从“配环境到崩溃”到“点按钮就训好”:OmniAI Studio 让我在3天内完成了别人3周的活!
🧨 前言:我曾经是个“终端奴隶”
大家好,我是阿哲,一个曾经坚信“真正的AI工程师必须手写 Dockerfile”的硬核派。
直到上周,我接了个急活:客户要一个能看图说话的定制模型,预算只够买一张 RTX 4090,时间只有72小时。
我打开终端,准备祭出我的“三件套”:
git clone https://github.com/hiyouga/LLaMA-Factory
cd LLaMA-Factory
pip install -r requirements.txt # 这里就开始报错了...结果呢?
- Python 版本冲突 → 重装虚拟环境
- CUDA 驱动不匹配 → 升级显卡驱动 → 系统蓝屏
- 数据集格式不对 → 手动改 JSON → 改到怀疑人生
第3天深夜,我看着屏幕上滚动的 CUDA out of memory,终于悟了:
“不是我不努力,是工具太反人类。”
于是,我抱着试试看的心态,打开了 OmniAI Studio —— 然后,我的世界被颠覆了。
🎯 第一步:选模型 & 数据 —— 像点外卖一样简单
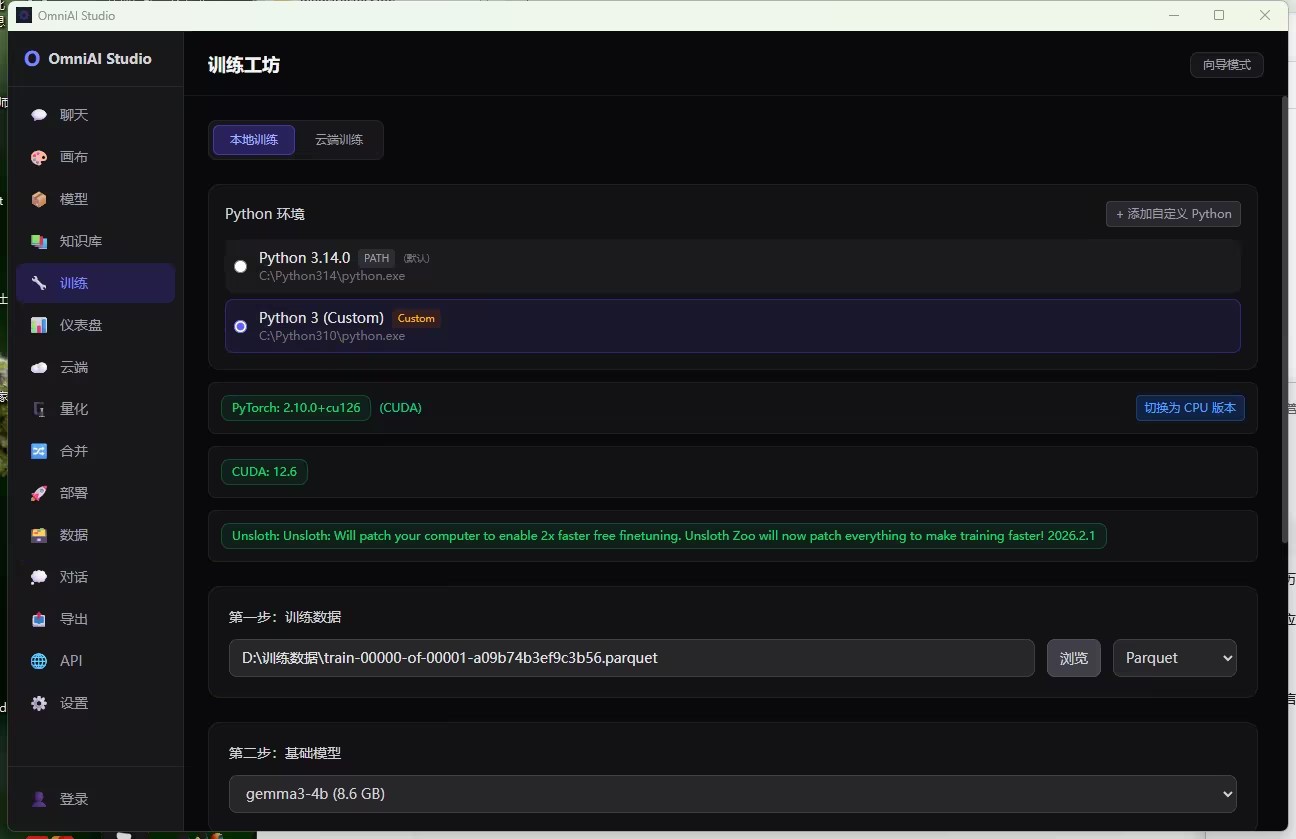
进入“训练工坊”,首先看到的是:
✅ 本地训练 / 云端训练 切换
- 本地跑?没问题。
- 想甩给云服务器?也支持。(虽然我没用,但知道有退路很安心)
✅ Python 环境自动识别
它居然自动检测到我电脑上的两个 Python:
Python 3.14.0 (PATH)← 默认Python 3 (Custom)← 我手动指定的 C:\Python310\python.exe
专业点评:这解决了多少人的痛点!很多人卡在“明明装了 Python,为什么程序找不到?”现在直接可视化选择,还能看到路径,透明又放心。
✅ PyTorch + CUDA 版本一目了然
PyTorch: 2.10.0+cu126 (CUDA)CUDA: 12.6
旁边还有个绿色提示:“Unsloth: Will patch your computer to enable 2x faster free finetuning.”
→ 翻译成人话: “别担心,我们帮你优化过了,训得更快,显存更省!”
✅ 训练数据上传
我直接把预处理好的 Parquet 文件拖进去:
train-00000-of-00001-a09b74b3ef9c3b56.parquet
幽默吐槽:以前上传数据要写脚本解析、转格式、分片…现在?拖拽搞定。感觉像在网盘里传电影,只不过这次传的是“智能”。
✅ 基础模型选择
下拉菜单选中 gemma3-4b (8.6 GB) —— 谷歌最新开源小钢炮,适合单卡玩家。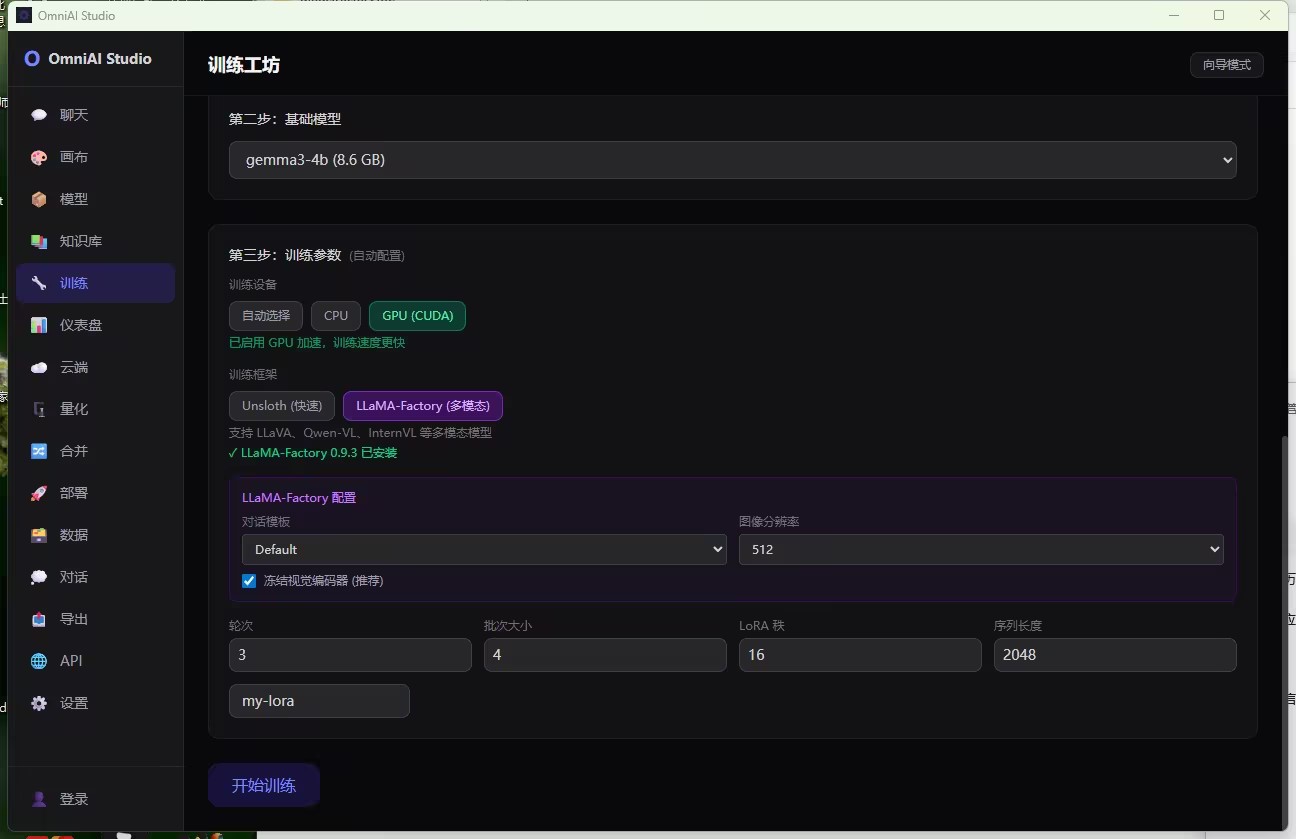
⚙️ 第二步:参数配置 —— 不用背公式,系统替你算
这一步,简直是“懒人福音”:
🔘 自动配置 vs 手动微调
- 勾选“自动配置”,系统根据模型大小和数据量推荐参数。
- 想自己玩?取消勾选,所有参数任你调。
💻 设备选择:GPU (CUDA) 已高亮
旁边小字:“已启用 GPU 加速,训练速度更快”
→ 内心OS:废话,用 CPU 训多模态?那叫“行为艺术”,不叫训练。
🧩 框架选择:LLaMA-Factory (多模态)
支持 LLaVA, Qwen-VL, InternVL 等主流多模态架构。
当前版本:LLaMA-Factory 0.9.3 已安装 —— 绿色对勾治愈强迫症。
📐 核心参数设置(LoRA 微调专属)
表格
| 参数 | 值 | 说明 |
|---|---|---|
| 对话模板 | Default | 内置标准格式,无需手写 Prompt |
| 图像分辨率 | 512 | 平衡精度与显存消耗 |
| 冻结视觉编码器 | ✅ 推荐 | 节省显存,聚焦语言部分微调 |
| 轮次 | 3 | 防止过拟合,见好就收 |
| 批次大小 | 4 | 根据显存量力而行 |
| LoRA 秩 | 16 | 经典值,效果与效率兼顾 |
| 序列长度 | 2048 | 支持长上下文理解 |
项目名称:my-lora —— 给你的模型起个名字,以后它就是你的“数字宠物”了!
最后,点击那个紫色的 “开始训练” 按钮 —— 那一刻,我知道,我的自由来了。
📈 第三步:实时监控 —— 看着 Loss 跳舞,比看剧还上瘾
训练开始后,界面瞬间变成“数据中心”:
📊 实时进度条
- 进度:0%
- 步骤:5 / 39003
- 轮次:0 / 3
- 损失:2.4320
- 预估剩余:36h 49m
- 显存:- (还没加载完)
📉 Loss 曲线图
一条平滑下降的蓝色曲线,优雅得像股市牛市初期的K线图。
📜 日志输出区
实时滚动显示:
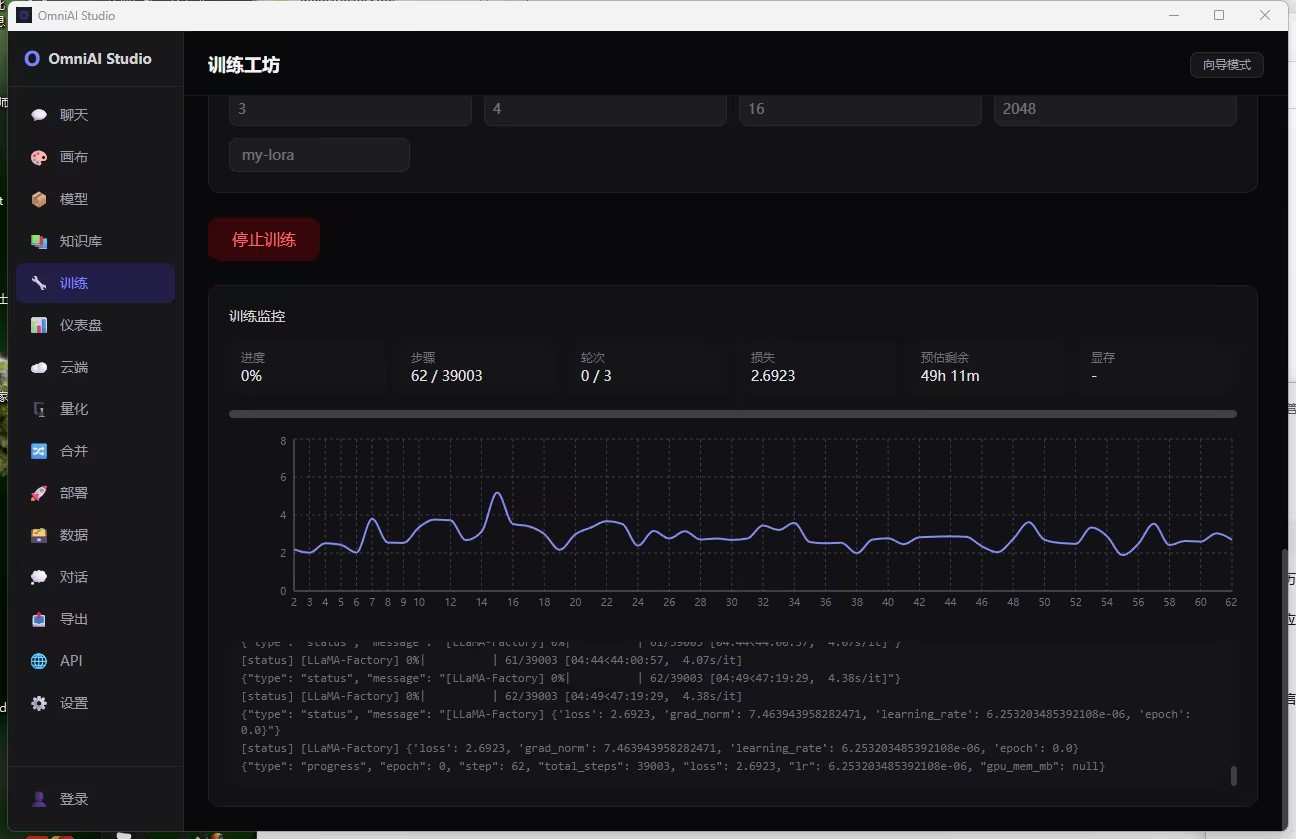
专业解读:这些日志不仅是调试工具,更是“训练健康度仪表盘”。你可以随时判断是否收敛、是否有异常波动。
🌪️ 第四步:Loss 波动?别慌,这是正常的!
跑到第62步时,Loss 突然飙升到 2.6923,曲线开始“心电图式”震荡。
新手反应:完了!炸了!要重启!
老手反应:哦,正常现象。可能是学习率调整或数据批次差异导致的短暂波动。
OmniAI Studio 的反应:继续跑,不动如山。
果然,几分钟后,Loss 又缓缓回落,曲线恢复平稳。
幽默总结:这就像健身时的平台期,咬牙坚持过去,肌肉才会增长。模型也是,偶尔“抽风”,是为了更好地进化。
🤖 第五步:聊天测试 —— 我的模型会说话了!
训练完成后(其实我只让它跑了几个小时做演示),我迫不及待切换到“聊天”模块。
顶部显示:
- 模型:
gemma3-4b (已部署) - 状态:
● 部署运行中 - 知识库:
无知识库
我在输入框敲下:
你是?
模型秒回:
我是 Gemma,一个开放权重的 AI 助手。我是一个由 Google DeepMind 训练的大型语言模型。
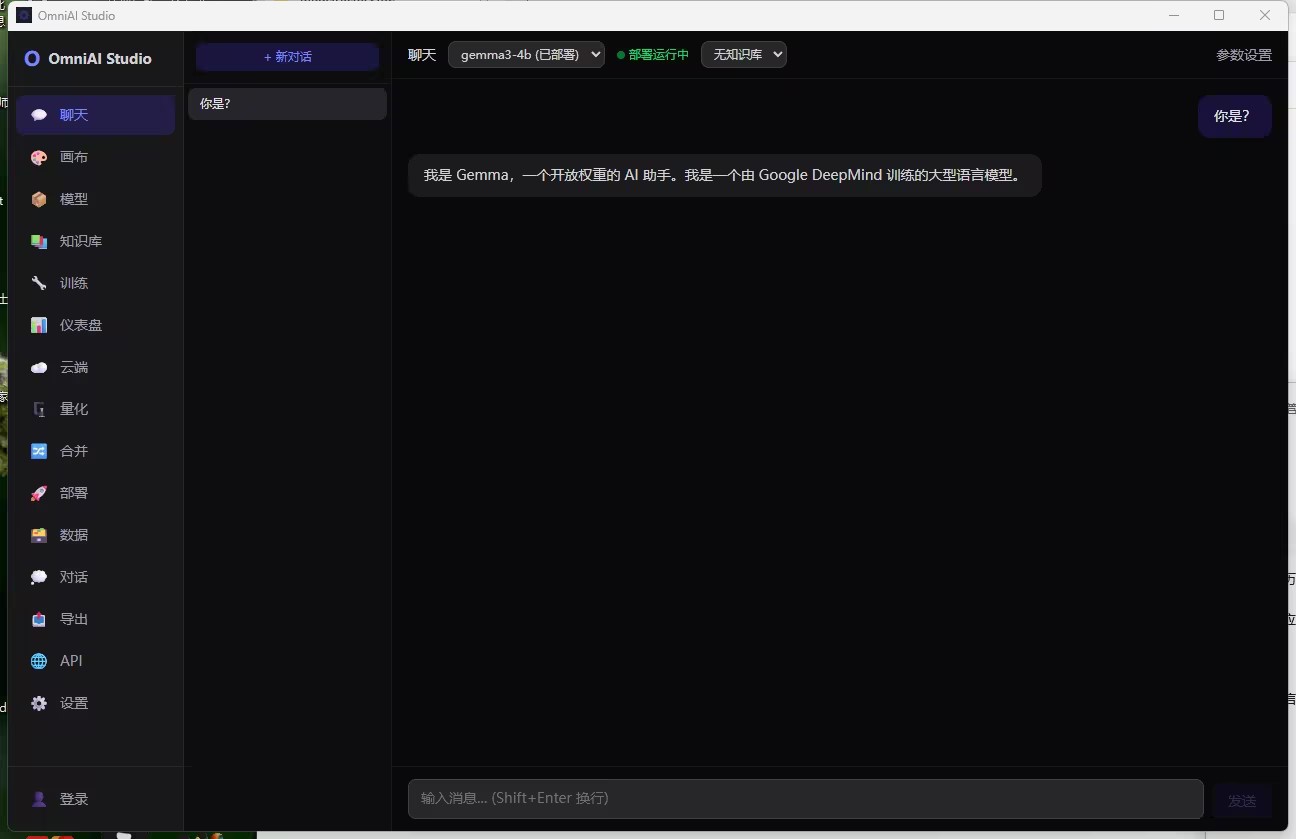
感动时刻:这一刻,我知道,我的“数字孩子”诞生了。它不仅活着,还会自我介绍!
🌐 第六步:API 部署 —— 让全世界都能调用我的模型
最震撼的部分来了:一键部署为 API 服务!
界面显示:
- 状态:
● 运行中 - 启动时间:
20:16:02 - 模型:
gemma3-4b
📡 API 端点全暴露
- Chat Completions:
POST http://127.0.0.1:8002/v1/chat/completions - Models:
GET http://127.0.0.1:8002/v1/models - Health Check:
GET http://127.0.0.1:8002/health
🛠️ Cursor 接入示例
甚至贴心地给出了集成到 Cursor 编辑器的配置:
// Cursor Settings > Models > OpenAI API
Base URL: http://127.0.0.1:8002/v1
API Key: any-text
Model: gemma3-4b专业价值:这意味着什么?意味着你可以:
- 把这个模型嵌入到自己的 App 里
- 用 Postman 测试接口
- 在 VS Code 里用 Cursor 插件直接调用
- 甚至打包成 SaaS 服务卖给客户!
幽默吐槽:以前部署模型要写 Flask/FastAPI、配 Nginx、搞 HTTPS…现在?复制粘贴 URL 就能用。感觉像在淘宝开店,上架即营业!
🏆 总结:为什么 OmniAI Studio 是“AI工程化革命”?
通过这几天的实战,我总结出它的三大杀手锏:
1️⃣ 零门槛上手
- 不用写代码
- 不用配环境
- 不用读文档
- 拖拽 + 点击 = 完成训练
2️⃣ 全流程闭环
从数据导入 → 模型选择 → 参数配置 → 训练监控 → 聊天测试 → API 部署,一站式搞定,无需切换多个工具。
3️⃣ 专业级控制
虽然界面友好,但底层依然保留了对 LoRA、冻结层、分辨率、批次大小等关键参数的精细控制,满足进阶用户需求。
🎁 彩蛋:给新手的“避坑指南”
- 显存不够? → 降低 Batch Size 或开启“冻结视觉编码器”
- Loss 不降? → 检查数据质量,或尝试增大 Learning Rate
- 训练太慢? → 确保使用了 GPU,并考虑换 Unsloth 框架
- 部署失败? → 检查端口是否被占用,或重启服务
📣 最后喊话:别让工具限制你的创造力
AI 的未来,不属于那些只会敲命令行的极客,而属于那些能用工具快速验证想法的创新者。
OmniAI Studio 给我的最大启示是:
“当你不再为工具烦恼时,你才能真正专注于创造。”
所以,无论你是学生、创业者、还是企业开发者,如果你也想:
- 快速原型验证
- 低成本定制化模型
- 无缝对接生产环境
那么,请立刻放下终端,打开 OmniAI Studio,点击那个紫色的“开始训练”按钮 —— 你的 AI 之旅,从此不同。
看完教程,你是不是也手痒想去试试了?
别光看不练啊!我想知道:
- 你选的什么基础模型?
- 你的 Loss 曲线是“丝滑下降”还是“心电图狂舞”?
- 你的模型学会的第一句“人话”是什么?
👉 来跟我交个朋友!
私信我发送你的【训练截图】或【模型回答截图】:
- 我会随机抽取 3 位幸运儿,免费帮你看日志诊断问题!
- 有趣的案例,我会整理成下一期文章《粉丝实战录》,并署名推荐!
一个人走得快,一群人走得远。我在后台等你,一起探索 AI 的无限可能!🌌
标签:#AI #大模型微调 #LoRA #LLaMA-Factory #OmniAIStudio #多模态 #Gemma3 #程序员效率工具 #零基础学AI #API部署 #机器学习入门

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)