至顶AI实验室硬核评测|驯服千亿级模型,OpenClaw本地调用——AMD锐龙AI Max+ 395释放个人超算极致性价比
至顶AI实验室硬核评测|驯服千亿级模型,OpenClaw本地调用——AMD锐龙AI Max+ 395释放个人超算极致性价比
最近,OpenClaw火了。
这个被称为“最接近Jarvis”的开源AI Agent,在GitHub上狂揽15万星。它能读写文件系统、执行Shell命令、操控浏览器,支持7×24小时运行,还能把任务结果主动推送到手机上——第一次,Agent开始像真正的“个人助理”。
但当我把OpenClaw真正接入日常工作,问题就很快显现出来。
一个复杂的编程任务,往往需要数十轮工具调用。读代码、跑命令、分析报错、修改方案、验证.....每一轮“思考”都在消耗token。按照Claude Code的计费标准,输入是5美元/百万token,输出是25美元/百万token。这对于长时间运行、超长上下文、频繁调工具的OpenClaw来说,成本会随着任务复杂度迅速累积。
数据是更现实的问题。当OpenClaw接触真实项目时,其读取的是代码仓库、内部文档、API密钥和业务逻辑。此时,如果依赖云端API,那么这些数据就必须离开本地网络,安全问题就变得不可控了。
也正是在这个过程中,我逐渐意识到,我需要的不只是一个能用的AI,更是一个稳定、保护隐私、随时可用的算力。其能保护数据安全、也不用为流量额外付费,即开即用。
这意味着,我们需要的是一台为AI长期运行而设计的本地算力节点。对个人而言,它可以被称之为一台“个人AI超算”。这种判断并非只来自个人思考。最近,OpenClaw创始人Peter Steinberger 在分享中透露,他已经在自己的工作室部署了一台512GB顶配设备,专门用于运行本地AI模型。
那么,应该如何选择这台“个人AI超算”呢?判断标准其实并不复杂,核心有三点:
第一,计算性能。能够在本地稳定运行主流模型,承载持续推理和多任务负载。
第二,扩展能力。能应对更复杂的Agent并行任务;
第三,性价比。在满足性能和扩展性的前提下,以更低价格获得更多“可持续、可用的算力”。
基于这些标准,我最近发现了一台能满足需求的设备——铭凡 MS-S1 MAX 迷你 AI 工作站。它搭载AMD锐龙AI Max+ 395处理器,单台支持128GB 统一内存,单机可运行OpenClaw,可本地调用Qwen3-Next 80B这类最新的端侧推理模型。更关键的是,其支持双机高速互联。两台设备组成集群后,算力与内存翻倍,足以支撑OpenClaw本地部署大参数模型。
然而,这台工作站,单台价格不超过两万元,相比顶配Mac Studio,这套方案的成本明显更低。

01 3.3L的个人超算,铭凡的80Gbps雷电5与双万兆“性能猛兽”
拿到这台铭凡MS-S1 MAX迷你AI工作站,说实话很难相信它只有3.3L的体积,在221×196×76mm(不含脚垫)的三维空间中,却塞进了一颗能稳定130W、峰值高达160W的AMD锐龙AI Max+395处理器平台(下称“AMD锐龙AI Max+ 395”),更配备了一套工作站级的一体化主板,这远远超过传统迷你工作站该有的规格了。
外观上看,整机机身采用极夜灰搭配经典商务黑金属外壳,相较于拼接式结构在抗弯折与抗冲击上更具优势;多道精细表面处理工艺在提升触感细腻度的同时,也增强了表面耐磨性,有效抑制日常使用中的指纹残留与细微划痕。
机身正面,铭凡采用了标志性的菱形矩阵散热网格设计。通过基于空气动力学优化的进气结构,显著提升了进风效率与气流均匀性。每一个菱形网孔都经过精确计算,并结合内部多层切割工艺处理,使正面在不同光线条件下呈现出清晰的层次感与纵深感,在强化散热性能的同时,也保留了鲜明的科技质感。

接口配置同样延续了商务感设计思路。首先是集成状态指示灯的电源键,按压反馈清晰,灯效逻辑直观,用户在任何情况下都能快速判断设备所处的运行、待机或关机状态。
整机前置接口电源键下边提供了一组USB 3.2 Gen2 Type-A接口,和两组USB4接口支持40Gbps的超高速数据传输,兼容DP Alt Mode 2.0视频输出,并提供最高15W的PD对外供电能力。在实际工作中,用户可以直接在前面板连接高速移动SSD读取模型权重或数据集,外接便携显示器作为副屏进行监看,甚至同时为手机或其他设备充电,连接多种创作设备,大幅降低接口切换与线材管理的复杂度。
音频部分配备了一个3.5mm二合一接口,支持耳机与麦克风输入输出,能够覆盖视频会议、音频监听以及基础录音等使用场景。
另外前面板还有2个Dmic拾音接口,支持主流AI大模型智能语音交互。

转到机身背面,一整套接口配置足以让人感到兴奋。
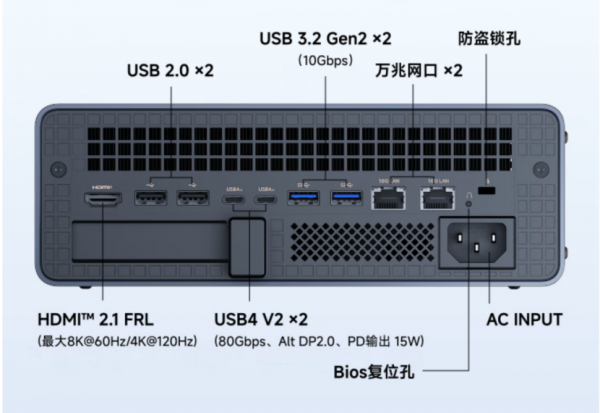
两个USB4 V2接口(雷电5),单口带宽高达80Gbps,这是目前主流USB4、雷电4(满血USB4)的两倍,不仅支持PCIe数据直通,还兼容DP 2.0 Alt Mode视频输出。其单口的高带宽,为现代办公、AI应用场景都带来了提升。无论是通过eGPU显卡坞扩展算力,还是外接高速磁盘阵列加载TB级模型和数据集,都能获得接近原生的体验。
网络部分同样毫不妥协,双10Gbps的万兆以太网口,让MS-S1 MAX既可以高速访问NAS中的海量训练素材,也能与多台设备协同工作,成为数据密集型训练或分布式推理中的核心节点。
显示输出方面,MS-S1 MAX的HDMI 2.1FRL接口支持8K@60Hz或4K@120Hz,配合USB4V2/USB4 5个接口多路视频输出能力,整机最多可实现4屏8K@60Hz的异显输出。
另外,2个USB 3.2 Gen2 Type-A负责高速外设,而USB 2.0则专门留给键盘、鼠标等低速设备,既不占用带宽,又规避了2.4GHz干扰问题,此外还提供了Kensington防盗锁孔与BIOS复位孔,兼顾商务安全与维护需求。
整体来看,MS-S1 MAX是围绕高带宽、高吞吐和多屏并行AI应用生产力精心设计的个人/企业级超级AI端侧计算机。
02 40CU集显+16大核,AMD锐龙AI Max+ 395生产力“狂飙”
看完了外观和接口,真正凸显这台机器性能的,无疑是其搭载的AMD锐龙AI Max+ 395。
在架构层面,AMD锐龙AI Max+ 395采用了先进的Chiplet封装设计,基于Zen 5架构的多核心CPU计算模块,与一颗高度集成的 SoC / I/O Die于同一封装之中。该 SoC Die内部集成了基于RDNA 3.5 架构的高性能GPU、XDNA 2架构算力高达50 TOPS的NPU以及高带宽统一内存架构,在物理布局与系统架构层面构建出CPU、GPU与NPU深度协同的“三位一体”计算体系。
具体到硬件规格,AMD锐龙AI Max+ 395配备了16个Zen 5 CPU 核心,并集成多达40个RDNA 3.5 计算单元(CU),同时引入了革命性的256-bit超宽内存位宽,配合最高128GB的统一内存架构(UMA),理论内存带宽可达256GB/s。
针对往常集显对内存带宽高度敏感的特性,AMD锐龙AI Max+ 395采用统一内存架构,用于缓解GPU侧的带宽与延迟压力,为高性能计算、AI推理,以及高负载图形任务提供了前所未有的带宽与算力基础。

在Cinebench R23的测试中,AMD锐龙AI MAX+395在单核、多核的表现全部处于第一梯队。
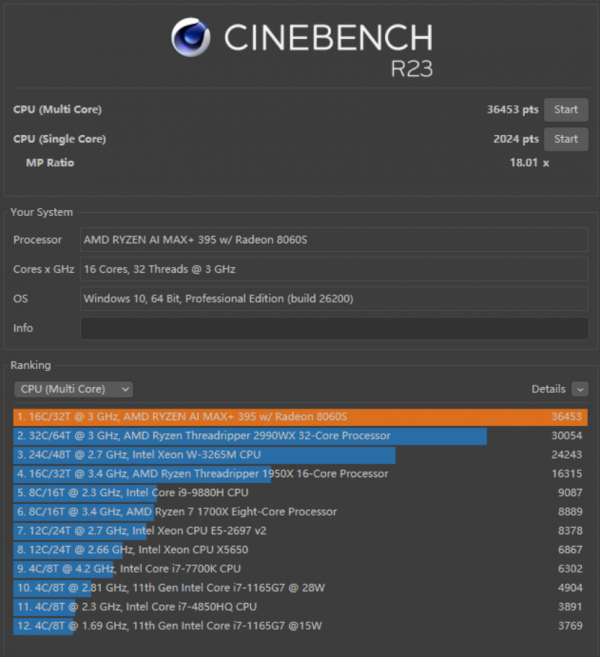
在CinebenchR23多线程测试中,单核心性能方面,得分为2024pts。该分数反映的是AMD锐龙AI MAX+ 395单个物理核心在双线程并发时的极限吞吐能力。如此表现,说明其在前端调度、执行单元利用率,以及缓存体系设计上已经具备相当成熟的优化水平。
CinebenchR23多核测试得分达到了36453,这意味着AMD锐龙AI MAX+ 395在所有核心同时工作时,性能可以稳定跑满。换句话说,多核并发时,不会很快因为功耗或温度问题掉速。这带来的直接好处是,在渲染、编译、长时间计算或多任务并行场景中,性能表现更稳定,执行时间更可预测,不需要担心“前边快,后面慢”的状态。
更具说服力的是其18.01x的MP Ratio(多核倍率)。这一数值意味着在全核满载情况下,频率衰减被控制在极低水平,同时SMT 实际效率接近理论上限,逻辑线程几乎不存在明显空转。这种高度一致的性能放大能力,正是其多线程表现能够持续、稳定释放的根本原因。
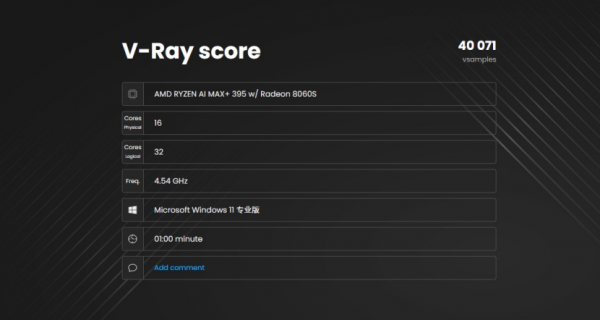
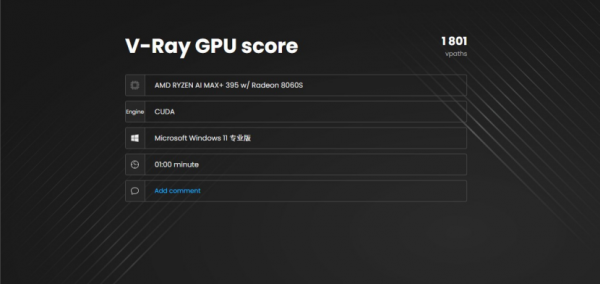
在V-Ray的测试中,CPU score达到了40071vsamples, GPU score达到1801vpaths。这一成绩表明,其CPU已经具备桌面级处理器的渲染性能,而iGPU在建筑可视化、工业设计,以及内容创作等典型生产力场景下,该平台已经能够单机完成完整的工作流,不再依赖外接显卡或者远程渲染节点,具备高效的算力表现。
在更贴近真实办公场景的PCMark 10测试中,AMD锐龙AI Max+ 395所呈现的则是系统级的效率优势,其总分达到9763分。
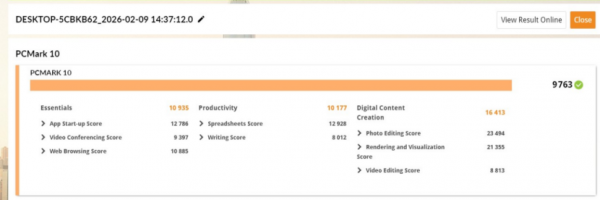
在数字内容创作子项中取得16413分,其中照片编辑达到23494分,渲染与可视化达到21355分,这些成绩体现出AMD锐龙AI Max+ 395在真实生产力负载中的表现极为强劲。
在处理超高像素RAW照片或复杂3D场景实时预览时,传统工作站往往需要在系统内存与独立显存之间频繁进行数据拷贝,不仅会产生额外的延迟,也会吞噬有效带宽,而在AMD锐龙 AI Max+ 395上,CPU与GPU可共享同一高速内存池,GPU能将128GB内存中的96GB作为专属显存使用,数据不再反复跨内存域搬运,使得渲染、预览与计算过程更加连续。
这种优势直接反映在素材能否顺利加载和运行速度、参数调整响应以及实时预览的流畅度上。对于创意工作室或内容创作者而言,这意味着在 Photoshop、Lightroom 等高负载应用中,大体量素材不再频繁成为工作流中的性能瓶颈。
在基础办公与企业级应用场景中,PCMark 10子项的“电子表格”跑出了12928分的成绩,这意味着即便面对包含数百万行数据、复杂函数嵌套与宏指令调用的金融分析或经营模型,系统依然能够保持快速计算与即时交互。
而在多应用频繁切换与重度办公软件并行启动的场景中,12786分的应用启动成绩则反映出Zen 5架构在单核瞬时响应、调度效率,以及存储与内存子系统协同方面的综合优势。
视频会议项目中9397分的成绩,则体现了平台在真实混合负载下的平衡能力,在支持的应用与系统调度前提下,其集成的NPU可持续承担背景虚化、语音降噪等任务,显著降低CPU与GPU的长期占用率,从而在多任务并行时,维持更稳定的系统响应。
03 “本地推理 + 多模态”同时起飞,AI Max+ 395 统一内存的硬核解法
从性能表现看,AMD锐龙AI Max+ 395在传统办公与内容创作场景中,已经展现出相当可观的效率优势。但对于一台定位为个人超算的设备而言,还需要通过其本地AI推理的表现来验证。
于是,我们选择80B(800亿)参数的Qwen3-next作为试金石。实测结果显示生成速度为43.72 tokens/s。
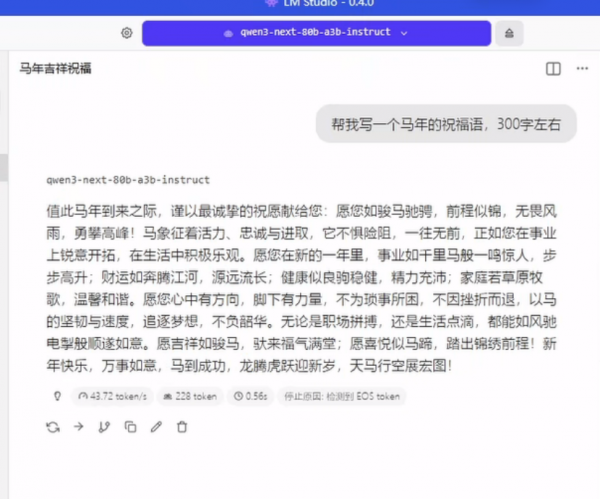
在生成阶段,43.72 tokens/s的速度,带来的体验是连续且稳定的输出节奏,已经远远超出覆盖常见的阅读与思考速度区间。无论是长文写作还是代码生成,都不会出现明显的停顿。
这主要缘于AMD锐龙AI Max+ 395在内存容量与内存访问路径上的设计优势。其128GB统一内存使CPU与iGPU共享同一物理内存池,为模型提供了充足的内存空间,从而减少额外的数据搬运开销。同时,其256-bit的位宽与高带宽的内存子系统,提供了连续的数据供给,有助于在长时间输出过程中维持稳定的吞吐。
多模态更接近个人本地AI的真实使用形态。对个人办公场景而言,截图询问、图片问答、文档与图像混合处理,正在成为高频需求。
在模型识图的场景,Qwen-3-VL-30B-A3B-Instruct模型共输出53tokens,整体耗时约 17.23 秒,平均速度约70.6 tokens/s,过程稳定,未出现明显卡顿或中途掉速。
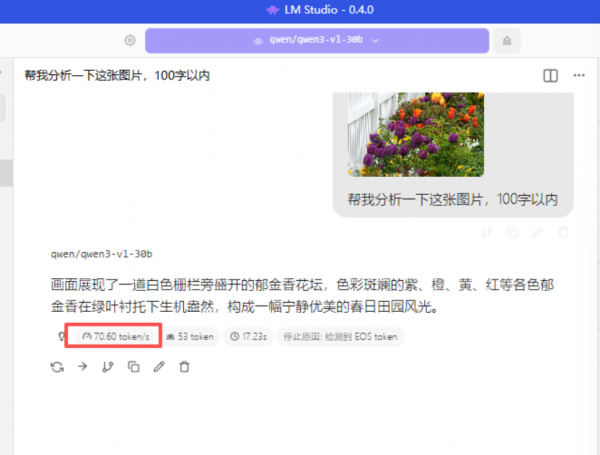
结合实际使用体验,多模态推理的整体交互节奏表现出良好的流畅性。图像输入后,模型能够迅速完成视觉特征解析并过渡到文本生成阶段,没有出现因图像编码占用资源而引发的阻塞或长时间空转。
这一表现依然与AMD锐龙AI Max+ 395的统一内存架构密切相关。CPU与iGPU访问同一物理内存池,使得图像特征、跨模态中间层,以及模型状态能够在同一地址空间内流转,减少了跨模态导致的同步开销。
正因如此,模型对图像的理解和文本生成,形成了连续、可控的推理流程,让用户在实际使用中感知到更稳定的体验。
04 本地四路并发,跑通千亿级参数模型
单模型的体验已经足够顺了,但真实使用里,很少有人只跑一个任务。当多个推理同时开跑、甚至开始挑战千亿级以上参数规模的模型时,平台的底子才能真正见分晓。
所以,我们选取了gpt-oss:120B 作为验证对象,重点考察AMD 锐龙 AI Max+ 395在单任务独占与多任务并发两种典型负载下的推理稳定性与连续性表现。
在单一推理任务中,1200亿参数的gpt-oss顺利完成了从模型加载到文本生成的完整推理流程。实测来看,在推理阶段,78tokens的处理仅耗时0.47秒;在生成阶段,模型输出187 tokens用时约5.2秒,整体生成速率稳定维持在 35.9 tokens/s。整个推理过程中,推理链路始终保持连贯、顺畅。
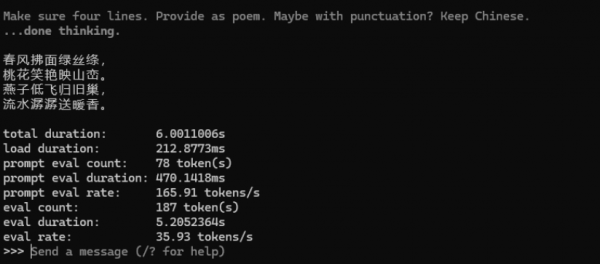
为了模拟真实使用中的多任务并行场景,我们还进行了gpt-oss:120b的四路并发测试。结果显示,在并发负载显著提升的情况下,生成阶段的单路输出速度依然稳定维持在34.9~35.1tokens/s区间,与单任务运行时几乎持平。这意味着系统总吞吐量并未随着负载增加而出现损失,推理节奏保持高度一致。
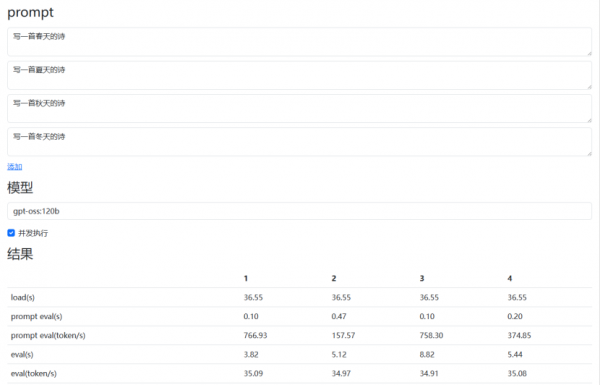
从使用体验层面看,这种表现尤为关键。本地大模型并不难跑起来,难的是一旦进入并发和持续运行状态,内存、调度和带宽不够,就会成为瓶颈。而在四路并发条件下,gpt-oss:120B 依然能够维持稳定输出,说明AMD锐龙AI Max+ 395在内存供给、访问路径以及任务调度层面具备充足余量。
这也意味着,千亿级模型可以在AMD锐龙AI Max+ 395作为多会话、并行工作的基础能力被稳定调用。对于定位为“个人超算”的产品而言,这种在高并发场景下仍能保持输出节奏与响应确定性的表现,才是真正具备实用价值的体现。
另一方面,这台设备在运行千亿参数模型时,无论是单任务还是高并发场景,都能保持出色表现,其背后来自AMD锐龙AI Max+ 395架构层面的多项关键设计。
一方面是统一内存架构(UMA)对显存墙的根本性突破。AMD锐龙AI Max+ 395支持最高128GB的统一内存,使120B级模型权重能够实现完整常驻(Full Residency)内存,同时为并发推理过程中持续增长的KV Cache(键值缓存)预留了充足空间。
这一点在多会话场景中尤为关键。传统“CPU + 独显”架构下,KV Cache的频繁扩展极易引发显存不足与跨设备的数据迁移,最终导致推理抖动甚至停滞。而在UMA统一内存架构中,模型权重、中间状态与缓存数据始终位于同一物理内存池内,彻底避免了因分页(Paging)或 PCIe 往返拷贝带来的隐性性能损失。
更进一步,CPU与iGPU 的零拷贝(Zero-Copy)访问路径,消除了传统架构中“计算单元闲等数据”的结构性瓶颈。在四路并发负载下,内存带宽得以被持续、稳定地利用,而不是被浪费在数据搬运本身,这正是系统总吞吐量能够线性扩展的重要前提。
另一方面,是AMD锐龙AI Max+ 395的Zen 5核心在控制上的调度能力。虽然本地大模型推理的主要算力消耗集中在iGPU,但在KV Cache 管理、Token 级采样、并发上下文维护,以及操作系统层面的线程调度等关键控制环节,仍高度依赖 CPU的单线程性能与调度效率。
AMD 锐龙 AI Max+ 395的Zen 5核心在单核IPC 提升的同时,也强化了多核场景下的线程调度、任务分发与状态同步能力,使其能够在多路并发推理中高效完成上下文切换,并以稳定节奏向iGPU 提供指令与数据,避免因调度抖动导致计算资源空转,从而保证多路输出的整体一致性。
另外,AMD锐龙AI Max+ 395的RDNA 3.5架构的iGPU与内存子系统共同构成了推理主通路,承担了绝大部分矩阵计算与数据访问任务。
综合来看,AMD 锐龙 AI Max+ 395 已经具备将千亿级模型作为“可并发、可持续、可交付”的本地能力来使用的系统基础,而MS-S1 MAX Mini AI Workstation正是这一能力的承载形态。
05 告别Token计费束缚,OpenClaw本地模型调用火力全开
既然千亿参数的“极限大考”都能在四路并发下稳如泰山,我决定正式让AI接管我的核心工作。
所以,我通过OpenClaw调用Ollama本地部署的开源模型。
通过OpenClaw调用Ollama本地部署的Qwen3-next:80b模型,可以明显感觉到整个流程变得顺畅而可控。在任务拆解、规划和工具调用之间的切换非常连贯,不再因为配额或速率限制被迫中断推理节奏。即便是在需要多轮分析和反复执行代码的场景下,模型依然能够保持上下文一致性,完整走完从“理解需求”到“修正结果”的闭环。
更重要的是,这种顺畅并不是靠“压缩任务”换来的,而是让 Agent 按它本该有的方式,把该想的步骤想完、该跑的工具跑完。
之所以这套OpenClaw+本地Qwen3-next:80b的组合能够稳定地跑下来,另一个关键在于底层硬件AMD锐龙AI MAX+395的承载能力。
事实上,Qwen3-next:80b即使在4-bit量化下,依然接近48GB的显存空间,这直接卡死了绝大多数消费级显卡。而AMD 锐龙AI MAX+ 395 采用的128G统一内存架构,让模型不再被专用显存容量所限制,可以完整地运行在GPU推理路径上。
在长时间、多轮推理和频繁工具调用的Agent场景中,系统不需要在显存与内存之间反复腾挪,也不会因为内存紧张而被迫中断任务。
在这套链路真正稳定下来之后,我开始让OpenClaw做更“真实”的任务。
我在OpenClaw中接入了Brave Search API,使其具备了网页检索能力,同时让其将检索与整理结果统一保存为本地文本,作为后续写作的素材备份。
从执行细节来看,这已经是一条相当成熟的检索型工作流。依托本地Qwen3-next:80b的推理能力,网页信息被压缩为高度概括的要点式条目,核心的关键要素得以完整保留,而冗余修辞被系统性剥离,最终形成“材料骨架”。
本地保存这一环节的意义同样关键。所有检索与分析结果均存储在本机,不依赖云端缓存、会话状态,也不存在对话结束后资料丢失的问题。对于需要反复调用、交叉比对、持续扩展的办公场景而言,这种可追溯、可复查、可二次加工的素材形态,远比一次性生成内容更具实际价值。
在任务执行过程中,搭载AMD 锐龙AI Max+395的铭凡MS-S1 MAX迷你AI工作站为Agent提供了可以长期占用、持续运转的本地算力底座,使检索、解析与推理能够在同一执行环境中连续完成。即便面对信息量较大的网页或者多轮连续调用的任务,模型依然能够维持稳定的输出,不会出现上下文断裂,也不会引发工具调用的节奏混乱。
正是这种稳定、可控、高性价比的本地任务能力,使这款AI超算足以持续承担检索、整理与归档等高频工作,真正进入办公生产的日常流程。
06 写在最后
回头看,搭载AMD锐龙AI Max+ 395的铭凡MS-S1 MAX迷你AI工作站的价值,远不止于一台“跑得快”的迷你主机,其代表了计算范式的深刻转移——将AI的边际成本归零。
当千亿级模型的推理成本低到只剩电费时,我们就可以放心地让OpenClaw等Agent在本地反复跑百次千次,把每条逻辑分支都试一遍,不再为API账单焦虑。这种“无限推理”的自由,才是Agent进化为“生产力”的关键门槛。
也正因为踩了云端的延迟、账单和数据安全的坑,我才更确定,拥有一台个人AI超算是必要的,甚至说,在现代办公、创作乃至科研场景下,每个人都需要一台个人AI超算。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献383条内容
已为社区贡献383条内容

所有评论(0)