6、【AI】【Agent】输入/输出 tokens
本文分析了AI模型生成token速度(tokens/s)与用户体验的关系,指出30-60 tokens/s是流畅交互的基准。文章对比了输入和输出token处理的差异:输入处理(prompt分词)可并行且快速(~1600 tokens/s),而输出生成必须串行且依赖上下文(典型100 tokens/s)。关键发现包括:1)输出速度是用户体验的决定因素;2)输出阶段计算量随上下文长度增加;3)用户更关
【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除
背景
上篇 blog
【AI】【Agent】tokens生成速度
分析了参数量和 tokens/s 输出速度的关系,并提到其实际速度还受到模型架构,内存带宽,CPU 缓存命中率等因素的影响,所以不是严格线性,而是衰减更快,分析了在纯 CPU 推理下,瓶颈不在 CPU 算力,而在于内存带宽,而如果是 GPU 作计算主力的话,由于其显存带宽远远大于内存带宽,所以瓶颈会转移到模型能力上,下面继续分析
Agent
最后再给上篇 blog 作个总结:
- 参数量上升 → 每
token计算量上升 → 内存搬运量上升 →tokens/s输出速度下降
一份 tokens/s 生成速度和用户体验的参考如下
tokens/s |
用户体验 |
|---|---|
| < 10 | 卡顿,像在等待转圈 |
| 10~30 | 可用,但需耐心 |
| 30~60 | 流畅,接近人类思考节奏 |
| > 60 | ⚡丝滑,感觉 AI 在抢答 |
| > 100 | 🚀 飞一般的感觉,Phi-3 在好的 CPU 上可达到 |
可以看到,用户本地部署的模型,其生成的 tokens/s 的速度应尽量达到 30~60 tokens/s,才能有良好的体验
另外,在生成式任务中,上面一直提到的 tokens/s 指的是输出 token 的速度,而不是输入处理速度,下面来对比下输入 token 和输出 token 的区别
| 类型 | 说明 | 负责模块 | 是否影响 tokens/s |
|---|---|---|---|
输入 tokens |
发给模型的 prompt | tokenizer | 不计入生成速度 |
输出 token |
模型生成的回答 | 模型 + tokenizer | tokens/s 只测这个 |
这里的 prompt 直译为提示词
以 OpenCoder 为例,假设让 Agent 写代码,发送输入 prompt
用 Python 写一个快速排序函数
此时 prompt 会被拆成 8 个 input tokens:[用,Python,写,一,个,快速,排序,函数],这一步很快,属于纯文本分词,而且不涉及模型推理,通常 < 10ms
接着模型会开始逐个生成输出 tokens,一个简易的模型内部循环如下
output_tokens = []
while not stop:
# 每次调用模型,生成 1 个新 token
next_token = model(input_tokens + output_tokens)
output_tokens.append(next_token)
print(tokenizer.decode(next_token)) # 实时显示
最后生成出
["def", " ", "quick", "sort", "(", "arr", ")", ":", "\n", " ", "if", ...]
等,假设有 60 个 output tokens,那么这 60 次的模型调用,就是 tokens/s 的测量对象
在 llama.cpp 或 Ollama 的性能测试工具中,可以这样测速
start_time = time.time()
# 生成 100 个 output tokens
for i in range(100):
token = model.generate_next_token()
output += decode(token)
end_time = time.time()
tokens_per_second = 100 / (end_time - start_time) # ← 只算输出!
可以看到,输入 tokens 的处理时间被排除在外,或单独报告为 prompt processing speed
举个例子,在 Ryzen 9 上跑 Phi-3-mini-Q5_K_M 模型,其速度差异如下
| 阶段 | tokens |
耗时 | 速度 |
|---|---|---|---|
| 输入处理 | 8 tokens |
~5ms | ~1600 tokens/s(极快) |
| 输出生成 | 60 tokens |
~0.6s | ~100 tokens/s(看到的指标) |
输入处理之所以比输出快得多,除了上面提到的,输入处理无需推理外,输入 prompt 可以并行处理(整个 prompt 一次向前传播),而输出必须串行生成(每步必须依赖上一步,也就是自回归过程),也就是下面这个模型
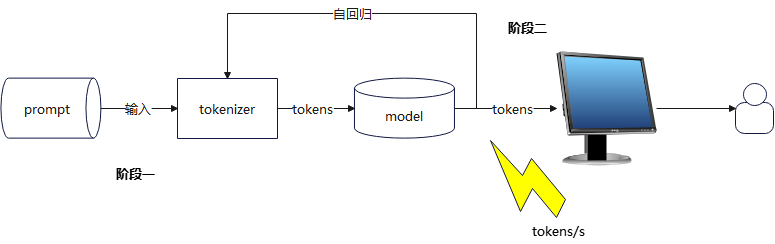
可以看到,在阶段一的输出处理中(Prompt Processing)
- 一次性处理整个 prompt
- 计算量 ≈ 模型参数量 × 输入
tokens数量 - 可并行加速,而且这一步只发生一次
而在阶段二的输出生成中(Token Generation)
- 逐个生成 output tokens
- 每生成一个
token,计算量 ≈ 模型参数量 × 当前上下文总长度 - 这一步必须串行(每步依赖上一步),而且这个串行步骤会发生 N 次(N = 输出
token总数)
此外,用户一般也只关心输出速度 tokens/s,因为
- 输入一般很短(< 100
tokens),耗时可忽略 - 用户体验由输出速度决定,一般使用的时候会盯着屏幕等 AI 打字
- 输出长度不可控,有时候只输出几个
token,多的时候也可能几千token
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)