美军用 Claude 打伊朗这件事,几个跟做企业 AI 直接相关的判断
这篇介绍Anthropic 与五角大楼这件事的来龙去脉;Anthropic 的 CEO 为什么自己说模型还远不够可靠,以及这个坦承对做企业 AI 的人意味着什么;Anthropic 划的两条红线和坚持原则这件事在商业上到底有没有回报;以及中美 AI 竞争的加剧,对做应用的人有哪些实际影响。
先看段视频

视频链接:公众号韦东东《美军用 Claude 打伊朗这件事,几个跟做企业 AI 直接相关的判断》https://mp.weixin.qq.com/s/7-xiyF2A6OlUjQMsQK04sQ?poc_token=HLuap2mjYoI9J2Am9rjlToRoIC-dmqXs9bIcw2-1
这是前 Google 产品经理 Bilawal Sidhu 在伊朗空袭发生后做的一个项目。他在空袭开始后立刻部署了一个 AI Agent 集群,趁公开情报信号还没被互联网缓存清除,批量抓取了所有能找到的开源数据——航班轨迹、GPS 干扰信号、卫星过境记录、空域关闭通告、霍尔木兹海峡的船舶 AIS 数据。然后在他自己开发的 WorldView 平台上,构建了一个完整的 4D 重建模型。
在一个 3D 地球仪上,你可以逐分钟回放整个打击行动的展开过程——德黑兰上空的空域清理、地面打击坐标锁定、9 个国家被划为禁飞区、观测卫星飞越打击区域。他原话说的是:无需"专有数据融合",一位拥有公共信号且热爱计算机图形和地理空间智能的开发者,就能构建出如此完整的图像。(感兴趣的盆友可以去 X 上搜 Bilawal Sidhu,或者直接访问 worldview4d.com,WorldView 平台预计四月公开发布。)
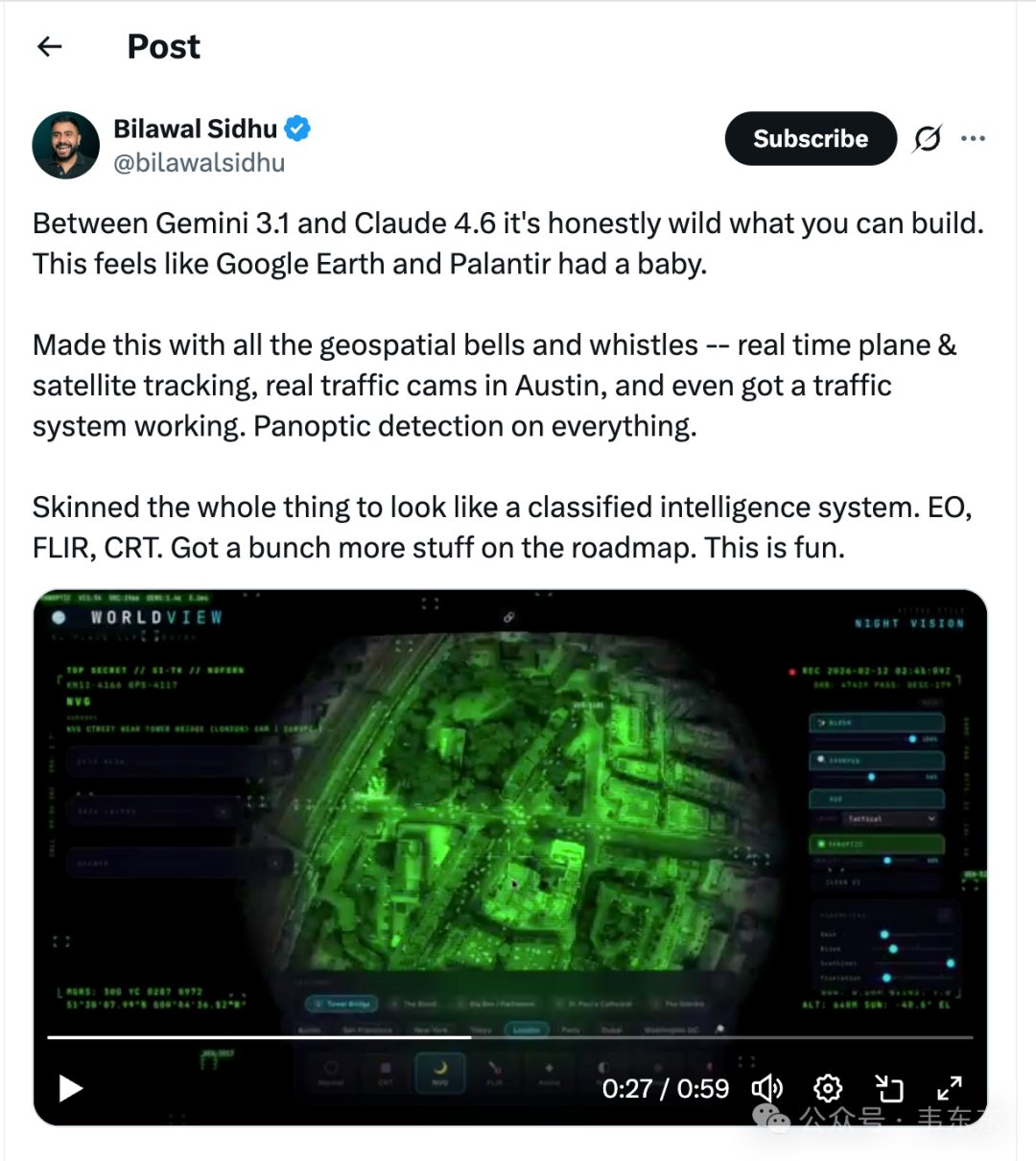
这个视频让我印象很深,不是因为画面多酷炫(虽然看起来确实不明觉厉),而是因为它把一个问题摆到了台面上:AI 的能力边界,正在被快速改写。做企业大模型应用这两年,我几乎每个项目都会碰到这组问题的民用版,就是客户问模型准确率够不够,能不能直接上生产,本质是在问能力边界;客户说数据不能出本地,本质是在划应用边界;客户纠结出了错谁负责,本质是伦理边界。
所以这两天被刷屏的时候,我没有把它当一条国际新闻在看。这件事也是当前做企业大模型应用落地项目的过程中,每天没法回避的那些模糊地带,在这个事件中用一种极端的方式给放大了。
另外,这件事有意思的地方在于,它同时涉及了 AI 能力、伦理边界、商业策略和地缘竞争这几条线,每条单独拿出来都能聊很久。作为一个每天跟企业客户聊企业大模型应用落地的人,我觉得这件事值得认真说一说。不是为了评论时事,而是因为这件事里有几个判断,跟做企业大模型应用确实直接相关。
这篇试图说清楚:
Anthropic 与五角大楼这件事的来龙去脉;Anthropic 的 CEO 为什么自己说模型还远不够可靠,以及这个坦承对做企业 AI 的人意味着什么;Anthropic 划的两条红线和坚持原则这件事在商业上到底有没有回报;以及中美 AI 竞争的加剧,对做应用的人有哪些实际影响。
以下,enjoy:
1、先把这件事的来龙去脉理清楚
先把事情说清楚,很多盆友这两天刷到的可能只是其中一个片段,就是要么是特朗普封杀 Anthropic,要么是美军打伊朗用了 Claude。但这件事的完整时间线,比任何单一标题都更有意思。
1.1、事件是怎么走到这一步的
|
时间 |
事件 |
备注 |
|---|---|---|
|
2025 年 (具体时间没查到) |
Anthropic 通过 Palantir 将 Claude 部署到五角大楼保密网络 |
唯一在军方机密网络里跑的前沿模型 |
|
2026 年 1 月 3 日 |
美军用 Claude 辅助抓捕委内瑞拉总统马杜罗 |
Anthropic 事后提出异议,矛盾的导火索 |
|
2026 年 2 月 |
五角大楼要求取消所有使用限制,允许"一切合法用途" |
Anthropic 拒绝 |
|
2026 年 2 月 27 日 |
Hegseth 最后通牍到期;特朗普 Truth Social 点名封杀;Hegseth 将其列为"供应链风险" |
这个标签此前只贴过华为这类外国公司 |
|
2026 年 2 月 28 日 |
Dario Amodei 接受 CBS 独家专访回应 |
— |
|
2026 年 3 月 1 日 |
美以联合打击伊朗;CENTCOM 仍在用 Claude 做情报评估 |
封杀令 24 小时后 |
|
2026 年 3 月 1 日前后 |
OpenAI 与五角大楼达成新协议,接替 Anthropic |
— |
|
2026 年 3 月 1-2 日 |
Claude App 下载量飙升,登顶美区 App Store |
— |
1.2、几个容易被忽略的细节
光看时间线,很容易把这件事读成 AI 公司不听话被封杀。但有几个细节,值得单独拎出来说。
分歧的核心不是要不要支持军方
Anthropic 从来没有反对军方使用 Claude,它反对的其实是两件非常具体的事:
(1)用 Claude 大规模监控美国公民的日常数据(通话、GPS、信用卡记录等);(2)在没有人类明确介入的情况下,让 Claude 直接驱动全自动武器系统。
The Atlantic 的深度报道显示,谈判中五角大楼提出的协议文本里,包含了“as appropriate(视情况而定)”这类措辞,Anthropic 认为这是在留后门,原话是"loophole-y phrases",直接拒绝签字。
OpenAI 接盘之后出现了一个反转
Anthropic 被踢出去之后,OpenAI 迅速填补了这个位置,与五角大楼达成新协议。但值得注意的是,OpenAI 这份新协议里,同样包含了禁止大规模监控和自主武器的条款。换句话说,Anthropic 死守的那两条红线,最终还是被行业后来者写进了合同。
"供应链风险"这个标签
Hegseth 援引了两项联邦法律来支撑这一认定(FASCSA 和 10 U.S.C. §3252),形式上是正式的行政动作,不只是发了条推文。但问题在于,其中 §3252 的适用范围,按法律专家和 Anthropic 自己的解读,仅限于国防部合同内部,并不授权政府禁止军方承包商与 Anthropic 之间的所有商业往来。Anthropic 随即发表官方声明,称该认定"legally unsound"(法律上站不住脚),并宣布将向法院提起诉讼。程序上也有漏洞:此类认定按规定须先完成正式风险评估、书面通知国会,两个步骤均未完成。

不过,按照川普这种 twitter 治国的套路,即便法律效力还在争议中,Google、Amazon 这类与军方有大量合同的云服务商,可能已经面临继续跟 Anthropic 合作的压力。
一句话总结,这不是一家美国大模型公司是否不爱国的故事,而是一场关于"AI 的使用边界应该由谁来定义"的真实博弈,而且显然这场博弈还没有结束。
2、CEO 自己说大模型远不够可靠
这件事里,绝大多数报道的焦点是 AI 上了战场。但我觉得这件事里最值得记录的,反而是另一个细节。
2.1、军方用 Claude 在干什么,拆解一下
集中翻了下 WSJ、Breaking Defense 等多家军事媒体的报道,CENTCOM 使用 Claude 的方式,大致可以分三个层次来理解:

第一层:帮人看海量信息。
军方每天采集的卫星图、信号情报、媒体监控、社交网络数据、历史战例……靠人一条条看,根本来不及。Claude 在这一层干的事说白了就是把各种来源的信息汇到一起,整理成一份能快速看完的摘要,给指挥层做参考。当然这个场景其实企业里也有,就是那种“接好几个数据源、最后输出一份报告”的应用。
第二层:辅助分析打哪里、怎么打。
打击行动启动前,得评估哪些目标该打、打完之后附带损害多大、时间窗口合不合适。这不是简单搜一下就有答案的事,需要大量历史数据支撑的推理。Claude 在这一层无疑可以很高效的帮分析师快速过一遍各种可能性。
第三层:也是最关键的一层。
Dario Amodei 在多个场合提到美国政府多年来一直在合法购买美国公民的数据,从商业数据经纪公司、大型互联网平台买。通话记录、位置数据、消费行为、社交关系……这些数据法律上说是合法获取的,但量太大、结构太复杂,人工情报分析员的认知带宽根本跟不上。所以大量数据压根没有被深度挖掘。
但大模型正在改变这件事,因为它不只是提高了分析效率,而是可以找到此前人不太可能发现的跨数据集关联。比如一个人在十年前在某地的某次消费,加上他的通话记录,加上他朋友的社交关系,加上近期的 GPS 轨迹,以前这些数据孤岛之间的连线,要消耗大量人力、花费大量时间。现在,大模型可以在秒级完成。
2.2、Dario Amodei 自己怎么说
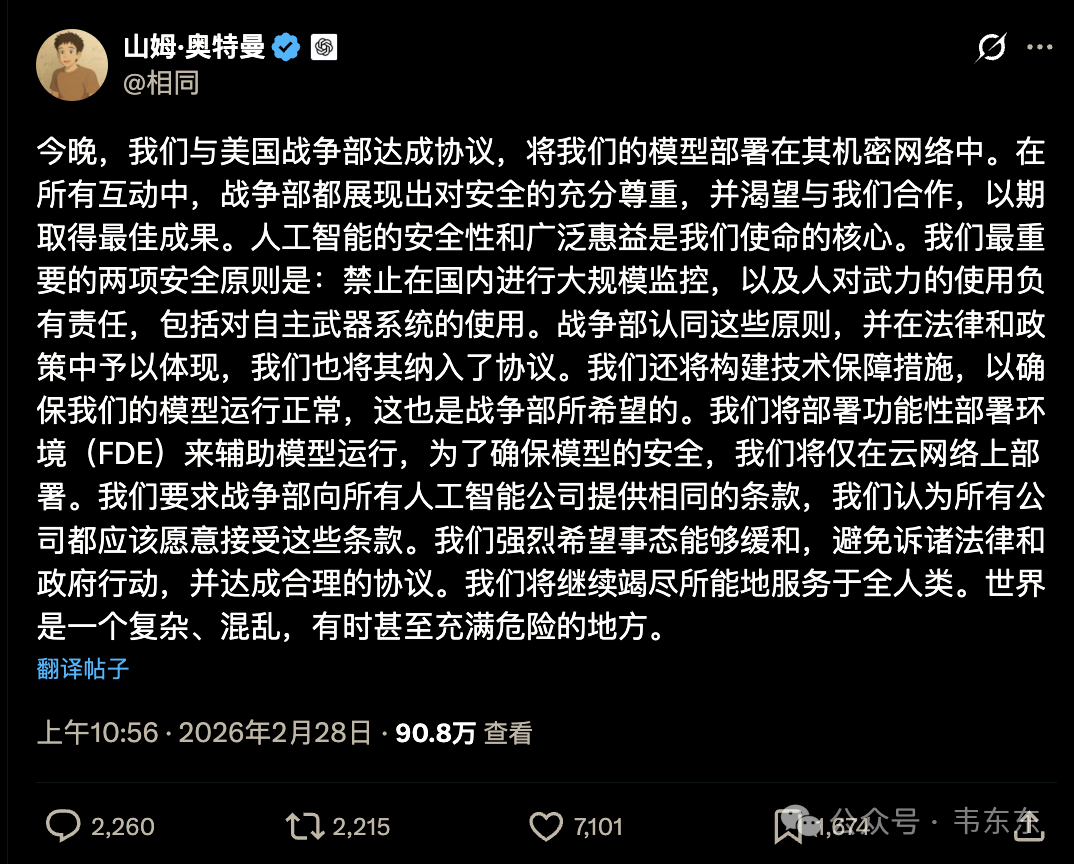
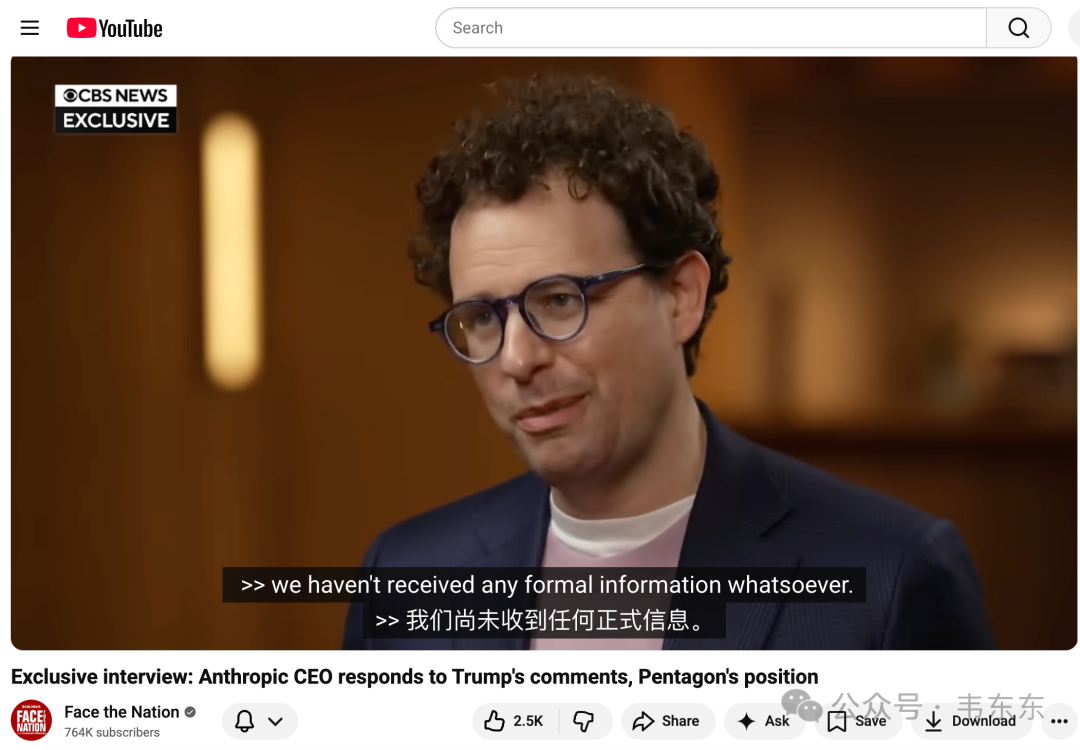
事件发酵后,Amodei 接受 CBS 独家专访。这 27 分钟的采访视频,我也看了两遍。他说了几段话,我觉得是这件事里最值得记下来的:
AI systems are nowhere near reliable enough to make fully autonomous weapons.
(当前的 AI 系统远不够可靠,不能用来制造完全自主的武器系统)
We do not want to sell something that could get our own people killed or that could get innocent people killed.
(我们不想卖一个可能导致自己人或无辜的人被杀的东西)
这话是做 Claude 的人自己说的,不是 AI 批评者,不是学界,不是监管部门,而是把这个模型做出来、靠它赚钱的那个人。
这 27 分钟里,我觉得 Amodei 说的东西可以用三层来理解:
第一层:心意相通。
这个女主持人咄咄逼人地问了很多个问题,比如凭什么一个私营企业的 CEO,有权利决定这项技术的使用边界,而不是把这个权力交给美国政府和五角大楼?当时看到这个问题,我脑子里第一个浮现的是奥本海默。一个把东西造出来的人,后来意识到他有责任去划那条线。不只是工程意义上的成功,还有它可能带来的后果。当然,Amodei 的回答没有那么戏剧性,但底层逻辑是一样的:"Disagreeing with the government is the most American thing in the world." 他不认为这是对抗政府,而是有些事本身就是错的,这跟谁来要求它无关。
第二层:技术的独特性。
主持人在视频里拿波音做类比,波音也给军方造飞机,但波音不会限制军方怎么用飞机,为什么 Anthropic 要特殊对待?Amodei 的回应是,因为这项技术的发展速度,根本不在同一个量级。训练前沿模型所需的算力,大约每四个月翻一倍。波音造一架飞机需要多少年?而这边,模型能力每隔几个月就在发生质变。当技术演进快到这种程度,"先卖给你,出问题了再说"这个逻辑就不成立了。
第三层:只有亲自训练过模型的人,才真正知道边界在哪里。
Amodei 表示当前大模型存在无法完全消除的幻觉问题,这是技术层面的现实。在多数企业应用场景里,幻觉顶多带来一个错误的报告、一段不准确的摘要,代价有限,可以纠正。但放到战场上,一个把错误目标识别为威胁的幻觉,可能意味着无辜人员的伤亡;放到政治场景里,一个被刻意喂进去的偏见,可以在关键时刻影响整套决策链路,被政客用于操纵舆论、干扰选举。
这些观点我觉得很坦诚,也很有所谓的社会责任感。
2.3、落到企业应用:这对我们意味着什么
做企业大模型项目这两年,我对这个两件事的感受非常深。很多企业对大模型的期待,要么过高恨不得让模型直接出结论、直接执行;要么过低,只敢用来生成一段摘要、写个草稿。
当然,合理的做法大家都知道,就是在这两个极端之间,根据场景的容错率,找到对应的人机协同模式。我自己做项目时会用下面这个简单的框架来评估:
|
风险等级 |
典型场景 |
我的做法 |
|---|---|---|
|
低风险:输出错了影响有限,可以快速纠正 |
知识库问答、内容生成初稿 |
LLM 直接输出,人工抽检,过了就放行 |
|
中风险:输出错了有一定业务影响,但可挽回 |
售前报价参考、合同条款初审 |
LLM 出草稿,人工复核后确认 |
|
高风险:输出错了代价大,难以挽回 |
关键决策支撑、合规判断 |
LLM 提供分析参考+置信度说明,人工做最终决策 |
再举两个之前发布在公众号的例子,方便大家理解:
售前报价 Agent:我没有让 LLM 预测最终成交价,只让它输出"参考价格区间 + 相似历史案例"。原因是 B2B 的定价本质是博弈,而 LLM 不掌握客户的预算信息、竞品情况、关系权重。这些关键变量只存在于老板的脑子里,模型猜不准,也不该猜。
售后知识库的差评分析:我跑了一次根因分析,发现用户给的差评里,有 37% 根本不是模型回答错了,而是知识库里压根就没有相关文档。用户问的是一个"不存在的答案"。能力边界,需要你自己去摸清,而不是归结于模型。
换句话说,大模型的能力是真实的,但可靠性需要用工程手段来保障。 做企业级应用,不是选一个最强的模型就完事了。开源模型(大、中、小尺寸)和联网旗舰模型 API 之间怎么组合、在什么场景下该用哪个,这里面的考量不仅仅是成本和延迟,更多的是合规性和稳定性。把能力强和可以信任分开来想,是做企业 AI 应用时一个值得反复提醒自己的基本功。
3、"两条红线"一些延伸想法
两条红线的具体内容,前面已经说过了,这里不再重复。这一节想聊的是另一个问题:坚持原则这件事,在商业上到底有没有回报?
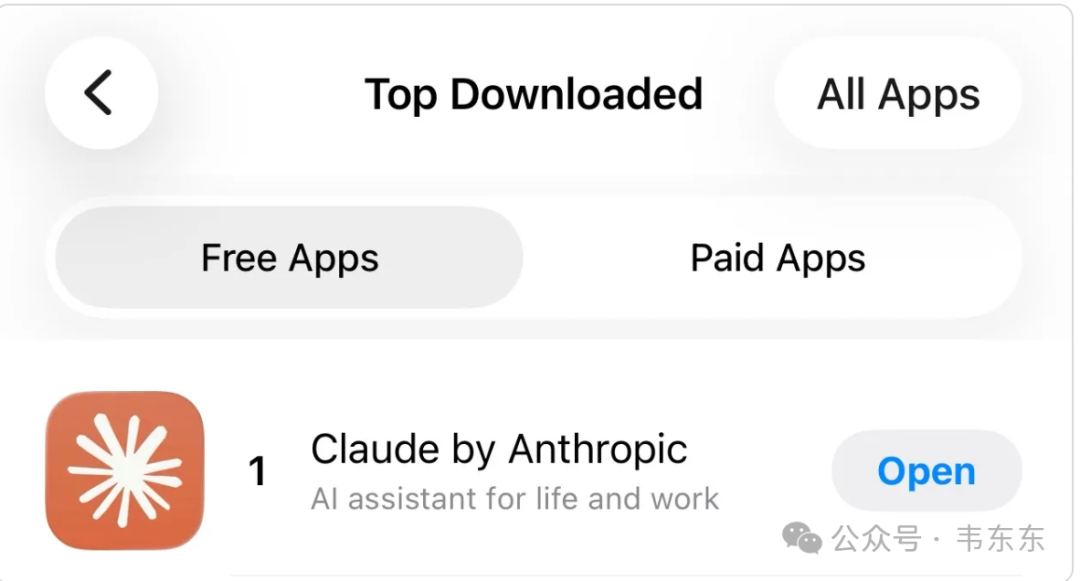
Anthropic 的短期代价很直接,但长期的信号也很有意思。Claude App 在事件发生后下载量逆势飙升,超越 ChatGPT 登顶美国区 App Store 免费榜。你很难说这些新用户全都是因为某种用脚投票的价值观才下载的,但至少说明有一部分人,是因为这次拒绝才认真考虑用 Claude。品牌信任这个东西,有时候就是在这种时刻建立的。
更值得注意的一个信号,前面也提到了。OpenAI 接盘后,新协议里同样写入了禁止大规模监控和自主武器的条款。Anthropic 因为坚持红线丢了合同,但这条红线本身,反而成了行业后来者默认遵守的标准。这在商业史上其实不少见。第一个坚持标准的人往往付出最大代价,但标准一旦立住了,所有人都受益。
说起企业大模型应用,经过过去三年的市场教育,大部分中小型企业也开始逐渐重视起来了,很多公司也在设专门的预算来做这块的试错或投资,不管是内部搞研发还是找外部服务团队。但这依然是一个信任门槛极高的行业,毕竟大模型应用通常需要边做边改、边优化,不是签完合同交付一个软件包就结束了。
尤其是作为外部的技术服务商,如果在和甲方的需求边界协商中,明确说不做什么,或者基于对技术边界和已有工程项目的理解,不去做过多的、夸大的承诺,这本身就是一种本分,或许也是一种长期竞争力所在。
4、中美 AI 竞争,跟做应用有什么关系
这件事还有一个维度,我觉得值得单独拿出来说。
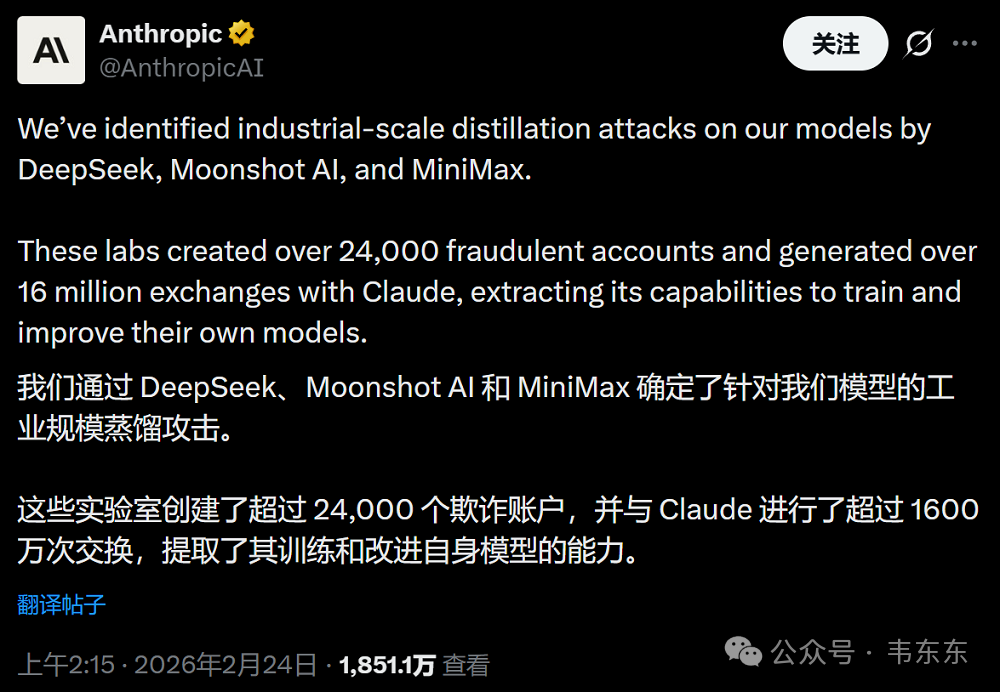
供应链风险这个标签,以前只贴在华为这样的外国公司身上。现在贴到了一家美国本土 AI 公司,原因仅仅是它拒绝了部分军事应用要求。与此同时,Anthropic 在 2 月下旬公开指控 DeepSeek、Moonshot AI、MiniMax 等中国 AI 公司,通过约 1600 万次交互和 24000 个欺诈账号,系统性地蒸馏提取 Claude 的能力。两件事放在一起看,结论也很直接,AI 能力已经被视为国家战略资产,竞争不只是技术层面的事了。
资本面的信号更直接,St. Louis Fed 的数据显示,2025 年 AI 相关活动占了美国 GDP 增长的大约 40%;AI 企业贡献了美股约 80% 的涨幅;VC 投资里 AI 的占比超过 63%。但同期 MSCI World ex USA 指数涨了 28.6%,跑赢了 S&P 500 的 16.4%。说白了就是,如果把 AI 从美国经济里拿掉,美国市场的表现其实不如全球平均水平。美国的增长引擎正在高度集中到 AI 这一件事上,All-in 的程度历史上少见。
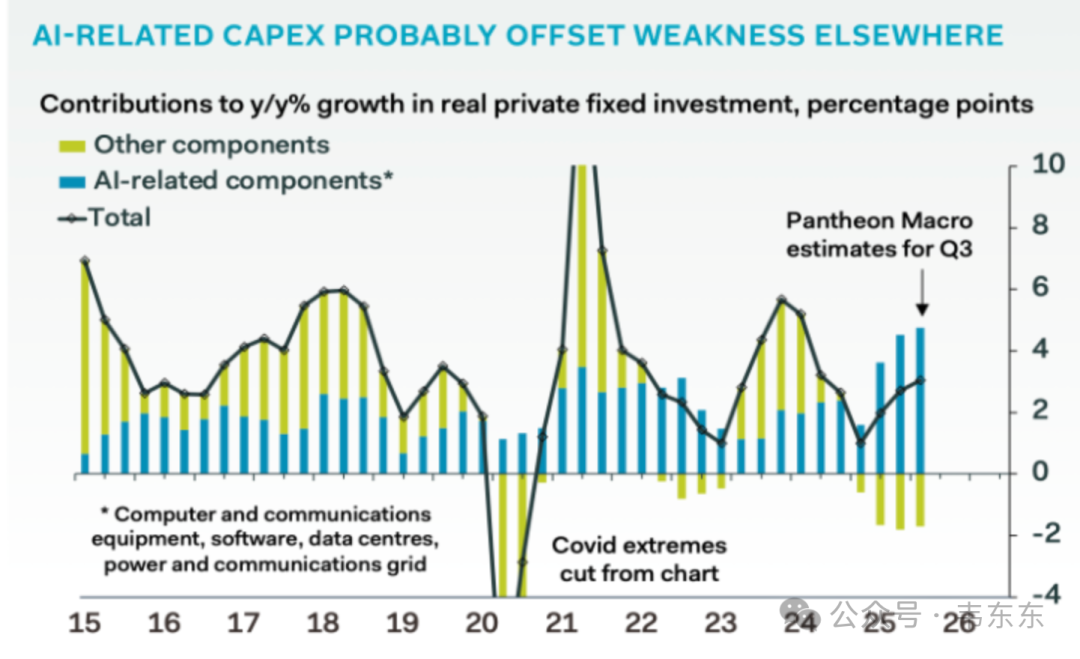
注:人工智能(绿)资本支出持续增长,而非人工智能(蓝)资本支出持续萎缩
对做企业应用的人来说,这些变化已经在影响日常的业务判断了。模型选型这件事,以前主要看能力和价格,现在还要看合规风险。涉及敏感数据的场景用海外闭源模型,客户的顾虑在明显增加。这无疑给国产模型创造了更大的空间,不只是开源模型的本地部署,也包括国产旗舰模型的 API 调用。
说到这个,最近一个很直观的例子是通义千问 Qwen 3.5 系列。2 月中旬发布之后,不光放出了旗舰的 397B MoE 模型,还一口气开源了从 0.8B 到 9B 的一整套小尺寸模型,全部 Apache 2.0 协议。更让我意外的是视觉能力,这几天抽空测试下来发现,Qwen3.5-35B-a3b 这个小模型在视觉语言任务上的表现,接近了之前 Qwen3-VL-235B 这种大了一个量级的模型;文档识别(OmniDocBench)甚至跑到了 90.8 分,超过了 GPT-5.2 和 Claude Opus 4.5。4B 参数的版本已经能跑视觉理解和 UI 导航了,完全可以部署在消费级硬件上。

之前我个人的体感是,国产大模型跟海外一线可能还有三到六个月的训练时间差。但现在看起来,至少在大部分企业级场景里,这个差距已经不是决定性的了。很多场景国产模型完全够用,而且在数据合规和部署灵活性上反而有优势。
5、写在最后
25年1月20号DeepSeek发布即开源的爆火,让很多人第一次直观看到了大模型那种显性的思维链推理能力;然后是 Manus,让更多人看到了 Agent 到底是怎么一步步拆解任务、自己干活的;再到 OpenClaw 昨天在 GitHub Star 数超过了 React 和 Linux,一个上线才三个月的项目,超越了存续十几年甚至几十年的经典老牌项目。仔细想想,这几个东西火起来的底层逻辑其实是相通的,它们用的都是当前最强的 Coding 能力,本质上是在用代码能力驱动 Agent 去完成越来越复杂的事情。
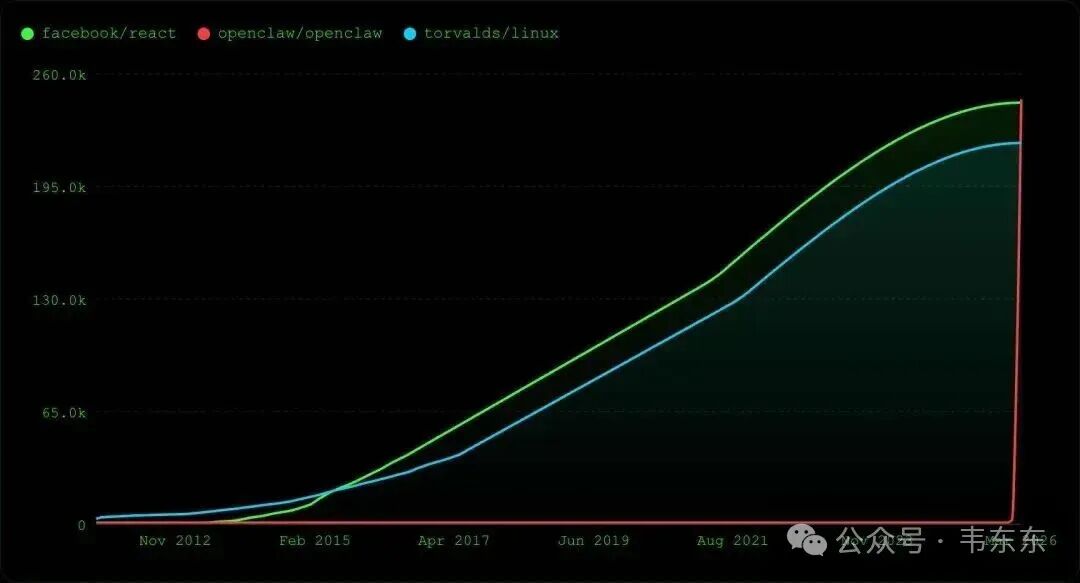
站在今天这个时间点看,底座模型的推理能力、Token 成本的持续下降、硬件算力的普及化,这几条线确实都在明显收敛。OpenClaw 带来的自下而上的 Agent 通用范式,让 Token 消耗呈指数级爆炸,也让大模型应用在 To B、To C 领域的可能性打开了很多想象空间。没人能提前画出商业化闭环的完整路径,但我们确实正站在这几个要素共同收敛的节点上。未来已来,只是分布得不太均匀。
这篇其实是我这两天一边反复看 CBS 那个 27 分钟的采访、一边翻 WSJ 和 The Atlantic 的报道、一边在笔记里记下来的,后来越写越长就变成了现在这篇。我觉得这本身就是一种深度使用的过程。今天知识星球的成员刚过 300 人,我也发了个朋友圈提到一篇帖子里说的,1994 年中国第一批接入互联网的那批人,大概也就是在中关村和高校的机房里,通过 64K 专线连上一个当时看起来像玩具的网络。大概就是这种感觉吧。
星球里日常在记各个行业的落地案例、工程细节和踩坑笔记,感兴趣的盆友欢迎加入一起交流。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)