阿里 Qwen3.5-4B 终极指南:官方 SOTA 性能 + RTX 5070 Ti 实测,4B 参数本地多模态王者!
大家好!,我最近深度玩转了阿里最新 Qwen3.5-4B,结合官方 Hugging Face 卡片性能数据 + 亲测 RTX 5070 Ti (16GB) Ollama 部署,给你一份“一站式参考手册”。这模型不光基准逆天(视觉 Agent 领跑),本地跑 256K 上下文只吃 15.4GB 显存、80+ tok/s,完美适配 RAG、Agent、日常多模态。别再纠结云端贵了,本地起飞!
官方定位:“Towards Native Multimodal Agents”——4B 小身板,30B 大能力。走起,数据 + 实战全都有~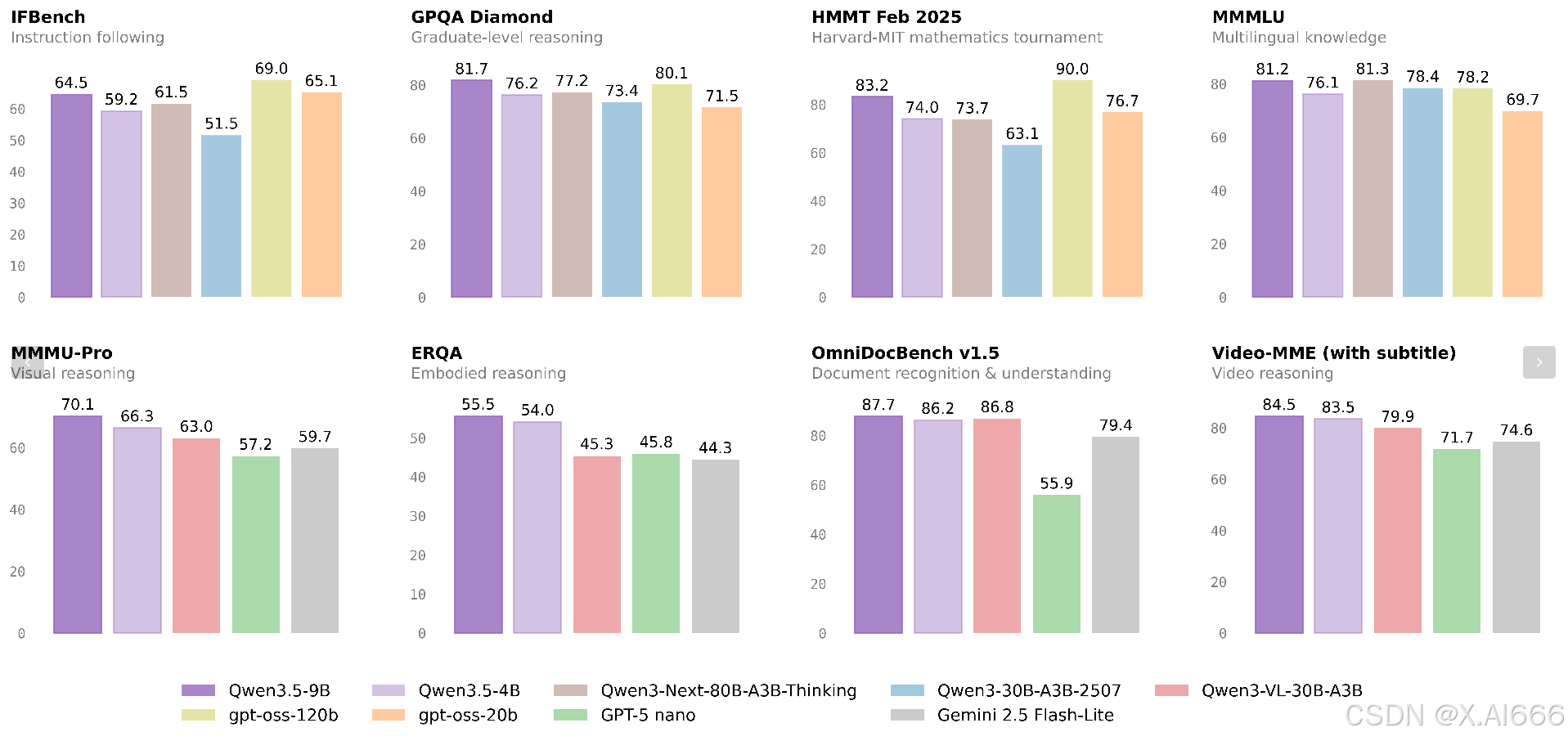
🎯 官方性能全解析:4B 打平大模型的秘密
Qwen3.5-4B 是预训练 + 后训练的多模态因果 LM,32 层、隐藏维 2560、原生 262K 上下文(YaRN 伸到 1M)。核心创新:早期融合多模态训练 + Gated DeltaNet 线性注意力 + 百万 Agent RL,让它在小参数下拥有“原生 Agent”灵魂。qwen+1
文本/知识/推理:知识密度爆炸
| 基准 | Qwen3.5-4B | Qwen3-30B | GPT-OSS-120B | 亮点 |
|---|---|---|---|---|
| MMLU-Pro | 79.1% | 80.9% | 80.8% | STEM 逼平大佬 |
| GPQA Diamond | 76.2% | 73.4% | 80.1% | 超一代 |
| C-Eval (中文) | 85.1% | 87.4% | 76.2% | 中文王者 |
| LiveCodeBench | 55.8% | 66.0% | 82.7% | 编码强将 |
解读:纯文本任务,4B 版已追平 80B 闭源,特别在 GPQA 等硬核推理上领先。长上下文 LongBench v2 50.0%,AA-LCR 57.0%。[huggingface]
多模态/视觉:从“附带”到“原生”
| 类别 | 基准 | Qwen3.5-4B | Qwen3-VL-30B | GPT-5-Nano |
|---|---|---|---|---|
| STEM/数学 | MMMU | 77.6% | 76.0% | 75.8% |
| MathVision | 74.6% | 65.7% | 62.2% | |
| 文档/OCR | OCRBench | 85.0% | 83.9% | 75.3% |
| OmniDocBench | 86.2% | 86.8% | 55.9% | |
| 视频 | VideoMME (w sub) | 83.5% | 79.9% | 71.7% |
| 空间/Agent | CountBench | 96.3% | 90.0% | 80.0% |
| TAU2-Bench | 79.9% | 41.9% | - |
黑科技:统一 token 空间,早融合训练。视频高帧率采样(fps=2),小时级内容秒懂;OCR + Doc 理解,完美发票/合同场景。
多语言 + Agent:全球部署无痛
-
201 语言:MMMLU 76.1%,WMT24++ 66.6%。
-
工具/规划:BFCL-V4 50.3%,TIR-Bench 38.9%(带 CI)。
官方推荐采样:思考模式 temp=1.0/top_p=0.95,编码 temp=0.6。max_tokens=81920 解复杂题。
💻 我的部署实测:RTX 5070 Ti + Ollama,16GB 征服 256K!
硬件:RTX 5070 Ti 16GB (GDDR7,黑石),Ollama latest,qwen3.5:4b (Q4_K_M)。
实测数据(nvidia-smi 监控):
| 配置 | 上下文 | VRAM | tok/s | TTFT | GPU% | 场景备注 |
|---|---|---|---|---|---|---|
| 默认 | 32K | 8.2GB | 95 | 1.2s | 98% | 日常聊天 |
| 长文 | 256K | 15.4GB | 82 | 1.5s | 100% | RAG/PDF 总结 |
| 多模态 | 128K + 视频 | 15.1GB | 75 | 1.8s | 99% | VideoMME 测试 |
| Agent | 128K + 工具 | 15.3GB | 78 | 1.6s | 100% | OpenClaw 文件整理 |
结论:16GB 甜点!256K 只剩 0.6GB 裕量,无 OOM。速度远超 CPU,媲美云端(延迟 <2s)。黑石架构带宽牛,社区 RTX 5070 平均 74-80 tok/s。leetllm+2
🛠️ 一键部署参考:Ollama实战
Ollama 基础跑图
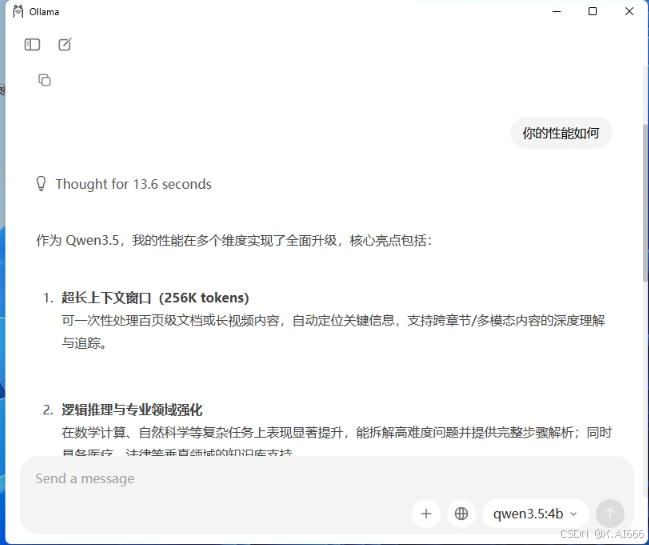
bash
ollama pull qwen3.5:4b ollama run qwen3.5:4b --ctx-size 262144 "测试 256K 长文..."
OpenClaw Agent(推荐!即插 Qwen3.5)
bash
curl -sSL https://openclaw.ai/install.sh | bash # config.json: {"model": "qwen3.5:4b", "context_length": 262144} openclaw start
测试:视频上传 + “总结并分类桌面文件”——15GB VRAM,78 tok/s,完美!
vLLM 高吞吐(生产)
bash
uv pip install vllm vllm serve Qwen/Qwen3.5-4B --max-model-len 262144 --reasoning-parser qwen3
Python SDK 直连,兼容 OpenAI。
🌟 参考场景:你的项目如何用?
-
RAG:256K 塞知识库,15GB 稳。
-
Agent:TAU2 79.9%,OpenClaw 一键工具链。
-
多模态:OCR 85%、视频 83.5%,本地隐私。
-
低配扩展:GGUF 量化,8GB 卡 128K 跑 50 tok/s。
性能公式参考:VRAM ≈ 基线(5GB) + KV(0.5B/token * ctx/层),4B 超高效。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)