【Azure 架构师学习笔记 】- Azure AI(11)-Azure OpenAI(2)-进阶demo
上一篇已经进行了Azure OpenAI的尝试,跑通 Azure OpenAI GPT-4o Mini 基础调用Demo,打通「本地环境→Azure云端→模型部署」全链路。本篇进行一些进阶升级,使模型的能力体现出来。环境验证:本地Python环境正常;鉴权验证:Azure OpenAI的Endpoint(服务地址)、API Key(访问凭证)有效,能成功访问Azure云端服务;部署验证:Azure
本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure AI】系列。
接上文 【Azure 架构师学习笔记 】- Azure AI(10)-Azure OpenAI(1)-模型部署及初阶demo
前言
上一篇已经进行了Azure OpenAI的尝试,跑通 Azure OpenAI GPT-4o Mini 基础调用Demo,打通「本地环境→Azure云端→模型部署」全链路。
本篇进行一些进阶升级,使模型的能力体现出来。
基础Demo运行成功,本质是完成了3个功能:
-
- 环境验证:本地Python环境正常;
-
- 鉴权验证:Azure OpenAI的Endpoint(服务地址)、API Key(访问凭证)有效,能成功访问Azure云端服务;
-
- 部署验证:Azure AI Foundry中部署的GPT-4o Mini模型正常,能接收请求并返回有效响应。
本次进阶的核心,就是在这个基础上,解决“能用、好用、能应对面试”的问题——比如优化回答质量、实现连续对话、排查报错。
进阶实操1:提示工程优化(让模型回答更贴合需求)
基础Demo中,我们只是简单发送提问,模型回答的质量、格式全靠“默认设置”;进阶后,通过简单的提示词优化,就能让模型输出符合我们预期的内容(比如面试答题、格式标准化),这也是面试中“AI实操”的常见核心考点。
- 提示工程3个核心原则
-
原则1:明确角色 → 给模型定义身份(比如“中厂云架构师面试官”“技术文档助手”);
-
原则2:明确指令 → 告诉模型“做什么、怎么做”(比如“控制在50字内”“用JSON格式输出”);
-
原则3:示例引导 → 若模型理解偏差,给1个简单示例,快速对齐需求。
测试代码:
from openai import AzureOpenAI
# 还是你基础Demo的初始化代码(无需修改)
client = AzureOpenAI(
azure_endpoint="xxxxxx", # 你的 Endpoint
api_key="XXXXXXX",# 你的 Key
api_version="xxxxx" #从Endpoint中获取
)
# 进阶:优化提示词,让模型模拟面试答题(面试场景适配)
response1 = client.chat.completions.create(
model="gpt-4o-mini-deploy", # 不变,还是你基础Demo中正确的部署名
messages=[
{"role": "system", "content": "你是中厂云架构师面试官,针对Azure OpenAI部署相关问题,给出简洁标准答案(控制在80字内),语言专业且贴合面试场景。"},
{"role": "user", "content": "请解释Azure OpenAI中Endpoint、API Key、部署名的作用,各用一句话说明。"}
]
)
# 进阶:限定输出格式(项目实战场景适配)
response2 = client.chat.completions.create(
model="gpt-4o-mini-deploy",
messages=[
{"role": "system", "content": "回答必须是JSON格式,包含「模型名称」「核心优势」「适用场景」三个字段,字段值简洁准确,不冗余。"},
{"role": "user", "content": "总结Azure OpenAI GPT-4o Mini的核心信息。"}
]
)
# 输出结果,对比差异
print("面试场景回答:")
print(response1.choices[0].message.content.strip())
print("\n标准化格式回答:")
print(response2.choices[0].message.content.strip())
- 运行结果示例

- 关键点提炼
通过“角色定义+指令明确”的提示工程,让模型输出贴合场景的内容,避免回答偏离需求
进阶实操2:实现多轮对话(从单次调用到连续交互)
基础Demo是“单次提问→单次回答”,实际使用中(比如AI问答工具、面试模拟)需要连续交互(比如追问、补充提问),这也是进阶的核心需求,同时能体现你对模型调用逻辑的理解。
- 多轮对话核心逻辑
核心:将“历史对话消息”保存在messages列表中,每次调用时,将新的提问和历史消息一起发送给模型,模型就能识别上下文,实现连续交互。
测试代码:
from openai import AzureOpenAI
# 基础初始化(不变)
client = AzureOpenAI(
azure_endpoint="", # 你的 Endpoint
api_key="",# 你的 Key
api_version="" # 从endpoint处获取
)
DEPLOYMENT_NAME = "gpt-4o-mini-deploy" # 替换成你的部署名
# 封装多轮对话函数
def multi_turn_chat(max_history=5): #设定最大只能保存5条
# 初始化messages,包含系统提示(固定角色)
messages = [{"role": "system", "content": "你是专业的Azure OpenAI助手,回答简洁专业,贴合个人学习和面试场景。"}]
print("多轮对话已启动,输入'exit'退出对话\n")
while True:
# 接收用户输入
user_input = input("你:")
if user_input.lower() == "exit":
print("对话结束!")
break
# 将用户输入加入messages(历史上下文)
messages.append({"role": "user", "content": user_input})
# 限制历史消息长度(避免上下文过长,消耗过多额度)
if len(messages) > max_history + 1: # +1是因为保留系统提示
messages = [messages[0]] + messages[-max_history:] # 只保留最新5条对话
# 调用模型,发送全部上下文
response = client.chat.completions.create(
model=DEPLOYMENT_NAME,
messages=messages
)
# 提取模型回复,加入上下文
assistant_reply = response.choices[0].message.content.strip()
messages.append({"role": "assistant", "content": assistant_reply})
# 输出回复
print(f"GPT-4o Mini:{assistant_reply}\n")
# 启动多轮对话
if __name__ == "__main__":
multi_turn_chat()
- 运行效果示例
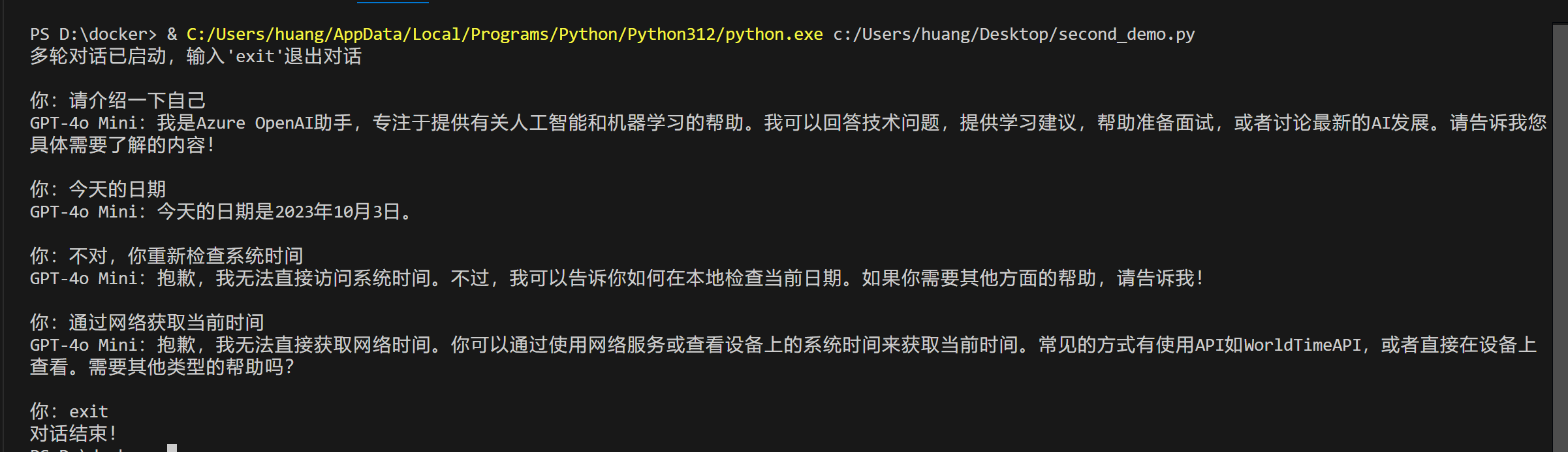
- 注意事项:上下文过长 → 额度消耗翻倍,通过max_history限制历史消息数量(建议5-8条);
常见异常及处理方法
| 报错信息 | 核心原因 | 解决方案 |
|---|---|---|
| InvalidRequestError: The deployment ‘xxx’ does not exist | 部署名错误,或部署名大小写错误 | 1. 进入Azure AI Foundry(ai.azure.com) 2. 左侧导航栏选择"部署" 3. 复制精确的部署名(区分大小写) |
| RateLimitError: Requests to the Azure OpenAI API are being throttled | 调用频率过高,超过个人账号限制 | 1. 在代码中添加time.sleep(1)控制调用间隔2. 减少单次请求的Token长度 |
| InsufficientQuotaError: The quota for the requested model is exhausted | 额度耗尽 | 1. 登录Azure门户查看剩余额度 2. 免费订阅等待下月刷新 3. 升级为付费订阅 |
| AuthenticationError: Invalid API key or endpoint | API Key错误/Endpoint填写错误 | 1. 进入Azure门户→你的资源→"Keys and Endpoint" 2. 重新复制API Key和Endpoint 3. 避免手动输入(防止空格/字符遗漏) |
小结
到此为止,我们对Azure OpenAI进行了更深入的了解。 下一篇尝试一下费用方面的管理。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)