多智能体强化学习——VDN
前言
因为动作空间和观测空间往往非常庞大,具有单一联合奖励信号的多智能体协同强化学习问题具有挑战。
1、问题引入
上述的多智能体协同强化问题中存在“虚假奖励”问题以及部分可观测引发的“懒惰智能体”现象。(
- 虚假奖励: 对于一个智能体而言,其获得的团队奖励可能是其他智能体造成的,因此该奖励对该智能体而言是“虚假奖励”。
- 懒惰智能体: 由于团队中的存在其他智能体已经学到足够解决问题的策略了,而剩下的智能体无论做什么都能获得不错的团队奖励,因而这些剩下的智能体被称为“惰性智能体”。
2、核心思想
2.1 Q值函数分解
本文提出了一种针对独立智能体的新型学习型加法价值分解方法。该价值分解网络通过深度神经网络反向传播总Q梯度,从团队奖励信号中学习最优线性价值分解,这些网络分别对应各组件的价值函数。
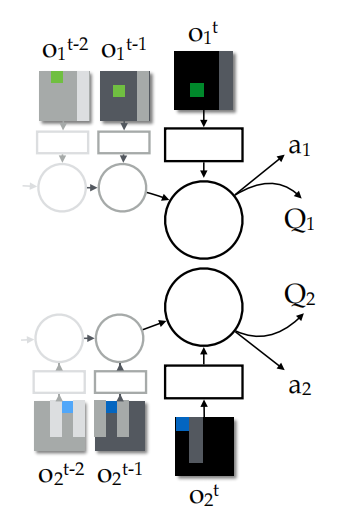
上图为独立智能体架构示意图,局部观测经过低级线性层传递至循环层,最终由对抗层生成个体Q值。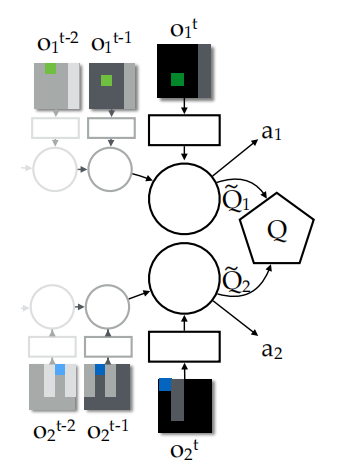
上图为价值分解个体示意图,局部观测通过低级线性层传递至循环层,随后对抗层生成个体“价值”,这些个体价值被汇总位联合Q函数用于训练,同时动作独立于个体输出生成。
VDN的核心思想是,该系统的联合动作价值函数可被加性分解为各智能体间的的价值函数。其中每个智能体的动作价值函数 Q ~ i \tilde{Q}_i Q~i仅仅依赖于每个智能体的局部状态观测,其是通过隐式学习而非特定奖励获得的。
Q ( ( h 1 , h 2 , … , h d ) , ( a 1 , a 2 , … , a d ) ) ≈ ∑ i = 1 d Q ~ i ( h i , a i ) Q\bigl((h^1, h^2, \dots, h^d), (a^1, a^2, \dots, a^d)\bigr) \approx \sum_{i=1}^{d} \tilde{Q}_i(h^i, a^i) Q((h1,h2,…,hd),(a1,a2,…,ad))≈i=1∑dQ~i(hi,ai)
该方法的一个显著特点为:虽然学习过程需要一定程度的集中化管理,但训练的智能体可以独立的部署。
2.2 参数不变性
VDN论文中提出一个定理叫:参数不变性,核心思想如下式所示,即如果对于智能体序号的任意排列满足 p : { 1 , … , d } → { 1 , … , d } p \colon \{1, \dots, d\} \to \{1, \dots, d\} p:{1,…,d}→{1,…,d},则称 π \pi π满足智能体不变性。
π ( p ( h ˉ ) ) = p ( π ( h ˉ ) ) \pi(p(\bar{h})) = p(\pi(\bar{h})) π(p(hˉ))=p(π(hˉ))
在需要通过特定角色优化系统时,保持智能体不变性并非总是理想选择。可以为每个智能体分配角色信息或标识符。角色信息以独热编码形式提供,即智能体身份信息与所有观测值的组合。当智能体共享全部网络权重时,它们仅仅在同角色的条件下才具有完全一致的策略。
2.3 模型架构
智能体算法基于DQN,融入了其标志性技术——经验回放池与目标网络,同时结合了LSTM值网络,通过时间截断反向传播的学习机制、采用前向视图
不同方法的架构差异在于各层的输入方式。
独立智能体架构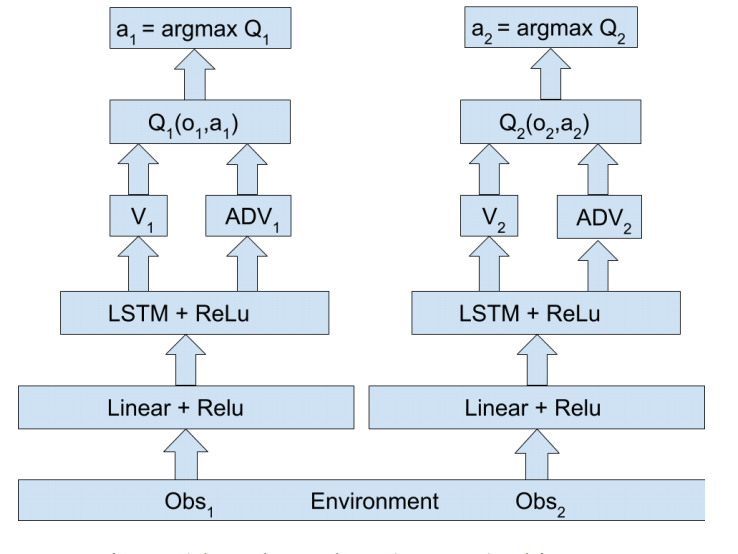
价值分解的独立智能体架构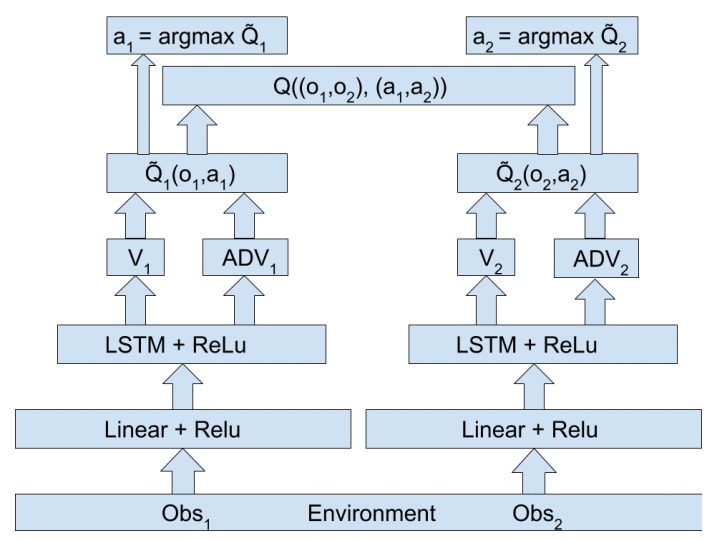
底层通信架构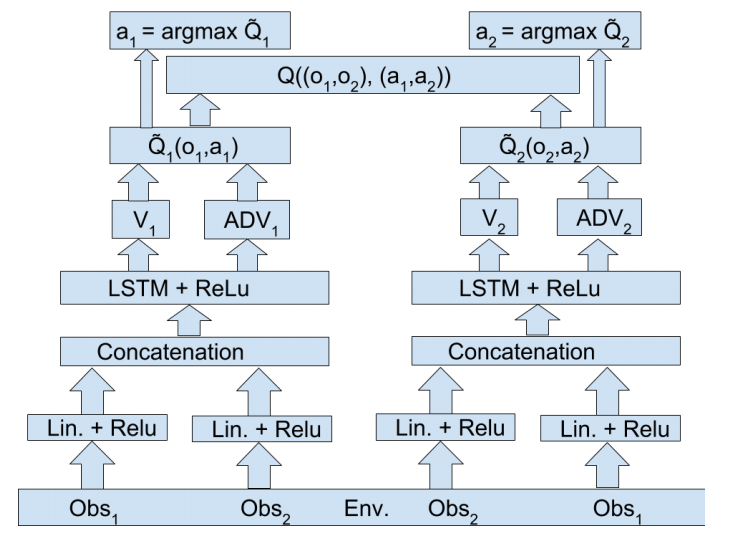
高层通信架构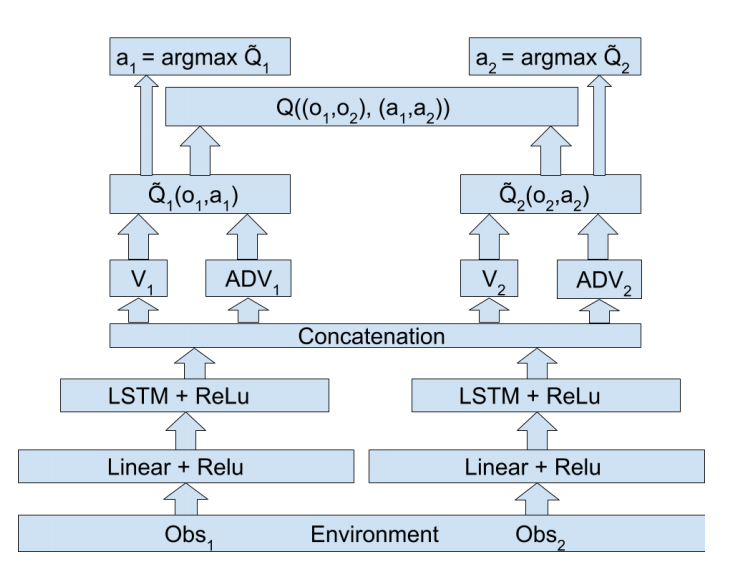
底层通信架构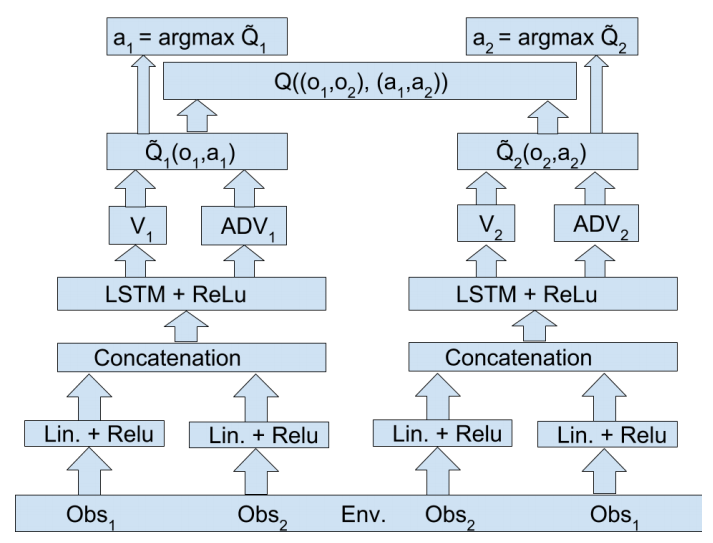
独立智能体架构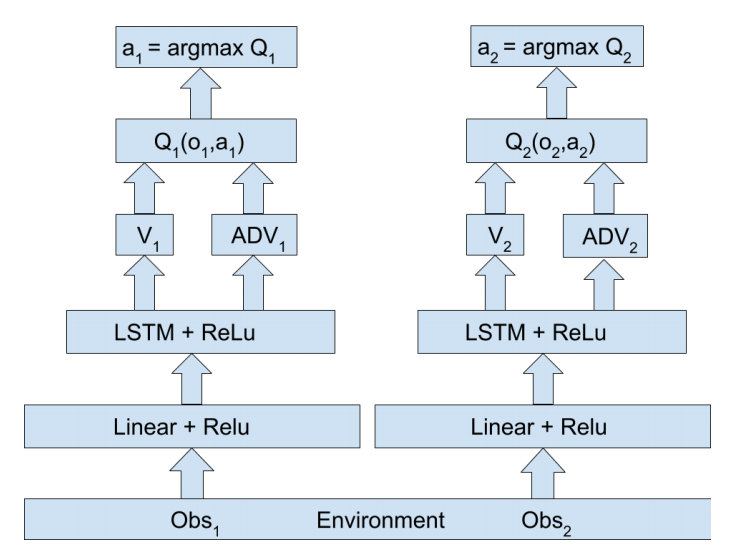
组合式集中式体系结构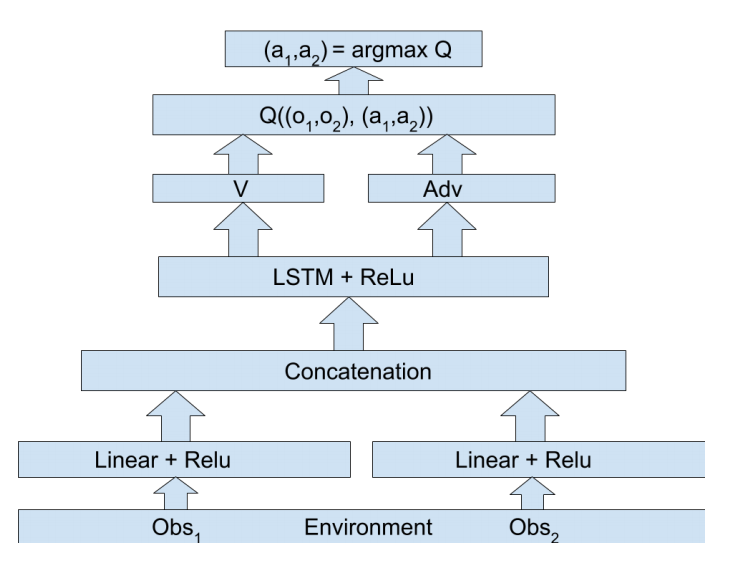
高层-底层通信架构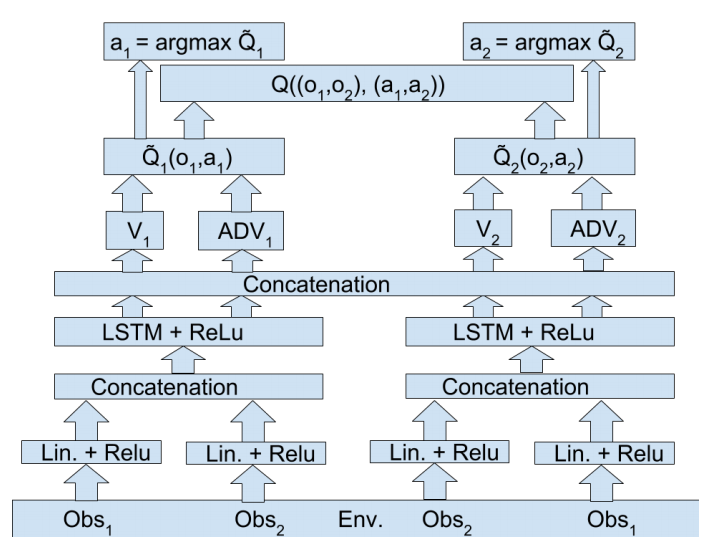
3、实验设计
此实验在如下二维环境中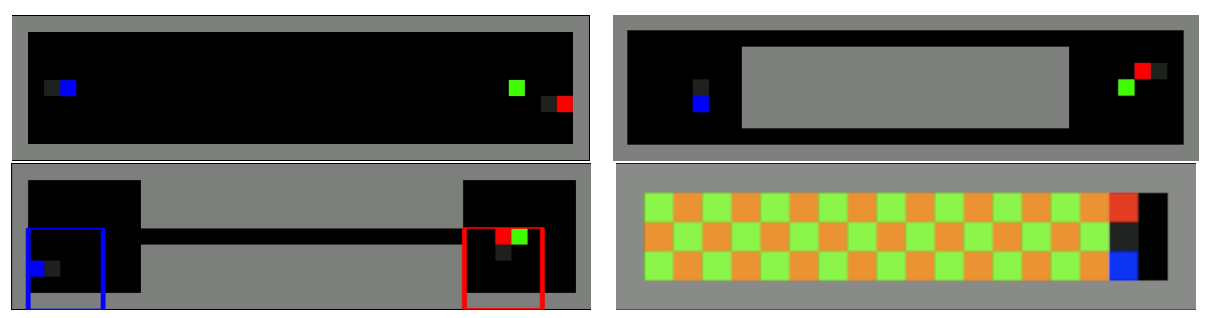
总结
- VDN的端到端训练方式与参数共享,算法收敛速度很快
- 值分解定理存在理论支撑验证其有效性

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)