5、【AI】【Agent】tokens生成速度
本文分析了不同硬件环境下大模型生成tokens的速度差异。在纯CPU推理场景中,内存带宽成为主要瓶颈,导致即使强大CPU也无法充分发挥计算能力,如7B模型受限于DDR5内存带宽只能达到40-60 tokens/s。相比之下,GPU凭借更高显存带宽(如RTX 4090达1TB/s)能更好发挥并行计算优势。文章特别推荐了微软优化的Phi-3-mini模型(3.8B),其通过架构精简、CPU友好设计和算
【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除
背景
上篇 blog
【AI】【Agent】tokens 介绍
分析了 token 的定义,以及输入 tokens 的处理,和输出 tokens 的速度,分析了参数量与输出 tokens 的关系:参数量越大,输出 tokens 速度越小,并分析了其原因,提到了大模型生成文本是逐个 token 自回归的过程,其生成的每一个 token 都会被重新作为输入,再经过模型计算,生成出新的 token,下面继续分析
Agent
上篇 blog 提到,对于每个新生成的 token,模型都要执行如下操作
- 从内存中,加载所有参数到 CPU 缓存
- 做矩阵乘法和激活函数
- 继续采样下一个
token
其中,这里的第 2 步的计算量 ≈ 模型参数量 × 上下文长度,所以 7B 模型的计算量 ≈ 3.8B 模型的 1.84 倍
所以用之前的表格数据
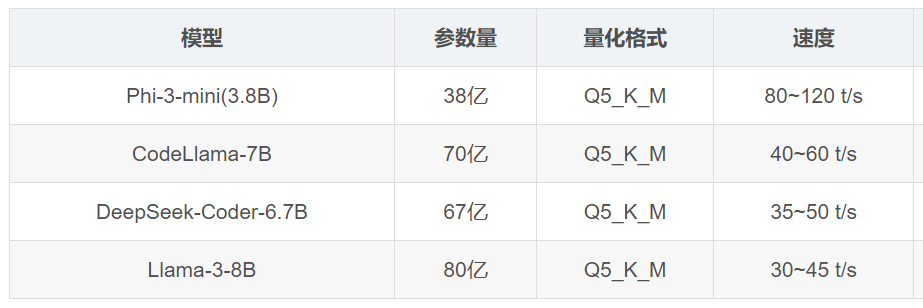
可以推算出来参数量和 tokens/s 输出速度关系大致如下
| 模型 | 参数量 | 相对计算量 | 速度 | 速度比(vs Phi-3) |
|---|---|---|---|---|
| Phi-3-mini | 3.8B | 1.0x | 100(取中值) | 1.0x |
| CodeLlama-7B | 7.0B | ~1.84x | 50 | ~0.5x |
| Llama-3-8B | 8.0B | ~2.1x | 37.5 | 0.375x |
可以看到,tokens/s 输出速度和参数量的关系是符合预期的,当计算量翻倍时,速度减半,而且实际速度还受模型架构,内存带宽,CPU 缓存命中率等因素影响,所以不是严格线性,而是衰减得更快,但大体趋势不变
OK,上面提到了 tokens 的生成速度除了正比于参数量,还受到一些硬件瓶颈的限制,下面来看下这些硬件约束(比如内存带宽),是如何影响计算能力的
在纯 CPU 推理的场景,比如这台机器,虽然 CPU 能力很强大(Ryzen 9),但是 GPU 很弱,属于入门级显卡,在这种场景下,真正的瓶颈往往不是 CPU 算力,而是内存带宽
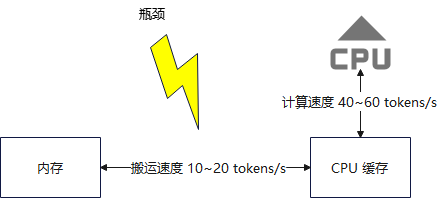
举个例子,比如一个 7B 的模型,使用 Q5_K_M 进行量化,经量化后的内存需要约 5.5GB,此时每生成一个 token,CPU 就需要从内存中再读取数个 GB 的权重,而 DDR5 内存的带宽 ≈ 50~70GB/s,也就是说,每秒最多能搬运 10 ~ 20 个 token 的数据权重(而这个模型下的计算能力可以生成 token 的速度是 40~60 tokens/s),此时就可以看到
- 数据搬运速度 < CPU 计算速度
这就意味着 CPU 要经常饿着等数据,这也就是为什么参数越多,每次要搬运的数据越多,等待的时间越长,tokens/s 越低,往往达不到 CPU 理论计算能力的 tokens 生成速度,所以即使 CPU 再强,有 16 核,也会被内存拖慢了
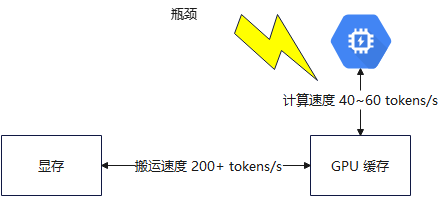
OK,上面提到的是纯 CPU 推理,主要依靠的是 CPU 计算能力,但受内存带宽的影响,其 tokens/s 的生成速度上限被降低了,但如果是 GPU 作为计算主力的话,下面来看下,假设有 RTX 4090(带 24GB 显存):
- 显存带宽 ≈ 1 TB/s(远远大于 DDR5,是 DDR5 的 15 倍!)
- 权重全在显存,此时数据搬运极快
- 那么此时数据搬运就不再是瓶颈,瓶颈又会转移到计算速度上,此时大模型更能发挥出并行优势
OK,所以最后总结下,在 CPU + 内存的场景,主要依靠 CPU 进行推理的话,内存带宽是瓶颈,大模型能力会被拖后腿,要想真正发挥大模型计算能力,建议升级 GPU
然后再提下 Phi-3 模型,如果是这种 CPU 推理场景,建议使用 Phi-3 模型,因为微软对 Phi-3 做了极致优化:
- 架构精简:用更少的参数实现接近 7B 的能力
- CPU 友好设计:减少内存访问模式的随机性,提高缓存命中率
- 算子融合:把多个计算步骤合并,减少数据搬运
所以 Phi-3-mini(3.8B)特别快,能达到接近于 2 倍于 Llma-3-8B 的速度,得益于其在数据搬运的功能上做了功夫,但从长远来看,还是最好升级 GPU
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog
【AI】【Agent】输入/输出 tokens

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)