为什么AI不需要考虑所有可能性?Top-K采样的智慧选择
本文介绍了top-k采样技术及其在AI文本生成中的应用。top-k采样通过仅考虑概率最高的前k个候选词,在保持生成合理性的同时增加多样性。文章详细解析了其工作原理,包括排序、筛选、重归一化和随机选择四个步骤,并探讨了k值选择的关键性。对比了top-k采样的优劣势,指出其在避免不合理输出与平衡多样性方面的优势,但也存在参数调优困难等局限。最后,文章提及了top-k采样在聊天机器人、内容创作等场景的实
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
什么是top-k采样?为什么只考虑最可能的几个选项就够了?
一、为什么需要top-k采样
想象一下你正在玩一个猜词游戏。每次轮到你时,系统会给你成千上万个可能的词汇选择,但其中大部分都是完全不相关的。比如在句子"今天天气真___“后面,理论上可以填入任何词汇,但实际上只有"好”、“棒”、“美”、"晴朗"等少数几个词是合理的。
传统的随机采样方法就像把所有词汇都放在一个巨大的抽奖箱里,虽然概率不同,但理论上每个词都有被抽中的可能。这会导致AI有时会生成完全不合逻辑的词汇,比如"今天天气真冰箱"或"今天天气真数学"。
而贪心搜索又太过死板,总是选择概率最高的那个词,导致文本变得单调重复。
top-k采样就像是一个聪明的过滤器:它先看一眼所有可能的选择,然后只保留最有可能的k个选项,再从这k个选项中进行随机选择。这样既避免了完全不合理的词汇,又保持了一定的多样性。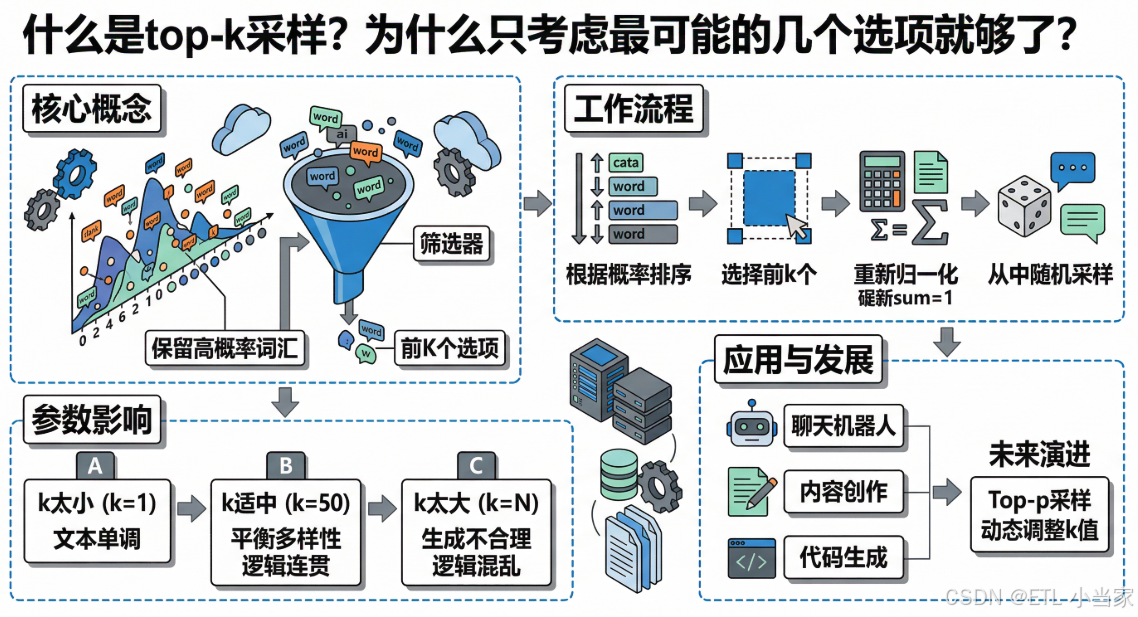
二、什么是top-k采样
top-k采样是一种文本生成策略,其核心思想很简单:
- 排序:对于当前要生成的下一个词,模型会为词汇表中的每个词计算一个概率
- 筛选:只保留概率最高的前k个词(这就是"top-k"的含义)
- 重归一化:将这k个词的概率重新调整,使它们的总和为1
- 随机选择:根据调整后的概率,从这k个词中随机选择一个作为输出
举个例子,假设我们的词汇表有10000个词,模型计算出前5个词的概率分别是:
- “好”:0.4
- “棒”:0.3
- “美”:0.2
- “晴朗”:0.08
- “不错”:0.02
如果我们设置k=5,那么top-k采样就会忽略剩下的9995个词,只在这5个词中按比例随机选择。这样既保证了合理性,又增加了多样性。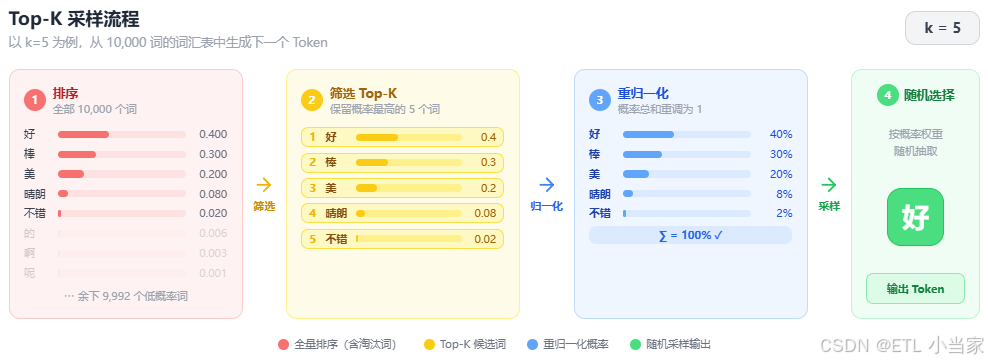
三、top-k采样如何工作
工作原理详解
top-k采样的工作流程可以分为以下几个步骤:
第一步:获取完整概率分布
模型首先会为词汇表中的每个词计算一个概率值,形成一个完整的概率分布。
第二步:选择top-k词汇
从这个概率分布中,选择概率最高的前k个词汇。k是一个超参数,通常设置为10、50或100。
第三步:概率重归一化
由于我们只保留了k个词汇,原来的所有概率之和不再是1。因此需要将这k个词汇的概率重新缩放,使它们的总和等于1。
第四步:随机采样
最后,根据重归一化后的概率分布,使用随机采样的方法选择最终的输出词。
参数k的选择
k值的选择非常关键:
- k太小(如k=1):退化为贪心搜索,文本会变得单调
- k太大(如k=10000):接近完全随机采样,可能会生成不合理的内容
- k适中(如k=50):在合理性和多样性之间取得良好平衡

四、top-k采样的优缺点
| 优势 | 劣势 |
|---|---|
| ✅ 避免生成完全不合理的词汇 | ❌ k值需要手动调参 |
| ✅ 在合理性和多样性间取得平衡 | ❌ 固定的k值可能不适合所有情况 |
| ✅ 实现简单,计算效率高 | ❌ 在某些情况下仍可能过于保守 |
| ✅ 显著提升生成文本的质量 | ❌ 无法动态适应不同上下文的不确定性 |
五、top-k采样的实际应用
top-k采样在实际应用中非常广泛:
- 聊天机器人:让对话更加自然多变,避免重复回答
- 内容创作:生成多样化的文章、故事或诗歌
- 代码生成:在保持语法正确的同时增加实现方式的多样性
- 机器翻译:避免过度保守的翻译结果
- 摘要生成:产生不同风格但同样准确的摘要
许多现代AI系统都会将top-k采样与其他技术结合使用,比如与temperature参数配合,或者与top-p(nucleus)采样结合,以获得更好的效果。
六、top-k采样的发展与演进
虽然top-k采样解决了传统随机采样的很多问题,但它也有自身的局限性。最主要的挑战是固定的k值无法适应不同上下文的不确定性。
例如,在某些确定性很高的上下文中(如"巴黎是法国的___“),可能只需要考虑很少的几个选项;而在开放性很强的上下文中(如"我认为___”),可能需要考虑更多的可能性。
为了解决这个问题,研究人员提出了top-p采样(也称为nucleus采样),它不是固定选择前k个词,而是选择累积概率达到某个阈值p的最小词汇集合。这种方法能够动态调整考虑的词汇数量,更好地适应不同上下文的需求。
目前,许多先进的语言模型都会同时提供top-k和top-p采样的选项,让用户可以根据具体需求进行选择和组合。
by @Laizhuocheng

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)