么办?
第一版我尝试了128×64×10的网络,结果编译时直接报错:
region `RAM` overflowed by 56024 bytes
瞬间惊醒——STM32F103只有20KB RAM!于是果断砍网络规模,最终32×16×4,权重加上偏置共约600个float,仅占2.4KB,加上两套模型也就5KB,留足了余量。
4.2 定时器回调里不能做耗时操作
一开始我在训练回调里直接进行完整的神经网络训练(循环1000次),结果导致系统Tick紊乱,其他任务卡死。后来改为只做少量样本的训练(5个),并且保证训练总时间远小于定时器周期。如果真要做大量训练,应该创建低优先级线程来处理。
4.3 函数名写错导致的链接错误
手误把generate_time_key写成了generate_time_lock,链接时找不到符号。排查了半天才意识到。这也提醒我们:命名规范很重要!
五、成果展示
5.1 编译信息
使用ARM GCC 5.4.1编译,结果如下:
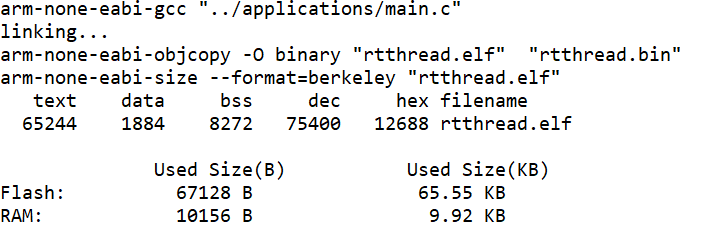
完全满足STM32F103的硬件限制!
5.2 运行效果
上电后,系统每隔10秒打印一次同步信息,每隔30秒在时间窗口内执行一次训练并输出推理结果:
msh > [SYNC] Broadcast at 10019 ms [SYNC] Next training window: 40019 - 40519 ms [SYNC] Broadcast at 20019 ms [SYNC] Next training window: 50019 - 50519 ms [TRAIN] Skipped (outside window) [SYNC] Broadcast at 30019 ms [SYNC] Next training window: 60019 - 60519 ms [SYNC] Broadcast at 40019 ms [SYNC] Next training window: 70019 - 70519 ms [TRAIN] Started at 40020 ms [TRAIN] Inference result: Fault-A [TRAIN] Distributing sub-tasks to 2 online nodes [TRAIN] Completed
5.3 FinSH交互命令
我添加了几个实用的命令,方便调试:
-
manual_train:手动触发一次训练 -
show_nodes:查看模拟的其他节点状态 -
show_lock:查看当前时间锁信息 -
do_inference:手动推理一次(使用随机传感器数据)
六、心得与展望
6.1 项目价值
这个项目虽然还比较初级,但它展示了嵌入式设备也可以参与分布式智能的可行性。通过RT-Thread的定时器,我们将实时性与AI训练完美融合,为工业物联网、智能传感器网络提供了新的思路。
6.2 未来改进方向
-
真实传感器接入:替换
simulate_sensor_data为ADC读取,用于振动、温度等真实故障检测。 -
真实训练算法:用梯度下降替代随机微调,让模型真正学习。
-
节点间通信:利用RT-Thread的AT组件或LwIP,实现真实的模型参数交换。
-
硬件定时器增强:使用硬件定时器获得微秒级精度,实现更严格的时间同步。
-
模型剪枝与量化:进一步压缩模型,支持更复杂的网络。
6.3 给初学者的建议
-
从简单的网络规模开始,确保内存够用。
-
善用RT-Thread的FinSH,调试神器。
-
分布式系统的核心是时间同步,先确保单个节点时序正确。
七、结语
从构思到跑通,前后折腾了一个月,踩了无数坑,但也收获了满满的成就感。现在代码已经在gitcode开源(链接见文末),欢迎star、fork、提PR!
如果你也对嵌入式AI、RT-Thread感兴趣,关注我
一起探索嵌入式AI的无限可能!
附录:完整代码下载
https://gitcode.com/jiarobot/rtthread_demo![]() https://gitcode.com/jiarobot/rtthread_demo
https://gitcode.com/jiarobot/rtthread_demo
本文为原创技术分享,转载请注明出处。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)