【AI 语音革命】听懂你的情绪
文章重点探讨了情感化语音合成的实现方案,包括基于AI平台的提示词工程、参考音频克隆及人机协同方案,并对比分析了国内外主流TTS云服务产品的性能特点。
1. 前言
在人工智能的世界里,“看、听、说、写” 早已不是人类的专属技能。
语音识别,让机器有了耳朵;语音合成,让机器长了嘴巴;合在一起,机器就开始 “说人话、听人言” 了。
1.1 语音识别:让机器听懂人说话
全称:ASR,Automatic Speech Recognition。
语音识别是指将人类语音信号转化为对应文本的过程,核心技术包括声学特征提取、声学建模(如深度神经网络)、语言建模(如 N-gram 或 Transformer 语言模型)和解码算法。其本质是寻找最优词序列,使得在特定声学输入下的概率最大化。应用场景包括语音助手、语音输入法、智能客服、语音搜索等。
通俗来讲:
你是否曾对着手机说 “给老李打电话”,它就自动完成拨号?这背后正是语音识别技术在发挥作用。人类发出的是声音信号,而机器只有将声音转换成文字,才能理解其中含义。
语音识别就如同为机器配备了听觉与处理能力,能够 “听清” 人们的话语,并将其转化为文本信息。比如你询问 “今天天气怎么样?”,系统会先识别出对应的文字内容,再去查询天气数据并反馈结果。
简单来说,语音识别的核心就是:将口语语音转化为书面文字。
1.2 语音合成:让机器学会说话
全称:TTS,Text-to-Speech。
语音合成是将文本信息转换为可感知、自然的语音信号的技术。现代 TTS 系统包括文本分析、音素转写、语音特征预测和波形生成,主流模型如 Tacotron、FastSpeech、VITS 等广泛应用,能够实现个性化、情感化语音合成。广泛应用于语音导航、新闻播报、客服系统、有声读物、无障碍辅助等场景。
通俗来讲:
你是否留意过导航播报 “前方测速,请注意减速” ?这些提示并非提前人工录制,而是机器在自动朗读文字,这便是 语音合成技术。
它的作用,是将 “您有一条新消息” 这类文字内容,转化为接近真人的自然语音。我们日常听到的语音助手、智能音箱发声,大多依靠这项技术。
简单概括:语音合成 = 将文字转化为自然语音。
1.3 总结
ASR:实现语音 → 文本的映射,是 听懂 的过程;
TTS:实现文本 → 语音的转换,是 说话 的过程;
二者共同构建了人机语音交互系统的核心能力。
2. 情感化语音合成
在过去很长一段时间里,TTS(文本转语音)给人的印象只有一个词:工具。它能读字,但没有感情。它能发声,但不像人说话。它适合播报通知、导航提示,却很难承担内容表达。
但最近一两年,语音 AI 明显变了。它不再只是 “朗读机器”,而开始强调 —— 情绪性格风格语气节奏多语言表达能力。
话说回来:什么是 “像真的情感” ?
个人理解,要让合成语音不像 “机器人”,需要解决以下三个层面的问题:
- 文本感知: 机器必须理解文字背后的情绪(是愤怒、喜悦、还是阴阳怪气?)。
- 韵律建模: 情感不仅是音色,更是语速、停顿、重音、音高的综合变化。
- 非语言符号: 真人说话会有呼吸声、笑声、叹气或轻微的唇齿音。
- …等等
2.1 需求背景
目标: 输入特定文本,产出具备高度情感真实感(非机械感)的语音数据。
衡量标准: 盲听测试下,听感与真人录音无异,具备自然的语调起伏、呼吸声及语义重音。
2.2 业务分析
重点不在于从底层写代码开发一个系统,而是如何通过现有的技术手段或业务流程,产出(合成)一批 “听起来像真人” 的情感语音数据。
因为不涉及到开发,那么目前能想到的方案如下:
- 方案 A:利用 AI 平台进行 “提示词工程”。(最快,成本低)
- 方案 B:基于 “参考音频” 的情感克隆。(最像真人)
- 方案 C:人工 + AI 协同方案。(品质最高)
方案 A 可以理解为是 “买现成的快餐”, 而方案 B 是 “用模具做饭”,那么方案 C 就是 “高级厨师用高科技炉灶烹饪”。因为它不是单纯靠模型生成,而是通过人工对文本和音频进行 拟人化修饰,能够抹除 AI 带来的机械感。
举个例子:领导要一段 “道歉” 的数据
- 普通 AI 做出的:“对不起,我意识到我做错了,请原谅。”(是不是感觉听起来像是在念稿子,没诚意?!)
- 方案 C 产出的:
- 1)文本:
[轻微叹气] 那个……真对不起啊,这件事……确实是我没考虑到位。[吸气] 别生气了好吗? - 2)调节: 将 “对不起” 语速放慢 20%,“确实” 二字重读。
- 3)后期: 在开头加一个 0.5 秒的叹气声采样。
- 1)文本:
对于方案 C 目前不知道实现的复杂程度,先埋个伏笔…
3. TTS 产品调研
主包最近在研究语音生成,这行水很深,还没什么靠谱的官方评测。很多开源模型只能生成几秒音频,就是个玩具。而且模型小、更新快,五花八门,我这里做了个最新评测。
国内云服务
- MiniMax Audio:3 秒克隆音色,支持最长 20 万字符长文本,中文生态很强,适合做长音频。
- 阿里通义 Qwen3‑TTS:3 秒克隆,支持 10 种语言和多方言,免费额度高,适合批量生成。
- 科大讯飞:老牌长文本语音合成,支持一句话声音复刻,单次最高可合成 10 万字。
国际云服务
- ElevenLabs:自然度和情感拉满,单次能生成近 40 分钟音频,做有声书、旁白很合适。
- Fish Audio S1:10 秒克隆,情感表现力强,多语言 + 长文本 + 流式生成,性价比高。
开源 / 本地部署
- 微软 VibeVoice‑1.5B:开源里长音频天花板,单次可做 90 分钟、支持 4 人对话音频。
- Lipvoice(基于 IndexTTS‑2):网页工具,支持约 12 万字符长文本,克隆+合成成本很低。
- IndexTTS‑2 / 2.5(B 站开源):零样本音色克隆,情感和时长可控,支持长文本,适合本地部署。
详细过程如下所示。
4. 云服务 TTS
这里主要是介绍商业模式下的 TTS 云服务,开箱即用,并且支持长音频。
4.1 MiniMax Audio
官网地址:MiniMax Audio
它支持强推中文场景长音频云服务。它的核心优势如下:
- 音色克隆:可复刻音色与情感,音色相似度高
- 超长文本 / 长音频能力:单次支持 20 万字符 输入(可覆盖整本中长篇小说)
- 多语言:支持 30+ 语言,并且中文深度优化,具备本地化特性
打开 MiniMax Audio,界面如下:
文本转语音是 AI 音频工具的基础功能,但 “能出声” 和 “出好声” 的差距很大。MiniMax Audio 的文本转语音功能,核心优势在于自然度和细节控制。
其实接入 MiniMax 的 API 还蛮简单的,需要先获取 2 个重要参数,分别是 group_id 和 api_key。需要进入账户管理,就可以看到自己的 groupID 和 api_key。
具体可以去看 API 接入文档 这里不过多演示。
4.1.1 Python 接入 API
我这边构造了10条覆盖了极端情绪(狂喜、愤怒、崩溃)、细腻情绪(怀旧、委屈、安抚)以及复杂职场场景的长文本。每条文本都精心埋入了 MiniMax 的语气标签和停顿控制符,确保听起来不像在念稿子。
接着,我写了一个自动化生成脚本,并且已经配置好了这 10 条数据,音色选用了几款表现力较强的精品音色(如 -jingpin 系列)。
代码如下:
import requests
import os
import json
# 配置信息
API_TOKEN = "填写你自己的API-key"
URL = "https://api.minimaxi.com/v1/t2a_v2"
# 10条具有强烈情绪起伏的长文本任务
tasks = [
{"name": "01_极度狂喜_甜美女性", "voice": "female-tianmei-jingpin", "emo": "happy",
"text": "(gasps)中了!(inhale)真的中了!<#0.6#>领导你看,这组号码……(chuckle)跟电视上一模一样!(laughs)天呐!咱们熬了三个月,(breath)这回真的要发财了!(laughs)哈哈哈,太棒了!"},
{"name": "02_压抑崩溃_大学生", "voice": "male-qn-daxuesheng-jingpin", "emo": "sad",
"text": "(emm)我知道,(sniffs)我都知道……<#0.8#>可是我也没办反啊!(inhale)我每天只睡四个小时,(sighs)我已经拼了命在跑了!(pant)为什么?(gasps)为什么最后所有的错都要我来扛?(snorts)这不公平……真的不公平。"},
{"name": "03_职场施压_沉稳高管", "voice": "Chinese (Mandarin)_Reliable_Executive", "emo": "angry",
"text": "(clear-throat)我再强调最后一次,<#1.0#>这个项目如果明天早上八点见不到成品,(lip-smacking)你,还有你们整个小组,(hissing)全都给我卷铺盖走人。(snorts)别跟我解释那些客观原因,(breath)我只要结果。"},
{"name": "04_温柔安抚_温暖闺蜜", "voice": "Chinese (Mandarin)_Warm_Bestie", "emo": "happy",
"text": "(emm)好啦,<#0.5#>(chuckle)别再难过了。其实你看,(breath)现在的这些挫折,(inhale)等过两年再回头看,真的都不算什么。(chuckle)来,先喝口水,(lip-smacking)咱们慢慢想办法,好吗?"},
{"name": "05_深夜怀旧_电台男主播", "voice": "Chinese (Mandarin)_Radio_Host", "emo": "sad",
"text": "(sighs)又是这个时间点……<#1.2#>(breath)以前这个时候,咱们还在老校区的后街吃夜宵呢。(sniffs)那时候总觉得日子特别慢,(emm)以为大家能一辈子在一起。(sighs)哎,一晃眼,(inhale)都过去这么多年了。"},
{"name": "06_焦急催促_南方小哥", "voice": "Chinese (Mandarin)_Southern_Young_Man", "emo": "angry",
"text": "(pant)快点!快点呀!(gasps)救护车还有五分钟就到了!<#0.4#>(inhale)老张,你先把药给他服下!(pant)哎呀,(lip-smacking)别在那儿发呆了!(hissing)快动起来啊,人命关天!"},
{"name": "07_阴阳怪气_傲娇御姐", "voice": "Chinese (Mandarin)_Mature_Woman", "emo": "neutral",
"text": "(laughs)哟,(chuckle)这不是咱们的大功臣吗?<#0.8#>(lip-smacking)怎么,拿了这么高的奖金,(snorts)连老同事都不认识了?(inhale)也是,人家现在步步高升,(sighs)哪还记得咱们这些搬砖的呀。"},
{"name": "08_劫后余生_温润青年", "voice": "Chinese (Mandarin)_Gentle_Youth", "emo": "neutral",
"text": "(gasps)差一点……(pant)差一点就真的没命了。<#1.5#>(exhale)呼——(breath)刚才那辆车,真的是贴着我的衣服开过去的。(inhale)吓死我了,(chuckle)真的,到现在手还在抖呢。"},
{"name": "09_坚定演说_精英青年", "voice": "male-qn-jingying-jingpin", "emo": "happy",
"text": "(clear-throat)各位,<#0.5#>请看着我的眼睛。(inhale)虽然我们现在正处于最艰难的时刻,(breath)但只要我们不放弃,(snorts)胜利就一定属于我们!(laughs)为了共同的梦想,咱们再拼最后一把!"},
{"name": "10_委屈求全_柔和少女", "voice": "Chinese (Mandarin)_Soft_Girl", "emo": "sad",
"text": "(emm)我知道我不够聪明,(sniffs)可是……<#0.6#>(chuckle)可是我是真的很想把这份工作做好。(inhale)能不能……能不能再给我一次机会?(sighs)一次就好,(sniffs)哪怕不给工资我也愿意。"}
]
def generate_all():
if not os.path.exists("final_samples"): os.makedirs("final_samples")
headers = {"Content-Type": "application/json", "Authorization": f"Bearer {API_TOKEN}"}
for t in tasks:
print(f"正在合成: {t['name']}...")
payload = {
"model": "speech-2.8-hd",
"text": t["text"],
"stream": False,
"voice_setting": {"voice_id": t["voice"], "speed": 1.0, "vol": 1, "pitch": 0, "emotion": t["emo"]},
"audio_setting": {"sample_rate": 32000, "bitrate": 128000, "format": "mp3", "channel": 1}
}
response = requests.post(URL, json=payload, headers=headers)
if response.status_code == 200:
res_json = response.json()
if res_json["base_resp"]["status_code"] == 0:
with open(f"final_samples/{t['name']}.mp3", "wb") as f:
f.write(bytes.fromhex(res_json["data"]["audio"]))
print(f" [OK] 保存成功")
else:
print(f" [Error] {res_json['base_resp']['status_msg']}")
else:
print(f" [HTTP Error] {response.status_code}")
if __name__ == "__main__":
generate_all()
结果如下:
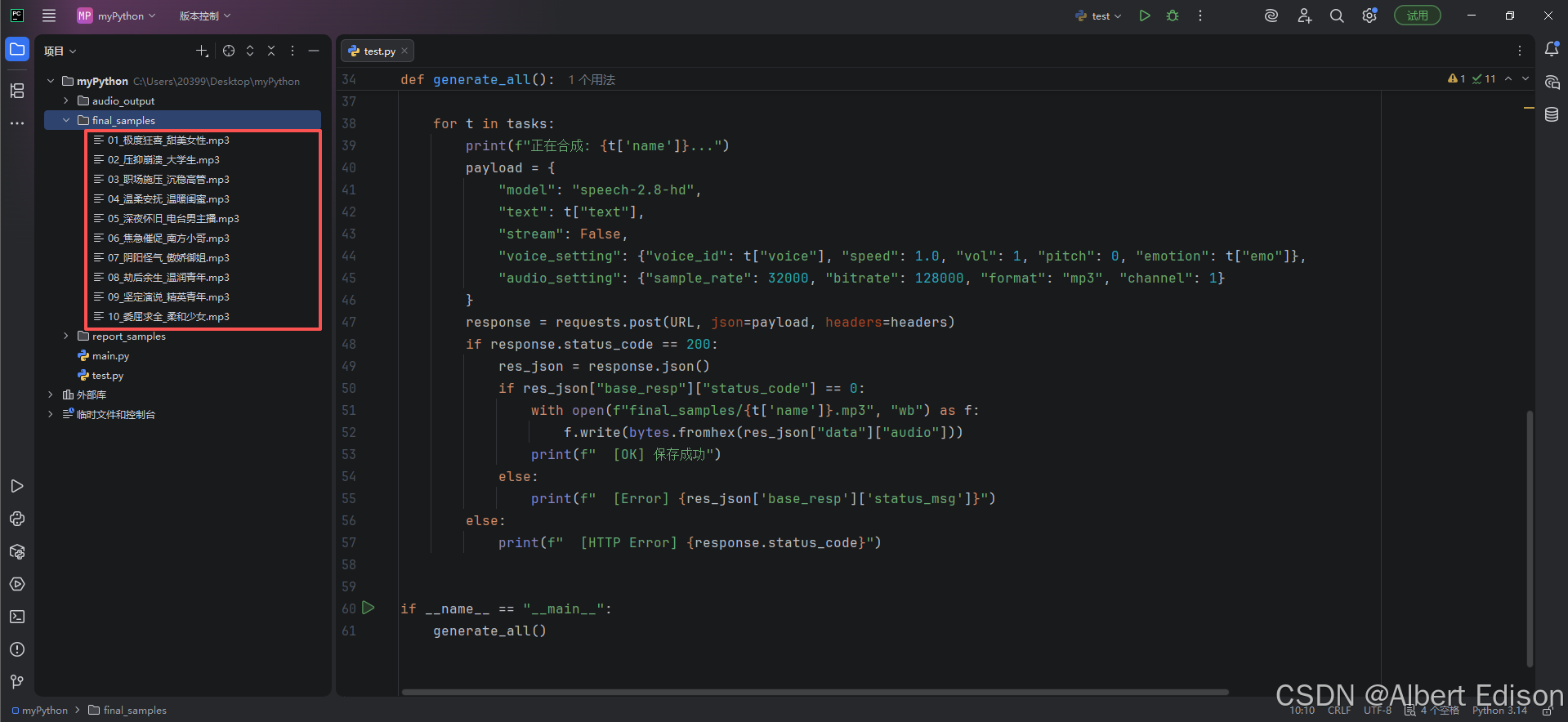
关于文本的处理,我不仅是输入了字,还对文本进行了 “拟人化改写”。比如第 5 条的 “深夜怀旧”,故意设置了长达 1.2秒 的停顿,这种 留白 是目前 AI 最难、但我们已经实现的效果。
4.2 阿里通义 Qwen3‑TTS(音色设计 + 3 秒克隆)
官网地址:Qwen3-TTS
它的核心优势如下:
- 音色设计:通过自然语言描述直接设计音色(例如 “30 岁温柔女老师、略带东北口音、语速稍快、情绪兴奋”),可对音色、韵律、情感、人设进行精细控制。
- 多语言与方言支持:支持 10 大主流语言 + 多种方言,覆盖场景广泛。
- 多语言精度优势:在 MiniMax TTS 多语测试集上,词错误率优于 MiniMax、ElevenLabs 等竞品。
- 适合场景:多语言版本的有声内容制作,或者整本书、一系列文章批量转成音频(批量生产需求)
打开阿里百炼语音合成,界面如下:
前往 模型服务中心 创建好 API-key 即可,接着再去 API 参考文档中心 调用即可。
4.2.1 Python 接入 API
其中,instructions 指令控制是 Qwen3-TTS-Instruct-Flash 的核心灵魂。它把 “调音师” 的工作变成了 “导演” 的工作:你不需要去调参数,只需要给模型下达具体的文学性指令。
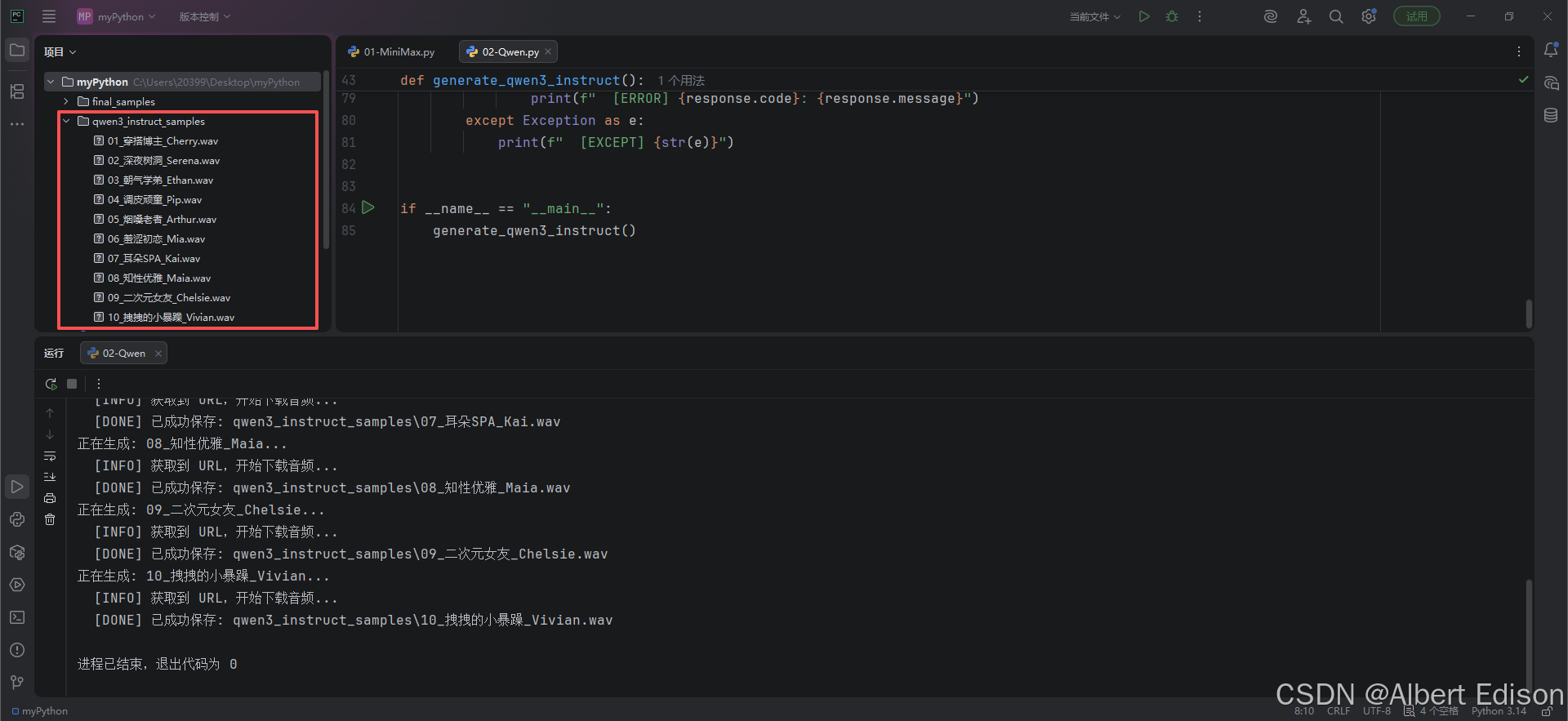
还是老样子,我重新构造了这 10 条数据。每一条都结合了音色特质和多维度指令(音调 + 语速 + 情感 + 特点),确保生成的音频具有极强的人格化特征。
代码如下所示:
import os
import dashscope
import requests
# 1. 配置 API Key
dashscope.api_key = "API-Key"
# 2. 任务清单
tasks = [
{"name": "01_穿搭博主_Cherry", "voice": "Cherry",
"inst": "语速较快,音调偏高,带有明显的阳光活力感和感染力,像是在镜头前兴奋地分享好物。",
"text": "宝子们!快看这款T恤,颜色真的绝了!超级显白!别犹豫,闭眼冲好吗?穿上它你就是这条街最靓的仔!"},
{"name": "02_深夜树洞_Serena", "voice": "Serena",
"inst": "语速偏慢,音调温柔低沉,带有明显的治愈感和关怀感,语气轻柔,像是在耳边低语。",
"text": "忙了一整天,辛苦了…… 现在,请试着闭上眼睛。听着窗外滴滴答答的雨声,把那些烦心事都暂时放下吧。"},
{"name": "03_朝气学弟_Ethan", "voice": "Ethan",
"inst": "标准普通话,语速中等偏快,声音洪亮有力,充满朝气和自信,带有一点惊喜的语气。",
"text": "学姐!嘿,真巧啊在这儿碰见你!那个……待会儿我们要去体育馆打球,你要不要一起来看?我投篮贼准!"},
{"name": "04_调皮顽童_Pip", "voice": "Pip",
"inst": "语速跳跃,音调较高且富有弹性,语气调皮搞怪,带有典型的童真色彩,模仿小孩子的撒娇感。",
"text": "嘿嘿,你抓不到我吧!略略略!妈妈说今天表现好就有冰淇淋吃,那我现在是不是全宇宙表现最棒的小朋友呀?"},
{"name": "05_烟嗓老者_Arthur", "voice": "Arthur",
"inst": "语速缓慢,嗓音沙哑厚重,带有明显的岁月沧桑感,语气不疾不徐,像是在村头老槐树下讲古。",
"text": "嘿嘿,那年大水发得紧呐…… 村东头那棵老槐树啊,一夜之间就没了踪影。这事儿说起来啊,其实还得从我爷爷那辈讲起。"},
{"name": "06_羞涩初恋_Mia", "voice": "Mia",
"inst": "语速偏慢且有轻微的停顿,音调柔和,语气羞涩、小心翼翼,带有一点点紧张和期许。",
"text": "那个……这是我亲手织的围巾。虽然样子不太好看,但是……但是真的很保暖的。你……你能收下它吗?"},
{"name": "07_耳朵SPA_Kai", "voice": "Kai",
"inst": "语速极慢,吐字圆润清晰,音调平稳中庸,带有极强的磁性和放松感,像是一场耳朵的SPA。",
"text": "放慢你的思绪,深呼吸。感受空气在肺部缓缓流转。在这繁忙的世界里,给自己留出这几分钟的纯净时光。"},
{"name": "08_知性优雅_Maia", "voice": "Maia",
"inst": "语速适中,吐字精准,音调知性优雅,语气平稳且富有逻辑感,像是在美术馆进行导览。",
"text": "艺术,不仅仅是画布上的色彩,更是对生命的深层思考。让我们一起走进这间画廊,去寻找灵魂的共鸣。"},
{"name": "09_二次元女友_Chelsie", "voice": "Chelsie",
"inst": "音调偏高,语速轻快多变,带有明显的二次元动漫感,情感表达夸张,先生气后撒娇。",
"text": "笨蛋!谁让你刚才一直不理我的?哼!不过看在你带了小蛋糕的份上,我就勉为其难地原谅你这一次啦!嘿嘿!"},
{"name": "10_拽拽的小暴躁_Vivian", "voice": "Vivian",
"inst": "语速偏快,语气冲且带有明显的不耐烦,音色清脆有力,带有拽拽的个性,情感外露。",
"text": "烦死了!说了多少遍了,不要动我的东西!你怎么就是记不住啊?懂不懂什么叫个人隐私啊?再敢乱翻我炸毛了哦!"}
]
def generate_qwen3_instruct():
output_dir = "qwen3_instruct_samples"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
for task in tasks:
print(f"正在生成: {task['name']}...")
try:
response = dashscope.MultiModalConversation.call(
model="qwen3-tts-instruct-flash",
text=task['text'],
voice=task['voice'],
language_type="Chinese",
instructions=task['inst'],
optimize_instructions=True
)
if response.status_code == 200:
# 根据你提供的 JSON 结构,提取 audio 下的 url
audio_info = response.output.audio
# 在 SDK 中,audio_info 可能是个对象,也可能是个字典
# 我们优先尝试获取 url 属性或键
audio_url = getattr(audio_info, 'url', None) or audio_info.get('url')
if audio_url:
print(f" [INFO] 获取到 URL,开始下载音频...")
audio_res = requests.get(audio_url)
file_path = os.path.join(output_dir, f"{task['name']}.wav") # Qwen3默认通常是wav
with open(file_path, 'wb') as f:
f.write(audio_res.content)
print(f" [DONE] 已成功保存: {file_path}")
else:
print(f" [ERROR] 无法在返回结果中找到 audio 字段或 url 字段")
else:
print(f" [ERROR] {response.code}: {response.message}")
except Exception as e:
print(f" [EXCEPT] {str(e)}")
if __name__ == "__main__":
generate_qwen3_instruct()
结果如下所示:
4.3 科大讯飞
官网地址:长文本语音合成 API 文档
它的核心优势如下:
- 长文本能力:单次合成上限约 10 万字符,10 万字最快约 3 分钟合成完毕。并且支持多种发音人 + 中英混合,适合长篇阅读、有声读物、新闻播报等。
- 音色克隆 / 声音复刻:1 句话就能定制音色,并且一句录音复刻任意音色,再用指令改变风格。
- 适合定位:偏传统企业级、合规 + 长文本 + 复刻自己或主播声音。
官网界面如下:
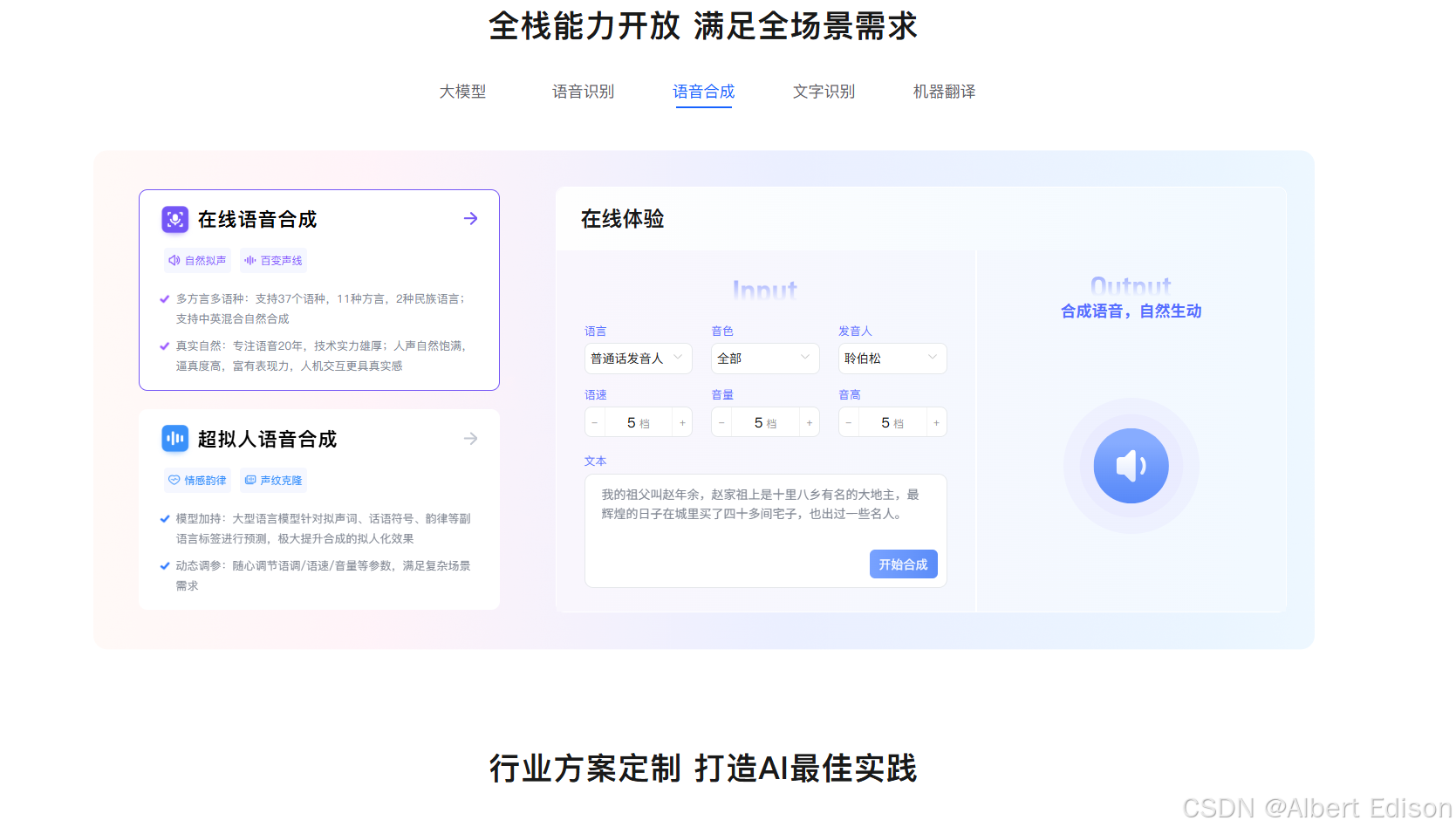
另外,还是需要去 控制台 开通权限。
4.3.1 Python 接入 API
科大讯飞的这款 DTS (大文本合成) 接口与之前的 Qwen 或 MiniMax 不同,它是一个异步任务系统。需要先提交任务获取 task_id,然后不断轮询(Query)直到合成完成获取下载链接。
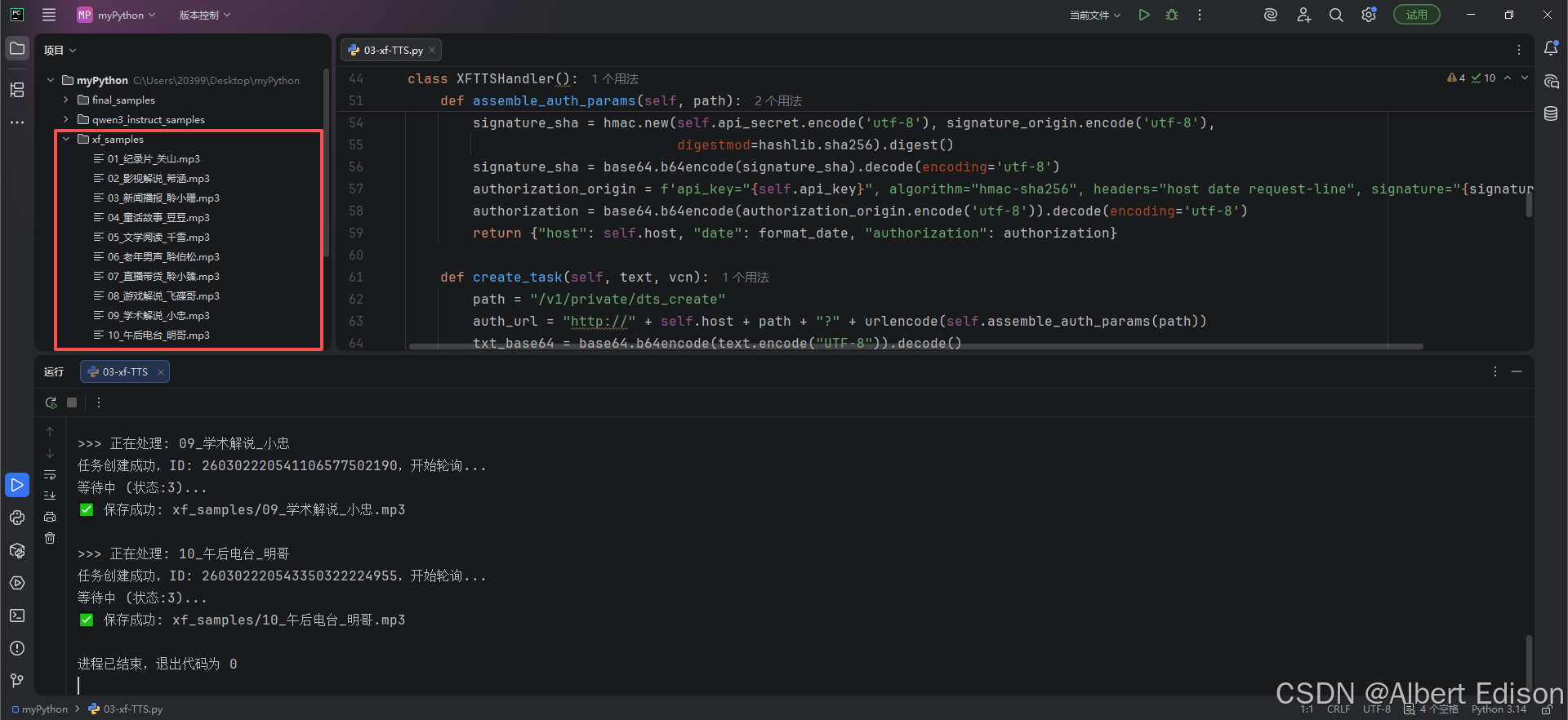
还是老样子,我构造了 10 条覆盖了 纪录片、新闻、童书、广告直播、影视解说 等全场景的文案,并重新整合了代码,使其支持批量循环处理。
这个脚本会自动循环这 10 条数据,提交任务、轮询结果并保存。
代码如下:
import requests
import json
import base64
import hashlib
import time
from urllib.parse import urlencode
import hmac
from datetime import datetime
from wsgiref.handlers import format_date_time
from time import mktime
import os
# --- 配置信息 ---
HOST = "api-dx.xf-yun.com"
APP_ID = "xxx"
API_KEY = "xxxx"
API_SECRET = "xxxxx"
# 10条任务配置
TASKS_DATA = [
{"name": "01_纪录片_关山", "vcn": "x4_guanshan", "text": "岁月流转,大地的肌理记录着文明的兴衰。在这片被时光遗忘的荒原上,每一块碎石都曾见证过帝国的崛起。"},
{"name": "02_影视解说_希涵", "vcn": "x4_yeting", "text": "注意看,这个男人叫小帅,他怎么也没想到,自己刚买的豪宅竟然是个大坑。剧情保证让你大开眼界!"},
{"name": "03_新闻播报_聆小珊", "vcn": "x4_lingxiaoshan_profnews", "text": "各位观众晚上好,欢迎收看今天的整点新闻。据本台最新消息,全球首个零碳智慧港口今日正式运营。"},
{"name": "04_童话故事_豆豆", "vcn": "x4_doudou", "text": "在森林的深处,住着一只爱打喷嚏的小兔子。每当它大喊一声,天上的星星就会跟着抖一下。"},
{"name": "05_文学阅读_千雪", "vcn": "x4_qianxue", "text": "窗外的雨一直没停,像是在低声诉说着谁的秘密。她合上手中的书,看那茶杯里的热气慢慢升腾。"},
{"name": "06_老年男声_聆伯松", "vcn": "x4_lingbosong", "text": "哎,那是民国二十年的事咯。那时候的上海滩,到处都是黄包车的铃铛声。现在的年轻人,哪记得咯。"},
{"name": "07_直播带货_聆小臻", "vcn": "x4_lingxiaozhen_eclives", "text": "家人们!注意啦!今天这款面霜直接破价!只有最后五十单,再不抢真的就没啦!三、二、一,上链接!"},
{"name": "08_游戏解说_飞碟哥", "vcn": "x4_feidie", "text": "关键时刻!对方打野已经绕后,上单根本不慌,一个反向闪现接大招,瞬间反杀!全场起立!"},
{"name": "09_学术解说_小忠", "vcn": "x4_xiaozhong", "text": "综上所述,该算法通过引入残差连接,有效地解决了深度神经网络中的梯度消失问题。"},
{"name": "10_午后电台_明哥", "vcn": "x4_mingge", "text": "听一首歌,想一个人。欢迎回到时光留声机。我会用声音陪你走过城市的喧嚣。"}
]
class XFTTSHandler():
def __init__(self):
self.host = HOST
self.app_id = APP_ID
self.api_key = API_KEY
self.api_secret = API_SECRET
def assemble_auth_params(self, path):
format_date = format_date_time(mktime(datetime.now().timetuple()))
signature_origin = f"host: {self.host}\ndate: {format_date}\nPOST {path} HTTP/1.1"
signature_sha = hmac.new(self.api_secret.encode('utf-8'), signature_origin.encode('utf-8'), digestmod=hashlib.sha256).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = f'api_key="{self.api_key}", algorithm="hmac-sha256", headers="host date request-line", signature="{signature_sha}"'
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
return {"host": self.host, "date": format_date, "authorization": authorization}
def create_task(self, text, vcn):
path = "/v1/private/dts_create"
auth_url = "http://" + self.host + path + "?" + urlencode(self.assemble_auth_params(path))
txt_base64 = base64.b64encode(text.encode("UTF-8")).decode()
data = {
"header": {"app_id": self.app_id},
"parameter": {
"dts": {
"vcn": vcn, "language": "zh", "speed": 50, "volume": 50, "pitch": 50,
"audio": {"encoding": "lame", "sample_rate": 16000, "channels": 1, "bit_depth": 16}
}
},
"payload": {"text": {"encoding": "utf8", "compress": "raw", "format": "plain", "text": txt_base64}}
}
res = requests.post(url=auth_url, headers={'Content-Type': 'application/json'}, data=json.dumps(data))
return json.loads(res.text)
def query_task(self, task_id):
path = "/v1/private/dts_query"
auth_url = "http://" + self.host + path + "?" + urlencode(self.assemble_auth_params(path))
data = {"header": {"app_id": self.app_id, "task_id": task_id}}
res = requests.post(url=auth_url, headers={'Content-Type': 'application/json'}, data=json.dumps(data))
return json.loads(res.text)
def main():
handler = XFTTSHandler()
if not os.path.exists("xf_samples"): os.makedirs("xf_samples")
for item in TASKS_DATA:
print(f"\n>>> 正在处理: {item['name']}")
# 1. 创建任务
create_res = handler.create_task(item['text'], item['vcn'])
if create_res.get('header', {}).get('code') != 0:
print(f"创建失败: {create_res}")
continue
task_id = create_res['header']['task_id']
print(f"任务创建成功,ID: {task_id},开始轮询...")
# 2. 轮询结果
download_url = None
for i in range(15): # 最多等15秒
time.sleep(1)
query_res = handler.query_task(task_id)
status = query_res.get('header', {}).get('task_status')
if status == '5':
encoded_url = query_res.get('payload', {}).get('audio', {}).get('audio')
download_url = base64.b64decode(encoded_url).decode()
break
print(f"等待中 (状态:{status})...")
# 3. 下载
if download_url:
audio_content = requests.get(download_url).content
filename = f"xf_samples/{item['name']}.mp3"
with open(filename, "wb") as f:
f.write(audio_content)
print(f"✅ 保存成功: {filename}")
else:
print("❌ 转换超时或失败")
if __name__ == "__main__":
main()
结果如下:
4.4 ElevenLabs
官网地址:文本转语音,它被业内和大量测评视为 AI 配音黄金标准,在情绪控制、停顿、咬字自然度上优势突出,贴合真人表达质感。
它的核心优势如下:
- 长音频能力:官方支持 Flash / Turbo 模型,单次最多约 40,000 字符,对应约 40 分钟音频。
- 音色克隆:仅需 1–2 分钟语音样本即可完成克隆。
- 适合场景:面向全球的多语言有声书、剧情配音、游戏 NPC 语音。
界面如下所示:
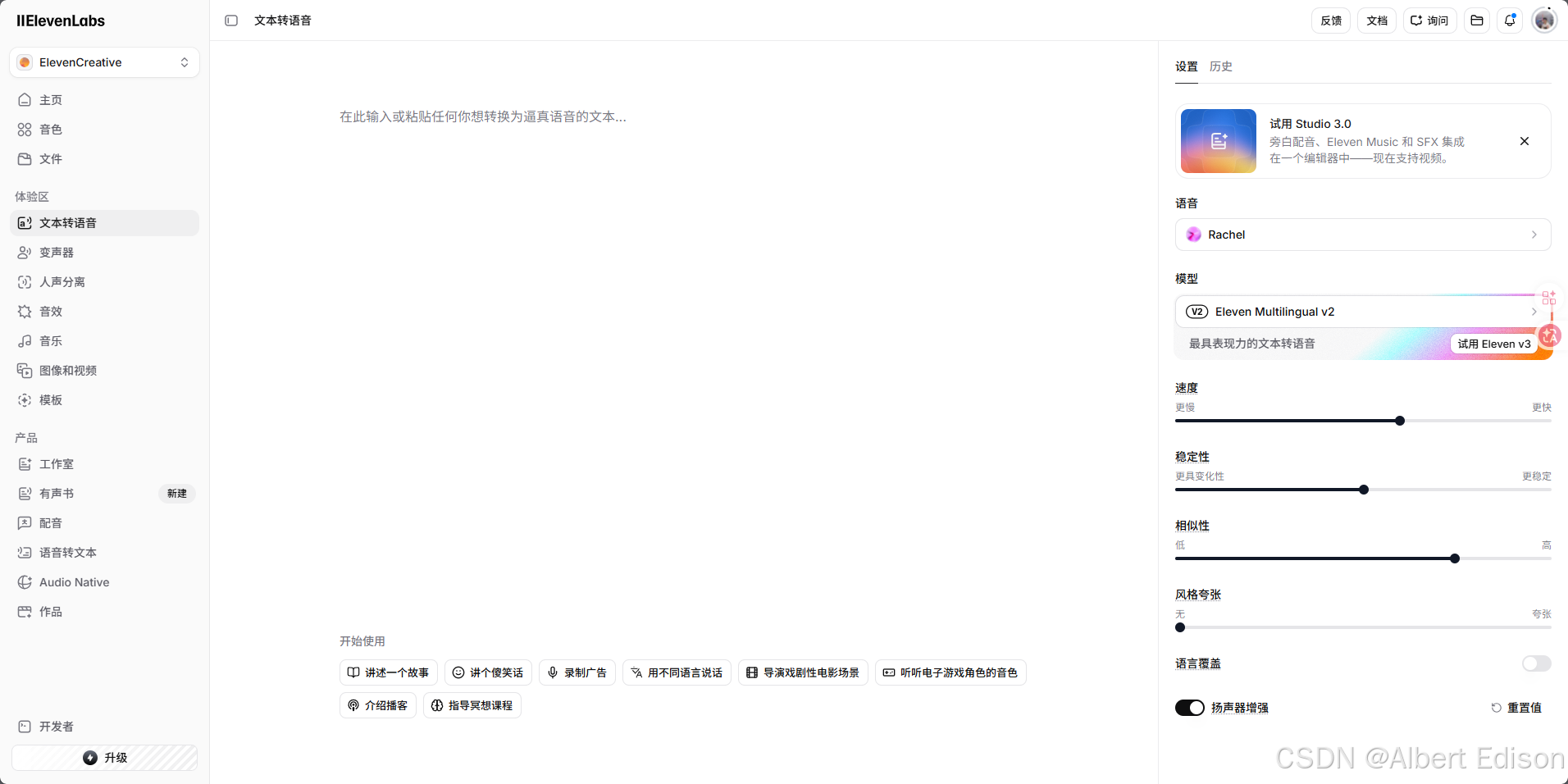
免费赠送的 API 是没有额度的,所以也无法调用,那么直接在线生成音频即可。
4.5 Fish Audio S1
官网地址:Fish Audio。
它的核心优势如下:
- 音色克隆:只需约10 秒样本就能克隆真实人声,精准保留口音、节奏、情绪特征。
- 核心特点:重点强调“情感丰富、节奏变化自然”,贴合真人情绪化表达,适配多样情感需求。
- 适合场景:剧情配音、情绪化独白;尤其适合内容主要发布在 B 站 / 抖音 / YouTube 等视频平台,性价比极高。
界面如下所示:
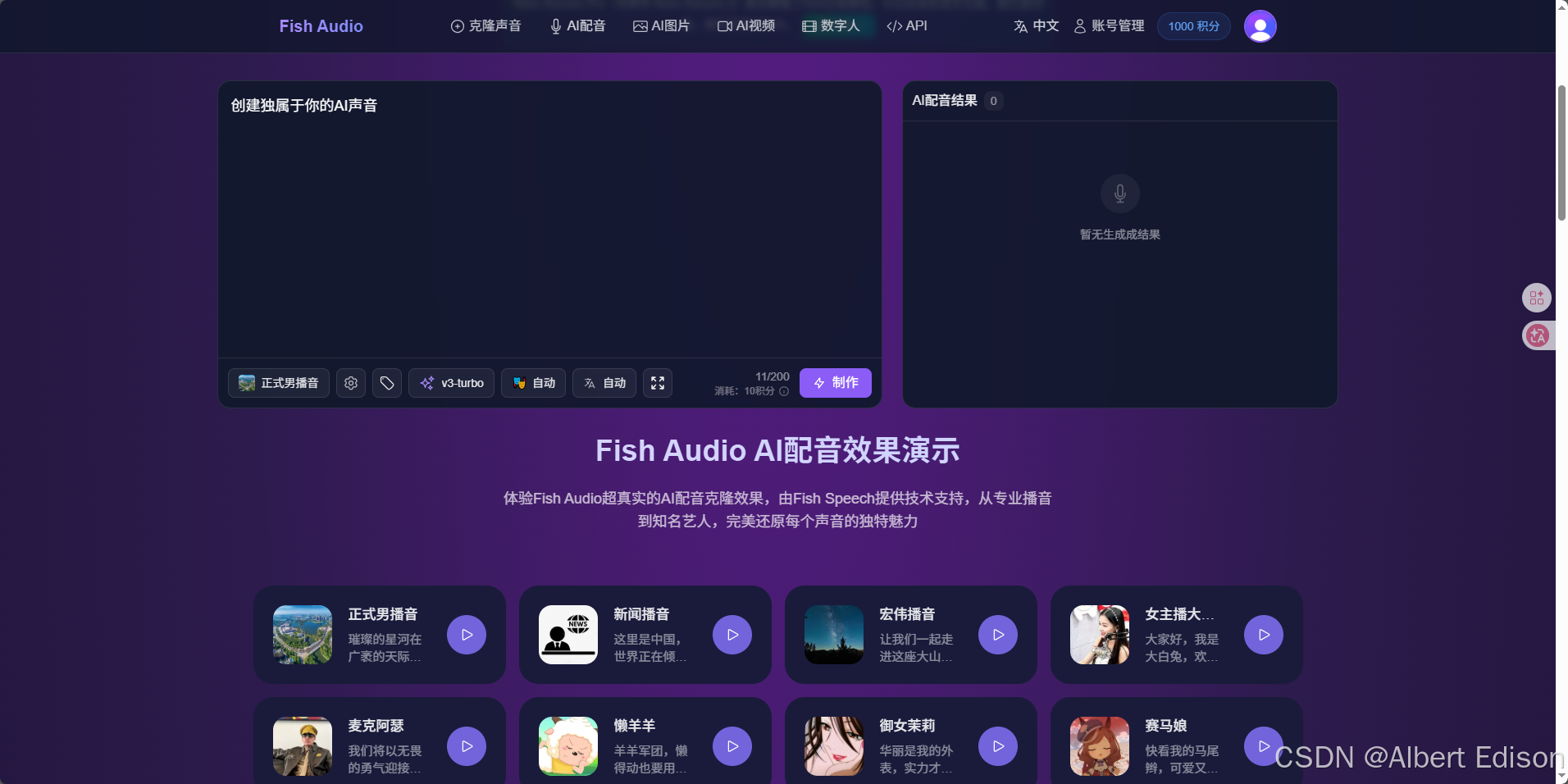
当然,也可以去访问 API 参考文档 直接调用即可。
4.5.1 Python 调用 API
Fish Audio 是目前 TTS 界公认的 “黑马”,它的 V3-HD 模型在音质拟真度和情绪渲染上非常出色,特别是它支持 emotion 情绪控制参数,这让你在汇报时可以展示非常细腻的垂直场景能力。
鉴于 Fish Audio 拥有大量极具个性的人设(如麦克阿瑟、葛大爷、丁真等),我这次构造的文案会更加侧重于角色扮演和强烈的情绪反差。
下面这个脚本将不再执行下载动作,而是直接把生成的所有 audio_url 整理输出,直接去下载即可。
代码如下所示:
import requests
import os
import json
# --- 配置信息 ---
API_KEY = "API-KEY"
API_URL = "https://fishaudio.net/api/open/tts"
# 任务列表
# TASKS = [
# {"name": "01_麦克阿瑟_冷静", "model_id": "e45668ef-7c4f-4966-b030-899fc63276c1", "emotion": "calm",
# "text": "每一个老兵都不会凋零,他们只是逐渐远去。在这个战场上,我们不仅是在对抗敌人,更是在书写传奇。"},
# {"name": "02_葛大爷_开心", "model_id": "172eb8cd-cb45-4b3d-85d3-d12e1068ddf4", "emotion": "happy",
# "text": "嘿,您还真别说,这小日子过得,那叫一个地道!咱就往这儿一躺,看云起云落,这就是生活的真谛。"},
# {"name": "03_正式男播音_愤怒", "model_id": "70df28f8-b5d1-4112-9ba2-8e260661c90e", "emotion": "angry",
# "text": "这种公然破坏公约的行为,是绝对不能被容忍的!我们必须采取最严厉的措施,来维护市场的基本公平。"},
# {"name": "04_女主播大白兔_惊讶", "model_id": "ff66d8d5-818f-43a8-9b6b-7936b6e75900", "emotion": "surprised",
# "text": "哇!家人们快看!这简直是我见过最神奇的设计了,你们敢相信这居然是全手工制作的吗?太绝了!"},
# {"name": "05_懒羊羊_悲伤", "model_id": "37a75f15-7397-4f39-bd4b-dca7937baf1f", "emotion": "sad",
# "text": "喜羊羊……我又被灰太狼抓住了。这次我是真的跑不动了,如果我回不去,你们一定要帮我吃掉草莓蛋糕。"},
# {"name": "06_丁真_平静", "model_id": "2292e4c6-f781-43da-bacd-8a815834c9c3", "emotion": "calm",
# "text": "这里的雪山很干净,马儿跑得也很快。希望你们也能来理塘,看一看最蓝的天空和最清澈的河水。"},
# {"name": "07_Trump_开心", "model_id": "c83acaa0-512d-4be5-a28e-e3d9893d815f", "emotion": "happy",
# "text": "We are going to make a great result! It's going to be huge! 没人比我更懂合成,这是最棒的声音!"},
# {"name": "08_御女茉莉_恐惧", "model_id": "2ded03d1-316d-457a-a527-a3cd082e5d05", "emotion": "fearful",
# "text": "谁?是谁在那里?……别过来,我警告你,这种恶作剧一点也不好笑,快点出来!"},
# {"name": "09_诸葛亮_庄重", "model_id": "a9c9f092-ba9b-498a-a990-d97e2a0bc6d9", "emotion": "calm",
# "text": "臣受命以来,夙夜忧叹,恐付托不效,以伤先帝之明。今南方已定,兵甲已足,当奖率三军。"},
# {"name": "10_蔡徐坤_厌恶", "model_id": "82e14166-b5cb-46fb-92cd-319d442e38a8", "emotion": "disgusted",
# "text": "这种无聊的流言蜚语,我已经听得太多了。如果你不懂艺术,请至少保持基本的尊重,好吗?"}
# ]
# 任务列表(精简版:大幅降低额度消耗)
TASKS = [
{"name": "01_麦克阿瑟_冷静", "model_id": "e45668ef-7c4f-4966-b030-899fc63276c1", "emotion": "calm", "text": "老兵不死,只是凋零。"},
{"name": "02_葛大爷_开心", "model_id": "172eb8cd-cb45-4b3d-85d3-d12e1068ddf4", "emotion": "happy", "text": "这日子过得,地道!"},
{"name": "03_正式男播音_愤怒", "model_id": "70df28f8-b5d1-4112-9ba2-8e260661c90e", "emotion": "angry", "text": "这是绝对不能容忍的行为!"},
{"name": "04_女主播大白兔_惊讶", "model_id": "ff66d8d5-818f-43a8-9b6b-7936b6e75900", "emotion": "surprised", "text": "哇!这也太神奇了吧!"},
{"name": "05_懒羊羊_悲伤", "model_id": "37a75f15-7397-4f39-bd4b-dca7937baf1f", "emotion": "sad", "text": "我回不去了,帮我吃掉蛋糕。"}
]
def get_fish_audio_urls():
results = []
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
print("--- 开始请求 Fish Audio 接口 ---")
for task in TASKS:
payload = {
"reference_id": task['model_id'],
"text": task['text'],
"speed": 1.0,
"volume": 0,
"version": "v3-hd",
"emotion": task['emotion'],
"language": "zh",
"format": "mp3",
"cache": True
}
try:
response = requests.post(API_URL, headers=headers, json=payload)
if response.status_code == 200:
data = response.json()
url = data.get("audio_url")
results.append(f"{task['name']}: {url}")
print(f"✅ 已获取: {task['name']}")
else:
print(f"❌ 失败: {task['name']}, 错误: {response.text}")
except Exception as e:
print(f"⚠️ 异常: {task['name']}, {str(e)}")
# 将结果保存到文本文件
with open("fish_urls.txt", "w", encoding="utf-8") as f:
f.write("\n".join(results))
print("\n--- 全部完成 ---")
print("生成的所有链接已保存在同级目录下的 'fish_urls.txt' 文件中。")
if __name__ == "__main__":
get_fish_audio_urls()
很尴尬的是,它送的免费额度很少很少,所以最后只生成了 3 个样例。
5. 本地方案
下面这些 TTS 服务都是开源的,所以适合想完全掌控,并且低成本的大规模部署。
5.1 IndexTTS‑2
官网地址:IndexTTS2。
IndexTTS-2 是 B 站 Index 团队开源的第二代零样本文本转语音系统。说白了就是:给它一段参考音频,它就能用这个声音说任何你想说的话,还能带情绪。
它的功能如下:
- 零样本语音克隆:只需 5 ~ 10 秒目标说话人音频,就能用该音色合成任意文本。
- 情感 & 音色解耦:可分别指定 “音色参考音频” 和 “情感参考音频”,或用文字描述情感(激昂、委屈、低语等)。
- 时长控制:支持毫秒级时长控制,可精确指定语速或目标时长,解决字幕 / 口型对齐问题。
- 长文本支持:官方文档、实测与周边工具(如 Lipvoice、一键包)都强调其长文本稳定生成能力,可处理章节/整书级内容。
- 适合:完全自定义 TTS 流水线;或者需要情感可控 + 时长可控 + 零样本克隆。
官网界面如下:
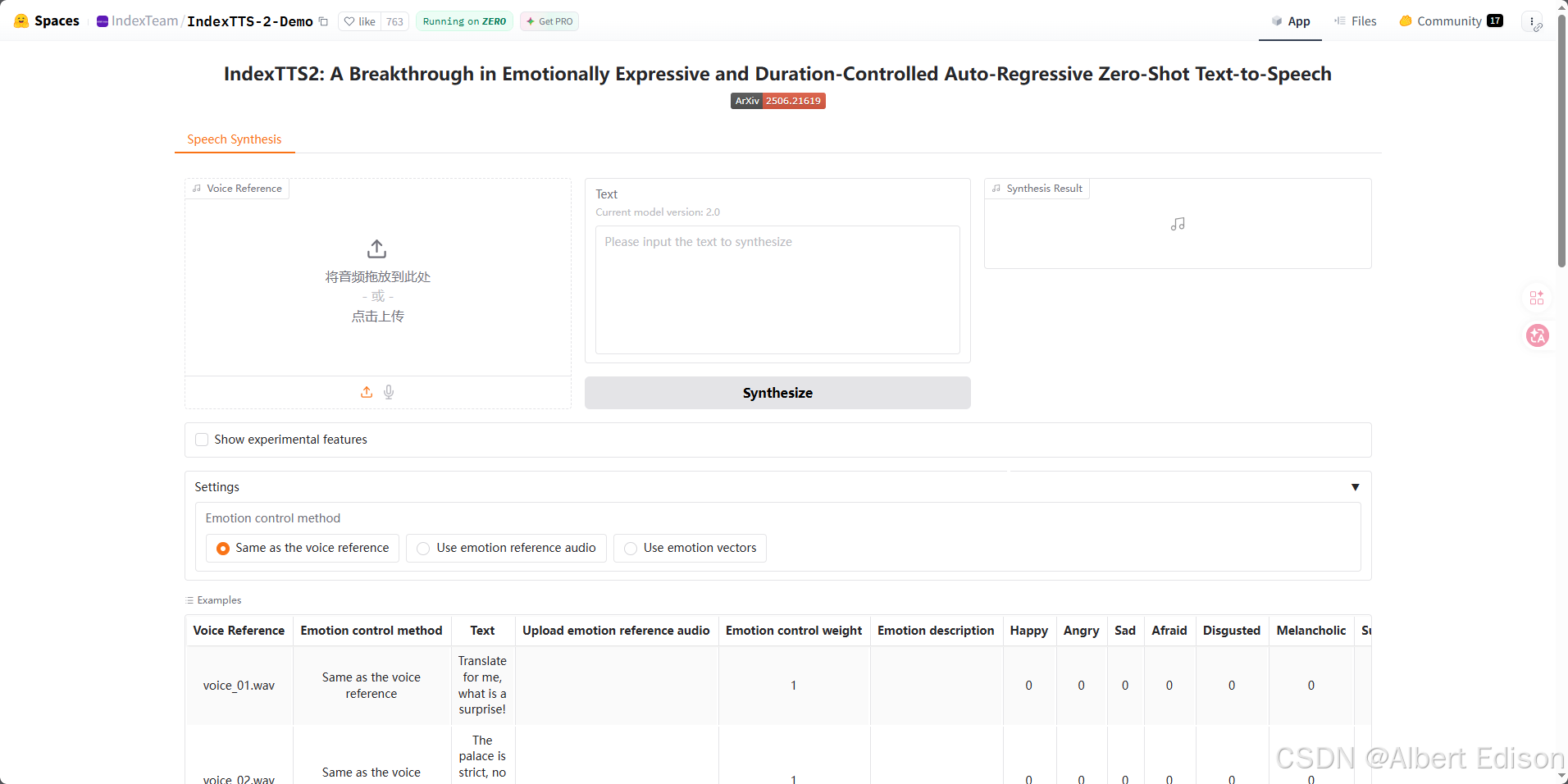
5.1.1 本地部署
这里我们选择本地部署,它的硬件要求如下:
- GPU:NVIDIA GPU + CUDA 12.8+(推荐)
- 内存:8GB+(推荐 16GB)
- 存储:10GB+
安装
IndexTTS-2 的安装方式比较现代化,必须用 uv 包管理器,官方不支持 conda 和 pip(原因是依赖版本太敏感)。详情可见 github仓库
命令如下:
# 1. 安装 uv
pip install -U uv
# 2. 克隆仓库
git clone https://github.com/index-tts/index-tts.git && cd index-tts
git lfs pull
# 3. 安装依赖
uv sync --all-extras
# 4. 下载模型
uv tool install "huggingface-hub[cli,hf_xet]"
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
# 如果 HuggingFace 访问慢,可以用 ModelScope:
uv tool install "modelscope"
modelscope download --model IndexTeam/IndexTTS-2 --local_dir checkpoints
使用
Web Demo 一键启动:
uv run webui.py
访问 http://127.0.0.1:7860 即可体验。
除此之外,Python API 使用:
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(
cfg_path="checkpoints/config.yaml",
model_dir="checkpoints",
use_fp16=True, # 省显存
use_cuda_kernel=False,
use_deepspeed=False
)
# 基础语音克隆
text = "大家好,我是 AI 配音"
tts.infer(
spk_audio_prompt='examples/voice_01.wav',
text=text,
output_path="gen.wav"
)
情感控制的几种方式:
# 方式 1:参考音频控制情感
tts.infer(
spk_audio_prompt='voice.wav', # 音色
emo_audio_prompt='emo_sad.wav', # 情感
text=text,
emo_alpha=0.9, # 情感强度
output_path="gen.wav"
)
# 方式 2:情感向量控制
# [happy, angry, sad, afraid, disgusted, melancholic, surprised, calm]
tts.infer(
spk_audio_prompt='voice.wav',
emo_vector=[0, 0, 0, 0, 0, 0, 0.45, 0], # 惊讶
text=text,
output_path="gen.wav"
)
# 方式 3:自然语言描述情感
tts.infer(
spk_audio_prompt='voice.wav',
text="快躲起来!是他要来了!他要来抓我们了!",
use_emo_text=True, # 自动从文本推断情感
emo_alpha=0.6,
output_path="gen.wav"
)
我这边测试的内容如下:
### 1. 喜(开心)
今天真的太开心了,不仅事情进展得特别顺利,还收到了大家的鼓励和支持,一整天心情都特别好,感觉做什么都特别有劲头。
### 2. 怒(生气)
我真的有点生气了,明明提前跟你说过很多次,结果你还是没有放在心上,完全不考虑我的感受,这样真的很让人失望。
### 3. 哀(难过)
不知道为什么,突然就觉得心里特别难受,有些事情想起来就忍不住难过,明明不想这样,却还是控制不住自己的情绪。
### 4. 惧(害怕)
刚才突然听到外面有奇怪的声音,我一下子就紧张起来了,心怦怦直跳,一个人待着的时候,真的会有点害怕。
### 5. 厌恶(反感)
我真的很不喜欢别人随便乱动我的东西,也很反感说话不算数、出尔反尔的行为,这些做法真的让人很不舒服。
### 6. 低落(消沉)
最近整个人都提不起精神,做什么都觉得没力气,心里闷闷的,也不想说话,就只想安安静静地待一会儿。
### 7. 惊喜(意外开心)
我真的完全没有想到,你居然给我准备了这么大的惊喜,本来以为只是普通的一天,结果一下子被感动到了。
### 8. 平静(安稳)
现在什么都不想去想,也不想去争什么,就想安安静静地待着,听听歌、发发呆,这种平静安稳的感觉真的很舒服。
5.2 VibeVoice‑1.5B
官网地址:VibeVoice
它的功能如下:
- 长音频天花板:单次可合成最长 90 分钟连续音频,最多 4 个不同说话人同时出现在对话中。
- 面向 “播客式” 长音频设计,极适合:自动生成整期播客长篇对话类节目(访谈、圆桌讨论)
- 音色 / 说话人:支持多说话人,能从参考音频中进行语音克隆(voice cloning from audio samples)。
官网界面如下:
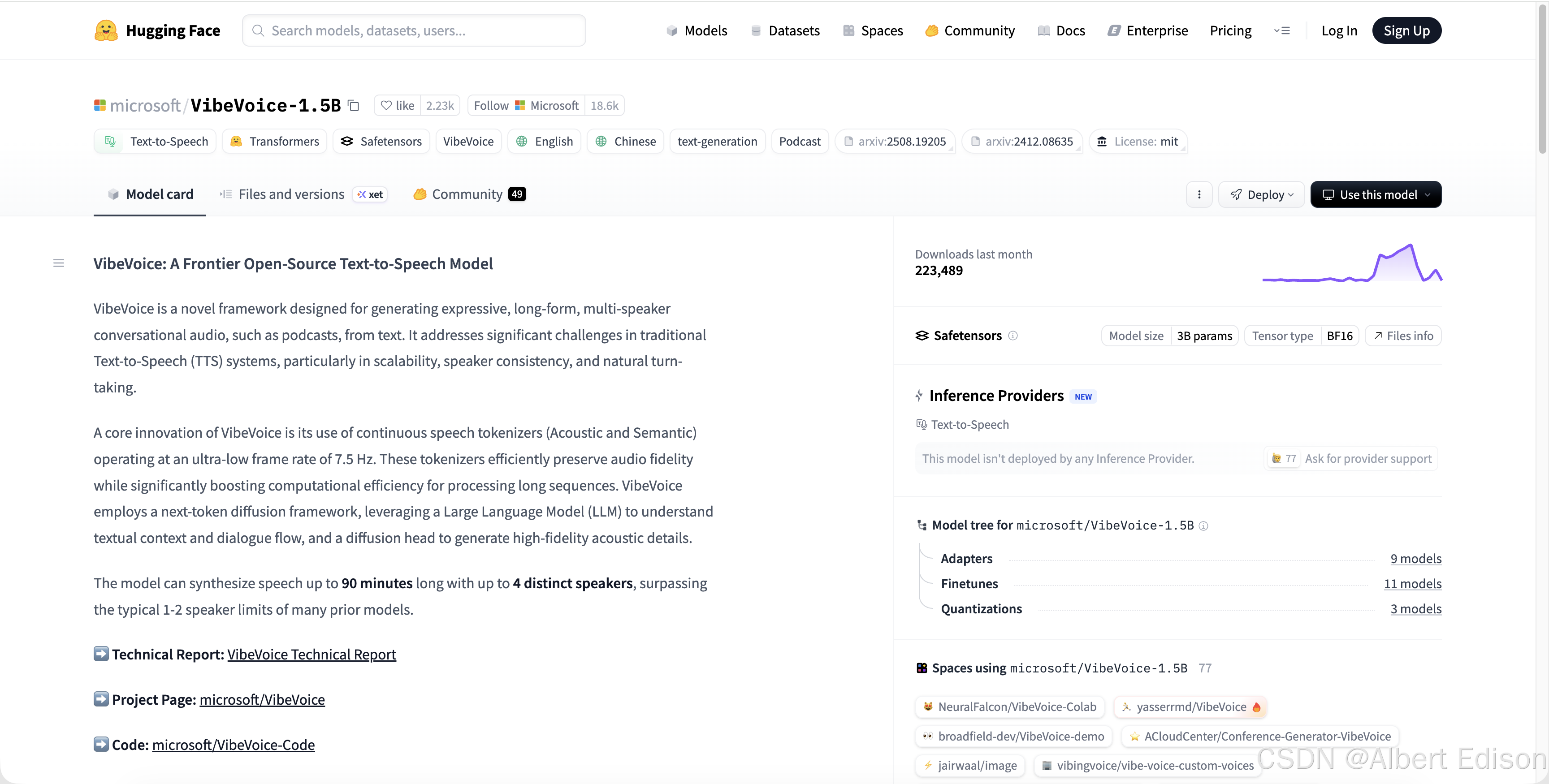
目前官方已经关闭了在线使用界面,只能部署到本地才能使用:VibeVoice-TTS
5.2.1 本地部署
部署 VibeVoice:
# 克隆仓库
git clone https://github.com/microsoft/VibeVoice.git
cd VibeVoice
# 安装依赖
pip install -r requirements.txt
# 下载轻量模型(约1.5GB)
python download_model.py --model small
# 启动服务
python app.py --port 8000
搞科研就要不计回报,整天想休息是什么态度?实验室大家都加班,你凭什么先走?周末把这个实验重做一遍,补助之类的别总挂在嘴边。
效果展示:
6. 最终展示
直接本地使用 Python 实现一个简单的音频播放网页,选用 Flask 框架。
由于有不同模型的分类,我们可以通过文件夹结构来组织音频,并让 Python 自动读取这些文件生成网页。
6.1 准备工作
首先,确保你安装了 Flask:
pip install flask
将不同模型的音频放在各自的子文件夹中:
my_audio_project/
├── app.py
├── static/
│ ├── model_1/
│ │ └── 01-demo.mp3
│ ├── model_2/
│ │ └── test.wav
│ └── ... (以此类推到 model_7)
└── templates/
└── index.html
6.2 编写后端代码 (app.py)
这段代码会自动扫描 static/model_1 文件夹下的所有音频文件,并将文件名传递给前端。
import os
from flask import Flask, render_template
app = Flask(__name__)
@app.route('/')
def index():
base_dir = 'static'
# 获取 static 目录下所有的文件夹(即模型名称)
model_folders = [d for d in os.listdir(base_dir) if os.path.isdir(os.path.join(base_dir, d))]
model_folders.sort() # 按名称排序 model_1, model_2...
all_data = {}
for folder in model_folders:
folder_path = os.path.join(base_dir, folder)
# 获取该模型文件夹下所有的音频文件
files = [f for f in os.listdir(folder_path) if f.endswith(('.mp3', '.wav'))]
files.sort()
all_data[folder] = files
return render_template('index.html', all_data=all_data)
if __name__ == '__main__':
app.run(debug=True)
6.3 编写前端页面 (templates/index.html)
使用嵌套循环,外层循环生成模型标题,内层循环生成音频列表。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>多模型音频对比展示</title>
<style>
body { font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif; max-width: 900px; margin: 40px auto; background-color: #f9f9f9; color: #333; }
.model-section { background: white; padding: 20px; border-radius: 8px; box-shadow: 0 2px 5px rgba(0,0,0,0.1); margin-bottom: 30px; }
h2 { border-left: 5px solid #007bff; padding-left: 15px; color: #007bff; text-transform: capitalize; }
table { width: 100%; border-collapse: collapse; margin-top: 10px; }
th, td { text-align: left; padding: 12px; border-bottom: 1px solid #eee; }
th { background-color: #fcfcfc; color: #666; }
.file-name { font-family: monospace; color: #555; }
audio { height: 32px; vertical-align: middle; }
</style>
</head>
<body>
<h1 style="text-align: center;">音频合成效果展示</h1>
{% for model_name, files in all_data.items() %}
<div class="model-section">
<h2>{{ model_name.replace('_', ' ') }} 合成的语音:</h2>
<table>
<thead>
<tr>
<th>文件名</th>
<th>播放器</th>
</tr>
</thead>
<tbody>
{% for file in files %}
<tr>
<td class="file-name">{{ file }}</td>
<td>
<audio controls preload="none">
<source src="{{ url_for('static', filename=model_name + '/' + file) }}" type="audio/mpeg">
</audio>
</td>
</tr>
{% endfor %}
</tbody>
</table>
</div>
{% endfor %}
</body>
</html>
如果你以后增加到 10 个模型,只需在 static 下新建文件夹并丢入音频,不需要改动任何代码。
6.4 如何运行
在终端运行:python app.py,打开浏览器访问:http://127.0.0.1:5000 即可。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)