《零基础搞懂神经网络 & 手写AI:从神经元公式到PyTorch实战》
【学习记录】零基础搞懂神经网络 & 手写AI:从神经元公式到PyTorch实战
本文完整记录了从“神经元数学模型”到“PyTorch训练循环”的学习全过程,包含公式推导、反向传播原理、代码逐行拆解。全程无废话,适合AI初学者收藏反复看。
🧠 一、一个公式搞懂AI如何“学习”
你有没有想过一个问题——
你三岁的时候,没有人给你讲“特征空间”“决策边界”,但你就是能一眼分清猫和狗。为什么?
因为你的大脑看了大量例子,自己总结出了规律。
而今天我们要聊的“神经网络”,就是模仿这个过程。
1. 小孩区分猫狗 → 学习本质
你给小孩看10张猫、10张狗,他一开始可能乱猜,但多看几次,脑子里就会慢慢形成规则:
“耳朵尖尖的、胡子长的……哦,是猫。”
“吐舌头、摇尾巴的……哦,是狗。”
这其实就是学习:通过数据,自动调整判断依据。
神经网络把这个过程用数学模拟出来——它不需要你告诉它“耳朵尖是猫”,它自己看几千张图,自己调整“判断标准”。
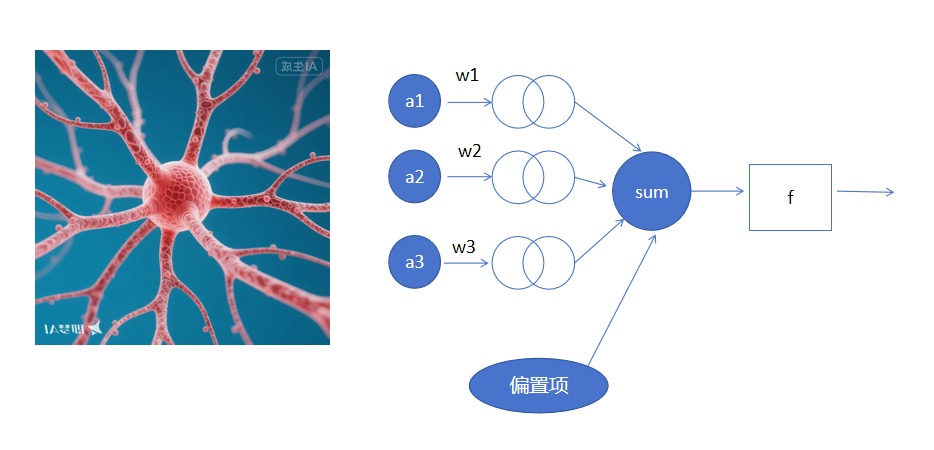
2. 人工神经元长什么样?
生物神经元有树突接收信号、轴突传出信号。
人工神经元更简单:接收多个输入,每个输入有一个权重,加一个偏置,算出一个总和,最后经过一个激活函数,决定要不要“兴奋”。
公式:
输出 = 激活函数( w₁×x₁ + w₂×x₂ + … + b )
手算一个苹果识别例子
假设判断一个东西是不是苹果,只看两个特征:
- 颜色红不红:红=1,不红=0
- 个头大不大:大=1,不大=0
权重:颜色重要程度 0.5,个头也是 0.5,偏置 b=0。
来了一个红红的大果子:
加权和 = 0.5×1 + 0.5×1 = 1.0
若激活函数设定为“总和≥1就算苹果”,则输出“是苹果”。
注:权重和阈值是人工设的,真正的神经网络会自动学出来。

3. 单个神经元不够 → 需要多层
区分猫和狗,特征远不止“红不红”“大不大”。很多情况下数据不是线性可分的——你没法画一条直线把猫和狗彻底分开。
这时候就需要把多个神经元堆叠起来:
- 第一层看局部特征
- 第二层组合特征
- 最后一层做决策
这就是神经网络的多层结构:
输入层 → 隐藏层 → 输出层
🔁 二、网络如何变聪明?——前向传播 + 反向传播
前面搞懂了神经网络是一堆积木(神经元)搭成的多层结构,每个积木有公式:加权和 + 激活函数。
但这些积木一开始全是随机乱搭的——它怎么从“全错”慢慢变成“很准”?
这一节讲清楚四个词:前向传播、损失函数、反向传播、梯度下降。
1. 前向传播(Forward Propagation)
名字吓人,其实特别简单:把输入数据从输入层开始,一层一层往前传,最后在输出层得到一个预测结果。
例如识别手写数字“3”:
图片像素值 → 第一层计算 → 传给下一层 → … → 输出层(10个神经元,代表0~9),分数最高的就是当前猜测。
比喻:学生拿到一道题,从头算到尾,给出一个答案。这就是“前向”。
2. 损失函数(Loss Function)
计算网络的预测和真实答案之间有多大的差距。
识别“3”时,真实答案是第4个神经元(索引3)为1,其它为0。网络可能输出第8个神经元(数字7)分数最高,损失函数就给出一个数值,比如2.3。猜得越离谱,损失越大。
比喻:老师给学生答卷打分,分数越高错得越离谱。
3. 反向传播(Backpropagation)
误差是从输出层一步步前向计算得到的,那我们就沿原路返回,把误差分摊给每一层的每个神经元,告诉它们:“你的贡献导致了多少错误,该怎么改。”
比喻:你做卷子(前向),老师打分(损失),你开始订正错题——发现最后一道大题错了,往前倒推:是第三步公式代错了?还是第一步条件看漏了?一步步检查到源头。反向传播就是网络内部自动做这个“倒推订正”。
4. 梯度下降(Gradient Descent)
把损失函数的值当作“高度”,权重当作地面上的坐标。一开始随机初始化权重,站在山上高点(损失大),要一步步往山下走到损失最小的谷底。
- 梯度:当前最陡的下降方向
- 下降:沿着这个方向迈一小步(步长=学习率)
更新公式:
新权重 = 旧权重 - 学习率 × 梯度
一句话总结:反向传播负责找方向,梯度下降负责迈步子。
5. 完整的训练循环
前向传播 → 计算损失 → 反向传播 → 更新参数
重复几百、几千次,网络就从“胡说八道”变得越来越准。
🧰 三、不写代码也能懂——神经网络的实现框架
前面干了件大事:认识了神经元、搞懂了训练四步。
但如果每次训练都要手算梯度、手写求导公式,头发就没了。
所以需要框架(如PyTorch)来自动化这些步骤。
1. 架构设计(搭积木)
- 输入层:大小由数据决定(如28×28图片 → 784个输入)
- 隐藏层:层数和每层神经元个数自己定
- 输出层:大小由任务决定(识别0~9 → 10个输出)
你只需要回答三个问题:
- 输入有多少特征?
- 中间要几层?每层几个神经元?
- 输出要分几类?
2. 训练循环的通用模板(不依赖具体框架)
无论PyTorch还是TensorFlow,训练循环永远长这样:
1. 前向传播:数据喂给网络,得到预测
2. 计算损失:比较预测和真实答案,得到一个数字
3. 反向传播:根据损失算出每个权重的梯度
4. 更新参数:用梯度下降把权重往正确的方向调一小步
比喻:学生做卷子(前向)→ 老师打分(损失)→ 订正错题(反向)→ 记到错题本(更新参数)。循环越多遍,成绩越好。
3. 框架帮我们做了什么?
在深度学习框架诞生前,研究者要手动推导每个权重的梯度公式,逐行实现反向传播。
现在用PyTorch,你只需要:
- 定义架构(搭积木)
- 写训练循环,其中最关键的一行是:
这一行会自动计算整个网络所有权重的梯度,不管网络多深。loss.backward()
此外,框架还支持GPU加速,原本训练一小时的任务可能两分钟搞定。
💻 四、PyTorch实战·上——数据加载 + 模型搭建
现在正式进入PyTorch代码实战。目标:跑通数据加载 + 搭好神经网络骨架。
1. 导入库
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
torch:主库,张量计算、自动微分torch.nn:神经网络层、激活函数、损失函数torch.optim:优化器(SGD, Adam等)torchvision:图像数据集和预处理DataLoader:批次加载、打乱数据
2. 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
ToTensor():PIL图片 → Tensor,像素值从0255缩放到0.01.0Normalize(mean, std):标准化,输出 = (输入 - mean)/std,将01映射到-11,训练更稳定
3. 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
4. DataLoader(批次加载器)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
batch_size=64:每次喂64张图片shuffle=True:训练集打乱顺序,防止模型学到数据顺序的假规律;测试集不打乱保证可复现
5. 搭建神经网络骨架
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(28*28, 128) # 输入784,输出128
self.fc2 = nn.Linear(128, 10) # 输入128,输出10
self.relu = nn.ReLU()
def forward(self, x):
x = x.view(-1, 28*28) # 展平图片
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
nn.Linear(in, out):全连接层view(-1, 784):将[64,1,28,28]变为[64,784],-1表示自动计算该维度- 注意:forward中没有softmax,因为后面用的CrossEntropyLoss内部已包含
6. 实例化模型、损失函数、优化器
model = SimpleNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
🚀 五、PyTorch实战·下——训练循环 + 评估 + 调试点
模型参数还是随机的,猜数字准确率仅约10%。现在运行训练循环,见证它学到95%以上。
1. 训练循环代码(逐行解析)
for epoch in range(3): # 训练3个完整周期
running_loss = 0.0
for images, labels in train_loader: # 每次取一个batch
# 前向传播
outputs = model(images) # 得到预测得分
loss = criterion(outputs, labels) # 计算损失
# 反向传播和优化
optimizer.zero_grad() # 清零梯度(重要!)
loss.backward() # 自动计算梯度
optimizer.step() # 更新参数
running_loss += loss.item()
print(f'Epoch {epoch+1}, Loss: {running_loss/len(train_loader):.4f}')
关键三行解释
optimizer.zero_grad():必须清零梯度,否则梯度会累积。比喻:梯度像垃圾桶,不清空旧垃圾就会越堆越多。loss.backward():一行代码自动完成整个网络的反向传播,计算出所有参数的梯度。optimizer.step():用梯度下降更新参数。
2. 评估模型(测试集)
correct = 0
total = 0
with torch.no_grad(): # 不记录计算图,节省内存
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1) # 得分最高的类别索引
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'准确率: {100 * correct / total:.2f}%')
在MNIST上,这个简单模型通常能达到 95%~97% 的准确率。
3. 常见调试点(避坑指南)
| 现象 | 可能原因 | 解决办法 |
|---|---|---|
| loss不下降或极慢 | 学习率太小 / 忘记Normalize | 调大lr到0.01 / 检查数据预处理 |
| loss变成NaN | 学习率太大,梯度爆炸 | 降低lr,或加梯度裁剪 |
| 准确率一直很低(<80%) | 训练不够 / 网络太简单 | 增加epoch到5~10 / 增加隐藏层神经元 |
| 训练准确率高,测试低(过拟合) | 网络太复杂 / 数据量少 | 加Dropout / 减小网络规模 |
🎯 总结:你走过的完整学习路径
✅ 神经元公式:输出 = 激活函数(∑wᵢxᵢ + b)
✅ 前向传播:数据从输入到输出走一遍
✅ 损失函数:量化预测与真实的差距
✅ 反向传播:把误差倒着传回去,算每个权重的梯度
✅ 梯度下降:用梯度更新权重,让损失变小
✅ 训练循环模板:前向→损失→反向→更新,重复N次
✅ PyTorch实战:数据加载、模型搭建、训练评估,不到30行代码跑通手写数字识别
你现在已经具备了自己动手写一个神经网络的基础能力。下一步可以尝试:换数据集(CIFAR-10)、加深网络、调参、或者用GPU加速。
📌 本文为完整学习记录,所有代码均可复制运行。如果对某个环节有疑问,欢迎在评论区交流。
#深度学习 #PyTorch #神经网络入门 #学习记录
代码
"""
《零基础搞懂神经网络 & 手写AI》系列完整代码
环境要求:Python 3.7+,PyTorch 1.10+
安装命令:pip install torch torchvision
"""
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# -------------------- 1. 数据预处理 --------------------
# 定义数据转换:先转张量并缩放到[0,1],再标准化到[-1,1]
transform = transforms.Compose([
transforms.ToTensor(), # PIL -> Tensor,像素值/255 -> [0,1]
transforms.Normalize((0.5,), (0.5,)) # 标准化: (x-0.5)/0.5 -> [-1,1]
])
# 下载并加载训练集(60000张)和测试集(10000张)
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 数据加载器:批量加载,训练集打乱顺序,测试集不打乱
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# -------------------- 2. 定义神经网络模型 --------------------
class SimpleNN(nn.Module):
"""一个简单的全连接神经网络:输入层(784) -> 隐藏层(128) -> 输出层(10)"""
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(28*28, 128) # 输入层:28x28=784个像素
self.fc2 = nn.Linear(128, 10) # 输出层:10个类别(数字0~9)
self.relu = nn.ReLU() # 激活函数
def forward(self, x):
x = x.view(-1, 28*28) # 展平: (batch,1,28,28) -> (batch,784)
x = self.relu(self.fc1(x)) # 全连接1 + ReLU
x = self.fc2(x) # 全连接2(输出层,未加softmax,因为CrossEntropyLoss自带)
return x
# 实例化模型、损失函数、优化器
model = SimpleNN()
criterion = nn.CrossEntropyLoss() # 交叉熵损失(适用于多分类)
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器
# -------------------- 3. 训练循环 --------------------
num_epochs = 3 # 训练轮数(简单任务3轮已够,可增加到5~10提升准确率)
for epoch in range(num_epochs):
running_loss = 0.0
for images, labels in train_loader:
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和参数更新
optimizer.zero_grad() # 清零梯度(避免累积)
loss.backward() # 自动计算梯度
optimizer.step() # 根据梯度更新权重
running_loss += loss.item()
# 每个epoch结束后打印平均损失
avg_loss = running_loss / len(train_loader)
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}')
# -------------------- 4. 模型评估 --------------------
correct = 0
total = 0
with torch.no_grad(): # 评估时不需要计算梯度,节省内存
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1) # 取概率最高的类别
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f'\n模型在测试集上的准确率: {accuracy:.2f}%')

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)